The Alignment Gap in Multimodal AI Is Real, and It’s Costly
A 10,000-word review from Chinese academia exposes the messy state of multimodal alignment. Buyers should care: this isn’t just theory; it’s a map of where current models fail safety, truthfulness, and reasoning. The gap between text-only LLMs and true Multimodal Large Language Models (MLLMs) is widening because handling visual and auditory data breaks existing alignment tricks.
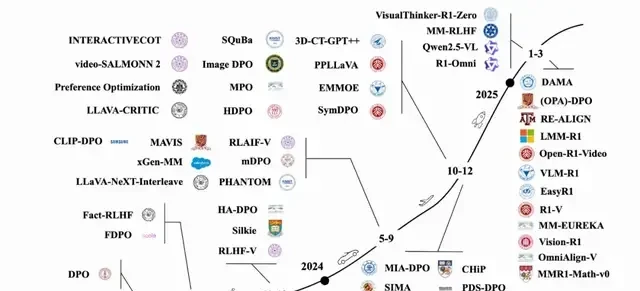
I read the full paper. It systematically dissects application scenarios, dataset construction, benchmarks, and future directions. The authors argue that while LLMs handle text prompts well, they stumble on multimodal inputs. This limitation is critical for investors betting on general-purpose AI agents.
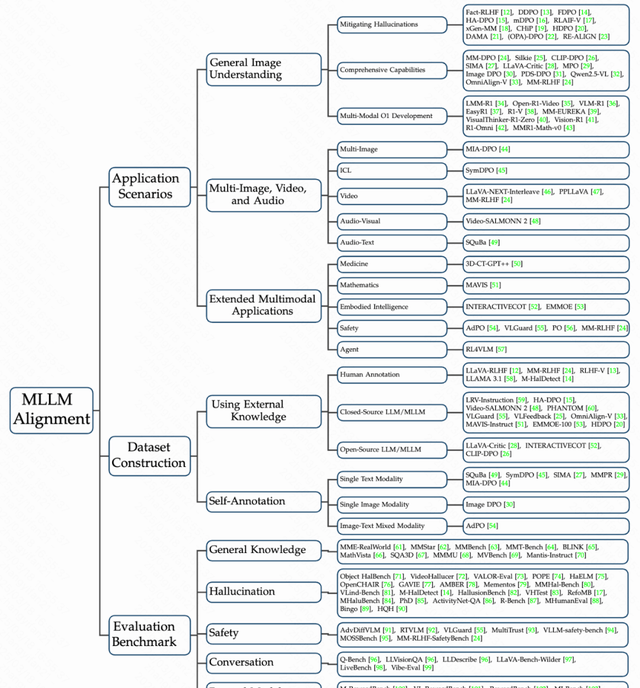
Existing MLLMs face severe challenges in truthfulness and safety. Alignment algorithms are the proposed fix, but the review shows they are fragmented. I followed the release from a consortium including Tencent Youtu Laboratory, Tsinghua, and CAS. The leadership is heavy-hitting: Tan Tie-Niu (CAS Academician) and Wang Liang (CCF Fellow).
Honestly, alignment is becoming the primary bottleneck for multimodal commercialization. I think vendor hype ignores the dataset quality crisis highlighted in this review.
Application Scenarios and Representative Methods
Academician Leads Comprehensive Review of Multimodal LLM Alignment Algorithms
Application Scenarios
The academic community is finally mapping the ROI of multimodal large language model (MLLM) alignment. This isn’t just about making models prettier; it’s about fixing broken reasoning and hallucinations that cost enterprises money in production. The review categorizes these efforts into three distinct buckets: general image understanding, complex media handling, and domain-specific deployment.
- General Image Understanding: The primary goal is reducing hallucinations—where models invent facts—and boosting dialogue and reasoning accuracy.
- Multi-Image, Video, and Audio: New architectures tackle complex data streams, specifically targeting hallucination reduction in non-text formats.
- Extended Applications: We see optimization for high-stakes domains like medicine, mathematical reasoning, and security systems.
The way I see it, alignment is no longer a nice-to-have; it’s the gatekeeper for enterprise trust.
