DeepSeek’s appearance on the cover of Nature isn’t just a vanity metric. It signals a shift in how Chinese AI firms compete: not just on benchmarks, but on scientific legitimacy and cost efficiency. For investors, this validates the “high leverage” narrative that DeepSeek has pushed for months. The $2 million training figure is the real story here, challenging the assumption that frontier models require billions in compute.

DeepSeek has become the first Chinese large model company to grace the cover of Nature, with founder Liang Wenfeng listed as corresponding author. This places them in an exclusive global club, alongside entities like DeepMind for AlphaGo and AlphaFold. The journal’s version of the R1 paper discloses training costs for the first time: approximately $294,000 (about 2.08 million RMB). It also details data types and safety measures previously kept under wraps.
Lewis Tunstall, a machine learning engineer at Hugging Face, notes that R1 is the first large language model to undergo peer review. This sets a precedent for transparency in an industry often criticized for black-box development. Huan Sun of Ohio State University adds that R1 has influenced nearly all recent research on reinforcement learning in LLMs since its release.
Honestly, peer-reviewed validation reduces regulatory and technical risk for enterprise buyers adopting open-source models.
The adoption metrics are staggering. As of this writing:
- Google Scholar Citations: 3,596
- Hugging Face Downloads: 10.9 million (Ranking first among open-source model downloads)
- GitHub Stars: 91.1K
These numbers prove that cost-efficiency does not equate to low utility. The market is rewarding models that deliver frontier performance at a fraction of the traditional compute spend.
I think deepSeek’s download dominance proves that price-performance arbitrage drives open-source adoption faster than brand prestige.
DeepSeek has raised the bar for Chinese AI companies. They are no longer satisfied with presenting at top conferences like CVPR, ICLR, and ICML. The new target is covers of Nature and Science. This suggests a strategic pivot toward establishing scientific authority as a competitive moat against Western incumbents.

The way I see it, scientific prestige is becoming a key differentiator in the geopolitical AI race, not just an academic exercise.
The Real Cost of Intelligence
I read the supplementary materials in Nature, and the numbers are stark. DeepSeek trained R1-Zero for 198 hours and R1 for just 80 hours on 512 H800 GPUs. At $2 per GPU hour, that is a total bill of $294,000.

This is not a rounding error. This is a 660B parameter model built for less than $300,000. Competitors burning tens of millions are now operating in a different economic reality. The stock market reaction earlier this year was justified; the myth that top-tier AI requires massive capital expenditure has been shattered.
Honestly, capital efficiency is now the primary competitive moat, not just raw parameter count. I think western vendors relying on brute-force spending are structurally disadvantaged against leaner architectures.
Data Composition and Safety Claims
DeepSeek also addressed rumors about data provenance. They explicitly denied using outputs from other models as inputs for R1. The dataset is a curated mix of five specific types: mathematics, programming, STEM, logic, and general knowledge.

The breakdown is precise. The mathematics set holds 26,000 quantitative reasoning questions. The code dataset includes 17,000 algorithmic problems and 8,000 repair issues. STEM covers 22,000 multiple-choice questions in physics, chemistry, and biology. Logic contains 15,000 real-world and synthetic problems. General knowledge comprises 66,000 items for creative writing, editing, Q&A, and harmlessness assessment.
Safety is where the nuance lies. DeepSeek released a security assessment covering risk control systems, comparative evaluations against six public benchmarks, internal test sets, multilingual checks, and jailbreak robustness. They claim R1’s inherent safety is moderate, comparable to GPT-4o, but requires external risk controls for production use.
The way I see it, the data strategy relies on high-signal synthetic reasoning rather than massive web scraping. Honestly, safety claims are relative; the model remains a tool that requires significant guardrails.
China’s AI Model Lands on Nature Cover! DeepSeek Reveals R1 Training Costed Just $2 Million
The Reinforcement Learning Breakthrough
I read the paper. It claims DeepSeek-R1 (Zero) solves the reliance of large language models on complex problem-solving and human-annotated data. They propose a pure reinforcement learning (RL) framework to enhance reasoning capabilities.
This method ignores manually annotated reasoning trajectories. Instead, it develops reasoning through self-evolution. The core mechanism is simple: the reward signal is based solely on the correctness of the final answer. It imposes no constraints on the reasoning process itself.
They used DeepSeek-V3-Base as the foundation and adopted GRPO (Group Relative Policy Optimization) for RL training. After thousands of steps, DeepSeek-R1-Zero showed excellent performance on benchmarks.
On AIME 2024, the pass@1 score jumped from 15.6% to 71.0%. Majority voting pushed it further to 86.7%, performing comparably to o1.
