I read the press release from Moore Threads this week, and while there were no new silicon announcements, the operational implication is significant: they’ve shipped a full-stack simulation platform that actually works on their hardware.
No new GPUs, no new AI accelerators.
Yet a domestic GPU manufacturer did something remarkably tangible during its entire press conference—
It launched the first fully localized, embodied intelligence simulation platform.
Let’s look at the results first.

A robot dog named Xiao Fei slowly walked onto the stage.
Upon reaching the center, Xiao Fei in the simulated world on the screen performed a sideways flip. Immediately after, the physical-world Xiao Fei executed the exact same movement.

It turned around and did it again; the movements were as if copied and pasted.

Xiao Fei’s motion strategy was simple:
100% trained in a simulation environment, then seamlessly transferred to the real physical world.
So, who is this domestic GPU player behind it? And what is this embodied intelligence simulation platform called?
No more suspense.
It is MT Lambda, freshly released by Moore Threads.

The sequence performed by Xiao Fei can be understood as:
This marks the first time a motion control strategy trained on fully domestic hardware has been completely deployed onto domestic edge-side chips, achieving the first real-world verification of Sim-to-Real (simulation to reality).
With this, Moore Threads has become the only GPU company in China to connect the entire chain of “Large Model Training — Simulation — Edge Deployment.”
If the explosion of large models relied on being “fed” massive amounts of internet data, then the rise of embodied intelligence urgently requires an extremely realistic virtual world.
Now, domestic GPUs are starting to build their own worlds.
A Factory Floor for Physical AI Training
I read through the breakdown of MT Lambda, and it’s clear this isn’t just a sandbox—it’s an assembly line. The architecture splits into MT Lambda-Lab for strategy (RL, imitation learning, VLA) and MT Lambda-Sim for high-fidelity physics and rendering. This creates a closed loop: Data Synthesis — Strategy Training — Simulation Verification — Edge Deployment.

The driving force here is cost. Zhang Jianzhong outlined three brutal realities of physical AI: manual data collection is too expensive, breaking real robots during training is a financial risk, and lab models rarely generalize to the messy real world. We can’t just scrape the internet for robot behavior; we need synthetic data that accounts for friction, lighting, and sensor noise at scale.
In practice, synthetic data pipelines are the only way to de-risk physical deployment before touching hardware. I think if your sim doesn’t handle differentiable physics, you’re flying blind on edge cases.
The engine stack relies on three pillars: physics, rendering, and AI. For physics, MT Lambda integrates MuJoCo-Warp-MUSA and Newton-MUSA alongside their self-developed AlphaCore engine. Built on the MUSA architecture for parallel solving, this setup claims a 30x improvement in simulation throughput efficiency under typical loads.
This matters because inaccurate physics breaks policies. If your sim doesn’t correctly model force feedback or ground stress, the robot fails when it hits reality. The goal is to make the virtual environment indistinguishable from the physical one so training transfers directly.
Operationally, a 30x throughput gain is nice, but only if the API overhead doesn’t eat the savings. In practice, differentiable physics is non-negotiable for gradient-based policy optimization in robotics.
On the rendering side, the MT Photon engine combines ray tracing with hybrid rendering, adding 3D Gaussian Splatting and AI generative rendering to boost realism. This narrows the Sim-to-Real gap by ensuring synthetic sensor data (camera, LiDAR, tactile) matches real-world distributions. During a demo with Guanglun Intelligence, Zhang noted that the MTT S5000 features RT Core ray tracing capabilities
I read the specs for the MTT S5000, and the numbers suggest a serious push into high-fidelity simulation. The hardware-accelerated RT Core delivers nearly a threefold increase in graphics rendering performance. In relevant tests, using this core for ray tracing resulted in a 2.7x performance boost.
