The core technical claim driving CVPR 2024 is that “Physical AI” represents the next wave of artificial intelligence, a prediction made by NVIDIA CEO Jensen Huang. This hypothesis rests on the assumption that embodied agents can effectively learn physical laws to navigate human-built environments. However, this vision faces immediate falsification if scalable data collection pipelines cannot match the computational demands of training such models.
The conference opened in Seattle with record-breaking paper submissions, signaling intense community engagement. From a research perspective, Embodied AI has emerged as the dominant hotspot. Huang’s keynote argued that humanoid robots are uniquely positioned to adapt to human infrastructure because they operate within the same physical constraints we do.
I think the leap from simulation to reality often breaks under distribution shifts not captured in synthetic datasets. From the paper, humanoid generalization requires physics-aware priors, which current vision-language models rarely possess.
Yet, this ambition collides with a hard constraint: massive amounts of data are required to support these systems. Humanoid robots encounter diverse, unstructured scenarios where collecting real-world data is prohibitively difficult and expensive. Some industry insiders argue that the lack of high-quality embodied data, rather than algorithmic inefficiency, is the primary bottleneck for current progress.
This scarcity extends beyond robotics. Whether developing AI models with strong logical reasoning or training large language models like GPT-4, access to large-scale, high-quality datasets remains indispensable. For context, the training of the GPT-4 model utilized a dataset comprising approximately 13 trillion tokens—a staggering figure that underscores the scale required for modern foundation models.
One caveat: scaling laws derived from text may not transfer directly to multi-modal physical reasoning tasks. I think the cost of curating 13 trillion tokens is likely prohibitive for most research labs today.
Given such immense data demands, we naturally ask:
Where does such vast amounts of training data come from?
The Data Bottleneck in the Robot World Jensen Huang Envisions Still Needs AI Data for ‘Training’ | CVPR 2024
Confronting the Real-World Data Scarcity
The current generative AI paradigm relies on a “brute force aesthetics” strategy: massive data and ultra-high computing power. The implicit assumption here is that scale alone guarantees capability, but this overlooks the physical constraints of data acquisition. I read the recent analysis from CVPR 2024 discussions, which highlights that while OpenAI-led companies dominate the narrative, the underlying infrastructure is hitting a wall.
Simply put, under equal conditions, more data yields stronger models. However, the competition for high-quality data has become a silent geopolitical and corporate battlefield. The monopoly on general data formed through digital technologies may create an insurmountable chasm for latecomers. Controlling data effectively means holding the reins over future industries, including AI itself.
But acquiring real-world data is fraught with difficulties. Google’s experience with its RT-1 project serves as a prime example of this friction. Despite substantial financial and research resources, Google’s team spent 17 months collecting only 130,000 robot data samples covering over 700 tasks. The generalization capability of this data fell far short of expectations.
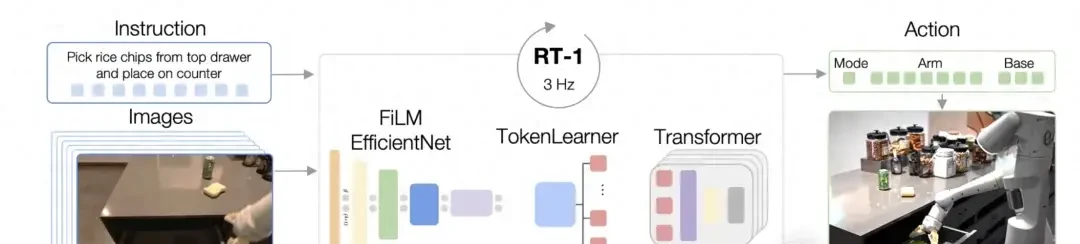
From the paper, real-world robotic data collection is prohibitively slow compared to the rate of model iteration. One caveat: google’s RT-1 results suggest that sheer volume does not automatically solve generalization issues in robotics.
This demonstrates that acquiring real-world data is difficult, time-consuming, and costly. Furthermore, challenges regarding privacy compliance and data security in real-world data collection make it hard to meet the needs of training large AI models. Currently, while the “battle of a hundred models” is raging and leading enterprises are competing fiercely in the AI track, insufficient effective data—particularly a shortage of high-quality data—and closed-loop data ecosystems in certain areas have constrained the development of artificial intelligence. How to resolve this “data bottleneck” is a challenge we will face—or are already facing—in the near future.
To address these challenges, one service provider leveraging computer technology to generate synthetic data deserves close attention: Coohom Cloud, incubated by Koolab, the innovation lab of Kujiale (Qunhe Technology).
