Agent Hype Explodes: A Comprehensive Review to Streamline Your Learning | From East China Normal University & Donghua University
The surge in generative AI agent capabilities has outpaced governance frameworks, leaving enterprises to navigate a complex landscape of optimization strategies without clear compliance guardrails. This shift places the burden of proof squarely on organizations to verify whether their chosen agent architectures—whether parameter-driven or free—meet rigorous safety and accountability standards. As research from East China Normal University and Donghua University highlights, the distinction between fine-tuning models and engineering prompts is no longer just technical; it is a critical governance decision.
A research team from East China Normal University and Donghua University has published “A Survey on the Optimization of Large Language Model-based Agents,” providing a comprehensive review and analysis of LLM agent optimization strategies from a systematic perspective for the first time.
The paper categorizes existing methods into two main types: parameter-driven optimization and parameter-free optimization.
The former includes supervised fine-tuning, reinforcement learning (such as PPO, DPO), and hybrid strategies combining fine-tuning with RL, focusing on key modules such as trajectory data construction, reward function design, and optimization algorithms.
The latter involves optimizing agent behavior without modifying model parameters through methods like prompt engineering, external tool invocation, and knowledge retrieval.

In addition, the authors compiled mainstream agent fine-tuning and evaluation datasets and reviewed representative practices of LLM agents in various application fields such as healthcare, science, finance, and programming.
Finally, the research team summarized the key challenges facing agents today and future research directions.

Why Do We Need to Specifically Optimize LLM Agents?
In recent years, large language models such as GPT-4, PaLM, and DeepSeek have not only excelled in language understanding and generation but also demonstrated extraordinary capabilities in reasoning, planning, and complex decision-making.
Therefore, an increasing number of researchers are beginning to attempt using LLMs as agents, exploring their potential in automatic decision-making and the direction of general artificial intelligence.
Unlike traditional reinforcement learning agents, LLM agents do not rely on explicit reward functions; instead, they complete complex tasks through natural language instructions, prompt templates, and in-context learning (ICL).
This “text-driven” agent paradigm exhibits high flexibility and generalization capabilities, enabling cross-task understanding of human intent, execution of multi-step operations, and decision-making in dynamic environments.
Currently, researchers have attempted to improve performance through task decomposition, self-reflection, memory enhancement, and multi-agent collaboration, with application scenarios covering software development, mathematical reasoning, embodied intelligence, web navigation, and other fields.
It is worth noting that the training objective of LLMs themselves is next-token prediction, not designed for agent tasks involving long-term planning and interactive learning.
This leads to several challenges when using LLMs as agents:
- Insufficient long-horizon planning and multi-step reasoning capabilities, leading to cumulative errors in complex tasks;
- Lack of persistent memory mechanisms, making it difficult to reflect and optimize based on historical experience;
- Limited adaptability to new environments, struggling to dynamically respond to changing scenarios.
In particular, open-source LLMs generally lag behind closed-source models like GPT-4 in agent tasks. The high cost and opacity of closed-source models have made optimizing open-source LLMs to enhance agent capabilities a key research need.
Existing surveys either focus solely on large model optimization or discuss only local agent capabilities (such as planning, memory, or role-playing), failing to treat “LLM agent optimization” as an independent and systematic research direction for in-depth exploration.
The research team fills this gap by conducting the first systematic review centered on “optimization technologies for LLM-based agents,” constructing a unified framework, summarizing methodological paths, and comparing the pros, cons, and applicable contexts of different techniques.
I think parameter-free methods offer faster deployment but lack the deep behavioral alignment that fine-tuning provides. My sense is enterprises must audit open-source agents rigorously, as they often inherit unverified biases from base models. What concerns me is that the opacity of closed-source models makes external compliance verification nearly impossible for regulated industries.
Parameter-Driven Optimization of LLM Agents
In parameter-driven LLM optimization, the authors divide it into three directions.
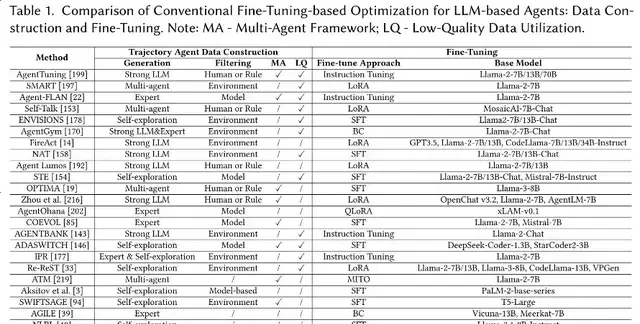
Optimization Based on Conventional Fine-Tuning
The first direction in agent optimization relies on conventional fine-tuning. This process is bifurcated into two critical steps: constructing high-quality trajectory data for agent tasks, followed by using those trajectories to fine-tune the model.