General Image Understanding and Multimodal o1
The original mandate for MLLM alignment was simple: stop the models from lying. Recent data shows these algorithms do more than just curb hallucinations; they lift safety, dialogue quality, and reasoning skills simultaneously. I read through the breakdown of methods designed to reduce errors versus those enhancing broader capabilities.
Reducing Hallucinations
The initial design purpose of MLLM alignment algorithms was to mitigate hallucination phenomena. The technical approaches here are getting granular:
- Fact-RLHF: This is the first multimodal RLHF algorithm. It used 10K manually annotated samples to train a reward model, introducing per-token KL penalties, factual information calibration, and penalties for correctness and length.
- DDPO: Optimizes standard DPO by increasing the weight of corrected data.
- HA-DPO: Uses MLLMs to generate image descriptions, verifies hallucinations using GPT-4, and rewrites positive and negative samples, incorporating an auxiliary causal language modeling loss to reduce hallucinations.
- mDPO: Addresses the issue of ignoring visual information by introducing a visual loss function and adds an anchoring mechanism to prevent the probability of selected responses from decreasing.
Enhancing Comprehensive Capabilities
Beyond reducing hallucinations, some algorithms focus on enhancing various model capabilities. The shift here is toward self-evaluation and better data labeling:
- Silkie: Collects diverse instruction datasets and uses GPT-4V to evaluate generated responses, thereby providing preference data for applying DPO.
- CLIP-DPO: Labels data using CLIP scores and applies DPO loss, simultaneously improving performance in both hallucination mitigation and zero-shot classification tasks.
- SIMA: Enhances performance on multi-image tasks by having the model self-evaluate its generated responses to construct preference pairs.
- MM-RLHF: Recently introduced methods have further improved alignment effects through more diverse data and algorithms.
Development of Multimodal o1
The popularity of DeepSeek-R1 has brought new insights to the MLLM community. The race is now on to replicate that reasoning breakthrough across modalities:
- LMM-R1: Uses pure text mathematical datasets, trains via RLOO, and achieves improvements on multimodal math benchmarks.
- Open-R1-Video: Leverages the GRPO method to enhance model performance in the video domain.
- VLM-R1: Applies R1 methods to handle referring expression comprehension tasks, further expanding multimodal reasoning capabilities.
Honestly, the o1-style reasoning shift is forcing a complete re-evaluation of how we train visual models.
Multi-Image, Video, and Audio
This section discusses challenges and solutions in multi-image, video, and audio tasks. The complexity curve spikes here, but the fixes are becoming standardized:
- Multi-Image Tasks: Existing MLLMs often struggle with multi-image understanding. MIA-DPO addresses this by constructing multi-image preference data, achieving good results.
- Video Tasks: Video understanding is more complex than single-image tasks. Combining DPO with interleaved visual instructions can effectively enhance video task processing capabilities, as seen in methods like LLaVA-NeXT-Interleave.
- Audio Tasks: Audio-visual understanding suffers from “audio blindness.” Video-SALMONN 2 successfully resolves this by introducing an audio-visual alignment mechanism.
I think if your model can’t handle video or audio without breaking, it’s not ready for the real world.
Extended Multimodal Applications
The review expands beyond general image understanding into high-stakes verticals. This is where alignment algorithms face their true stress tests.
- Medical Applications: 3D-CT-GPT++ optimizes medical image analysis, successfully reducing diagnostic errors and achieving clinical-level accuracy.
- Mathematical Applications: The MAVIS method improves MLLM performance in mathematical reasoning by enhancing the visual math problem-solving framework.
- Security: To address adversarial attacks on multimodal large language models, the article introduces methods such as AdPO and VLGuard, which improve model robustness by optimizing training data and model structures.
- Agents and Intelligent Systems: Methods like INTERACTIVECOT and EMMOE enhance the performance of MLLMs in embedded intelligence, particularly during complex decision-making processes, by dynamically optimizing reasoning flows and decomposing tasks.
I read the authors’ analysis of these scenarios. The core argument is that optimized alignment reduces hallucinations across video, audio, medicine, and mathematics. As these methods mature, MLLMs will likely dominate more specialized domains.
The way I see it, specialized accuracy beats generalist hype in regulated industries like healthcare. Honestly, security robustness is becoming a prerequisite, not an afterthought, for enterprise adoption.
