The decision by X to open-source its recommendation engine sends a ripple through Asia-Pacific markets where platform opacity remains the norm. By exposing their code, Elon Musk is not just changing Twitter’s architecture; he is challenging the regulatory and competitive status quo across borders.
I think this transparency test could pressure other APAC platforms to justify their black-box algorithms to regulators. From an APAC angle, open-sourcing core AI logic shifts power from corporate secrecy to community audit, a trend we may see in Tokyo or Seoul.
As I followed the release of Elon Musk’s open-sourced recommendation algorithm system, the full details are now visible on GitHub. The documentation explicitly states that this is an algorithmic system driven almost entirely by AI models.
We have removed all manually designed features and the vast majority of heuristic rules.
The announcement immediately sparked a frenzy across the community. The top-voted comment offered high praise:
Incredible! No other platform achieves this level of transparency.

Musk himself quickly retweeted the original post from his engineering team. However, despite his usual high-profile rhetoric, he adopted a more subdued tone this time:
We know this algorithm is dumb and needs significant improvement, but at least you can see in real-time and transparently how we are working to improve it.
No other social media company does this.

Long before acquiring the platform (formerly Twitter) in 2022, Musk had frequently criticized it for being too closed off. Since the acquisition, he has fulfilled his promise to publicly disclose core aspects of Twitter’s recommendation algorithm multiple times; this latest move can be seen as staying true to that original commitment.
The Mechanics Behind X’s AI-Driven Feed
I followed the release of X’s recommendation engine documentation, and what stood out immediately is how it attempts to replace human intuition with raw data processing. In short, this system relies on the same Transformer architecture as Grok-1, learning from your historical interactions—likes, replies, or retweets—to determine content visibility.
When you open the “For You” feed, your client sends a request that triggers this entire algorithmic chain. The system’s first task is to construct a real-time user profile by analyzing two distinct data categories: Action Sequence (immediate signals like clicks or dwell time) and Features (long-term attributes such as location or declared interests).
Globally, this shift from manual feature engineering to end-to-end learning reflects a broader industry move toward automated pattern recognition.
Previously, engineers might have manually coded rules for “user interest scores,” but Musk’s approach rejects these preset assumptions. Instead, it feeds raw behavioral data directly into models, allowing them to learn patterns without human bias—a process described as “de-manualization.”
Once the profile is built, the system branches into two retrieval paths to filter thousands of potential tweets: one via your social circle using the Thunder module, and another external path using Phoenix Retrieval for content from accounts you don’t follow.
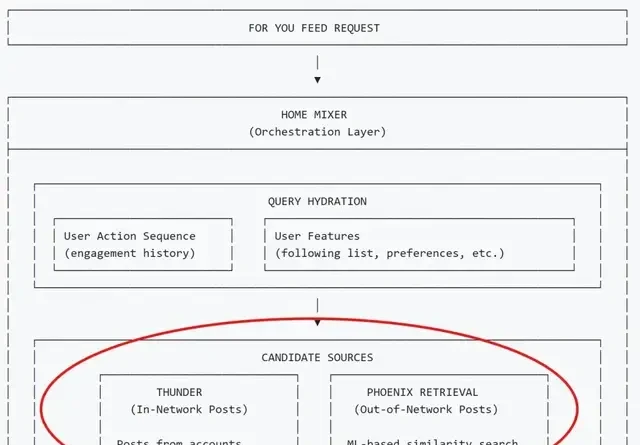
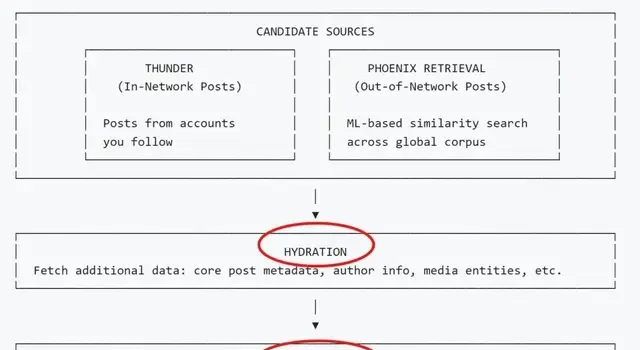
These sources are treated uniformly, initially filtering only tweet IDs. The Hydration module then enriches these candidates with full text, media, and interaction history for deeper evaluation. Before ranking begins, the Filtering module removes obvious noise: duplicates, expired posts, blocked accounts, or content you’ve already seen.
I think by separating eligibility from relevance, X isolates technical constraints from algorithmic preference, a common but critical architectural choice in large-scale feeds.
This step only determines if content “can appear,” not if it is worthy of recommendation. The remaining candidates are then scored by the Phoenix ranking model, a Transformer-based system that predicts the probability of various user actions on specific tweets.
The model weighs these probabilities against preset weights—adding points for likes and subtracting for blocks—to generate a final ranking score. The system then applies minor engineering adjustments, such as controlling author diversity to prevent an
X’s new open-source recommendation engine aims to dilute the influence of any single account, preventing one major influencer from dominating the feed. To ensure each post is scored independently, the system enforces a “candidate posts cannot see each other” mechanism, eliminating cross-attention between tweets.
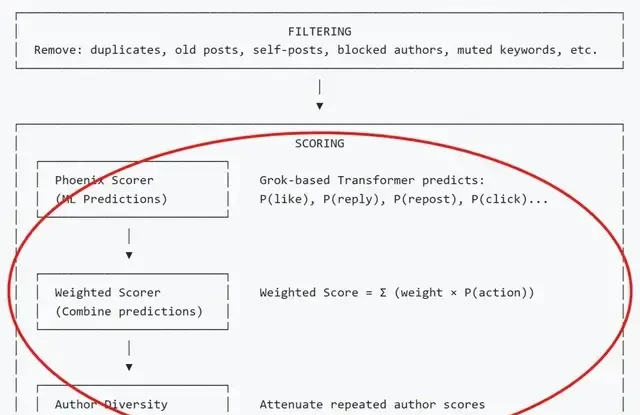
All candidate posts are sorted by their final scores, and the system selects the Top-K posts as the recommendation results for this request. Before returning to the client, the system performs one last round of verification to ensure content complies with platform safety standards—removing any deleted tweets, those marked as spam, or those containing violent/gory or otherwise violating content. Finally, after undergoing multiple rounds of filtering, the information is displayed to the client user in order of their scores.

