As developers, we are tired of chasing larger parameter counts when our real bottleneck is often data quality. We spend more time cleaning datasets than writing features. ByteDance Seed challenges this assumption with Seed-Coder, an 8B-parameter model that claims to solve the data hygiene problem autonomously.
This release marks ByteDance’s first open-source code model, and it immediately positions itself against heavyweights like Qwen3. The core promise is striking: “with minimal human intervention, LLMs can autonomously manage code training data.” By self-generating and filtering its own high-quality training data, the model aims to boost code generation capabilities without the usual manual curation overhead.
I see this as a direct extension of the strategy popularized by DeepSeek-R1, where self-generation and filtering become central to performance gains. It suggests that for smaller models, data curation might matter more than raw scale.
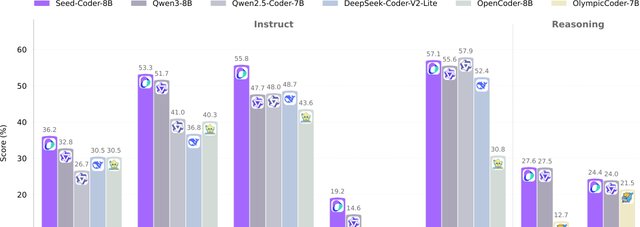
The release includes three distinct versions: Base, Instruct, and Reasoning. The Instruct version is particularly notable for its programming focus, achieving State-of-the-Art (SOTA) results on two benchmark tests.
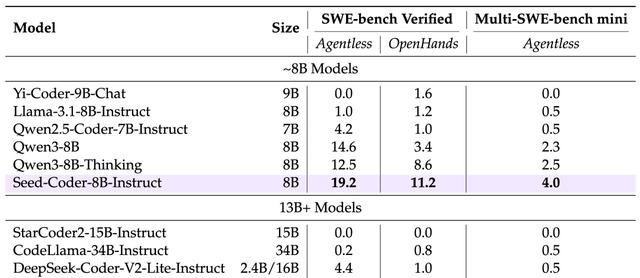
I think an 8B model with SOTA results is hard to ignore for resource-constrained teams. As a builder, autonomous data filtering could save us hours of manual dataset cleaning weekly. Personally, the MIT license makes it safe to integrate into commercial pipelines immediately.
The Reasoning version also shows significant strength, surpassing both QwQ-32B and DeepSeek-R1 in the IOI 2024 evaluation. This performance gap between an 8B model and larger competitors is worth watching closely.
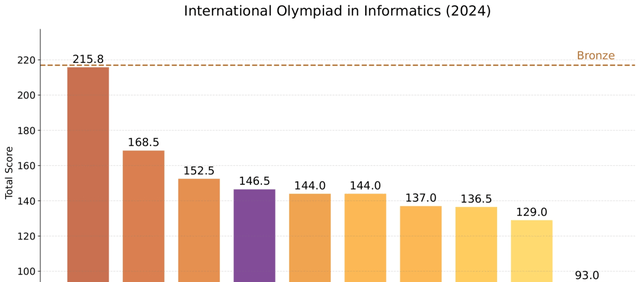
Technically, the model supports a context length of 32K and was trained on 6T tokens. ByteDance has released the complete code under the permissive MIT open-source license, with full access available on Hugging Face.
Curating Code with Models
I’ve watched the industry chase bigger parameter counts, but ByteDance’s new open-source release, Seed-Coder, suggests that how you feed a model matters just as much as its size. The team is proposing a “model-centric” data management paradigm where the AI itself helps curate the training corpus—a shift from manual curation to automated, intelligent filtering.
Seed-Coder builds on the architecture of its predecessor, doubao-coder. That earlier version used an Llama 3 base with 8.2B parameters, 6 layers, and a hidden size of 4096, leveraging Grouped Query Attention (GQA). The new iteration doubles down on data quality, using models to scrape, filter, and structure raw code from GitHub and web archives into pre-training-ready formats.
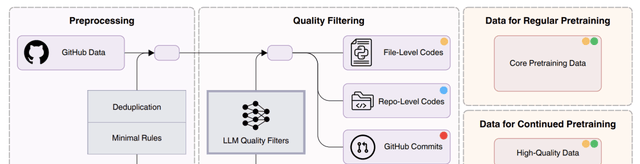
The resulting corpus is split into four distinct categories to teach the model different aspects of software engineering:
- File-level Code: Individual files from GitHub, cleaned for high-quality content.
- Repository-level Code: Files organized by project structure, allowing the model to learn inter-file relationships and context.
- Commit Data: Snapshots of 74 million commits from 140,000 high-quality repositories, including messages, metadata, related files, and code patches.
- Code-related Web Data: Documents extracted from web archives that contain code blocks or are highly relevant to coding tasks.