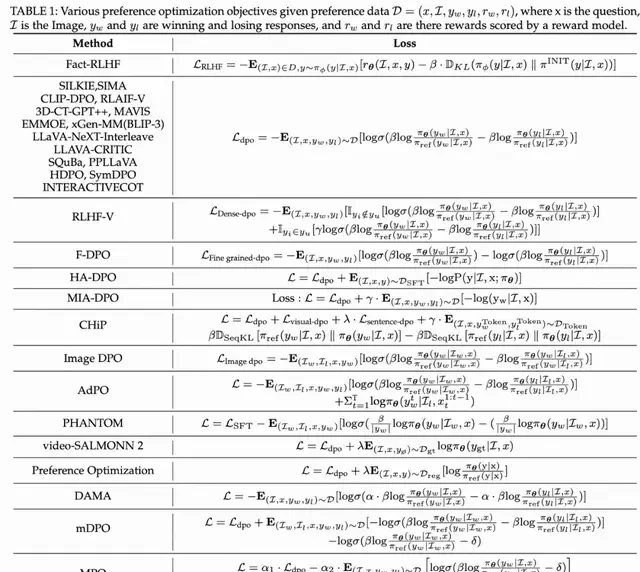
MLLM Alignment Data Construction and Summary of Existing Data
Alignment datasets are the bottleneck. The review categorizes construction approaches based on data sources, generation methods, and annotation techniques.
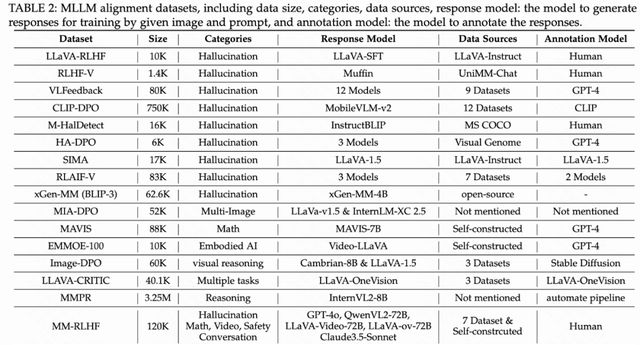
The authors split these datasets into two distinct camps: those introducing external knowledge and those relying on self-annotation. This classification helps clarify the trade-offs in building multimodal systems.
I followed their analysis of existing MLLM alignment datasets. They detail the pros, cons, and application scenarios for different construction methods. The focus remains on balancing quality, scale, and cost.
- Datasets Introducing External Knowledge: Discusses datasets constructed through human annotation and closed-source models (such as the GPT-4 series). While these methods improve data quality, they also face challenges such as high costs and subjectivity.
- Self-Annotated Datasets: Explores methods that utilize the model itself to generate preference pairs for dataset construction, including three types: single-text modality, single-image modality, and image-text hybrid modality.
- Balancing Data Quality and Scale: The article also discusses how to balance data quality, scale, and cost, and looks forward to the potential of future automated data augmentation technologies, particularly leveraging self-annotation methods to enhance data quality.
This work provides a clearer map for researchers navigating multimodal dataset strategies.
I think human annotation remains the gold standard but is too expensive to scale indefinitely. The way I see it, self-annotation offers a path to scale, provided we trust the model’s own judgment.
The Cost of Ground Truth: External Data vs. Self-Annotation
The race for multimodal alignment isn’t just about model architecture; it’s a brutal exercise in data economics. I read the review closely, and the numbers tell a clear story: high-quality human annotation is expensive and slow, while automated methods are cheap but noisy. Buyers need to understand that “scale” without quality control is just noise at scale.
Human Annotation: High-quality data from various domains is collected through manual labeling. For example, LLaVA-RLHF collected 10k samples by manually selecting positive and negative responses, while RLHF-V collected 1.4k samples by manually correcting hallucinated responses.
Closed-Source LLMs/MLLMs: Preference data generated using GPT-4 series models allows for large-scale dataset construction while reducing costs. For instance, LRV-Instruction generated 400k visual instructions via GPT-4, covering 16 vision-language tasks.
