Honestly, a 23.67% score on SWEBench is a massive leap for non-GPT-4o models. This proves agent architectures can finally bridge the gap between code generation and actual software engineering. Chinese startups are no longer just catching up; they are setting new technical standards. Investors should watch OpenCSG closely as a serious contender in the LLM4SE space.
Yao Class Team Shatters Devin’s Record on SWEBench
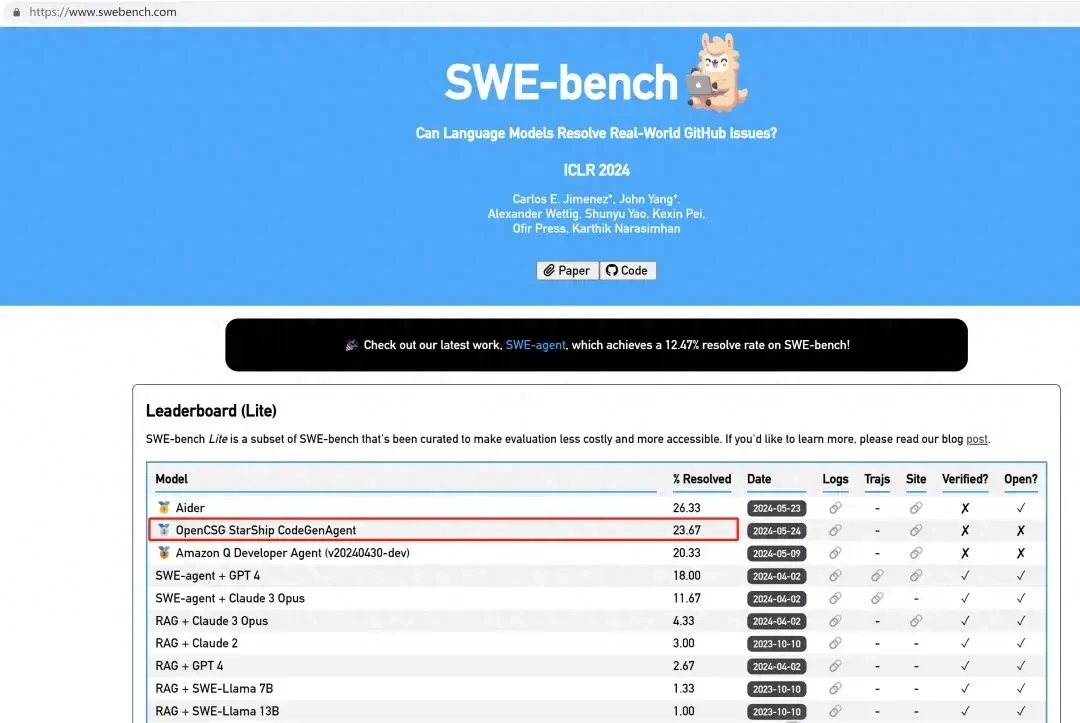
StarShip CodeGen Agent, built by OpenCSG—a startup founded by members of Tsinghua University’s elite Yao Class—has secured second place globally on the SWEBench leaderboard with a score of 23.67%.
More importantly, it established a new State-of-the-Art (SOTA) record for non-GPT-4o base models.
SWEBench is not a toy benchmark. It mirrors real-world programming scenarios with brutal rigor. Models must understand requirements, coordinate changes across multiple functions and classes, interact with execution environments, handle ultra-long contexts, and perform complex logical reasoning. This goes far beyond traditional code completion tasks.
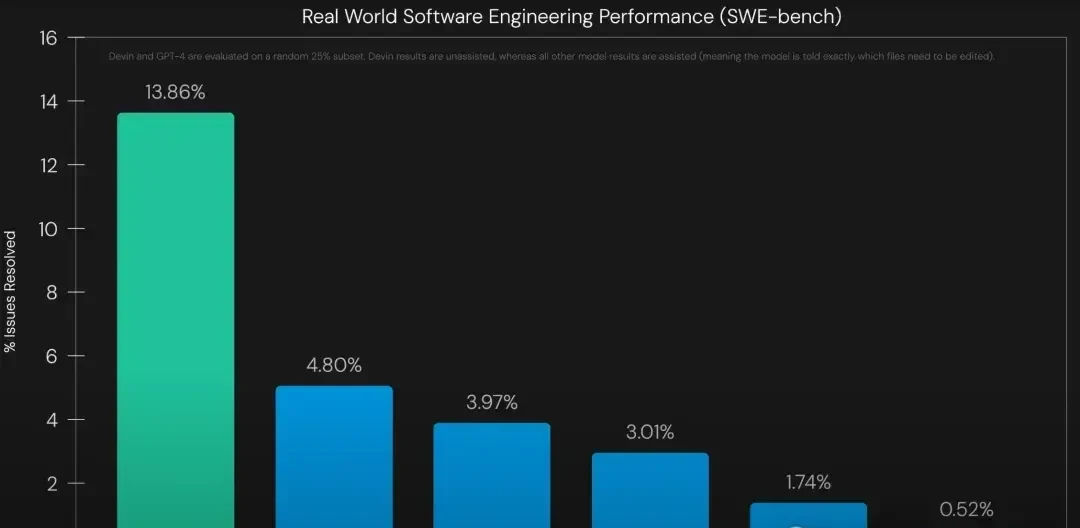
The difficulty is stark. In these tests, the industry’s most advanced models struggled: GPT-4 solved only 1.74% of problems, while Devin managed 13.86%.