The Preprocessing Pipeline
The filtering process is rigorous. In the preprocessing stage, Seed-Coder implements a two-layer deduplication strategy: SHA256 hashing for exact matches and MinHash algorithms for approximate duplicates. This creates two corpus variants—one optimized for short context windows and another preserving project structure for long-context learning.
Next, syntax parsers like Tree-sitter scan the remaining files to discard those with errors. This step alone reduces the original data volume by approximately 98%.

Quality filtering is handled by a scoring model based on DeepSeek-V2-Chat. This scorer was trained on over 220,000 code documents and evaluates files across four key dimensions:
- Readability: Checks for reasonable comments, consistent naming, and standard formatting.
- Modularity: Ensures well-structured code with clear logical separation, avoiding overly complex functions.
- Clarity: Removes redundancy like excessive function calls or debug print statements to ensure intent is clear.
- Reusability: Verifies the code is free of syntax/logic errors, avoids hard-coded data, and is designed for easy integration.
The model assigns a score from 0 to 10 with a detailed explanation. These scores are rescaled to [0,1], and a fine-tuned Llama 2 model (1.3B parameters) acts as the final quality scorer. By filtering out the bottom 10% of files by score, Seed-Coder produced a corpus supporting 89 programming languages with about 1 trillion unique tokens.
Leveraging Commit History
Beyond static code, Seed-Coder utilizes commit history to teach change prediction. The team selected 74 million commits from repositories that met specific activity thresholds: at least 100 stars, 10 forks, 100 commits, and 100 days of maintenance.
Each record includes rich metadata—commit messages, code patches, merge status, and pre-commit snapshots. To make this useful for pre-training, the data is formatted as a code change prediction task: given a commit message and context, the model must predict modified file paths and corresponding changes. After deduplication and preprocessing, this yielded approximately 100 billion tokens from commit data alone.
For web-derived data, Seed-Coder also propos
Data Curation: The Hidden Engine Behind SOTA Benchmarks
As a developer who spends half my day debugging pipelines and the other half staring at token limits, I’ve learned that model architecture gets all the glory, but data curation is where the actual work happens. ByteDance’s release of Seed-Coder isn’t just about another set of weights; it’s a masterclass in how to handle the messy reality of web-scraped code.
The team didn’t just throw raw Common Crawl data at a transformer and hope for the best. They built a specialized extraction framework that acknowledges a fundamental truth: not all HTML is created equal, and most of it is noise.
The Two-Tier Extraction Challenge
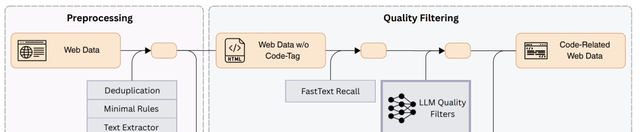
In the preprocessing stage, the framework efficiently preprocesses large-scale web archives and identifies two types of raw data:
- The first type consists of web pages in HTML with explicit code tags (e.g.,
<code>,<pre>), which can be extracted directly via standard rules; - The second type includes data without explicit code tags but potentially containing code or related knowledge. This type presents extraction challenges due to its volume and complexity.
Similar to GitHub data processing, the research team implemented exact and approximate deduplication techniques and developed heuristic rules to eliminate obvious low-quality documents during preprocessing (e.g., documents with fewer than 10 words).
I think deduplication is non-negotiable for training stability; skipping it guarantees model collapse. As a builder, heuristic filters like word counts are blunt instruments but effective at removing spam early.
Fixing the LLM Bias in Quality Filtering
In the quality filtering phase, the framework adopts two complementary strategies to ensure data quality: first identifying code relevance, then evaluating the intrinsic quality of the identified content.
In the code relevance identification step, the research team first extracted 10 million web page samples from Common Crawl data, marked pages with code features, and established an evaluation dataset.
70% of this dataset was used as a training set to train a fastText model for automatically identifying code-related content, while the remaining 30% served as a validation set to evaluate model performance.
In the quality assessment step, the system uses LLMs to score the identified code-related content using a 0-10 scale, evaluating the Normativity, completeness, and value.
However, during the actual evaluation process, researchers discovered systematic biases in the scores assigned to different types of websites:
Document websites and technical blogs generally received higher scores due to their standardized formats and clear structures. In contrast, technical forums and Q&A platforms often contained valuable technical discussions and solutions but scored lower because of their informal formatting.
To address this scoring bias, the research team optimized the evaluation system by first categorizing websites based on content format and functionality, then establishing specific evaluation criteria and filtering thresholds for each category.
Through this optimized dual-filtering mechanism, the system ultimately constructed a web data corpus containing approximately 1.2 trillion tokens.
Personally, relying on LLMs for scoring without category adjustments will bias your model toward polished docs over useful StackOverflow threads. I think categorizing sources before scoring is a simple fix that preserves the signal in messy, real-world code snippets.