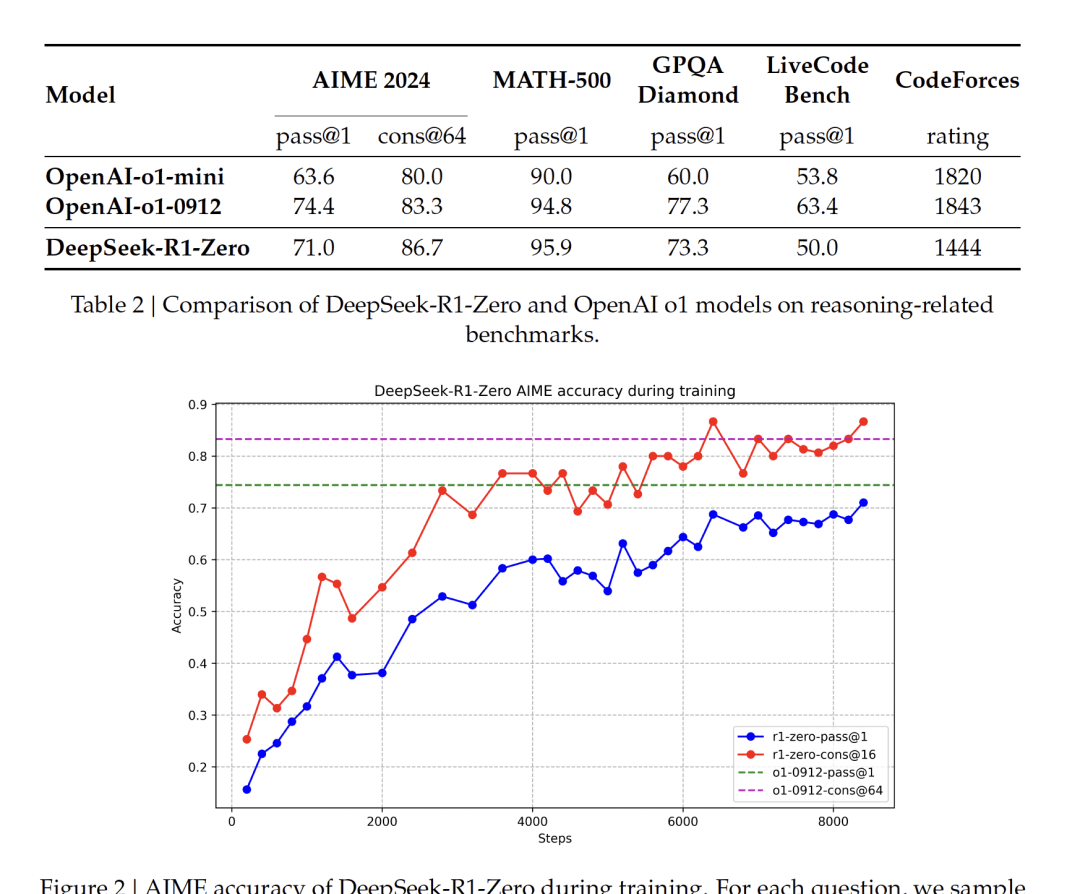
I think pure RL reward signals are a cheaper, faster path to reasoning than supervised fine-tuning.
The R1 Refinement Process
DeepSeek-R1-Zero had readability and language mixing issues. Researchers introduced DeepSeek-R1 to fix this. This version uses a multi-stage training framework: cold-start data, rejection sampling, reinforcement learning, and supervised fine-tuning (SFT).
The team first collected thousands of cold-start data points to fine-tune DeepSeek-V3-Base. Then came reasoning-oriented RL training similar to R1-Zero.
As RL approached convergence, they performed rejection sampling on RL checkpoints. They combined these with supervised data from DeepSeek-V3 in writing, factual Q&A, and self-awareness. This generated new SFT data for retraining the base model.
After this fine-tuning, an additional RL process covering various prompt scenarios resulted in DeepSeek-R1.
