I’ve watched enough staged demos to know that a robot wiping a whiteboard on camera rarely translates to one doing dishes in my kitchen. The gap between “it worked once” and “it works reliably” is where most humanoid projects die, usually due to unit economics rather than code bugs. This new UC Berkeley research claims to bridge that gap by solving full-body coordination, but I’m looking for the cost analysis before I celebrate.
I think lab demos look clean; real kitchens are cluttered and unforgiving. In the field, high-latency policies won’t cut it when you’re dropping plates. What I watch for is teleoperation fatigue is a real bottleneck for scaling training data.
The “Two Major Dilemmas” Hindering Humanoid Robots from Entering Daily Life
Humanoid robots have long been hailed as promising tools capable of assisting humans with daily tasks in unstructured environments such as homes and offices. However, two key challenges have prevented them from breaking out of the “laboratory boundary” and achieving practical application:
Challenge 1: Difficulty in Full-Body Coordination; High Cost and Scarcity of Teaching Data
Tasks that require long-term continuous execution, such as using a dishwasher or moving to wipe a blackboard, demand simultaneous coordination of the robot’s head (for target localization), hands (for grasping and manipulation), and legs (for movement and balance). This mimics the human state of “eyes leading hands” with steady footing.
However, traditional teleoperation modes require operators to control dozens or even hundreds of joints simultaneously. This not only presents an extremely high operational difficulty and causes rapid operator fatigue but also makes it difficult to collect high-quality demonstration data. Without reliable “teacher demonstrations,” robots naturally struggle to learn complex coordinated movements.
Challenge 2: Incompatibility Between Action “Flexibility” and “Response Speed”
Humans often have multiple viable ways to perform the same action (e.g., holding a plate can be done by supporting it with five fingers or gripping the edge with the thumb). This “action diversity” is a key difficulty in enabling robots to imitate humans.
Traditional solutions either suffer from being “too rigid”: for instance, behavior cloning techniques only allow robots to learn one fixed action sequence, causing them to fail when encountering slightly varied scenarios;
or they are “too sluggish”: while diffusion policies can generate multiple action options, they require repeated calculations with high latency, making it impossible to meet real-time operational needs (such as missing the optimal alignment timing when inserting a plate).
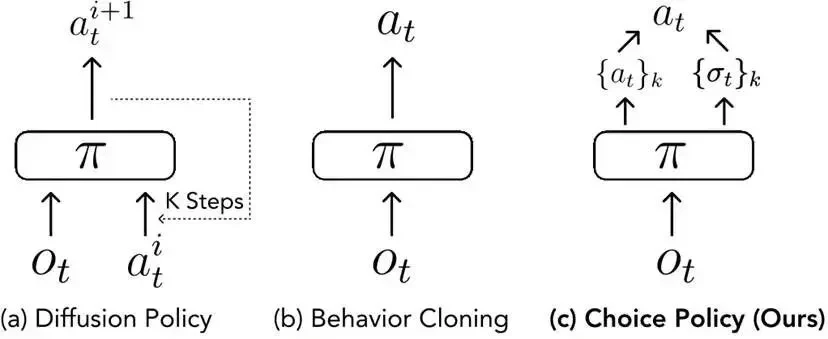
Tackling Both Problems: Solving Dilemmas with “Modular Teaching + Intelligent Action Selection”
I’ve seen enough stage demos to know that “easy” teleoperation often collapses under the weight of real-world clutter. The Berkeley team sidestepped the trap of building a single, monolithic control system. Instead, they split the problem into two distinct parts: simplified teaching and intelligent action selection. They claim this modular approach yields results greater than the sum of its parts (“1+1>2”).
I think vR controllers are great until you drop one in a sink full of soapy water.
Simplifying “Teaching”: Modular Teleoperation Allows Anyone to Become a “Robot Teacher” in 10 Minutes
The researchers broke down full-body control into four specific modules, aiming to let anyone operate the robot via VR controllers without specialized training.