As China’s largest spatial design software platform, Qunhe Technology has enabled Coohom Cloud to utilize its vast indoor data resources. By combining high-performance rendering engines with advanced data processing technologies, Coohom Cloud provides the AI industry with products and services such as realistic and physically accurate 2D and 3D indoor datasets.
The Qunhe Technology platform generates over 400,000 3D design proposals daily and has accumulated approximately 360 million 3D model data points, covering furniture, appliances, household items, and more. Building on this foundation, Qunhe Technology has partnered with universities including Imperial College London, the University of Southern California, and Zhejiang University to launch various datasets. These provide a robust data foundation for research in indoor environment understanding, 3D reconstruction, and robot interaction.
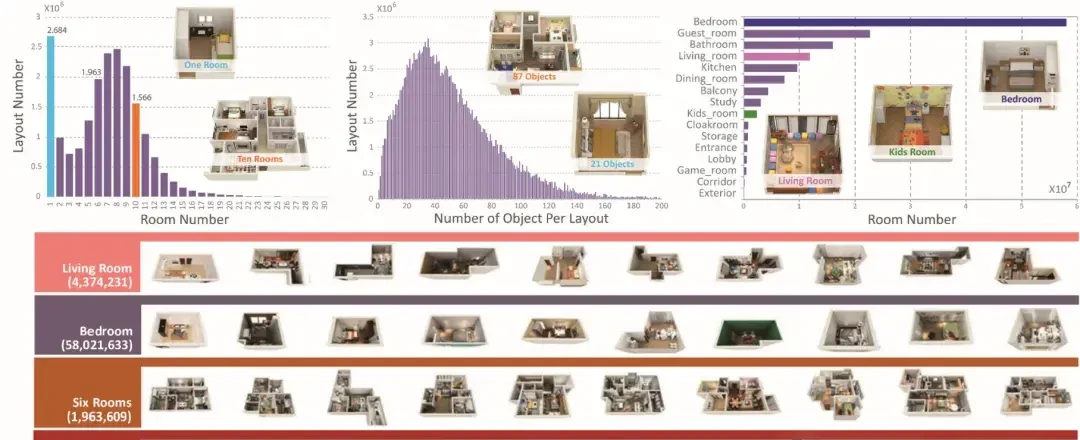
I think synthetic data pipelines must be validated against real-world sim-to-real gaps to ensure utility. From the paper, partnerships with academic institutions lend credibility, but independent replication of results is still lacking.
In terms of 2D image rendering technology, Coohom Cloud utilizes its proprietary rendering engine. By adjusting camera parameters, trajectories, lighting conditions, and other settings in diverse indoor scenes, it collects image data to ultimately generate 2D datasets in formats such as RGB, depth, semantic segmentation, normals, and point clouds. This output capability allows Coohom Cloud to produce 300,000 sets of 2D datasets daily, providing ample training material for AI agents’ navigation, visual perception, and environmental understanding capabilities.
The Robot World Jensen Huang Envisions Still Needs AI Data for ‘Training’ | CVPR 2024
How Qunhe Technology Solves It: Low Cost + High Quality
Lower cost is an essential advantage in data acquisition, encompassing both acquisition costs and economic expenses. Many enterprises are burning through cash in attempts to meet AI model training needs with massive amounts of data. The high investment coupled with uncertain returns has put the sustainability of funding under pressure.
To provide a more cost-effective data service solution, Coohom Cloud developed its proprietary data engine. This is an efficient tool designed specifically for mining data conversion capabilities, capable of efficiently transforming the database accumulated on design platforms into fuel for AI training. It can not only customize output datasets tailored to specific industry needs but also achieve digital generation of indoor scenes, seamlessly integrating with professional simulators and rendering engines such as NVIDIA Isaac Sim, Unreal Engine, and Blender.
All processes are implemented using computer technology, making data usage more convenient and intuitive for users. There is no longer a need to expend significant manpower and resources on data collection, allowing teams to focus more on model tuning and optimization.