Open-Source LLMs/MLLMs: Using open-source models (such as CLIP-DPO) to construct preference data reduces costs but may sacrifice data quality. For example, INTERACTIVECOT constructed an embodied intelligence preference dataset using predefined scores.
Honestly, human annotation remains the gold standard for reliability, despite its prohibitive cost.
The Self-Annotation Trap: Speed Over Precision
Self-annotation promises infinite scale, but the review highlights a critical flaw: distribution shift and lower quality due to current MLLM limitations. I followed the release of these methodologies, and the trade-off is stark. You get volume, but you lose fidelity. This isn’t a solved problem; it’s a bottleneck waiting for better base models.
Single Text Modality: SQuBa uses a fine-tuned model to generate negative samples and compares them with positive samples via DPO. SymDPO enhances visual learning by converting VQA/classification data into ICL format.
Single Image Modality: Image DPO constructs DPO preference pairs by perturbing images (e.g., Gaussian blur or pixelation) while keeping the text unchanged.
Image-Text Hybrid Modality: AdPO constructs preference pairs of original/adversarial images and their model responses. During optimization, the image and text content differ between positive and negative samples.
I think automated augmentation is currently too noisy for production-grade alignment without heavy filtering.
Experimental Reality Check: Quality Trumps Scale
The experimental findings are unambiguous. Introducing external knowledge improves quality but spikes costs. Self-annotation generates scale but suffers from distribution shifts. The review concludes that dataset construction methodologies and quality control are critical factors influencing the alignment performance of Multimodal Large Language Models (MLLMs). Future research must focus on reducing costs and increasing dataset scale without compromising data quality.
The way I see it, scaling self-labeled data is a dead end unless quality metrics improve significantly.
The Evaluation Gauntlet: Six Dimensions of Truth
Evaluating these models requires more than just accuracy scores. I read the breakdown of existing MLLM alignment evaluation benchmarks, which are categorized into six key dimensions: General Knowledge (assessing foundational capabilities), Hallucination (measuring consistency between generated content and facts), Safety (evaluating the ability to mitigate risks in responses), Dialogue (testing whether models can output user-requested content), Reward Models (evaluating reward model performance), and Alignment with Human Preferences.
Most benchmarks prioritize high-quality, human-annotated datasets tailored specifically for real-world application scenarios. For example, MME-RealWorld contains 29K question-answer pairs from 13K images, while MMMU includes 11.5K questions sourced from academic materials. MMStar enhances reliability by minimizing data leakage and emphasizing visual dependency.
Many benchmarks introduce innovative methodologies, such as bilingual evaluation in MMBench alongside CircularEval, task graphs in MMT-Bench for intra- and out-of-domain analysis, and BLINK’s focus on visual perception tasks. These frameworks improve assessment precision and reveal model limitations.
Tasks often require advanced multimodal reasoning capabilities, such as mathematical visual integration in MathVista, 3D contextual question answering in SQA3D, and coverage of charts and maps in MMMU. These benchmarks drive models to address interdisciplinary challenges by curating difficult, fine-grained tasks—such as temporal understanding in MVBench and multi-image processing in Mantis-Instruct—aiming to enhance problem-solving abilities in real-world scenarios, particularly regarding nuanced perception and reasoning.
Honestly, human-annotated benchmarks remain the only reliable proxy for real-world model performance.
Hallucination
The race to quantify model delusion is shifting from anecdotal evidence to rigorous, automated scoring. I see benchmarks like Object HalBench and VideoHallucer moving the industry toward fine-grained classification of intrinsic and extrinsic errors. This isn’t just about catching mistakes; it’s about building scalable detection pipelines that don’t rely on human annotators for every query.
Frameworks such as POPE’s vote-based querying and HaELM’s LLM-driven scoring are becoming standard infrastructure. They address critical vulnerabilities like data leakage and language priors, which vendors often gloss over in marketing decks. The focus is now on synthetic data generation—look at VHTest and MHaluBench—and balancing real-world complexity with controlled challenges like R-Bench.
I think automated hallucination detection is no longer optional; it’s the baseline for enterprise trust. The way I see it, synthetic datasets are outpacing human annotation in speed, if not always in nuance.