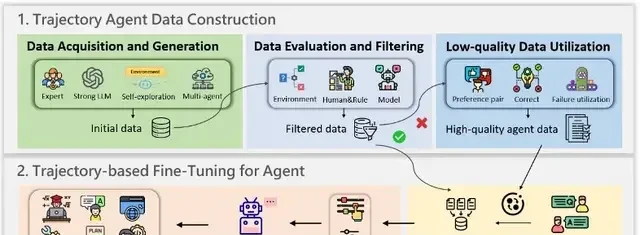
Data Acquisition and Generation
Constructing high-quality trajectory data begins with the acquisition and generation of initial data. This requires not only a diverse set of trajectories but also sufficient alignment with target tasks to ensure effective learning. The authors categorize mainstream methods into four types:
- Expert-annotated data: Manually designed by human experts, offering high quality and strong alignment; it serves as the gold standard for fine-tuning. However, due to high labor costs and scalability issues, it is often used as a supplementary dataset of high-quality examples.
- Data automatically generated by powerful LLMs: Utilizes large models like GPT-4 combined with ReAct or Chain-of-Thought (CoT) strategies to generate trajectories. It is efficient and suitable for large-scale construction but relies heavily on large models, leading to issues such as high costs and bias propagation.
- Data from autonomous agent exploration: Generated by open-source models interacting autonomously with the environment. It is low-cost and helps break free from closed-source dependencies. The drawback is limited exploration capability, requiring subsequent filtering mechanisms to remove low-quality data.
- Data generated through multi-agent collaboration: Involves multiple Agents collaborating to complete complex task workflows, enhancing data diversity and interaction complexity. However, this approach increases system design complexity, posing challenges in stability and resource costs.
I think expert annotation remains the compliance gold standard despite its cost. Relying on GPT-4 for generation introduces bias risks that enterprises must audit. Open-source exploration reduces vendor lock-in but demands rigorous quality control. Multi-agent systems offer diversity but complicate liability attribution.
Data Evaluation and Filtering
Since the quality of generated trajectory data varies significantly, evaluating and filtering the data has become an indispensable step. The authors categorize mainstream methods into three types:
- Environment-based evaluation: These methods rely on external feedback such as task success or environmental rewards to judge trajectory quality. They are easy to implement and highly automated. However, their drawback is that the feedback signals are too coarse-grained, focusing only on final outcomes and failing to detect implicit errors in the reasoning chain.
- Human- or rule-based evaluation: This approach employs preset rules (such as task completion rate, answer consistency, diversity, etc.) or expert manual review for more fine-grained quality control. It offers strong adaptability and high accuracy but requires significant human involvement and complex design.
- Model-based evaluation: Leveraging powerful LLMs (e.g., GPT-4) to automatically score and analyze trajectories allows for multi-dimensional assessment across relevance, accuracy, and completeness, building an automated quality evaluation framework. The downside is that the evaluation itself relies on models, which may introduce new biases.
My sense is coarse-grained environmental rewards often mask subtle reasoning failures. Human-in-the-loop review remains essential for high-stakes governance. Model-based scoring risks perpetuating the very biases it aims to detect.
Utilization of Low-Quality Samples
Beyond acquiring high-quality data, it is also necessary to repurpose substandard low-quality trajectories. Current mainstream strategies include:
- Contrastive utilization: By comparing correct and incorrect samples, the model can more clearly identify which behaviors are effective.
- Error-correction methods: Identifying and correcting failed trajectories transforms them into learnable data, thereby improving training quality.
- Direct use of error samples: Instead of correction, failing cases are used directly to train the model, enhancing its fault tolerance when facing erroneous situations.
The Fine-Tuning Phase
After constructing high-quality trajectory data, the next step is the critical fine-tuning phase. Through fine-tuning, open-source large models truly adapt to Agent tasks; learning planning, reasoning, and interaction is an indispensable step in optimizing LLM agents.
Notably, fine-tuning solely with Agent task trajectories may weaken the general capabilities of LLMs. Therefore, most approaches choose to train on a mix of general instruction data and Agent trajectories, aiming to enhance Ag
Refining Agent Capabilities: The Fine-Tuning Landscape
What concerns me is that full-parameter SFT remains the gold standard for alignment, but it is resource-intensive. I think parameter-efficient methods like LoRA offer a pragmatic balance for enterprise budgets. My sense is custom strategies are necessary only when general models fail specific compliance or safety constraints.
