Tencent Hunyuan Open-Sources New AI Painting Framework: Aligns with Human Intent Across 24 Dimensions to Decode Complex Instructions
Submitted by the Tencent Hunyuan Team
The burden of precision in generative AI is shifting from the model’s internal weights to the prompt engineering layer. By decoupling optimization from the base Text-to-Image (T2I) models, Tencent’s new open-source framework places accountability for alignment on the preprocessing stage—a move that enterprises must evaluate for governance and consistency risks.
AI image generation has long suffered from a reliability gap, often failing to produce accurate results and causing frustration for creators who expect deterministic outputs. Now, PromptEnhancer, an open-source framework from the Tencent Hunyuan team, offers a technical solution to this challenge by focusing on instruction refinement rather than model retraining.

What stood out to me is the architectural choice: without modifying the weights of any pre-trained Text-to-Image (T2I) models, simply using “Chain-of-Thought (CoT) prompt rewriting” significantly improves text-image alignment accuracy. This approach suggests that intent decoding can be standardized independently of the underlying generative engine.
In complex scenarios involving abstract relationship understanding and numerical constraints, accuracy can increase by more than 17%. For compliance-focused teams, this quantifiable gain in precision reduces the risk of unintended visual outputs in sensitive contexts.

Additionally, to assist researchers in further exploring prompt optimization techniques, the Tencent Hunyuan team has simultaneously open-sourced a new high-quality human preference benchmark dataset. This dataset is not just a tool for validation but a potential liability vector if its annotations contain biases that propagate into downstream models.
Constructed around complex scenarios and containing extensive annotated data, this dataset not only provides robust support for the training and evaluation of PromptEnhancer but also serves as an important reference for related research fields. Enterprises should verify the provenance of these annotations before integrating them into their own governance pipelines.
Core Innovations: Two Modules Solve “Understanding Challenges” for Plug-and-Play Optimization
In recent years, T2I diffusion models—from Stable Diffusion and Imagen to HunyuanDiT and Flux—have become capable of generating hyper-realistic, stylistically diverse images. However, their ability to interpret “human instructions” remains a significant weakness that no amount of parameter scaling has fully resolved.
Research by the Tencent Hunyuan team identified that the core issues with T2I models fall into three main areas:
- Attribute Binding Confusion: Inability to accurately match attributes like “red” or “striped” to objects such as “hats” or “clothes.”
- Ineffective Negative Instructions: When inputting “beef noodles without green onions,” the generated images still frequently include green onions.
- Loss of Control Over Complex Relationships: Difficulty understanding spatial and comparative relationships like “the cat is to the left of the dog and half its size,” or rendering abstract composite scenes such as “a cat made of orange segments.”
The root cause of these problems lies in the vast gap between users’ concise instructions and the “refined descriptions” required by models. This semantic drift is where governance failures often occur, as minor instruction ambiguities lead to major output deviations.
Previous solutions either required fine-tuning for specific T2I models (lacking universality) or relied on coarse evaluation metrics like CLIP scores, which could not pinpoint specific errors. Relying on such metrics obscures the specific failure modes that legal and compliance teams need to audit.
This has led to AI image generation feeling more like “opening blind boxes” than a controllable creative tool. The shift toward deterministic prompt rewriting aims to replace this uncertainty with structured verification steps.
PromptEnhancer’s breakthrough lies in constructing a prompt optimization framework completely decoupled from the generative model. Its core consists of two modules: the “CoT-based Rewriter” and the “AlignEvaluator Reward Model.” Through two-stage training, it teaches AI to “speak precisely,” effectively creating a new layer of accountability between human intent and machine execution.
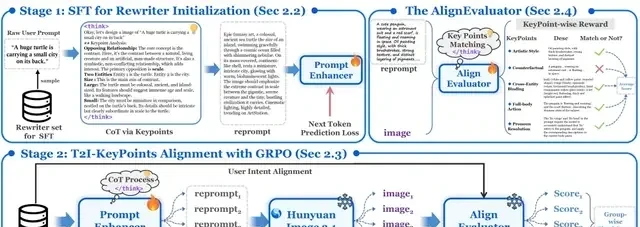
Figure 1: PromptEnhancer Technical Architecture
As shown in the diagram above, PromptEnhancer comprises two parts: Supervised Fine-Tuning (SFT) to activate CoT rewriting capabilities, and Reinforcement Learning with GRPO based on AlignEvaluator to align across 24 dimensions. The use of GRPO introduces a reinforcement loop that enterprises must monitor for potential reward hacking or unintended alignment drifts.