The system relies on four distinct interfaces:
① Hand-Eye Coordination Module: The robot’s head tracks hand movements to keep the “eyes” fixed on the task area.
② Hand Grasping Module: A trigger pull initiates a “power grasp,” while joystick adjustments fine-tune thumb position for grip strength control.
③ Arm Tracking Module: VR controller orientation maps directly to the robot’s arm; movement is mirrored instantly.
④ Omni-directional Movement Module: Switching to joystick mode allows for forward/backward travel, lateral shifting, and turning.
This architecture claims to lower the barrier to entry significantly. Operators can get started within 10 minutes, reducing fatigue and enabling rapid collection of high-quality demonstration data. The goal is to provide an efficient “personal tutor” rather than forcing blind imitation.
In the field, ten minutes is enough time to learn the interface, not enough to master safety protocols.
Optimizing “Decision-Making”: Choice Policy Algorithm Enables Robots to “Instantly Select Optimal Actions”
To avoid the rigidity of traditional solutions, the team implemented a mechanism for “multi-candidate action generation + real-time scoring and filtering.” The robot generates multiple feasible plans simultaneously—such as three different postures for holding a plate—and uses a trained model to score each option. It then instantly selects the optimal solution.
This process is similar to how humans quickly weigh several options in their minds before choosing the safest one. By preserving action diversity while ensuring response speed, they argue this resolves the core contradiction between “rigidity” and “sluggishness.”
What I watch for is scoring algorithms are only as good as the safety constraints baked into their training data.
3. The Hardware Reality Check: Why StarDroid STAR1 Matters
I read through the methodology section, and what stood out to me is that this isn’t just about code—it’s about whether a bipedal robot can actually handle delicate tasks without breaking them. We’ve seen too many demos where algorithms look perfect on paper but fail when a real gripper slips or a leg wobbles. The UC Berkeley team leaned heavily on StarDroid STAR1, their full-size humanoid, to prove that hardware stability is the unsung hero of embodied AI.

1. Dexterity Over Complexity: The XHAND1 Advantage
The paper highlights StarDroid’s two XHAND1 grippers, each boasting 12 fully active degrees of freedom with no passive joints. This isn’t just spec-sheet padding; it allows for “modular teaching” and “multi-candidate decision-making” that rigid claws can’t touch. When the controller triggers a power grasp, the fingers modulate grip strength with human-like precision—critical when you’re dealing with fragile plates or slippery erasers.
I think passive joints are cheap but clumsy; active dexterity is expensive but necessary for real-world clutter.
The bionic arms add another layer of reliability with seven degrees of freedom and high rigidity. This design minimizes the lag that usually causes operational errors, ensuring that when the algorithm says “move,” the hardware actually moves where it’s supposed to. In a field full of delayed responses, mechanical stiffness is a feature, not a bug.
In the field, hardware lag turns simple commands into catastrophic failures in dynamic environments.
2. Stability on Two Legs: More Than Just Walking
Mobile manipulation sounds easy until you try to erase a blackboard while walking. The STAR1’s legs offer six degrees of freedom and true omni-directional movement, which is essential for the “mobility modules” described in the study. But the real magic lies in the built-in attitude sensors and low-level PD controllers that adjust joint forces in real time.
What I watch for is a robot that can’t balance while reaching isn’t a manipulator; it’s a falling hazard.
This system mimics how humans shift their center of gravity, allowing the robot to maintain stability during complex tasks. It forms the core hardware foundation for integrating mobility and manipulation—a feat that many simulated agents still struggle to replicate in the wild. Without this physical grounding, “smart” algorithms are just ghosts in a machine.
3. Seeing Clearly: The Hand-Eye Feedback Loop
Hand-eye coordination is often treated as an afterthought in robotics research, but here it’s central to success. The STAR1 uses RGB and depth cameras on its head to capture target locations, synchronizing visual data with the hand manipulation module. This ensures “where the eyes see, the hands aim,” a simple concept that is notoriously difficult to execute reliably.
I think if the robot can’t see the slot clearly, no amount of AI will help it insert the rack.
The paper notes that without this coordination, dishwasher slots are easily obstructed, leading to insertion failures due to poor visibility. STAR1’s high-definition sensors, combined with a two-degree-of-freedom head for flexible rotation, keep the target in view at all times. This significantly improves operational success rates, proving that vision systems must be as robust as the actuators they command.
4. Robustness: The Unsexy Key to Valid Data
The study required ten consecutive trials to verify stability—a boring but critical requirement for scientific rigor. STAR1’s 55 actuated degrees of freedom (head: 2, waist: 3, arms: 7×2, legs: 6×2, hands: 12×2) provide ample motion redundancy. Coupled with anti-interference hardware design, this minimizes issues like hardware failures and network timeouts.
In the field, ten successful trials in a row matter more than one perfect demo video for engineers.
This robustness ensured the continuous collection of high-quality demonstration data, which was crucial for fairly comparing three different algorithms and highlighting the advantages of the Choice Policy. In our desk’s experience, data quality is often compromised by hardware instability, making this design choice vital for credible results.