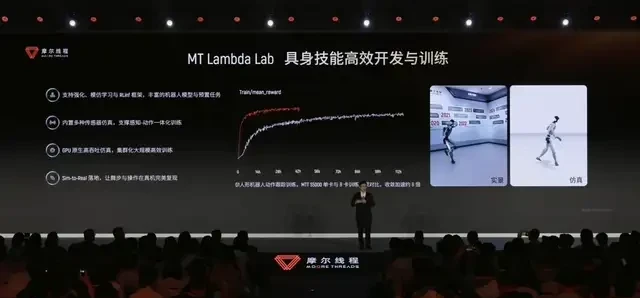
Finally, the AI Engine.
MT Lambda integrates the Torch-MUSA framework, deeply adapted for PyTorch, alongside acceleration libraries like muSolver and muFFT. It supports the development and deployment of Vision-Language-Action (VLA) models while incorporating reinforcement learning and imitation learning training paradigms. In embodied AI, this engine trains the robot’s “brain,” connecting vision, language, and action to transform environmental feedback into decisions.
I think ray tracing gains matter for simulation fidelity, but driver maturity is the real bottleneck for production. Operationally, torch-MUSA adaptation reduces friction for teams already invested in the PyTorch ecosystem.
Why Moore Threads Fits Compute, Simulation, and Rendering into One Lambda
The production implication here isn’t just about hardware specs; it’s about eliminating the data gravity that kills iteration speed in robotics. If you can’t keep your physics engine, renderer, and AI model on the same silicon without shuffling terabytes across PCIe lanes, your training loop is already too slow for deployment.
This is where the value of a fully functional GPU becomes critical. In China, these chips are scarce, making their utility even more pronounced for teams trying to ship real-world agents.
The demands embodied AI places on chips extend far beyond standard AI matrix calculations. Robot training requires running VLA models, reinforcement learning, and imitation learning—this constitutes AI intelligent computing. It must simulate collisions, friction, dynamics, and complex contacts—this involves scientific computing and physical AI. It needs to generate sufficiently realistic training visuals and sensor data—this is 3D rendering. In the future, it will also involve extensive collection, transmission, generation, and playback of video data, which relies heavily on ultra-high-definition video codec capabilities.
TPUs, NPUs, or certain GPGPU approaches often focus on specific types of AI or general-purpose computing tasks. While they can achieve high efficiency in particular scenarios, embodied AI presents a more complex mix of challenges: it requires training digital brains, constructing physical worlds, and integrating real-world visuals and sensor feedback into the training loop simultaneously.
In practice, consolidating these stacks reduces the number of failure points in your CI/CD pipeline for model training. I think single-chip integration eliminates PCIe bandwidth bottlenecks that throttle large-scale parallel simulations. Operationally, unified architecture simplifies driver maintenance, which is a nightmare when juggling separate GPU and CPU-side physics libraries.
The underlying reason Moore Threads was able to create MT Lambda as an integrated platform combining physical simulation, rendering, and AI engines lies in its consistent adherence to the fully functional GPU roadmap since its inception.
According to Moore Threads’ definition, fully functional GPUs rely on their proprietary MUSA architecture to support AI computing, graphics rendering, physical simulation, scientific computing, and ultra-high-definition video codec within a single chip.
In other words, MT Lambda is not merely a patchwork of disjointed tools but a platform capability grown from the foundation of a fully functional GPU and the unified MUSA architecture.
For embodied AI, this integration of “compute, simulation, and rendering” aligns perfectly with the actual needs of robot training: running AI models while calculating physical collisions and rendering realistic visuals simultaneously.
In the past, developers might have needed to switch between different hardware and software stacks: one platform for AI training, another for graphics rendering, and a third tool for physical simulation. Data had to be moved across systems, leading to low efficiency, difficult debugging, and accumulated errors.
MT Lambda aims to consolidate these previously disjointed processes onto a single underlying infrastructure. For developers, the ideal state is to spend less time battling low-level adaptations and more time focusing on algorithms, tasks, and scenarios themselves.
Cloud, Edge, and Ecosystem: Closing the Loop
If MT Lambda handles the training and simulation heavy lifting, Moore Threads is now focusing on closing the loop across cloud, edge, and ecosystem components. This isn’t just about raw compute; it’s about ensuring the data flows from the cluster to the robot without breaking in transit.
