As a developer who has watched LLM services buckle under the weight of sudden user surges, I know that server overload isn’t just an inconvenience—it’s a trust killer. When a model becomes popular, the infrastructure often fails to keep pace, leaving users staring at spinning wheels or error messages. The latest paper from Moonshot AI and the Tsinghua University KVCache.ai team addresses this exact pain point by revealing the inference architecture behind Kimi.
Kimi is currently one of China’s most popular large language models (LLMs), consistently attracting significant traffic and frequently experiencing server overload.

With the publication of this paper, answers have emerged regarding how Kimi manages such massive traffic loads.

The inference architecture powering Kimi is named Mooncake (Yuebing). Its primary feature is a decoupled design.
I think decoupling compute from memory storage feels like the right move for scaling. I want to see how this handles cold starts in production environments. As a builder, high throughput numbers are great, but latency consistency matters more to me.
Mooncake was designed with high-traffic scenarios in mind from the outset, specifically engineered to handle such conditions.
In simulated environments, Mooncake can achieve a throughput increase of up to 525%, while in real-world scenarios, it can process 75% more requests.
According to an article by Xu Xinran, Vice President of Engineering at Moonshot AI, over 80% of Kimi’s traffic is handled by this system.
Building a Distributed System Around KV Cache
The core bottleneck in modern LLM inference isn’t just raw compute—it’s the KV cache. The Kimi paper details how Mooncake builds an entire distributed system around this constraint.
(The KV cache stores key-value pairs. Its main advantage lies in simple and efficient data access and retrieval, which improves inference speed and reduces computational resource consumption in large models.)
The team’s design choice hinges on the assumption that KV cache capacity would remain high for an extended period, making optimization around these caches essential rather than optional.
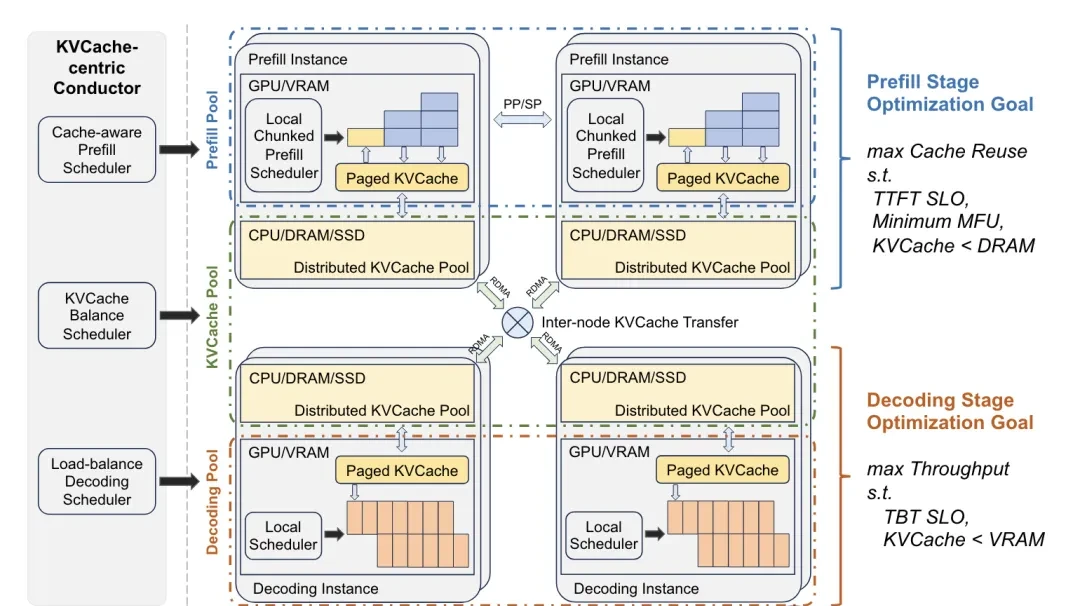
Structurally, Mooncake consists of a global scheduler (Conductor), Prefill node clusters, Decoding node clusters, and a distributed KVCache pool. It also includes an RDMA communication component called Messenger.