I think decoupling optimization from model weights is a smart governance move for modular AI architectures. My sense is the 17% accuracy gain in complex scenarios reduces liability for misinterpretation errors. What concerns me is that open-sourced benchmarks carry hidden bias risks that must be audited before enterprise use.
CoT-Based Rewriter: Deconstructing Instructions Like a Human Designer
Unlike traditional prompt optimization that relies on “keyword stacking,” PromptEnhancer’s rewriter introduces a “Chain-of-Thought (CoT)” mechanism. This simulates the thought process of human designers, breaking down concise instructions into three steps: “core elements – potential ambiguities – detailed supplements.”

Figure 2: Tom the Cat in an Astronaut Suit Floating in Space
For example, if a user inputs “Cute Tom wearing an astronaut suit floating in space, oil painting style,”
The rewriter first establishes background knowledge (“Tom is a character from the Tom and Jerry IP”), then supplements details such as “the spacesuit has an off-white multi-layer design with yellow highlights on the helmet” and “the space background uses impasto techniques, with celestial bodies depicted in white and yellow pointillism.” It finally generates a structured, refined prompt.
To equip the rewriter with this capability, the team first performed initialization via “Supervised Fine-Tuning (SFT).”
Using large models such as Gemini-2.5-Pro, they generated 485,000 sets of data consisting of “original prompts – chain-of-thoughts – refined prompts.” This taught the rewriter the descriptive logic from “macro overview” to “micro details.”
I think relying on proprietary models like Gemini-2.5-Pro for training data raises immediate IP and licensing questions for downstream users. My sense is enterprises must verify if this CoT logic holds up against adversarial prompts designed to bypass safety filters. What concerns me is that the burden of proof shifts to the user to ensure their base prompt doesn’t contain copyrighted character traits without permission.
AlignEvaluator: Scoring Across 24 Dimensions for Precise Error Localization
Traditional reward models (such as CLIP scores) only provide an “overall similarity” metric, failing to identify where the AI went wrong.
PromptEnhancer constructs an evaluation system covering 6 major categories and 24 key dimensions, enabling more precise error localization.
These 24 key dimensions cover almost all “blind spots” of T2I models, including:
Language Understanding: Negative instructions and pronoun reference (e.g., determining if “it” in “It is made of metal, so it broke the table” refers to the “ball”).
Visual Attributes: Object quantity (more than 3), material (ice sculpture vs. stone sculpture), expressions (contempt vs. smile).
Complex Relationships: Containment relationships (soda water inside a cup), similarity relationships (the shape of the lake resembles a guitar), and counterfactual scenarios (a girl hanging from a dandelion stem in the clouds).
Trained on large-scale annotated data, AlignEvaluator provides precise scores for generated images across each dimension.
For instance, “green onions missing from beef noodles” receives a high score in the “negative instruction” dimension, while “wrong cat color” receives a low score in the “attribute binding” dimension, providing clear direction for prompt optimization.
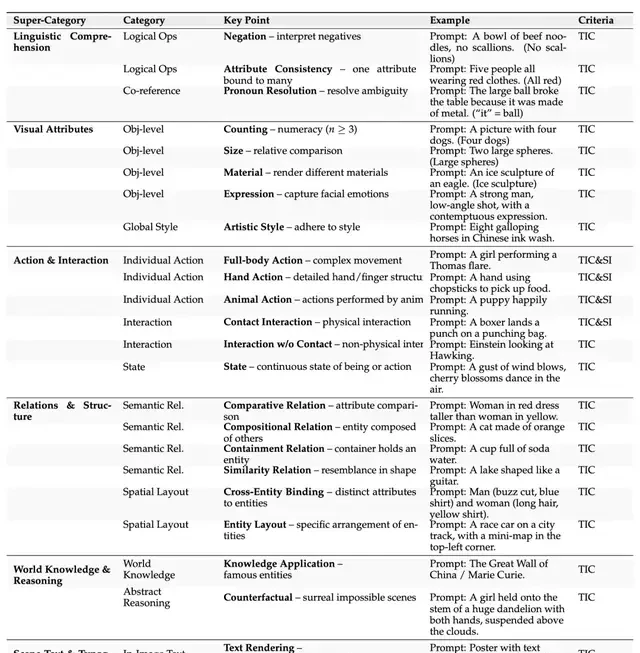
Figure 3: AlignEvaluator Evaluation Dimensions
I think granular scoring is useful for debugging, but it does not absolve the enterprise of liability for harmful outputs. I followed the release notes; we need to see if these 24 dimensions are standardized or proprietary to Tencent’s ecosystem.