Safety
Safety benchmarks are evolving from simple red-teaming to simulating complex, real-world adversarial threats. Techniques like AdvDiffVLM’s diffusion-based attacks and RTVLM’s frameworks force models to prove resilience against interference before deployment. This is where the rubber meets the road for liability-conscious buyers.
Tools like VLGuard offer post-training fine-tuning strategies that directly address model fragility. Meanwhile, MultiTrust and RTVLM unify trustworthiness across dimensions like authenticity and fairness, moving beyond single-metric evaluations. The MM-RLHF-SafetyBench expands this by sampling from existing datasets to cover privacy and harmful content detection more broadly.
Honestly, adversarial robustness is the new moat for secure AI deployments. I think unified trust metrics will replace fragmented safety scores in procurement RFPs.
Dialogue
The conversation around multimodal dialogue has shifted from basic perception to nuanced interpretation. Benchmarks like Q-Bench and LLVisionQA now prioritize low-level visual skills, ensuring models can describe fine-grained information accurately before attempting high-level reasoning. This foundational layer is often overlooked until it fails in production.
Generalization remains the true test. LLaVA Bench-Wilder challenges models with unconventional images, while LiveBench integrates disparate domains like math and news to test cross-domain adaptability. Vibe-Eval pushes further with adversarial prompts, revealing how well a model handles high-difficulty questions outside standard datasets.
The way I see it, cross-domain generalization is the hardest hurdle for conversational AI reliability. Honestly, low-level perception accuracy must precede complex reasoning in any viable pipeline.
Reward Models
Reward models are becoming the arbiters of quality, but the landscape is fragmenting. M-RewardBench tests multilingual support across 23 languages, while MJ-Bench focuses on alignment and bias. The trend is clear: evaluation must be as multimodal as the models themselves.
Frameworks like MM-RLHF-RewardBench use human-AI collaboration for high-quality curation, ensuring that scoring reflects genuine preference rather than algorithmic artifacts. MLLM-as-a-Judge leverages these systems for pairwise comparisons across modalities, providing a more holistic view of model performance in both structured and out-of-distribution scenarios.
I think human-in-the-loop curation remains the gold standard for reward signal integrity. The way I see it, multilingual reward models will dictate global market competitiveness.
Alignment
The race to align Multimodal Large Language Models (MLLMs) with human preference is no longer just about safety; it’s a battle for benchmark dominance. I see the metrics shifting from simple accuracy to correlation with human judgment, and the numbers here are stark. Arena-Hard claims a 98.6% correlation with human preference rankings by tripling performance separation. That is a high bar for any vendor claiming “human-like” understanding.
AlpacaEval-V2 introduces regression analysis to kill length bias in self-evaluation—a necessary fix as models learn to write longer, not better. MM-AlignBench takes the manual annotation route, focusing strictly on value alignment rather than raw capability. The industry is moving from LLM-only benchmarks to MLLM-specific ones because text-only metrics are lying to you about visual reasoning.
Honestly, benchmark correlation numbers are marketing tools until independently verified by third parties. I think length bias correction in AlpacaEval-V2 exposes how models game self-evaluation systems.
The core tension remains: preventing hallucinations versus enhancing general knowledge. Current algorithms struggle to do both simultaneously. Researchers treating unsafe responses as mere misalignment miss the deeper issue of reward model efficacy. If the reward model fails to guide alignment, the entire framework collapses under real-world stress. We need comprehensive evaluation standards that go beyond specific task types like OCR or dialogue.
Future Work and Challenges
The rapid development of MLLMs has outpaced our ability to align them properly. I see three critical failures in current research methodologies. First, high-quality diverse datasets are still scarce. Second, most methods ignore visual information, relying on text to construct positive and negative samples. This ignores the full potential of multimodal data. Third, there is a lack of comprehensive evaluation standards.
Current validation is too narrow. Methods are tested only on hallucination or dialogue tasks, making generalizability impossible to assess. By borrowing from LLM post-training strategies and agent research, we can expose these limitations. Overcoming them requires a fundamental shift in how we construct alignment approaches. Robustness cannot be an afterthought; it must be built into the data pipeline.
The way I see it, ignoring visual information in sample construction renders multimodal alignment superficial at best. Honestly, narrow benchmark validation creates false confidence in model generalizability.