The Cloud side is powered by the Kuae (KUAE) Intelligent Computing Cluster.
In the large model era, clusters were mostly seen as training foundations. In embodied AI, they act like massive robot training grounds. As simulation data scales, demand explodes:
A single robotic arm trajectory might need visuals from multiple angles, under various lighting conditions, with different materials and disturbances. Autonomous driving world models can generate vast amounts of test mileage weekly. Humanoid robot training requires extensive parallel environments for repeated trial and error…
When data hits millions or tens of millions of frames, the role of underlying computing power shifts from an accelerator to a production line.
The core acceleration units of Moore Threads’ Kuae Intelligent Computing Cluster include the MTT S5000. Based on the fourth-generation MUSA architecture “Pinghu,” the single-card AI dense computing power reaches up to 1,000 TFLOPS. It is equipped with 80GB of VRAM and a memory bandwidth of 1.6TB/s, supporting full-precision calculations from FP8 to FP64. It is also one of the few domestic GPUs that simultaneously support hardware-level ray tracing and AI training/inference.
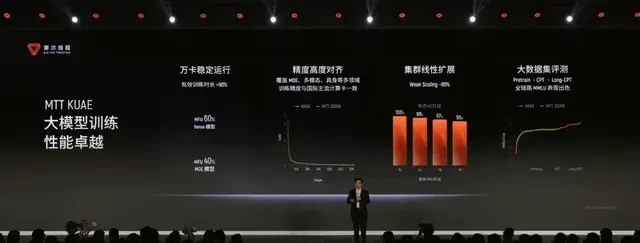
In embodied AI, these specs matter more than just FLOPs. FP8, BF16, and FP16 serve AI training and inference; ray tracing serves high-fidelity rendering; and physical simulation handles complex dynamic solutions. Embodied AI requires multiple capabilities to collaborate within the same architecture.
The Edge side consists of the Changjiang SoC and E300 AI Module.
While the cloud handles large-scale training and the simulation platform manages trial-and-error, strategies must ultimately run on the robot itself. Robots can’t always rely entirely on cloud responses in the real world. They need to perform perception, decision-making, and control locally, especially for tasks requiring low latency and high reliability. Edge computing power is a necessary component to complete this loop.
Based on Changjiang…
The MTT E300 AI module within the SoC provides 50 TOPS of local computing power, enabling direct deployment on robot terminals to support low-latency, high-reliability real-time responses. Experience trained in the cloud must be transformed into immediate reactions by edge-side modules installed on the robots themselves.
This creates a more complete closed loop: the cloud handles large-scale training and parallel simulation; MTT Lambda manages strategy development, data synthesis, and simulation verification; and the E300 AI module is responsible for executing trained results at the robot terminal.
More importantly, Moore Threads’ layout has begun entering real-world ecosystem validation.
For instance, in its collaboration with BAAI (Beijing Academy of Artificial Intelligence), RoboBrain 2.5 completed end-to-end training on an MTT S5000 cluster comprising thousands of cards. Validation results showed that the training loss curve closely matched that of H100 clusters, with a difference of only 0.62%, and it performed better in certain tasks. The cluster achieved over 90% linear scaling efficiency when expanded from 64 to 1,024 cards.
The significance of these results lies in validating the feasibility of domestic computing power clusters as the foundation for embodied AI model training.
Another example is the collaboration with Guanglun Intelligence, which focuses more on mass production of simulation data. Relying on Moore Threads’ fully functional GPUs and the Kuai’e intelligent computing cluster, combined with Guanglun Intelligence’s “solve-measure-generate” integrated simulation platform, the two parties jointly developed a high-confidence simulation data synthesis solution. Guanglun Intelligence’s high-precision GPU-based physics solver has been adapted to the MUSA architecture, supporti
In practice, 90% scaling efficiency on domestic hardware is a strong signal for production readiness over lab demos. I’d worry about the operational complexity of maintaining such a specialized closed-loop ecosystem.