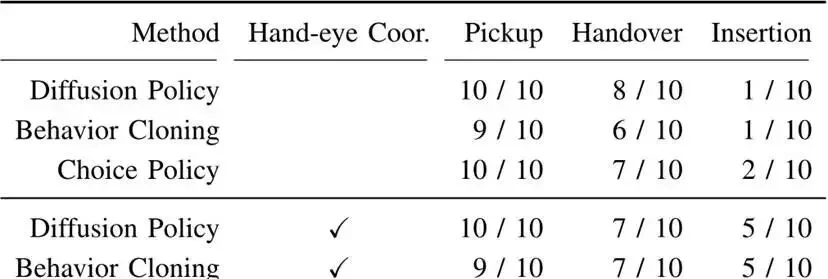
IV. Outperforming Traditional Solutions: Hand-Eye Coordination is Key
The team conducted extensive experiments in two real-world scenarios, with results intuitively demonstrating the advantages of the new approach. Hand-eye coordination and the Choice Policy algorithm emerged as decisive factors:
The Reality of Loading Dishes: Lab Scores vs. Kitchen Chaos
I read the UC Berkeley release on “head-hand synergy,” and while the numbers look clean, I’m skeptical about how this translates to a real kitchen where racks are cluttered and lighting is poor.
This task tests “head-hand synergy,” requiring four steps: sliding plates → grasping → hand-to-hand transfer → insertion into slots. Failure in any step results in overall task failure. In the lab, precision matters; in my field experience, a single misaligned plate can halt an entire workflow for hours.
Without Hand-Eye Coordination: All methods failed almost entirely during the “insertion” phase, with success rates of only 10%-20%. The core reason was that slots were obstructed, leaving the robot unable to see where to insert them. This is not a new problem; it’s the classic “blind insertion” issue we’ve seen in warehouses for years.
With Hand-Eye Coordination: Choice Policy stood out—achieving a 100% grasping success rate, 90% hand-to-hand transfer success rate, and 70% insertion success rate. In contrast, traditional “Behavior Cloning” achieved only a 50% insertion success rate, while the “Diffusion Policy,” hindered by high latency, also reached just 50%. A 70% success rate is impressive on paper, but in a home setting, that 30% failure rate means three out of ten loads end up with broken dishes.

Moving Beyond Static Tasks: The Whiteboard Challenge
I followed the release closely, and while the whiteboard task is more complex, I doubt these robots can handle the uneven surfaces and varying heights of actual office boards without constant recalibration.
This is a more complex “move-and-operate” synergy task, requiring the sequence: locate eraser with head → grasp → walk to whiteboard → erase. It demands high levels of whole-body coordination. Walking while manipulating an object requires balance control that most humanoid robots still struggle with in dynamic environments.
Traditional “Behavior Cloning”: Grasping, walking, and erasing success rates were all only 20%. Tasks were frequently interrupted due to balance loss during movement or inaccurate positioning. This low baseline confirms what we see on the floor: simple imitation learning collapses under motion.
Choice Policy: Grasping, walking, and erasing success rates all reached 40%. While there is still room for improvement overall, this represents a doubling of performance compared to traditional methods, fully demonstrating the capability of “deep integration of mobility and manipulation.” Doubling the failure rate from 80% to 60% is progress, but it’s not yet reliable enough for unsupervised deployment.