OpenCSG’s achievement signals a leading step by Chinese companies in driving language models toward greater practicality and autonomy.
The Reality of Large Model Programming
I followed the trajectory of this space closely since March 2024, when Devin launched as the first AI software engineer. Despite controversies, its ability to handle the entire software development lifecycle—from planning to deployment—ignited excitement across Silicon Valley.
Devin didn’t just write code; it autonomously handled website building, bug hunting, and model fine-tuning.
Why did Devin dare to challenge base models like GPT-4? Because software engineering is more than syntax. It requires requirement understanding, code interpretation, planning, debugging, and exception handling. Each stage dictates whether a model is usable or just a parlor trick.
Princeton University introduced SWEBench to quantify this end-to-end capability. The results were sobering: GPT-4 scored only 1.74%. Even with Retrieval-Augmented Generation (RAG), the score stayed below 3%. Relying solely on base models for real-world programming was, and remains, unfeasible.
Devin’s innovation was architectural. By constructing workflows based on Agents, it lifted SWEBench success rates significantly. In March, Devin independently solved 13.86% of problems, moving the field from “nearly unusable” to “promising.”
This triggered a rush. Major tech giants and AI startups flooded the LLM for Software Engineering (LLM4SE) field, rewriting records continuously. By late April 2024, Amazon Q Developer Agent set the bar at 20.33%.
Until now, Chinese companies had shown diversity in base model rankings but rarely competed in these high-difficulty challenges. OpenCSG has just broken that silence—and the record.
The China Playbook: Speed Over Scale
OpenCSG has jumped to second place on the SWEBench leaderboard with its OpenCSG StarShip CodeGen Agent. It hit a 23.67% pass rate in the Lite evaluation. That number beats Devin and Amazon’s current performance. This is not just a technical tweak; it is a market signal. Chinese startups are bypassing foundational model wars to optimize application-layer agents. They are moving faster than Western incumbents who are bogged down in infrastructure costs.

The company is barely a year old. OpenCSG (Kaifang Chuanshen) claims to build an ecosystem for large models. It connects upstream and downstream AI enterprises. The goal is providing tool platforms for vertical industry applications. I see this as a classic consolidation play. They are aggregating demand before they even have a dominant product.
The leadership team explains the speed. CEO Chen Ran has built multiple commercial companies in open source. CTO Wang Wei, the CTO, graduated from Tsinghua University’s Yao Class (Class of 2005). He brings years of AI R&D experience. The core team includes graduates from Tsinghua, Peking University, Wharton, and HKUST. This is not a ragtag garage project. It is a well-funded, elite execution engine.
I think elite talent density in China allows for rapid iteration that Western firms cannot match on speed alone.
Engineering Over Hype
While competitors chase base models or RAG architectures, OpenCSG picked a narrow lane: programming Agents and algorithm optimization. I followed their technical approach closely. It is distinct from generic LLM+RAG frameworks.