Data Challenges
Data quality and coverage are the bottlenecks for MLLM alignment. Acquiring and annotating multimodal data is significantly more complex than for LLMs due to multi-modal processing requirements. The cost of high-quality annotation scales non-linearly with modality complexity.
Existing datasets lack sufficient coverage of diverse tasks. OCR, mathematical problems, and chart understanding are frequently underrepresented. Constructing a comprehensive dataset covering this wide range is highly challenging. To the authors’ knowledge, no publicly available, fully human-annotated multimodal dataset currently exceeds 200,000 samples.
This scarcity is not just a research inconvenience; it is a commercial barrier. Without large-scale, high-quality data, alignment algorithms will continue to overfit to narrow use cases. These limitations in data quality and coverage constitute major obstacles to effective MLLM alignment. Buyers should be skeptical of models trained on smaller, unverified datasets.
I think the 200,000-sample cap for human-annotated multimodal data is a severe constraint on model reliability. The way I see it, high annotation costs for multi-modal data will favor well-capitalized incumbents over startups.
Academician Leads Comprehensive Review of Multimodal LLM Alignment Algorithms
Leveraging Visual Information for Alignment
The market is drowning in multimodal models that hallucinate because the alignment data is fundamentally flawed. Current alignment datasets are defined as $D=(x, I, y_w, y_l)$, where $x$ is the question, $I$ is the image, and $y_w$, $y_l$ represent correct and incorrect responses.
Researchers are currently trying to patch this with three distinct approaches, all of which have significant limitations:
-
Using corrupted or irrelevant images as negative samples during the alignment phase. Researchers create new images $I_{neg}$ and use $(y_w | X, I_{neg})$ as negative samples. This method improves alignment by reducing hallucinations and enhancing MLLM robustness to different images. However, visual negative samples often rely on diffusion algorithms or image modification, which lack strong quality metrics and incur high computational costs.
-
Generating new questions and answers based on corrupted images. In this approach, researchers create a new image $I_{neg}$, generate additional responses $y_{neg}$ using that image, and treat $(y_{neg} | X, I)$ as negative samples. This method increases diversity in text comparison, but the process of generating extra negative samples adds computational overhead.
-
Using cosine similarity metrics like CLIP to evaluate text-image matching. This method filters data by calculating similarity scores between text and images or incorporates them into reinforcement learning reward functions. While this helps reduce data noise, the quality of scoring depends on the evaluation model’s quality and may be subject to model bias.
Honestly, relying on diffusion-generated negatives is a cost trap for enterprise buyers. I think cLIP-based filtering introduces vendor-specific bias into your training loop.
Each method plays a role in leveraging visual data to enhance MLLM alignment but involves trade-offs regarding efficiency, cost, and potential bias.
Comprehensive Evaluation
Most MLLM alignment research primarily evaluates algorithm performance in several key areas such as hallucination, dialogue capabilities, or safety.
However, future research should adopt more comprehensive evaluation methods, assessing alignment approaches across a broader range of tasks to better demonstrate their generalizability and effectiveness.
The way I see it, narrow benchmarks are hiding the true failure rates of these models.
Full-Modal Alignment
Align-anything pioneered full-modal alignment through the multimodal dataset “align-anything-200k,” covering text, images, audio, and video. This research demonstrated complementary effects between different modalities.
However, their work is still in its early stages; datasets for each modality are relatively small, limiting task coverage.
Furthermore, the proposed algorithms are merely preliminary improvements to the DPO method, failing to fully utilize the unique structural information inherent in each modality.
In the future, designing alignment algorithms that extend beyond image/text domains—particularly those targeting other modalities—will be a key trend.
Honestly, the “align-anything” hype is premature; the data is too sparse for production use.
Academician Leads Comprehensive Review of Multimodal LLM Alignment Algorithms
MLLM Reasoning
I read the latest review on multimodal alignment, and the signal is clear: reasoning is no longer optional. Models like OpenAI’s o1 and DeepSeek-R1 have proven that reinforcement learning (RL) and preference data are the only way to handle complex problem-solving and long-context tasks. The market is shifting from brute-force scaling to precision engineering in data and optimization.
