Tencent Hunyuan Launches First Open-Source Hybrid Reasoning Model, Exceling in Agent Tool Use and Long Text Comprehension
On June 27, Tencent Hunyuan announced the open-sourcing of its first hybrid reasoning Mixture-of-Experts (MoE) model, Hunyuan-A13B. This move shifts the burden of proof to enterprises: can you actually secure and govern an 80-billion-parameter architecture running on consumer-grade hardware? I see this as a significant shift in accessibility, but also a new vector for governance risk if deployment controls are lax.
With a total parameter count of 80 billion and only 13 billion active parameters, the model delivers performance comparable to leading open-source models with similar architectures, while offering faster inference speeds and higher cost-effectiveness. This development lowers the barrier for developers to access superior model capabilities. As of today, the model is available on open-source communities such as GitHub and Hugging Face. The model API has also officially launched on the Tencent Cloud website, supporting rapid integration and deployment.
Hunyuan-A13B marks the industry’s first 13B-level open-source MoE hybrid reasoning model. Leveraging an advanced architecture, it demonstrates robust general capabilities, achieving strong results across multiple authoritative industry benchmark datasets. It shows particularly outstanding performance in Agent tool calling and long-document comprehension.
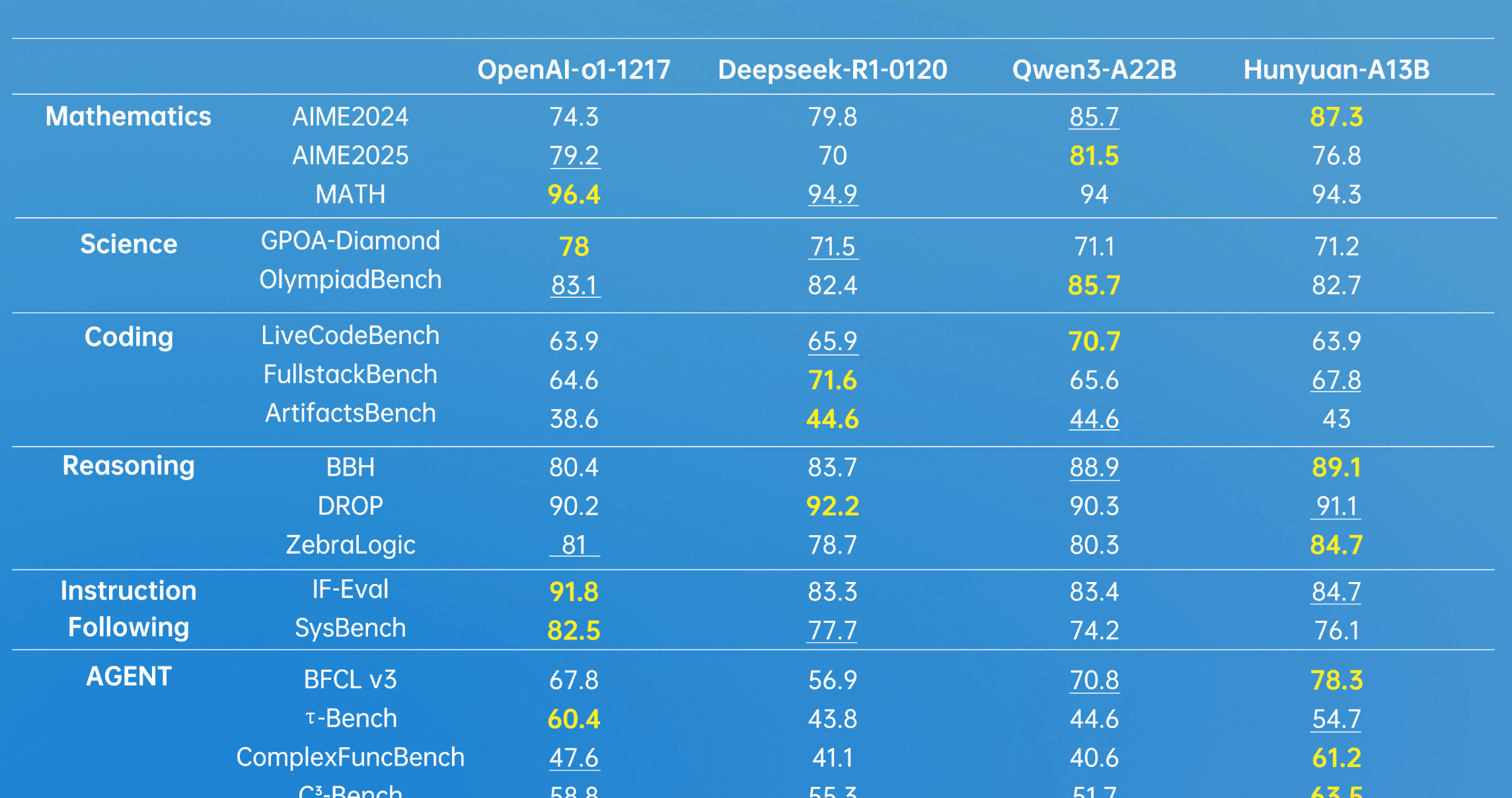
*Bold indicates the highest score; underlined text denotes second place. Data sourced from various public test dataset scores for the model.