Training Strategy: From Foundation to Reasoning
Based on the four data categories mentioned earlier, Seed-Coder’s pre-training was divided into two stages.
The first stage is standard pre-training, which uses file-level code and web data related to coding to build the model’s foundational capabilities.
The second stage is continued pre-training, utilizing all four data categories while additionally introducing high-quality datasets and long-context datasets to enhance performance, align the model, and stimulate its ability to understand long-context data.
In addition to the standard next-token prediction objective, Seed-Coder also employs Fill-in-the-Middle (FIM) and Suffix-Prefix-Middle (SPM) training methods to enhance context-aware completion and mid-content generation capabilities.
Building on the base model, the Seed team developed two special variants of Seed-Coder:
- Instruction Model (-Instruct): Designed to enhance the model’s ability to follow instructions. Its training consists of two stages: Supervised Fine-Tuning (SFT) followed by Direct Preference Optimization (DPO).
- Reasoning Model (-Reasoning): Aimed at improving multi-step reasoning capabilities in complex programming tasks. It utilizes Long Chain-of-Thought (LongCoT) reinforcement learning training. This begins with warm-up training using solutions generated from programming competition problems and high-quality models, followed by reinforcement learning training implemented via the GRPO framework.
The establishment of these two variants further expands the practical utility of Seed-Coder.
As a builder, fIM and SPM are essential for any model intended to act as an autocomplete agent in IDEs. Personally, using GRPO for reasoning tasks suggests a shift away from standard PPO, which may offer more stable convergence for code logic.
The Shift Toward Accessible AI Infrastructure
I’ve been tracking ByteDance Seed’s recent pivot, and it’s clear they are aggressively lowering the barrier to entry for advanced AI capabilities. It’s not just about releasing code; it’s about making high-end models deployable by smaller teams without requiring massive infrastructure budgets.
Take their video generation model, Seaweed. It natively supports 1280×720 resolution, arbitrary aspect ratios, and variable durations with only 7 billion parameters. That efficiency allows it to outperform models with 14 billion parameters while emphasizing cost advantages. The training required just 665,000 H100 GPU hours, making it deployable by small to medium-sized teams on a single GPU with 40GB of VRAM for resolutions up to 1280×720.

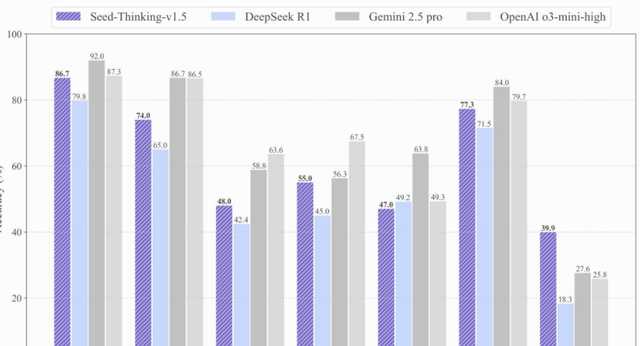
Their reasoning model, Seed-Thinking-v1.5, is also getting lighter on activated parameters while surpassing DeepSeek-R1 in mathematics and coding tasks. The team has been transparent about their methods, publishing technical reports that detail how they improved reasoning through data curation, RL algorithms, and infrastructure tweaks.
In the agent space, they partnered with Tsinghua University to launch UI-TARS. Built on Qwen-VL, this computer operation agent outperforms GPT-4o and others in autonomous, cross-task operations across various systems. It’s free for commercial use and has already garnered over 5.8k stars on GitHub.
They’ve also introduced Multi-SWE-bench, a multilingual benchmark spanning seven programming languages with 1,632 high-quality instances to better measure problem-solving capabilities.
Internal Consolidation and Future Focus
The organizational structure under Seed is tightening. Reports indicate that the three LLM teams—Pre-train, Post-train, and Horizon—now report directly to Wu Yonghui. Additionally, initiatives from ByteDance AI Lab in robotics & embodied intelligence, AI for Science, and AI safety/interpretability have been merged into Seed.
There’s also “Seed Edge,” a new research project focused on longer-term, fundamental AGI frontier research. It offers independent computing resources and longer evaluation cycles, targeting next-generation innovation rather than just iterative model updates.
I think seaweed’s single-GPU deployment is a game-changer for prototyping video features without cloud costs. As a builder, uI-TARS being free for commercial use removes legal friction for internal automation tools. Personally, seed-Thinking-v1.5’s efficiency suggests we can run strong reasoning locally on modest hardware soon.
The broader trend here is clear: open source, original innovation, and making AI accessible to everyone. It raises the question of whether this competitive pressure is a direct response to competitors like DeepSeek.
Project Address:
https://github.com/ByteDance-Seed/Seed-Coder
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google