Domestic GPUs Enter the Global Arena: China Launches First Full-Stack Embodied AI Simulation Platform
I read through the latest announcements from Moore Threads, and what stood out to me isn’t just the chip specs—it’s the pivot toward simulation as a critical infrastructure layer for embodied AI. We’re seeing a shift from pure compute power to physics-aware environments that can actually stress-test autonomous systems in ways real-world data simply cannot match at scale.
The platform now supports high-precision, real-time simulation of complex physical processes, including rigid bodies, soft bodies, fluids, and granular materials. In relevant test cases, the accuracy of core physical parameter simulations reached over 99%. This level of fidelity is no longer a nice-to-have; it’s becoming a baseline requirement for validating safety-critical systems before they ever touch a road or a factory floor.
I think 99% physics accuracy means fewer catastrophic edge cases in production, reducing post-deployment hotfixes.
The collaboration with Pony.ai extends these simulation scenarios directly into autonomous driving. Based on the MTT S5000 and Kuai’e intelligent computing cluster, the two parties are advancing the adaptation and verification of world model and vehicle-side model training. Pony.ai’s world model generates over 10 billion kilometers of test data weekly, deriving numerous extreme scenarios that would be impossible or too dangerous to collect in the real world. For autonomous driving, long-tail scenarios, extreme hazards, and safety validation are precisely where simulation adds the most value—and cost efficiency.
Operationally, synthetic data generation at this scale cuts testing costs by orders of magnitude compared to physical fleet testing.
Additionally, Moore Threads is working with partners such as Wuyi Vision and RayData Cloud to advance physical AI simulation systems and embodied simulation platforms. Whether it involves 4D Gaussian Splatting (4DGS) model training and inference, synthetic data generation, or the closed loop of task libraries, simulation computing, and virtual verification, these efforts essentially answer one question: Embodied intelligence cannot be developed in isolation by a single company; it requires computing power providers, simulation experts, algorithm developers, and scenario owners to collaborate and build an ecosystem.
This is another key aspect of Moore Threads’ recent launch worth noting. It has advanced the narrative from “I have a chip” to “I can build an infrastructure system.”
Building platforms upward from the underlying MUSA architecture and fully functional GPUs, connecting downward to edge devices, and horizontally expanding the ecosystem, this approach may not overnight change the industry landscape. However, it has further pushed the battlefield for domestic GPUs beyond large model training and inference into physical AI infrastructure.
In practice, full-stack control reduces vendor lock-in risk but increases internal maintenance burden for non-GPU components.
The Goal Is Domestic Embodied Intelligence Infrastructure
I read the release notes for Moore Threads’ new platform, and what stood out immediately is the shift from pure compute metrics to system-level integration. We are seeing a push to solve the “simulation gap” in embodied AI, where models advance faster than physical scenarios can support them.
The core contradiction here is clear: large models evolve rapidly through digital data, but robots struggle with real-world costs. Teleoperation is slow, equipment damage is risky, and long-tail scenarios are hard to exhaustively cover. Consequently, simulation-generated data and the Sim-to-Real closed loop have become critical infrastructure for moving embodied intelligence from laboratories to industry applications.
I think simulation latency directly impacts training throughput; if the physics engine bottlenecks, your GPU sits idle.
This is why “building worlds” has become the core proposition in the competition for embodied intelligence. The value of these virtual worlds does not lie in visual appeal for gaming purposes, but in their ability to train robots, verify robot behaviors, and correct errors. These environments must be realistic enough to reflect lighting, materials, collisions, friction, and sensor noise; efficient enough to generate data at scale through parallel processing; and open enough to allow different models, robots, and scenarios to integrate seamlessly.
From this perspective, Moore Threads’ advantage cannot be summarized by a single technical metric. Its “fully functional GPU + MUSA ecosystem” technology roadmap is naturally better suited to the composite needs of embodied intelligence.