The global scheduler serves as the entry point for user requests entering the system. It receives requests and dispatches them to Prefill and Decoding nodes based on KV cache distribution and load conditions.
When scheduling, the scheduler comprehensively considers factors such as KV cache reuse length and load balancing to maximize KV cache utilization.
Specifically within Mooncake, it employs a heuristic-based automatic hot-spot migration strategy that automatically replicates hot KV cache blocks without requiring precise predictions of future access patterns.
Furthermore, this dynamic replication of hot KV cache blocks is a crucial method for achieving balanced loads.
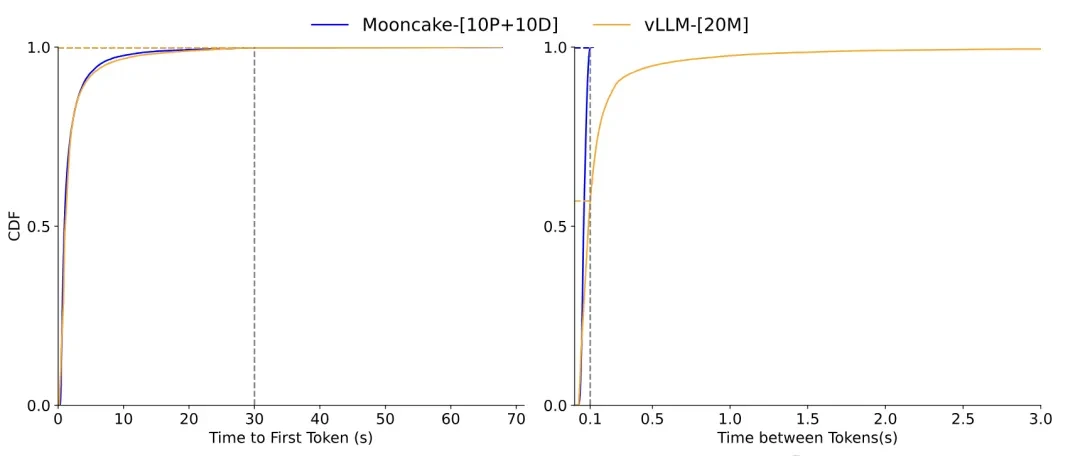
Experimental results indicate that compared to random scheduling and load-balanced scheduling, Mooncake’s scheduling strategy significantly reduces TTFT (Time To First Token) and improves overall system performance.
Personally, heuristic migration beats complex prediction models in production where patterns shift constantly. I think reducing TTFT is the only metric that matters for user-facing chat interfaces.
After scheduling, tasks are assigned to Prefill and Decoding nodes for computation.
Upon receiving requests forwarded by the scheduler, Prefill nodes read caches from the KV cache pool, perform pre-computation, and generate new KV caches.
For long-context requests, Mooncake uses chunked pipelining to process data across multiple nodes in parallel, thereby reducing latency.
Decoding nodes receive not only requests from the scheduler but also the KV caches generated during the Prefill phase. These nodes decode the caches to produce final results.
As a builder, chunked pipelining is a necessary evil for handling context windows that exceed single-GPU memory. Personally, decoupling prefill and decode stages allows you to scale each independently based on actual load.