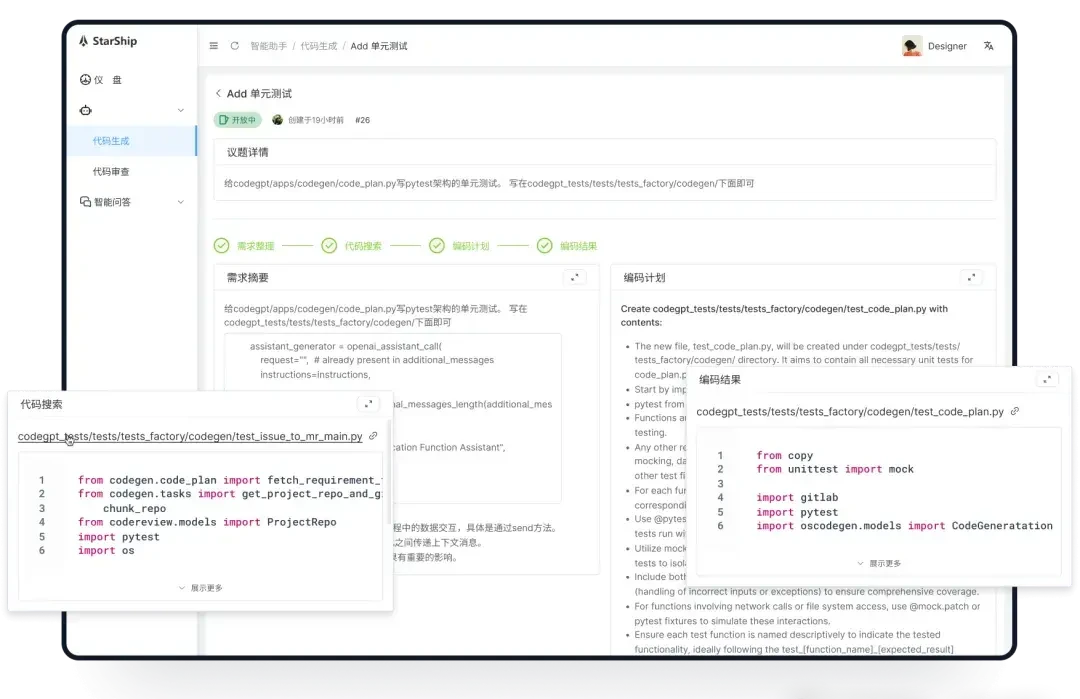
The StarShip CodeGen Agent is customized for software R&D. It handles requirement understanding, code retrieval, planning, coding, and iterative verification via LLM Agents. Crucially, it integrates AST syntax analysis and dependency retrieval. This deep optimization targets precision. Most agents fail at context retention; this one tries to enforce structural integrity.
At the algorithm level, they address API conflicts from version changes. OpenCSG uses an “adaptive teacher mode.” The teacher model analyzes code change logs to generate high-quality programming data. This data improves the base model’s generation performance. Evaluations show these improvements significantly outperform current RAG modes. This is especially true for projects with frequent API updates. They have submitted related findings to international conferences.
The way I see it, focusing on engineering constraints like AST analysis yields higher utility than pure scale in coding tasks.
The Moat Is Narrow, But Deep
This dual approach of algorithm and engineering allowed the CodeGen Agent to stand out. It is not a general-purpose breakthrough. It is a specialized tool for specific pain points in software development.
For investors, this highlights a shift in value creation. The alpha is no longer just in the model weights. It is in how you wrap those weights around real-world engineering workflows. OpenCSG’s 23.67% score proves that targeted optimization can disrupt established players like Devin. However, their ecosystem strategy remains unproven at scale.
Honestly, specialized agents will eat into general-purpose model market share faster than expected.
StarShip: The Appliance Strategy
If CodeGen was a test drive, StarShip is OpenCSG’s actual product roadmap. CEO Chen Ran isn’t selling a copilot; he’s selling a workforce. The platform bundles agents for coding, review, and search into “digital employees” designed to operate without human intervention. This shifts the value proposition from assistance to automation.
I think automation promises are cheap; execution is where vendors fail. The way I see it, independent agents require robust guardrails OpenCSG hasn’t shown yet.
The company is moving fast, launching CSGHub (open-source models), Wukong (pre-trained models), and CSGCoder (fine-tuned code). Chen Ran uses a utility metaphor: if large models are electricity, CSGHub is the grid, and StarShip is the appliances delivering value. It’s a clear attempt to commoditize AI infrastructure while monetizing the end-user experience.
CTO Wang Wei frames this as an engineering challenge rather than just an AI one. He argues the question isn’t if models boost productivity, but how. His team believes open source was the catalyst for their speed, allowing them to iterate rapidly in a crowded market.
The Open Source Paradox and Benchmark Reality
Wang Wei aligns with Sam Altman’s view: open source is just a model; product value matters more. This pragmatic stance suggests they know models are becoming commodities. They plan to give back to the community, but their primary goal is capturing enterprise and individual users through tangible utility.
The benchmark talk is where skepticism is warranted. Wang admits SWEBench scores for GPT-4o will likely exceed 30% soon, potentially hitting 50% next year. He dismisses raw numbers in favor of “qualitative shifts” from usable to highly effective. I read this as a deflection: they are betting on workflow integration rather than pure coding accuracy.
Honestly, benchmarks are lagging indicators; workflow integration is the real moat. I think 50% SWEBench scores won’t save vendors who can’t handle edge cases.
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google