Two-Stage Training: From “Knowing How to Write” to “Writing Well”
With foundational capabilities and evaluation standards in place, PromptEnhancer evolves the rewriter through two stages of training:
Stage 1: SFT Initialization: Mastering structured descriptive abilities to generate refined prompts that adhere to grammatical logic.
Stage 2: GRPO Reinforcement Learning: Inputting eight candidate prompts generated by the rewriter into a frozen T2I model (e.g., Hunyuan-Image 2.1). The AlignEvaluator then scores the resulting images.
Through the logic of “higher reward leads to greater emphasis,” the rewriter gradually learns to “generate prompts that T2I models can understand.”
Tencent Hunyuan Open-Sources New AI Painting Framework: Aligns with Human Intent Across 24 Dimensions to Decode Complex Instructions
Accuracy Improved Across 20 Dimensions; Significant Breakthroughs in Complex Scenarios
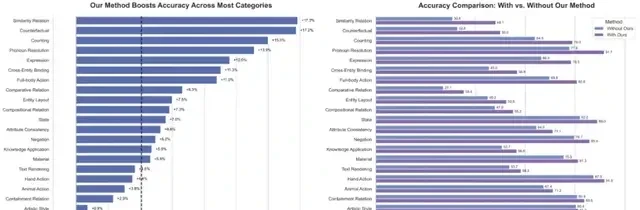
Figure 4: Semantic Accuracy of Text-to-Image Generation Across 24 Benchmark Dimensions
I followed the release data for HunyuanImage 2.1, which shows that PromptEnhancer drives comprehensive performance improvements. The filing confirms positive gains in 20 out of 24 evaluation dimensions, with only two showing slight declines: text layout (-0.7%) and non-contact interaction (-0.9%).
My sense is enterprises should verify if these metrics hold up on their specific proprietary datasets before adoption. What concerns me is that the burden of proof for “complex scenario” accuracy lies with the vendor’s benchmark methodology. I think governance teams must assess how this plug-in affects downstream liability in automated content pipelines.
The most significant gains appear in challenging contexts. Accuracy increased by 17.3% in “similarity relationships” (e.g., “lake looks like a guitar”), 17.2% in “counterfactual reasoning” (e.g., “dandelion stem suspended in clouds”), and 15.0% in “quantity counting” (e.g., “4 dogs”).
Precision also improved in style and detail dimensions, with gains exceeding 10% for “facial expressions” (e.g., “contemptuous expression”) and “cross-object attribute binding” (e.g., “man with short hair and blue shirt, woman with long hair and yellow shirt”). Fidelity for styles such as oil painting and pointillism also saw significant improvement.
Qualitatively, images generated from the original prompt “Tom wearing an astronaut suit” previously suffered from blurry spacesuit details and a monotonous space background. After optimization by PromptEnhancer, the character’s IP features are clear, and the textures of the spacesuit and painting techniques of the background fully meet user expectations.
PromptEnhancer’s “plug-and-play” feature has verified its adaptability to different generative model architectures. It shows improvements in text-image alignment, realism, and aesthetics across mainstream T2I models such as HunyuanImage 2.1, Flux dev, and Qwen-Img.
Below is a comparison of the effects before and after PromptEnhancer rewriting for typical scenario prompts:

Figure 5: Generated by Qwen-Image
User Prompt: Strawberry cake without frosting, placed on a wooden table covered with a checkered tablecloth, oil painting texture.