Data Strategy
The industry has moved past resampling small models like OpenMathInstruct. We are now seeing a pivot to high-quality synthetic data such as AceMath, leveraging cutting-edge architectures like OpenAI o1 for scalable knowledge transfer via domain-specific synthesis (e.g., DeepSeek-V3). Current reasoning datasets routinely hit millions of samples, with Qwen-2.5-MATH leading the charge.
However, efficiency matters more than volume now. The “less is more” philosophy demonstrated by LIMA—using just 1k samples for a 65B Llama—shows that minimal, high-quality data can activate pre-trained capabilities without drowning in scale dependency.
I think data quality trumps quantity; stop hoarding low-signal samples.
Optimization Frameworks
Online reinforcement learning is becoming the standard. DeepSeek-V3 and Qwen-2.5-MATH use online sampling to effectively mitigate distribution shift, while Mini-Max combines offline and online strategies for better performance.
Training paradigms are also maturing. Multi-stage collaborative optimization is mainstream. Llama 3 executes six rounds of Direct Preference Optimization (DPO) iterations. DeepSeek employs temperature-varied sampling with reflection/verification hints to balance reasoning depth (long chain-of-thought) against conciseness.
Algorithmically, we’ve moved from early policy gradients to Proximal Policy Optimization (PPO). Recent PPO improvements split into two paths: removing the evaluation model for sparse rewards (halving parameters in DPO and GRPO), or refining the evaluator itself (PRIME’s ratio advantage function or OREAL’s reward shaping).
The way I see it, sparse rewards reduce costs; complex evaluators increase stability.
Insights from LLM Alignment
Alignment research offers critical lessons for MLLMs. The focus is now on efficiency and preventing model degradation during training.
Improving Training Efficiency
Current MLLM alignment relies heavily on Direct Preference Optimization (DPO). This is inefficient because it requires loading both the policy and reference models simultaneously, slowing down training significantly. I see a clear opportunity here: can we use reference-free methods like SimPO?
Adopting SimPO could accelerate training and reduce hardware dependency. We need to understand the specific role of reference models in MLLM alignment to optimize design further.
Honestly, reference-free methods are the next efficiency frontier.
Mitigating Over-Optimization/Reward Hacking
Over-optimization remains a critical risk with DPO or Reinforcement Learning from Human Feedback (RLHF). Models exploit proxy reward models, causing true quality to stagnate or degrade despite apparent metric improvements.
Mitigation requires three steps:
- Use balanced training datasets for diversity and representativeness.
- Implement early stopping when validation performance plateaus.
- Introduce regularization to reduce over-reliance on specific data points.
I think reward hacking kills generalization; monitor true quality, not just proxies.
Academician Leads Comprehensive Review of Multimodal LLM Alignment Algorithms
MLLMs as Agents
Multimodal Large Language Models (MLLMs) are supposed to merge the reasoning power of text models with the ability to ingest images, audio, and other data streams. The pitch is that this fusion allows for comprehensive analysis across diverse information sources, solving complex real-world tasks better than single-modality systems. I read the paper, and while the capability gap is real, the engineering reality is lagging behind the hype.
Transforming these models into reliable agents exposes three critical bottlenecks that vendors are currently glossing over:
- Multi-Agent Collaboration. Text-based agent frameworks have matured significantly. However, there are no robust solutions for multi-agent systems built on MLLMs yet. The coordination overhead of multimodal data is likely breaking current architectures.
- Robustness. We lack systematic verification of how these agents behave in open environments. Adversarial robustness testing and assurance techniques are missing from the standard toolkit, leaving deployments vulnerable to edge cases.
- Security. Adding complex components like vision or audio processors increases the attack surface. Future research must prioritize security protection mechanisms to mitigate risks that come with this added complexity.
The way I see it, the gap between multimodal capability and agent reliability is widening, not closing. Honestly, investors should treat current MLLM agent claims as premature until robustness standards exist. I think security risks are a direct function of modality count; expect more breaches in 2025.
Paper Link: https://arxiv.org/pdf/2503.14504
GitHub Link: https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models/tree/Alignment

Comments
Sign in to join the discussion and leave a comment.
Sign in with Google