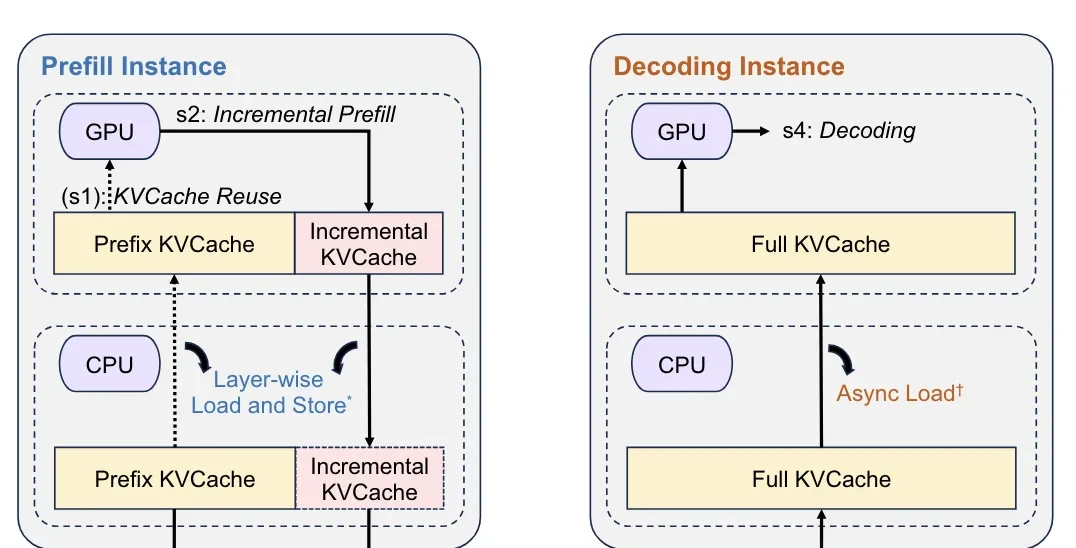
In this process, large-capacity, high-performance KV cache storage is provided by the cache pool. The RDMA communication component leverages its high bandwidth and low latency to facilitate KV cache transmission between different nodes.
Beyond its KV-cache-centric workflow, Mooncake features another key characteristic: a decoupled architecture.
One significant factor in adopting this decoupled architecture is the substantial difference in computational characteristics between the Prefill and Decoding stages.
Specifically, these stages are responsible for TTFT (Time To First Token) and TBT (Time Between Tokens), respectively.
This leads to differences in their computational complexity, memory access patterns, parallelism granularity, and sensitivity to latency:

Consequently, the Moonshot AI team split its GPU clusters accordingly, allowing them to be deployed on separate node clusters for resource isolation and specialized optimization.
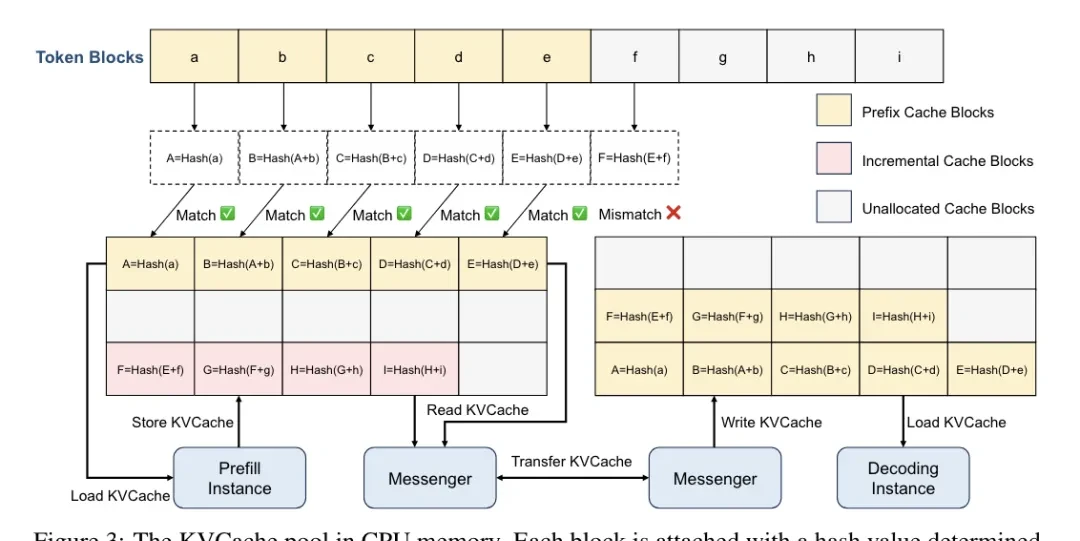
Additionally, the KV cache pool in Mooncake is distributed. It fully utilizes idle CPU, DRAM, and SSD resources within the GPU cluster, achieving large-capacity, high-bandwidth KV cache storage and transmission while minimizing waste of idle resources.
Predicting Load to Reject Excessive Requests
Even with Mooncake’s efficient decoupled architecture, real-world traffic spikes remain a headache. I read the Kimi paper to see how they handle overload without crashing the system. The core challenge isn’t just processing power; it’s deciding whether to accept new requests when things get crowded.