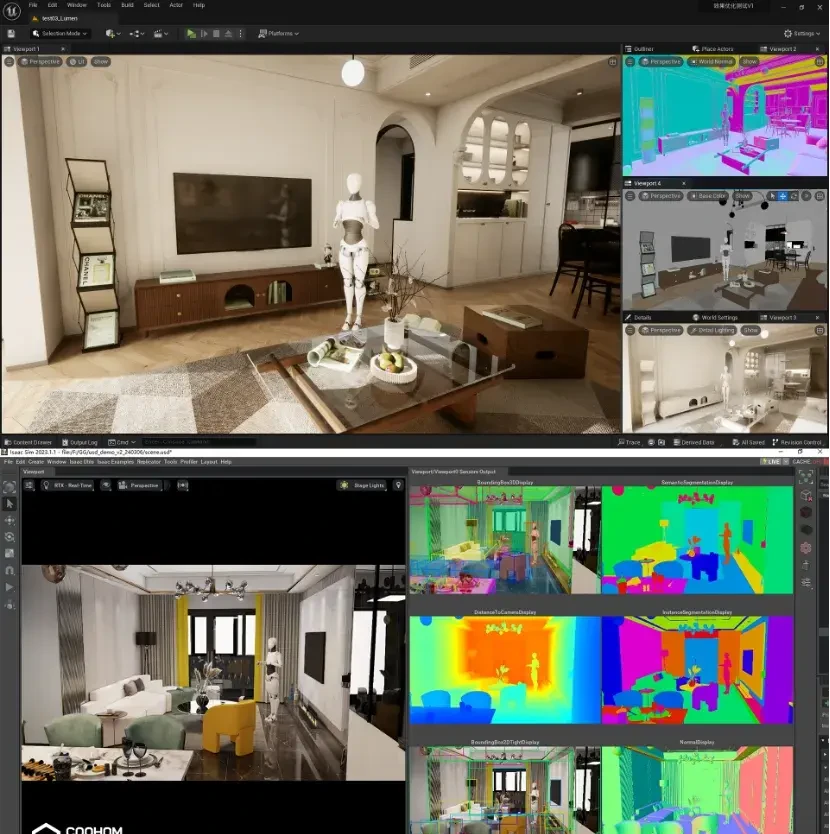
Of course, for data to enter commercial use, beyond volume and cost advantages, ensuring high quality is paramount. This will determine the future scale of the data industry.
In this regard, how does Coohom Cloud approach it?
1. Physical Property Enhancement
In the development path of humanoid robots, environmental interaction capability is key to their intelligence. Examples include freely opening and closing doors, precisely picking up and placing objects, and even folding clothes.
Taking NVIDIA Isaac Sim simulation platform projects as an example, by creating a realistic 3D environment with physical properties, robots can learn how to interact with objects, predict physical events, and explore or navigate within the virtual world. In such virtual environments, robots can undergo countless interaction tests without worrying about physical damage or environmental constraints, significantly reducing training costs while improving safety and repeatability.
Based on this philosophy, Coohom Cloud leverages simulation platforms represented by Isaac Sim and Unreal Engine to provide customized scenes and interaction models for robot training. These data are not only visually realistic but, more importantly, possess true physical properties—components such as hinges and slides can rotate and translate. The models also contain real physical state information such as density, friction, and elasticity. This allows robots to acquire large amounts of training data at extremely low costs in physically accurate virtual environments, testing and optimizing their performance.

One caveat: sim-to-real gaps remain the primary bottleneck; visual fidelity does not guarantee physical correctness.
2. Scene Environment Enhancement
In the world of AI, lighting is often the detail that determines success or failure, especially in visual perception tasks where lighting conditions play a crucial role in an AI’s recognition and analysis capabilities.
Consider InteriorNet mentioned earlier: this large-scale multi-sensor realistic indoor scene dataset demonstrates the importance of environmental enhancement and diversity in improving AI performance by providing high-fidelity rendered images under different lighting environments. Service robots may encounter identification obstacles when facing changes in indoor and outdoor lighting; therefore, having a dataset that covers a wide range of lighting conditions is crucial for training AI to adapt to various environments.
Coohom Cloud sets detailed parameters for each light source in virtual indoor scenes, enabling personalized lighting environment control. This ensures that robots can “see” clearly and learn effectively under different lighting conditions.

Beyond the diversity of lighting conditions, Coohom Cloud further enhances scene complexity through Domain Randomization technology. This is akin to giving the rob
The core technical claim here is that synthetic environments can replace real-world data collection for robot training by simulating physical diversity. This would be falsified if models trained exclusively on these simulations fail to generalize when deployed in unstructured, real-world physical settings due to the “reality gap.”
I read through Coohom Cloud’s latest feature set, and what stood out to me was their focus on material flexibility as a proxy for real-world complexity. They claim this allows for flexible switching of model surface materials—such as replacing marble floors with wooden flooring or adjusting reflection effects—to simulate the diversity and complexity of the real world in virtual environments. The argument is that this makes robot training more realistic, thereby enhancing its adaptability and generalization capabilities.