Fully functional GPUs provide capabilities across AI computing, graphics rendering, physics simulation, scientific computing, and video encoding/decoding; MUSA offers a unified software ecosystem; MTT Lambda integrates physical engines, rendering engines, and AI engines; the Kuai’e intelligent computing cluster handles large-scale training and simulation; the Changjiang SoC and E300 AI modules bring these capabilities to the edge; and external ecosystem partners supplement data, scenarios, simulation platforms, and industry applications.
Operationally, consolidating physics, rendering, and inference on one stack reduces context-switching overhead between microservices.
The value of this chain lies in the fact that embodied intelligence is essentially a systematic engineering project. Large model companies may initially compete on building digital brains, but robot companies ultimately face the challenge of how the brain controls the body, how the body understands the environment, and how the environment can be reproduced at low cost. Whoever can build a training world for robots that is sufficiently realistic, controllable, and scalable at lower costs and higher efficiency will have a better chance of moving embodied intelligence from demos to real production lines, roads, homes, and urban spaces.
Of course, building domestic embodied intelligence infrastructure will not happen overnight. Continuous verification is needed regarding simulation realism, Sim-to-Real transfer effects, developer ecosystem maturity, and large-scale adoption by industrial clients. How far Moore Threads’ solution can go depends on feedback from subsequent real-world projects, more developers, and a wider range of robot platforms.
But at least judging from this launch event, domestic GPUs are entering a new phase. They are beginning to move beyond the passive narrative of whether they can replace specific chips, actively defining new computing scenarios: the upgraded “Xiaomai” (Little Wheat) unveiled at the event is a digital agent; the somersaulting robot dog “Xiao Fei” (Little Fly) is a physical agent. As AI moves from screens to reality, and as agents evolve from merely speaking to acting, underlying computing power must simultaneously understand models, graphics, and physics.
Zhang Jianzhong
The event highlighted the aspiration for Moore Threads’ products, ranging from the Kuae supercomputing platform to the Changjiang large model, to empower all intelligent agents. In the context of embodied AI, this statement can be articulated more concretely: the cloud hosts massive training grounds, simulation environments create virtual worlds, edge devices execute tasks via “cerebellum”-like processing, and ecosystems provide real-world scenarios.
The competition in large models hinges on who can train a more powerful digital brain. In embodied AI, the contest extends to another critical dimension: who
Domestic GPUs Enter the Global Arena: China Launches First Full-Stack Embodied AI Simulation Platform
can first build a sufficiently realistic training world.
This time, domestic GPUs have begun entering the arena to construct these worlds.
In practice, realistic simulation requires massive parallel throughput; expect significant memory bandwidth bottlenecks on consumer-grade hardware. I think if the stack isn’t optimized for heterogeneous compute, your training jobs will spend more time waiting than computing. Operationally, shipping this week means dealing with immature driver stacks and potential kernel compatibility issues across different GPU vendors.
I followed the release of China’s first full-stack embodied AI simulation platform, and what stood out to me is the shift from pure inference to complex, physics-aware training environments. For years, the narrative has been about running models; now, it’s about building the worlds those models inhabit. This isn’t just a software update—it’s an infrastructure play.
The core premise is simple but expensive: you cannot train embodied AI agents effectively in a vacuum or with low-fidelity data. You need a “sufficiently realistic training world.” Until recently, constructing these high-fidelity digital twins was the exclusive domain of well-funded labs using top-tier Western GPUs. That dynamic is changing. Domestic GPU manufacturers are no longer just chasing parity on benchmarks; they are entering the arena to construct these worlds at scale.
This move signals a maturation in the hardware ecosystem. It’s not enough to have chips that can multiply matrices quickly if they can’t handle the complex, stateful simulations required for robotics and autonomous agents. The entry of domestic GPUs into this specific niche suggests a strategic pivot toward owning the entire stack—from silicon to simulation engine.
For platform engineers, the implication is clear: the tooling landscape is fragmenting further. We are moving away from a monolithic reliance on a single hardware provider’s software ecosystem toward a more diverse, and potentially more complex, set of dependencies. The race is no longer just about who has the fastest chip, but who can provide the most stable environment for training the next generation of AI agents.
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google