In summary, there are five key factors for the successful operation of this system (as highlighted by the official documentation):
(1) Purely data-driven, rejecting manual rules.
Completely abandoning complex rules manually defined to determine “what content is good,” and instead allowing AI models to learn directly from raw user data.
From an APAC angle, this shift signals a broader industry move toward black-box optimization over curated editorial standards.
(2) Candidate isolation mechanism for independent scoring.
When the AI model scores content, each piece of content “cannot see” other candidates; it only sees user information. This ensures that a post’s score does not change based on other posts in the same batch, making scores consistent and efficiently cacheable/reusable.
Globally, isolated scoring simplifies compliance audits but may reduce contextual nuance in diverse markets.
(3) Hash embeddings for efficient retrieval.
Both retrieval and ranking use multiple hash functions for vector embedding lookups to improve efficiency.
(4) Predicting diverse behaviors rather than a single score.
The AI model does not directly output a vague “recommendation value,” but instead predicts various user behaviors simultaneously.
I think multi-behavior prediction aligns with global trends toward engagement-maximizing, if not always quality-focused, algorithms.
(5) Modular pipeline supporting rapid iteration.
The entire recommendation system adopts a modular design, allowing individual components to be developed, tested, and replaced independently.
”Yes, this algorithm is terrible”
Despite the community’s appreciation for Musk’s open-source stance, there are still some “flaws” in this algorithm.
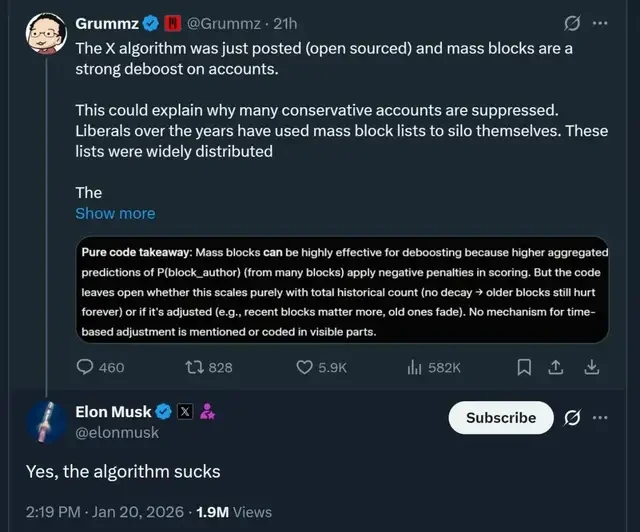
After the recommendation algorithm was made public, one user complained:
Due to API access restrictions and high costs, blocking lists are rarely used now, but they were very common in the past.
The algorithm must ensure that older block lists gradually fade over time so that these outdated blocks are not maliciously exploited.
The implication is that the algorithm code shows “blocked by many users” as a strong negative signal, which directly leads to an account being “demoted,” meaning its content becomes harder to recommend. However, there is no clear time decay mechanism for the “block” signal visible in the code.
This means that historical block records may still be affecting an account’s recommendation score today.
From an APAC angle, transparency without maintenance invites scrutiny; open-source code requires active governance to remain useful. Globally, aPAC platforms often prioritize real-time relevance over static historical penalties, a contrast worth watching.
This comment prompted Musk himself to appear in the comments section and complain:
Yes, this algorithm is terrible.
Regardless, Musk’s attitude toward change is clear—
Not only has he open-sourced in the past and present, but he will continue to do so. Future updates will be open-sourced every four weeks.
Open-source repository:
https://github.com/xai-org/x-algorithm
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google