Efficient Annotation via Synthetic Generation
Data annotation is a key factor in model performance within the AI field, but traditional manual annotation methods are labor-intensive and time-consuming. Coohom Cloud leverages advanced synthetic data generation technology to customize segmentation and annotation of data according to researchers’ needs. For example, when processing 3D models of bedroom scenes, the system can break them down into basic elements such as beds, pillows, and blankets, generating precise semantic labels. This improves data accuracy and meets specific requirements, thereby enhancing model cognitive precision.
I think synthetic segmentation assumes perfect ground truth in generation, which rarely holds for noisy real-world sensor inputs.
This approach not only reduces the workload of manual annotation but also allows researchers to focus more on model innovation and optimization, improving data processing efficiency and injecting new vitality into AI technology development.

Privacy and Security by Design
Additionally, regarding issues such as privacy and security regulations, Coohom Cloud’s synthetic data security strategy avoids contact with any real user data. Security audit mechanisms are used to check for compliance, and authorization management is applied to delivered data to ensure secure usage. Within the ecosystem, Coohom Cloud connects excellent designers and researchers, developing more efficient tools tailored to AI needs to promote the integration of the design ecosystem into the forefront of AI.
From the paper, avoiding real user data solves privacy but does not guarantee the synthetic distribution matches the target domain’s edge cases.
The Robot World Jensen Huang Envisions Still Needs AI Data for ‘Training’ | CVPR 2024
The Industrial Pivot from Research to Reality
The shift toward industrial application is no longer theoretical; capital flows and practical deployments confirm that data services are moving from academic labs to marketization. However, in artificial intelligence, the quality of data and its actual application effects matter far more than blind accumulation. I read the release regarding Coohom Cloud’s massive indoor dataset and followed how it lands in different industry scenarios.
At the end of 2022, Qunhe Technology’s KooLab jointly refined the SPEAR Intelligent Simulation Platform with Intel Labs, the Spanish Computer Vision Center (CVL), and Technical University of Munich. The platform is now fully open to developers, helping them accelerate the training and verification of various intelligent robots.
Throughout this project, the Coohom Cloud team provided over 300 scenes and more than 17,000 models, offering significant data support for simulator research and allowing researchers to conveniently test robot performance in virtual environments.

Mike Roberts, Chief Scientist at Intel, praised Coohom Cloud’s high-quality data:
It not only accelerated embodied intelligence research but also provided comprehensive data assurance for the implementation of simulator projects.
One caveat: simulated environments often fail to capture the stochastic noise of physical hardware, risking a significant sim-to-real gap.
Solving the Edge-Case Bottleneck
Taking cleaning robot products as another example, in business scenarios primarily focused indoors, accumulating edge-case data requires a significant amount of time, which directly impacts the product experience for end-users. Therefore addressing edge cases in robotics has become the key to enhancing product competitiveness.
The edge scenarios for cleaning robots primarily involve obstacles that are difficult to collect, such as pet waste and fruit shell debris, as well as data from special narrow passages, highly reflective floor glass, and low-light environments. Previously, manufacturers had to assemble teams of dozens of people, spending months outsourcing data collection to third parties. This process was cumbersome, expensive, and did not guarantee that the data quality met standards.
Coohom Cloud’s solution allows enterprises to maintain full control over the entire workflow, from model assets to semantic annotation and data structure processing. By creating specialized indoor virtual environments tailored to the edge cases users care about and adjusting lighting parameters to derive scenario diversity, they generated tens of thousands of high-quality 3D model datasets and millions of refined image data points in just 45 working days. The delivered data is ready for use, helping companies significantly reduce investment in data acquisition and accelerate AI project progress.

I think synthetic lighting adjustments cannot fully replicate the complex spectral reflections of real-world glass surfaces.
As large AI models and humanoid robots become hot topics in the tech industry, data has emerged as the core asset of this era. Coohom Cloud is supporting the diverse application needs of AI through its powerful data generation technology, driving the industry toward broader intelligent development.
From the paper, the claim of “high-quality” remains unverified without independent benchmarking against real-world physical trials.
One More Thing
We look forward to Coohom Cloud continuing to deepen their technology and exploring new fields in the future.
From June 17 to June 21, the Coohom Cloud team will showcase their latest achievements at Booth No. 1637 during the CVPR 2024 conference in Seattle. If you are interested in data services, we invite you to visit the booth and engage in in-depth discussions with the Coohom Cloud team to witness the future of AI data services together.
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google