I think demo slides look clean; I want to see the latency numbers under real-world load. In the field, open-sourcing weights is good, but the inference framework details matter more for adoption. What I watch for is “Native MoE” in diffusion is a bold claim that needs rigorous benchmarking against standard AR models.
The Bund Summit: Ant Group and Renmin University Unveil First Native MoE Diffusion Language Model
What actually runs in production rarely matches the polished slides at a summit. While the industry buzzes over new architectures, I’m looking for unit economics and stability, not just theoretical breakthroughs. At the 2025 Inclusion·The Bund Conference on September 11, Ant Group and Renmin University of China stepped onto that stage to unveil LLaDA-MoE. They claim it is the industry’s first native Mixture-of-Experts (MoE) architecture diffusion language model (dLLM).

(Joint release of the first MoE architecture diffusion model LLaDA-MoE by Renmin University and Ant Group)
The team asserts they completed zero-to-one training on approximately 20 trillion tokens. They say this validates the scalability and stability of industrial-grade large-scale training. The stated goal is to push dLLMs beyond their current limits, with a promise to fully open-source the model in the near future to aid the global AI community.
Challenging Autoregressive Dogma
Li Chongxuan, Associate Professor at Renmin University’s Lingling College School of Artificial Intelligence, and Lan Zhenzhong, Director of Ant Group’s General AI Research Center and Founder of Westlake Xinchen, led the launch. Their core argument challenges a fundamental tenet of modern AI: that language models must be autoregressive.
Li Chongxuan explained that current large models are “inherently unidirectional,” generating tokens sequentially from start to finish. This structure, he noted, makes it difficult for them to capture bidirectional dependencies between tokens. While some researchers have turned to diffusion language models with parallel decoding, existing dLLMs rely on dense architectures. These dense systems struggle to replicate the “parameter scaling, computation efficiency” advantages found in Mixture-of-Experts (MoE) systems within autoregressive models (ARM).
Lan Zhenzhong stated, “The LLaDA-MoE model validates the scalability and stability of industrial-grade large-scale training, marking another step forward in our journey to scale dLLMs to larger sizes.”
Performance Claims vs. Reality
According to reports, LLaDA-MoE utilizes a non-autoregressive masked diffusion mechanism. The team claims it achieves language intelligence comparable to Qwen 2.5—covering in-context learning, instruction following, code generation, and mathematical reasoning—for the first time through native MoE training on large-scale language models.
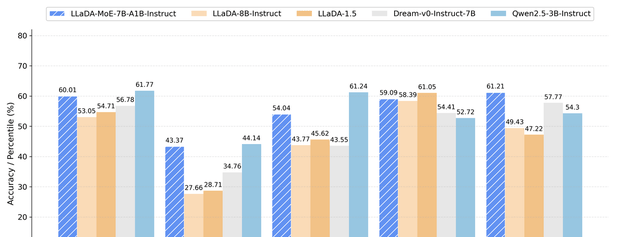
(LLaDA-MoE Performance Results)
The performance data released suggests LLaDA-MoE leads other diffusion language models like LLaDA 1.0/1.5 and Dream-7B in tasks involving code, mathematics, and agents. More critically, it approaches or surpasses the autoregressive model Qwen2.5-3B-Instruct. The team highlights that it achieves performance equivalent to a 3B dense model while activating only 1.4B parameters. This retention of a multi-fold advantage in inference speed is what usually catches my eye, though I remain skeptical until independent verification confirms these efficiency gains hold up outside controlled benchmarks.
Engineering Behind the Release
The Ant Group and Renmin University team spent three months tackling technical challenges. Building on LLaDA-1.0, they rewrote the training code and leveraged parallel acceleration technologies provided by Ant’s proprietary distributed framework, ATorch, including Expert Parallelism (EP). Utilizing training data based on Ant’s Ling 2.0 foundation model, the team achieved breakthroughs in core issues such as load balancing and noise sampling drift.
Ultimately, they completed efficient training on approximately 20 trillion tokens using a 7B-A1B MoE architecture (totaling
The Economics of Sparse Activation
I think 1.4 billion active parameters on a 7B model sounds efficient until you factor in the memory bandwidth cost of sparse routing. In the field, benchmarks are nice, but I want to see latency under concurrent load before trusting this “unified framework.” What I watch for is matching Qwen2.5-3B is a high bar; most open-source clones fail to replicate that stability.
The numbers from Ant Group’s release are precise: 7 billion total parameters with only 1.4 billion activated at any given time. Under their proprietary unified evaluation framework, LLaDA-MoE achieved an average improvement of 8.4% across 17 benchmarks, including HumanEval, MBPP, GSM8K, MATH, IFEval, and BFCL. It outperformed LLaDA-1.5 by 13.2% and matched the performance of Qwen2.5-3B-Instruct. These experiments further validate that the “MoE Amplifier” law holds true in the dLLM domain, providing a viable path for subsequent sparse models ranging from 10B to 100 billion parameters.
The Engine Behind the Weights
I think an inference engine optimized for parallel characteristics is where the real unit economics live, not just the model weights. In the field, claiming significant acceleration over NVIDIA’s fast-dLLM requires transparent profiling data I haven’t seen yet.
According to Lan Zhenzhong, alongside the model weights, Ant will simultaneously open-source an inference engine deeply optimized for the parallel characteristics of dLLMs. Compared to NVIDIA’s official fast-dLLM, this engine delivers significant acceleration. The related code and technical reports will be published on GitHub and the Hugging Face community in the near future.
AGI as a Highway, Not a Destination
What I watch for is treating diffusion models as a “main highway” ignores the current reliability gaps compared to autoregressive systems. I think collaboration with academia is good; I just hope it doesn’t delay practical deployment for another two years.
Lan Zhenzhong also revealed that Ant will continue to invest in AGI fields based on dLLMs. In the next phase, they will collaborate with academia and the global AI community to drive new breakthroughs in AGI. “Autoregression is not the end; diffusion models can equally become a main highway toward AGI,” Lan stated.
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google