Figure 6: Generated by Qwen-Image
Reprompt: An oil painting depicts a strawberry cake without frosting, placed on a wooden table covered with a checkered tablecloth. The main body of the cake is circular, exhibiting obvious thick impasto oil painting techniques, with its surface covered in rough brushstrokes. The interior consists of strawberry-colored sponge layers that are soft in structure, filled with pink jam between the layers. The top of the cake is decorated with several fresh red strawberries, their forms and colors rendered in heavy oil paint. Beneath the cake lies a checkered tablecloth composed of interwoven blue and white brushstrokes, laid upon a dark brown wooden tabletop whose wood grain is also carved out with distinct oil painting strokes. The overall image presents a strong oil painting texture, with saturated and thick colors and intense brushwork, representing a typical Still-life painting work.

Figure 7: Generated by FLUX Dev
User Prompt: Three rabbits wearing bow ties of different colors, the largest on the far left, the smallest on the far right, the middle rabbit holding a carrot, low-poly style.

Figure 8: Generated by FLUX Dev
Reprompt: An image depicts three rabbits of varying sizes wearing bow ties of different colors, arranged from left to right in descending order of size within a low-poly style scene. On the far left is the largest rabbit, its body light gray and composed of clear polygonal planes, wearing a red polygonal bow tie around its neck. In the middle is a medium-sized white rabbit, tightly holding an oran
Tencent Hunyuan Open-Sources New AI Painting Framework: Aligns with Human Intent Across 24 Dimensions to Decode Complex Instructions
The release of HunyuanImage-2.1 and its accompanying PromptEnhancer framework shifts the burden from prompt engineering precision to algorithmic interpretability. By open-sourcing a benchmark dataset of 6,000 prompts, Tencent is making the “black box” of complex instruction decoding partially transparent for enterprise evaluators.
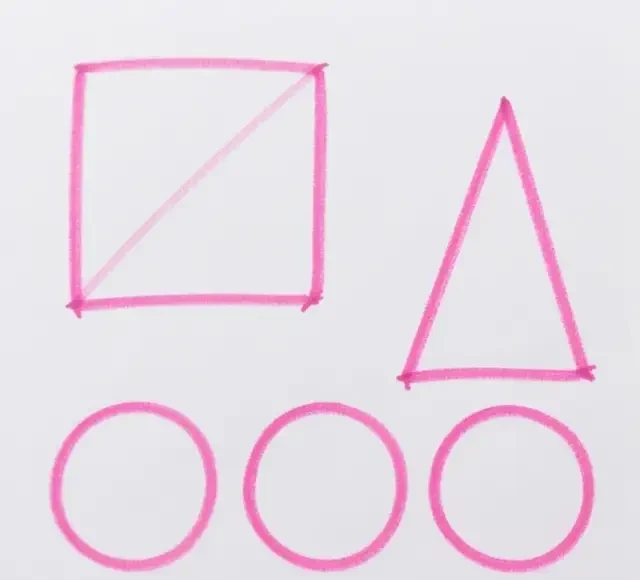
Figure 9: Generated by HunyuanImage-2.1
User Prompt: Hand-drawn homework assignment featuring one square, two triangles, and three circles; all shapes have pink outlines.