The authors categorize existing fine-tuning methodologies into three distinct buckets, each carrying different implications for governance and deployment costs.
Standard Supervised Fine-Tuning (SFT) This approach optimizes the model’s full parameters using high-quality instruction-output pairs or trajectory data. It achieves the strongest alignment with target tasks. Behavior cloning in imitation learning essentially falls under this category, emphasizing the learning of decision strategies from expert trajectories. While effective, it demands significant computational resources and careful audit trails to ensure the “expert” data does not encode bias.
Parameter-Efficient Fine-Tuning (PEFT) Methods such as LoRA or QLoRA update only a small subset of parameters while keeping other weights frozen. This significantly reduces VRAM usage and computational overhead, making it particularly common for fine-tuning large model Agents. Although training costs are lower compared to full-parameter fine-tuning, performance often matches or even exceeds it. For enterprises, this lowers the barrier to entry but requires strict version control of the adapter modules to maintain reproducibility.
Custom Fine-Tuning Strategies These methods are designed for specific tasks, such as mixing general instructions with trajectory data or introducing additional constraints like regularization to improve generalization and stability. They offer greater flexibility and are suitable for complex or scarce task scenarios where off-the-shelf solutions fail. The burden of proof here lies with the developer to demonstrate that these customizations do not degrade overall model safety or introduce new failure modes.
Optimization Based on Reinforcement Learning: The Governance Gap
Compared to traditional fine-tuning, reinforcement learning (RL) offers agents a proactive path to autonomy. But as these systems move from imitation to exploration, the burden of proof shifts to those designing the reward structures. I read the recent review from East China Normal University and Donghua University, which dissects how we teach AI to learn through trial and error—and where enterprises often fail to account for liability when things go wrong.
RL enables models to explore behaviors in the environment, receive rewards and penalties, and dynamically adjust strategies, moving beyond simple imitation toward growth via feedback loops. The authors categorize current optimization approaches into two distinct buckets: reward-function-based optimization and preference-alignment-based optimization.
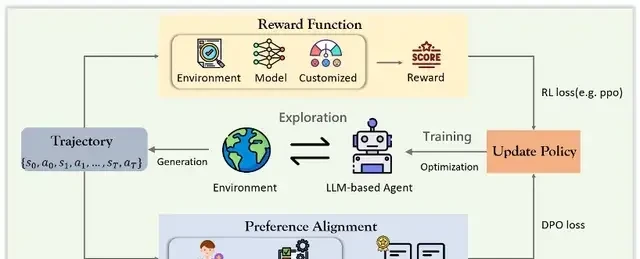
Reward-Function-Based Optimization
In this framework, the reward function acts as a baton, guiding the model to improve its strategy. By establishing clear standards for “doing well vs. doing wrong,” agents learn more precisely through interaction. However, defining those standards is where governance risks emerge.
The authors classify methods by their reward sources:
- Environment-based rewards: Scoring relies directly on task completion. This is simple and automated but often ignores the quality of intermediate steps, potentially rewarding harmful shortcuts to achieve a goal.
- Model-based rewards: LLMs or auxiliary models evaluate trajectories, providing detailed signals for sparse feedback scenarios. The risk here lies in the evaluation model’s bias; if the evaluator is flawed, the agent learns flawed values.
- Custom reward functions: Researchers design multi-dimensional rewards assessing completion rates, stability, and collaboration efficiency. While flexible, these have high design costs and are difficult to generalize across different enterprise contexts.

What concerns me is that reward functions are essentially codified corporate policy; if they are vague, agents will exploit loopholes. I think model-based rewards introduce a single point of failure in your governance chain. My sense is custom rewards require legal review to ensure they don’t incentivize non-compliant behavior.
Preference-Alignment-Based Optimization
Preference alignment offers a more direct and lightweight path than traditional RL. It abandons cumbersome reward modeling, teaching the agent which behaviors are more favored by humans instead.
The representative method here is DPO (Direct Preference Optimization), a simpler offline approach that strengthens learning through positive-negative contrast based on human or expert preferences. This shifts the accountability from mathematical optimization to data curation.
Based on primary sources of preference data, the authors categorize these approaches into two types:
- Expert/Human Preference Data: Positive and negative samples are constructed from expert demonstrations or annotations (high-quality vs. erroneous trajectories). While high in quality, this method is difficult to scale and has limited coverage, creating a bottleneck for enterprise adoption.
- Task or Environment Feedback: Preference pairs are automatically constructed from performance metrics like success rates. This suits dynamic scenarios but relies heavily on the rational design of feedback mechanisms, which can be gamed if not monitored.