Regarding the currently popular Agent capabilities of large language models, Tencent Hunyuan has developed a multi-Agent data synthesis framework. This framework integrates diverse environments such as Model Context Protocol (MCP), sandboxes, and large language model simulations. Through reinforcement learning, Agents are enabled to autonomously explore and learn across various environments, further enhancing the performance of Hunyuan-A13B.
I think autonomous agent exploration without strict guardrails increases liability for unintended actions. My sense is enterprises must verify MCP integration points before allowing external tool access.
In terms of long-document processing, Hunyuan-A13B supports a native 256K context window and has achieved excellent results in multiple long-text datasets.
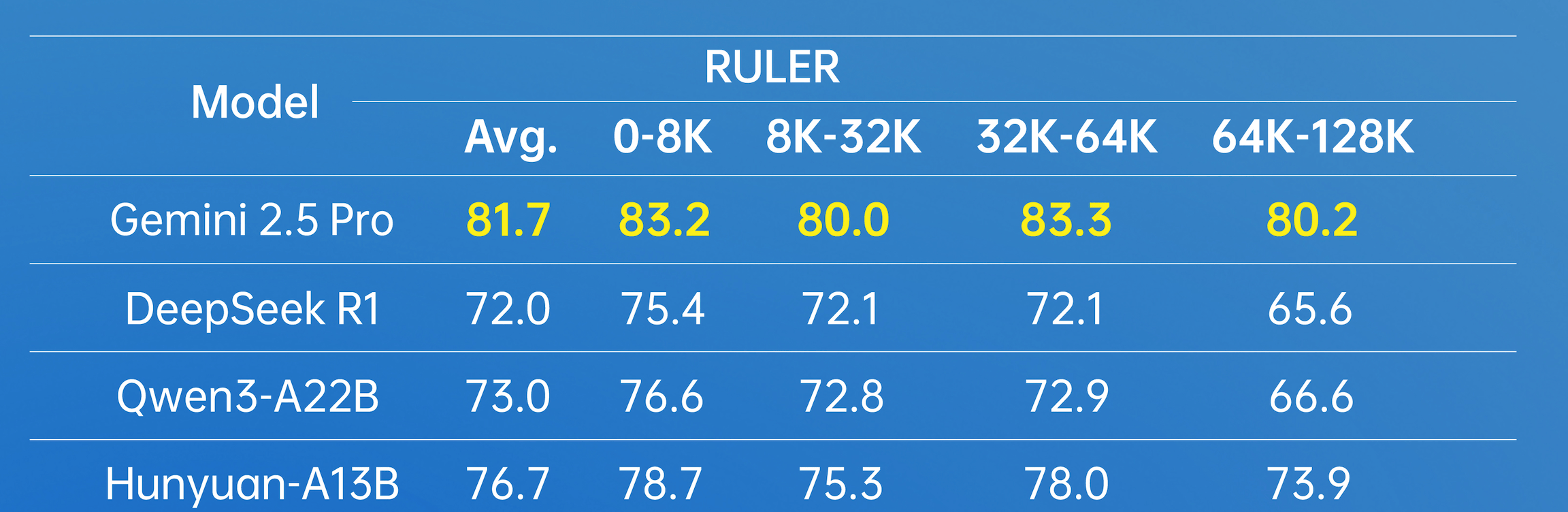
In practical usage scenarios, the Hunyuan-A13B model allows users to select a thinking mode based on their needs. The “fast thinking” mode provides concise and efficient outputs, suitable for simple tasks where speed and minimal computational overhead are prioritized. Conversely, “slow thinking” involves deeper and more comprehensive reasoning steps, such as reflection and backtracking. This hybrid reasoning approach optimizes the allocation of computational resources, allowing users to balance efficiency and task-specific accuracy by switching between think and no_think modes.