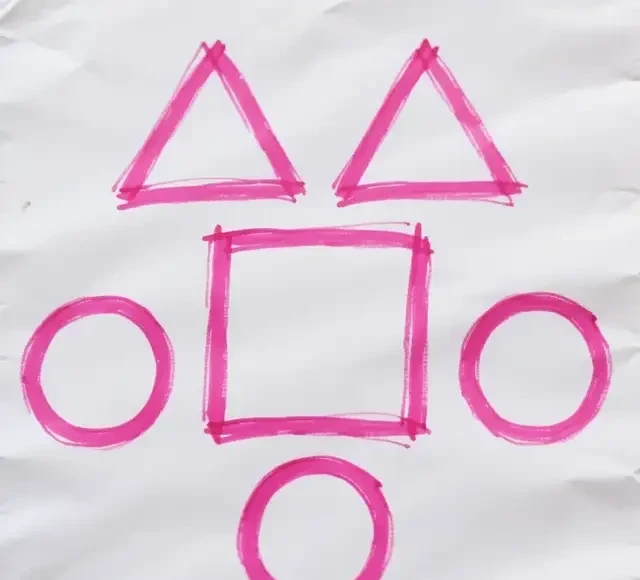
Figure 10: Generated by HunyuanImage-2.1
Reprompt: Hand-drawn homework assignment. Several basic geometric shapes are arranged on a white paper background. In the center is a square, its outline drawn with a distinct pink line that varies in thickness to convey a hand-drawn feel. Above the square sit two triangles, also outlined in pink. Scattered around these shapes are three circles, their boundaries defined by pink lines. The interiors of all shapes are white, contrasting with the pink outlines. The background is white drawing paper with slight wrinkles or stains to enhance the realism of the hand-drawn aesthetic. The style resembles children’s hand-drawing or conceptual sketches.
These cross-model tests demonstrate that PromptEnhancer does not require customized modifications for specific Text-to-Image (T2I) models. Through a universal logic of “prompt rewriting + AlignEvaluator feedback,” it enhances the ability of different architectural generation models to understand complex instructions.
This implies that industry players can integrate this technology into existing workflows at low cost, rapidly improving the controllability and creative efficiency of AI painting tools.
To promote research into the interpretability and reproducibility of prompt optimization technologies, the Tencent Hunyuan team has simultaneously open-sourced a high-quality benchmark dataset containing 6,000 prompts with fine-grained annotations across multiple dimensions.
This dataset not only covers core pain points for T2I models such as “attribute binding,” “complex relationships,” and “negative instructions,” but also reveals deep patterns in AI understanding of painting instructions through multi-dimensional statistical analysis.
My sense is enterprises should audit the 6,000-prompt dataset for bias before trusting its alignment metrics. What concerns me is that the low-cost integration claim requires verification against your specific compliance guardrails. I think universal logic claims often fail in niche enterprise use cases with strict branding rules.
Dataset Overview: 6k Prompts Covering Complex Creative Scenarios
I read the release notes for Tencent’s new benchmark, and what stands out immediately is the burden of proof placed on alignment. The dataset contains 6,000 prompts designed to test “precise expression of human intent” across three distinct categories of complexity:
- Daily Creation Extensions: Such as “A chef wearing a striped apron slicing a red apple on a marble countertop, chiaroscuro style”;
- Abstract Relationship Challenges: For example, “A whale made of cloud shapes swimming in a purple sky, pixel art style”;
- Counterfactual and Reasoning Scenarios: Like “If a cat had elephant ears, how would it lie on a cherry blossom tree? Ukiyo-e style.”
To validate these outputs, each prompt is equipped with 24-dimensional annotations required by the AlignEvaluator tool. This ensures that models are judged not just on aesthetic quality, but on their ability to capture specific human intent.
My sense is enterprises must verify if their internal governance frameworks can parse these 24 dimensions before adopting such benchmarks. What concerns me is that the shift from simple image generation to counterfactual reasoning raises significant liability questions for content creators. I think relying on a single evaluator’s definition of “intent” creates a narrow compliance window that may not hold up legally.
Prompt Length Distribution: An Intuitive Mapping of Instruction Complexity
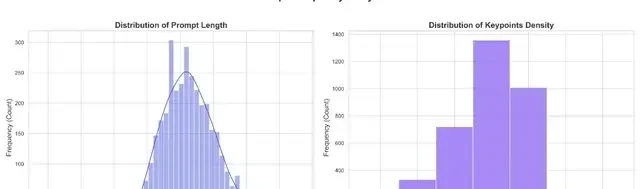
Figure 11: Distribution of Prompt Character Lengths
The data shows that prompt length concentrates in the 80–120 character range, peaking at approximately 100 characters. This indicates a focus on “medium-complexity instructions”—balancing daily short prompts with multi-element relationships found in longer instructions.
However, the “long-tail interval” above 120 characters still shows high frequency. These represent “extremely complex instructions” involving combinations of multiple objects, attributes, and relationships, providing critical material for testing model capabilities at their limits. This distribution mirrors real-world creative workflows, where creators start with concise ideas but add extensive detail during professional production.