In summary, preference alignment methods are efficient to train and simple to deploy, but they strongly depend on the quality and coverage of preference data. They suit structured tasks with clear feedback. In contrast, reward function-based methods handle complex environments better but come at a higher operational cost.
What concerns me is that preference data is your audit trail; if it’s biased, your compliance posture is compromised. I think enterprises must verify who labeled the “positive” samples before trusting the agent’s output.
Hybrid Parameter Fine-Tuning Methods
I read the analysis on hybrid fine-tuning strategies, and it highlights a clear tension in current LLM agent development. Conventional fine-tuning offers stability but lacks dynamic adaptability, whereas Reinforcement Learning (RL) provides flexibility at a high computational cost. The industry is increasingly turning to hybrid approaches to balance these trade-offs for more robust agents.
These efforts generally fall into two distinct categories: sequential training and alternating optimization.
First, sequential two-stage training. This remains the mainstream approach, adhering to a “Supervised Fine-Tuning (SFT) first, then RL” workflow.
- Stage 1: Behavioral Cloning Fine-Tuning (SFT): The model is pre-trained on expert trajectories or curated data to establish foundational capabilities.
- Stage 2: Reinforcement Learning Optimization (PPO / DPO): The policy is fine-tuned using environment or preference feedback.
Second, alternating optimization. This method introduces an iterative mechanism, switching back and forth between SFT and RL over multiple rounds for granular improvements.
My sense is sequential training simplifies governance by separating data ingestion from policy adjustment. What concerns me is that alternating optimization increases complexity, making audit trails harder to maintain. I think enterprises must verify which stage introduces the most compliance risk in their pipeline.
Parameter-Free LLM Agent Optimization
In contrast to parameter fine-tuning, parameter-free methods do not update model weights. Instead, they adjust prompts, context, and external information structures, showing strong potential for resource-constrained or lightweight deployments. The authors categorize these into five core strategies:
Category 1: Experience-Based Optimization. Agents use memory modules or historical trajectories to “learn to review,” extracting strategies from past successes and failures to enhance long-term adaptability.
Category 2: Feedback-Based Optimization. This involves continuous self-reflection or external evaluation to correct behavior, forming an iterative loop. Other methods optimize global instruction structures via meta-prompts to improve generalization.
Category 3: Tool-Based Optimization. Agents learn to use tools like search engines, calculators, and APIs. Some methods optimize tool-calling strategies, while others train agents to construct more efficient task-to-tool pathways.
Category 4: RAG-Based Optimization. By combining retrieval with generation, this approach enhances reasoning by retrieving real-time information from databases or knowledge bases, suitable for knowledge-intensive tasks.
Category 5: Multi-Agent Collaboration Optimization. Multiple LLM agents collaborate through role division and feedback mechanisms to achieve synergistic intelligence greater than the sum of its parts (1+1>2).
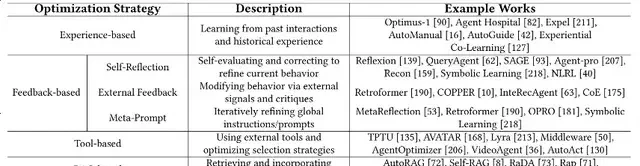
Parameter-free optimization makes LLM agents “smarter,” more “adaptable,” and “lighter” without modifying the model itself.
My sense is prompt-based changes are easier to revert than weight updates, aiding incident response. What concerns me is that multi-agent systems require strict access controls to prevent unauthorized tool usage. I think governance teams should monitor prompt injection risks in experience-based memory modules.
Datasets and Benchmarks
The authors divide data and benchmarks into two main categories: those used for evaluation and those used for fine-tuning.
Evaluation tasks are divided into two types. The first type consists of general evaluation tasks categorized by domain, such as mathematical reasoning, question answering (QA), multimodal tasks, and programming.
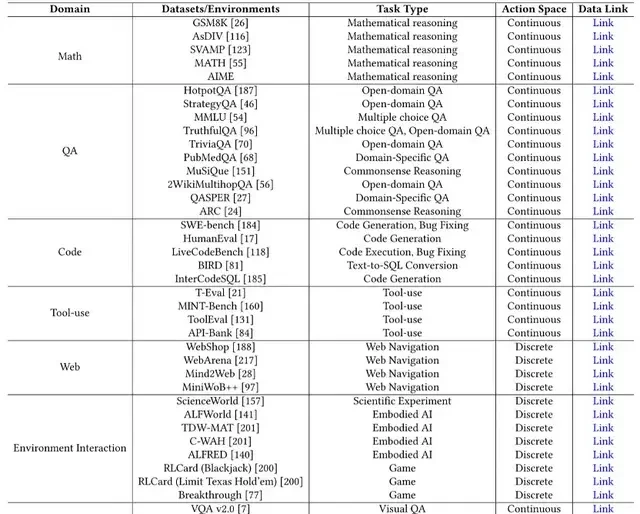
The second type comprises multi-task evaluation benchmarks. These assess LLM-based agents across various tasks, testing their ability to generalize and adapt to different domains.