The Hunyuan-A13B model is particularly developer-friendly. Under strict conditions, it can be deployed with just one mid-to-low-end GPU card. Currently, Hunyuan-A13B has integrated into the mainstream open-source inference framework ecosystem, offering lossless support for various quantization formats. At equivalent input-output scales, its overall throughput exceeds that of frontier open-source models by more than two times.
What concerns me is that low hardware requirements do not exempt organizations from data privacy compliance obligations. I followed the release notes closely; the quantization support simplifies but does not eliminate security audits.
Hunyuan-A13B incorporates innovative technologies from Tencent Hunyuan across multiple stages, including pre-training and post-training, which collectively enhance its inference performance, flexibility, and efficiency.
During the pre-training phase, Hunyuan-A13B was trained on 20 trillion tokens of corpus data covering various domains. High-quality corpora significantly improved the model’s general capabilities. Furthermore, through systematic analysis, modeling, and validation, the Tencent Hunyuan team constructed a joint scaling law formula applicable to MoE architectures. This discovery refined the theoretical framework for MoE architecture scaling laws and provided quantifiable engineering guidance for MoE design, greatly enhancing pre-training effectiveness.
In the post-training phase, Hunyuan-A13B adopted a multi-stage training approach to boost inference capabilities while maintaining general competencies in content creation, comprehension, and Agent functionalities.
Figure: Four steps of p
Post-training refinements and new evaluation benchmarks
I read the release notes carefully, and what stood out to me is Tencent’s dual approach: releasing a model while simultaneously publishing rigorous evaluation datasets. This shifts some of the burden of proof onto the community to validate claims against standardized metrics.
Tencent Hunyuan has open-sourced two new datasets designed to address specific gaps in industry evaluation standards. ArtifactsBench establishes a benchmark of 1,825 tasks across nine domains—ranging from web development and data visualization to interactive games—to bridge the visual and interaction gap in code generation. Difficulty levels are graded for comprehensive assessment. Meanwhile, C3-Bench targets Agent scenarios by designing 1,024 test cases that address three key challenges: planning complex tool relationships, handling critical hidden information, and making dynamic path decisions. These benchmarks aim to identify potential weaknesses in model capabilities before enterprise deployment.
I think enterprises must verify if these new benchmarks align with their specific compliance requirements for agent autonomy. My sense is the focus on “hidden information” suggests Tencent is aware of hallucination risks in complex tool-use chains. I believe the 1,825-task scope provides a more realistic stress test than generic coding benchmarks.
Internal adoption metrics and performance claims
Hunyuan-A13B is not just an academic exercise; it is one of the most widely used large language models within Tencent internally. Over 400 business units are fine-tuning or directly invoking it, generating more than 130 million daily requests. This upgrade and subsequent open-sourcing represent another significant milestone for the Hunyuan LLM series following the release of the “large” version. Despite having fewer parameters, Hunyuan-A13B achieves substantial improvements in performance and effectiveness. I followed the trajectory here: moving from internal scale to external open-source is a high-stakes move that requires robust governance frameworks.
What concerns me is that the 130 million daily request volume indicates significant real-world load testing, which reduces theoretical risk. I advise enterprises to audit these 400 business units’ use cases for potential data leakage patterns.
Future roadmap and open-source commitments
Moving forward, Tencent Hunyuan will introduce more models with varying sizes and features, sharing practical technologies with the community to foster a thriving open-source ecosystem for large models. Tencent Hunyuan remains committed to embracing open source, continuously promoting the open-sourcing of its full range of multi-size and multi-scenario models. Its foundational models across various modalities—including images, video, 3D, and text—are already fully open-sourced.
In the future, Hunyuan plans to release hybrid reasoning models in multiple sizes, including dense models ranging from 0.5B to 32B, as well as MoE models with 13 billion active parameters. These are designed to cater to diverse enterprise and edge-side needs. Additionally, its image, video, 3D, and other multimodal foundational models, along with supporting plugin models, will continue to be open-sourced. I see this as a strategic move to lock in developers across the spectrum from edge devices to cloud infrastructure.

Comments
Sign in to join the discussion and leave a comment.
Sign in with Google