Because Mooncake separates Prefill and Decoding nodes, it can implement an early rejection strategy. This means rejecting requests during the Prefill phase based on the current load of Decoding nodes. To make these decisions, they use Service Level Objectives (SLOs) for Time to First Token (TTFT) and Time Between Tokens (TBT).
The specific SLO requirements are strict:
- The 90th percentile (P90) of TTFT should not exceed ten times the processing time of a single request under empty-load conditions.
- The P90 value of TBT should not exceed five times that baseline.
This early rejection strategy significantly reduces invalid Prefill computations and improves resource utilization. However, it introduces a new problem: fluctuations in load between Prefill and Decoding nodes, which can lower resource utilization and impact system performance.
This issue arises because there is a lag in the decision-making process for request rejection within the early rejection strategy, as illustrated below:
- Phase 1: Both Prefill and Decoding node loads are low. The scheduler continuously accepts new requests until the Prefill node load reaches its upper limit.
- Phase 2: Requests processed by the Prefill nodes begin entering the Decoding nodes, causing their load to rise rapidly. Once the Decoding node load exceeds a threshold, the scheduler begins rejecting new requests. However, at this point, the Prefill node load remains high.
- Phase 3: Due to the rejection of new requests by the scheduler, the Prefill node load starts to decrease. Meanwhile, previously queued requests are still being processed in the Decoding phase, keeping that node’s load high.
- Phase 4: The Decoding node load begins to drop as previous requests complete and no new requests are accepted. The scheduler then resumes accepting new requests, causing the Prefill node load to rise again.
This cycle repeats periodically, leading to out-of-phase fluctuations in the loads of Prefill and Decoding nodes.
To address this issue, the Moonshot AI team refined the simple early rejection strategy by proposing a prediction-based early rejection strategy to reduce node load fluctuations. The core idea is to predict the Decoding node load after a certain period and decide whether to reject requests based on these predictions.
Predictions can be made at two levels: request-level and system-level. Request-level prediction is difficult because it requires predicting the execution time of individual requests; system-level prediction is relatively easier, requiring only an estimate of overall load conditions. Mooncake employs a simplified system-level prediction method, assuming that each request’s execution time follows a fixed distribution to predict future load conditions.
I think predictive rejection feels like necessary insurance for production inference servers. As a builder, system-level prediction is the pragmatic choice over per-request timing guesses. Personally, decoupled architectures need smarter scheduling, not just more GPUs.
Experimental results show that this prediction-based early rejection strategy effectively alleviates load fluctuation issues.
Ultimately, end-to-end performance evaluations demonstrate that Mooncake’s architectural design and optimization strategies effectively improve inference service performance, with advantages being particularly pronounced in long-context and real-world scenarios.
On the ArXiv Summarization and L-Eval datasets, Mooncake’s throughput increased by 20% and 40%, respectively, compared to the baseline method vLLM.
On simulated datasets, Mooncake’s throughput reached up to 525%, and on real-world datasets, it could process approximately 75% more requests than vLLM.

Performance evaluations in overload scenarios showed that using the prediction-based early rejection strategy reduced the number of rejected requests from 4,183 (the baseline) to 3,589. This indicates a tangible improvement in the system’s request processing capacity during peak times.
I think early rejection saves compute without killing latency. It is a pragmatic fix for noisy production environments.
Regarding future developments, Zhang Mingxing, Assistant Professor at Tsinghua University’s Department of Computer Science and another author of the paper, stated that current trends suggest LLM service loads will become increasingly complex and diverse. Consequently, scheduling will grow more complicated and critical.
As for Moonshot AI’s development direction, Xu Xinran explained that the implementation of distributed strategies implies that the company’s entire system will evolve independently in two directions: “compute power per dollar” and “bandwidth per dollar,” making it more friendly to hardware optimization.
As a builder, optimizing for compute-per-dollar is smart when margins are thin. Hardware-friendly design reduces long-term operational costs.
Paper Link:
https://arxiv.org/pdf/2407.00079
GitHub:
https://github.com/kvcache-ai/Mooncake
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google