My sense is the long-tail data suggests current models are being stress-tested beyond standard enterprise use cases. What concerns me is that governance teams should monitor whether these complex prompts trigger unintended bias or safety violations.
Key Dimension Co-occurrence: The “Combination Code” of Instruction Complexity
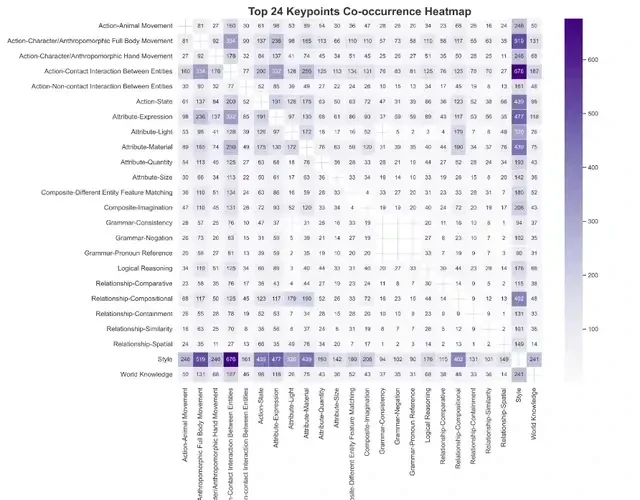
Figure 12: Top 24 Dimension Co-occurrence Heatmap
The heatmap reveals which dimensions frequently appear together, with darker colors indicating higher co-occurrence values. For instance, “Style” and “Action-Contact Interaction Between Entities” co-occur 676 times, indicating that “dynamic interaction scenes with specific styles” are a high-frequency demand for creators.
Similarly, “Attribute-Expression” and “Action-Character/Anthropomorphic Full Body Movement” co-occur 332 times, reflecting the common need for combinations of character actions and expression details.
The dataset also highlights niche but critical combinations. For example, “Logical Reasoning” and “Relationship-Comparative” co-occur in instructions requiring logical chains, such as “The cat is half the size of the dog, so it jumps higher.” This demonstrates a move toward testing causal understanding rather than just visual composition.
I think enterprises should audit their AI outputs for these specific logical relationships to ensure compliance with accuracy standards. My sense is the emphasis on co-occurrence suggests that isolated feature testing is no longer sufficient for robust governance.
Future and Outlook
The release of PromptEnhancer signals a shift in how we approach AI image generation, moving beyond raw model capability toward structured intent alignment. Its significance extends beyond improving individual model accuracy; it introduces three distinct breakthroughs to the technical and ecological landscape of AI painting:
- Generality: The framework operates as a “plug-and-play” module that requires no modification to Text-to-Image (T2I) model weights. It adapts to pre-trained models such as Hunyuan, Stable Diffusion, or Imagen, thereby reducing optimization costs for enterprises;
- Interpretability: By leveraging Chain-of-Thought (CoT) reasoning and a 24-dimensional evaluation framework, prompt optimization is no longer treated as a black box. Developers can now clearly identify where models fail to understand specific instructions;
- Ecological Completion: The team released a high-quality human preference benchmark containing extensive annotated data for complex scenarios, offering critical reference points for future research into prompt optimization.
As AI painting transitions from an “entertainment tool” to professional domains like “industrial design and advertising creation,” the precise understanding of human intent becomes a core competitive advantage. PromptEnhancer provides a practical technical path for this direction by focusing on “optimizing instructions rather than modifying models.” In the future, creators may only need to input simple ideas, with AI automatically completing professional details, making the realization of “what you think is what you get” a reality.
What concerns me is that enterprises should verify if the 24-dimensional evaluation aligns with their specific compliance and brand safety standards. I think the plug-and-play nature reduces liability but shifts the burden of prompt accuracy to the user interface layer. My sense is relying on instruction optimization rather than model retraining is a cost-effective strategy for rapid deployment.
Project Homepage: https://hunyuan-promptenhancer.github.io Github: https://github.com/Hunyuan-PromptEnhancer/PromptEnhancer HuggingFace: https://huggingface.co/tencent/HunyuanImage-2.1/tree/main
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google