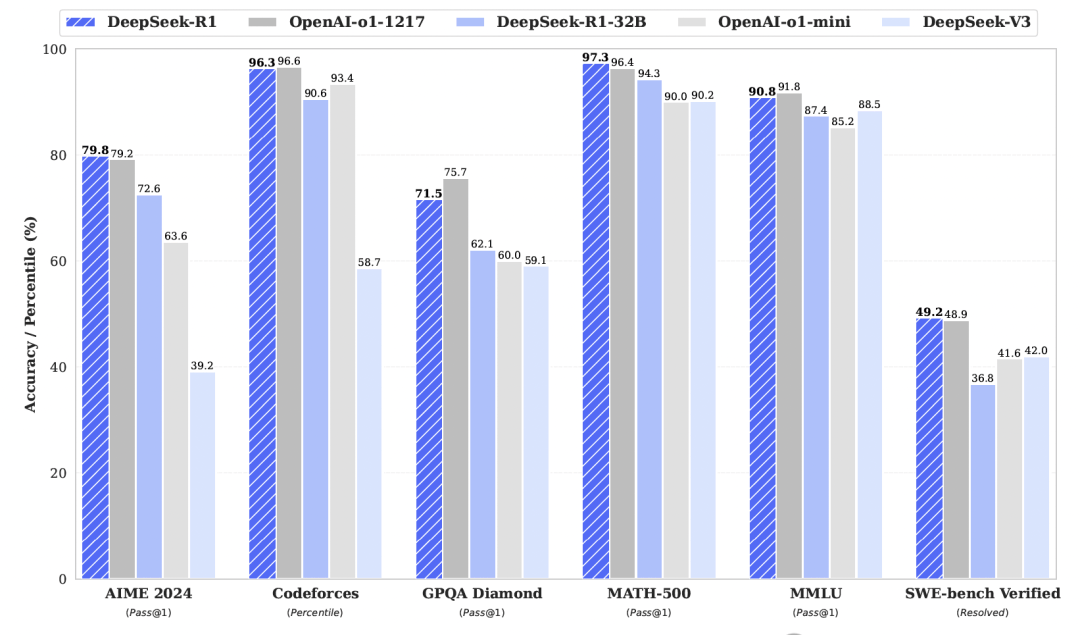
The way I see it, the multi-stage refinement is where the real engineering value lies, not just the initial RL burst.
Distillation and Open Source Impact
Experiments showed DeepSeek-R1 was comparable to OpenAI-o1-1217 at the time. Using reasoning patterns from large models to guide smaller ones is a classic approach.
The paper used Qwen2.5-32B as the base model. Performance distilled from DeepSeek-R1 outperformed directly applying RL on that base model.
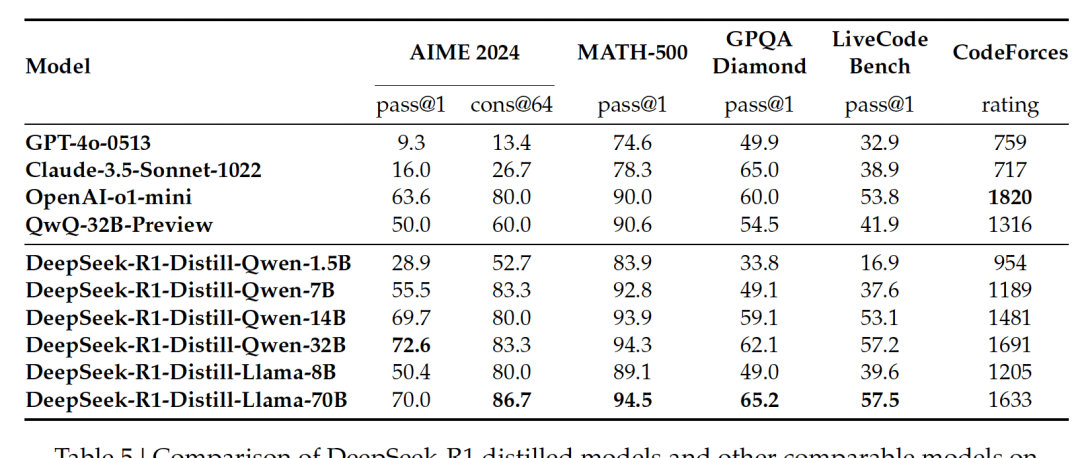
Honestly, distillation allows smaller models to punch above their weight class without massive compute budgets.
Beyond the paper, Nature praised DeepSeek’s transparency and open-source spirit. They released weights for DeepSeek-R1 and R1-Zero on HuggingFace. They also open-sourced distilled models based on Qwen2.5 and Llama3 series for free community use.
Recall when DeepSeek went viral overseas earlier this year. Founder Liang Wenfeng’s bold statement that “Chinese AI cannot follow forever” was inspiring. Now, with Nature cover recognition validating DeepSeek’s influence, if there were an S-tier certification for AI research institutions, DeepSeek has undoubtedly earned it.
Who is next? Alibaba Tongyi, ByteDance Seed, Tencent Hunyuan, Baidu Wenxin, Huawei, Zhipu, Kimi, StepFun…
Who?
References
I’ve combed through these primary sources to verify the claims against the hype.
- Secrets of DeepSeek AI model revealed in landmark paper — First peer-reviewed study shows how a Chinese start-up firm made the market-shaking LLM for US$300,000.
- DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning - Nature — A new artificial intelligence model, DeepSeek-R1, is introduced, demonstrating that the reasoning abilities of large language models can be incentivized through pure reinforcement learning, removing the need for human-an
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google