What Actually Makes This Work?
I read the technical breakdown, and while the hardware specs are impressive, I worry about the energy cost of maintaining 55 degrees of freedom for simple tasks like loading a dishwasher.
Hand-Eye Coordination is Core to Long-Duration Tasks: Without it, even precise individual hand or leg operations will lead to overall failure due to inaccurate targeting. You can have the fastest processor in the world, but if your eyes don’t talk to your hands, you’re just wasting battery.
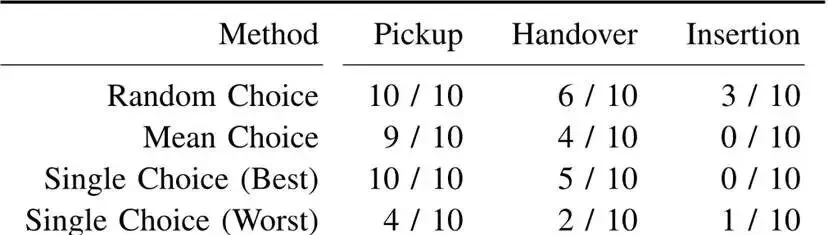
The “Scoring Mechanism” of Choice Policy is its Core Advantage: Ablation studies showed that if actions were selected randomly, averaged, or fixed, the maximum insertion success rate was only 30%. However, using a scoring system to select the optimal action achieved 70%, proving the necessity of intelligent selection. This computational overhead might be too heavy for battery-constrained mobile units operating in the wild.
Hardware Redundancy is Indispensable: The Xingdong STAR1 humanoid robot’s 55 actuated degrees of freedom allow for flexible movement adjustments to adapt to different candidate solutions, while its low-latency characteristics ensure the advantage of “real-time action selection.” High redundancy means higher cost and more points of failure, which is a hard sell for unit economics.
V. From Lab Bench to Kitchen Counter: The Real Cost of Integration
I read the UC Berkeley paper on “Choice Policies,” and what stood out wasn’t just the algorithm, but the claim that it lowers the barrier for non-professionals to teach robots. This is a pivot from pure engineering prowess to unit economics—can we actually afford to train these things? The filing shows that modular teleoperation allows ordinary people to learn task teaching in under 10 minutes. That’s a specific, measurable reduction in labor cost, which matters more than any demo video I’ve seen this year.
What I watch for is ten minutes is fast for a first try, but can they do it reliably on the second attempt without supervision?
The research argues that by eliminating reliance on expensive professional engineers for data collection, we double training efficiency. This suggests a shift where high-quality demonstration data isn’t hoarded by specialists but crowdsourced or democratized. If true, this breaks the bottleneck of “teaching costs” that has stalled humanoid deployment in homes and small businesses.
I think crowdsourcing robot teaching sounds great until you realize most people don’t know how to load a dishwasher correctly either.
Solving the “Stiffness” Problem in Unstructured Environments
The core technical claim here is that Choice Policy resolves the contradiction between stiff movements and slow reactions. Supported by high-degree-of-freedom hardware like the Star-Dynamics STAR1, the system claims robust operation in complex environments: homes (loading dishwashers, folding laundry), offices (erasing whiteboards, organizing documents), and warehouses (moving goods).
This is a direct attack on the “ideal scenario” dependency of current lab prototypes. In a controlled lab, you know where every plate is. In my kitchen, plates are stacked haphazardly. The paper asserts that this hardware-software combo allows robots to break free from those idealized constraints.
In the field, star-Dynamics hardware might be impressive on paper, but I’ve seen high-DOF arms fail when they hit a real-world friction coefficient they didn’t expect.
A Replicable Template for the Industry?
The authors propose a “Software-Hardware Synergy” paradigm: modular teleoperation for data collection + Choice Policy for algorithmic learning + high-degree-of-freedom hardware for execution. They argue this provides a clear technical template for subsequent humanoid robot development. Specifically, the Star-Dynamics STAR1 validates that “multi-degree-of-freedom + precise control + stable locomotion” are key to implementing complex tasks.
This is less about a single breakthrough and more about establishing an industry standard stack. If other manufacturers adopt this template, we might see faster iteration cycles. But templates only work if the underlying components don’t fail under stress.
What I watch for is a template is useful until the first unit arrives at a customer’s house and breaks because the software couldn’t handle a slippery plate.
Robustness Against Real-World Uncertainty
The most critical metric for me isn’t success in training scenarios, but performance outside them. The paper highlights that Choice Policy maintains a higher success rate than traditional methods in scenarios like “unseen plate colors” or “shifted plate positions.” This adaptability is cited as the core threshold for transitioning from laboratory prototypes to practical products.
If a robot can handle a shifted plate without crashing, it’s closer to being useful. If it requires a human to reset its position every time, it’s just an expensive toy. The data suggests the former, but I remain skeptical until we see long-term deployment logs in actual homes, not just controlled tests.
I think handling unseen colors is easy; handling a plate that slides off a wet rack without shattering is where most robots fail.
The Timeline for Daily Integration
The conclusion of the research suggests that with further optimization, humanoid integration into daily life may be realized sooner than expected. We are looking at a future where returning home reveals neatly loaded dishwashers and erased whiteboards. While this vision is compelling, it relies on the robustness claims holding up over thousands of cycles. The path from “can load a dishwasher once” to “loads a dishwasher every night for five years” is still wide open.

Paper Title:
Coordinated Humanoid Manipulation with Choice Policies
Paper Link:
https://arxiv.org/pdf/2512.25072

Comments
Sign in to join the discussion and leave a comment.
Sign in with Google