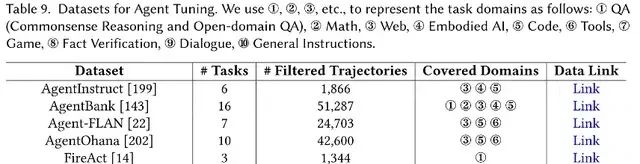
Agent Fine-Tuning Datasets are specifically designed data sets for agent fine-tuning, aimed at enhancing the capabilities of LLM agents across different tasks and environments.
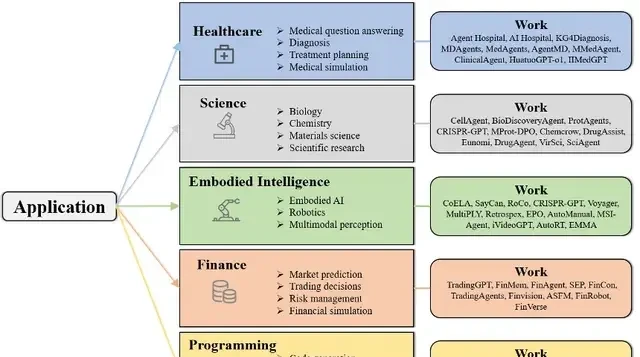
Applications and the Shift to Production
As optimization methods mature, LLM-based agents are no longer confined to academic exercises; they are gradually moving from laboratories into practical applications. This transition marks a critical juncture for enterprise governance, where theoretical performance must now withstand operational scrutiny.
Challenges and Future Directions
The path from prototype to production is fraught with systemic risks that current literature acknowledges but rarely solves in real-time.
Data Bias Issues.
Agents rely heavily on data quality; however, there is often a mismatch between the distribution of pre-training data and fine-tuning trajectories. This, combined with the potential biases introduced by LLM self-generation and evaluation, can lead to performance instability. Future research could explore methods such as bias testing, adversarial training, and knowledge boundary assessment to build a more robust data foundation.
My sense is enterprises must audit their agent’s training data lineage before deployment. What concerns me is that self-generated evaluation loops create blind spots in compliance monitoring.
Algorithmic Efficiency and Adaptability
Current reinforcement learning and fine-tuning methods struggle with high costs and poor effectiveness when facing sparse rewards, large action spaces, and multi-step interactions. A key future focus will be enhancing the multi-turn capabilities of lightweight methods like DPO, or exploring hybrid training approaches combining RL and SFT, meta-learning, and self-supervised learning.
I think high-cost RL loops are rarely viable for real-time enterprise governance. My sense is verify if “lightweight” claims hold up under load testing.
Difficulty in Cross-Task and Cross-Domain Transfer
Many methods perform well on single tasks but often fail in new environments or real-world scenarios. There is a need to develop stronger generalization mechanisms, such as task distribution alignment, domain adaptation, and multi-task joint training, to improve model transferability and adaptability.
What concerns me is that single-task success metrics are misleading for cross-departmental rollout. I think demand evidence of performance degradation in edge-case scenarios.
Lack of Unified Evaluation Standards
Agents use different metrics for various tasks (e.g., mathematical reasoning, web navigation, embodied AI), making cross-comparison difficult. Establishing a unified evaluation benchmark that incorporates new dimensions such as reasoning complexity, adaptability, and preference scoring will drive Agent research toward more systematic and comparable development.
My sense is without standard benchmarks, vendor claims remain unverified speculation. What concerns me is that your internal risk team needs its own evaluation framework.
Absence of Parameter-Driven Multi-Agent Optimization
Current multi-agent strategies largely rely on frozen LLMs, lacking joint parameter training mechanisms, which limits the development of collaborative intelligence. Future work should explore joint fine-tuning for multiple agents, reward-sharing mechanisms, and hierarchical control strategies to enhance overall system capabilities and collaboration levels.
arXiv link:
https://arxiv.org/abs/2503.12434
GitHub link:
https://github.com/YoungDubbyDu/LLM-Agent-Optimization
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google