Tsinghua’s Sun Maosong: Big Tech Can Scale, Others Should Focus on Vertical Applications | MEET2026
By Priya Sharma, Enterprise AI & Governance Editor
The burden of proof in the current AI arms race is shifting. While capital-intensive scaling remains the domain of a few well-resourced entities, governance and practical utility are becoming the primary differentiators for the broader market. As Sun Maosong outlines at MEET2026, enterprises must distinguish between speculative frontier research and viable, detailed application strategies to avoid wasted investment.
Emergence is the “realm” that AI strategists are currently eager to see on the battlefield of artificial intelligence.
Since Scaling Laws brought about astonishing improvements in model capabilities, nearly every model manufacturer has been swept up in an endless wave of FOMO (Fear Of Missing Out). No one dares to stop.
I believe the most captivating aspect of large models lies in their non-linear changes, which represent immense uncertainty. However, once performance emergence occurs, it will far exceed imagination.
Sun Maosong, Executive Vice Dean of the Institute for AI at Tsinghua University and Foreign Member of the European Academy of Sciences, expressed these sentiments at this website’s MEET2026 Intelligent Future Conference.

As long as computing power can be stacked and parameters increased, the burning of capital must not cease.
However, with the marginal costs of scaling becoming increasingly high, what if we eventually discover this is a dead end and all investments are wasted?
Sun Maosong’s advice is to “aim for breadth” but even more so to “attend to details.”
From an industry perspective, a few exceptionally well-resourced teams can attempt to continue following international frontiers in the direction of “breadth.” However, the vast majority of AI companies should focus their primary efforts on “attending to details.”
To fully present Sun Maosong’s thoughts, this website has edited and organized his speech content without altering its original meaning, hoping to provide new perspectives and insights.
MEET2026 Intelligent Future Conference is an industry summit hosted by this website, featuring discussions among nearly 30 industry representatives. The offline audience numbered nearly 1,500, while online live viewership exceeded 3.5 million, garnering widespread attention and coverage from mainstream media.
Key Takeaways
-
As model size and data scale continue to grow, capability emergence may occur. This high degree of non-linear change brings uncertainty, which is precisely what makes large models most fascinating. It is expected that in the coming years, even humanity’s most difficult exams with standard answers may not stump machines.
-
The fundamental challenge currently facing large models and embodied intelligence lies in how to clarify the relationship between “speech,” “knowledge,” and “action,” enabling machines to truly achieve “unity of knowledge and action.” Solving this problem is extremely difficult and involves major innovations in AI theory and foundational methods.
-
How far Scaling Laws can go remains highly uncertain. Any information system typically tends toward saturation at a certain stage. However, the emergence of new phenomena can break through this saturation. Therefore, China still needs a small number of top-tier teams to closely follow global frontier developments and explore the limits of scaling.
-
It is almost impossible for humanoid robots to enter general open environments within the next few years to autonomously perform relatively complex tasks. Instead, efforts should be focused on achieving “spark-to-prairie-fire” style implementation of AI applications across as many specific real-world scenarios or tasks as possible. This is entirely feasible (though the robots do not necessarily need to be humanoid) and should be the primary focus for the vast majority of enterprises.
Below is the full text of Sun Maosong’s speech:
I think capital-intensive scaling carries significant financial risk for entities without deep pockets. My sense is enterprises must verify if their vertical applications offer clearer ROI than generic model training. What concerns me is that governance frameworks should prioritize safety in specific scenarios over theoretical general intelligence.
Eight Years of Rapid Progress
I read Sun Maosong’s opening remarks at MEET2026 with a compliance lens. The burden of proof for safety shifts to those deploying these models, not just those building them. His timeline highlights how quickly the landscape has shifted from GPT-3 to today’s multimodal reality. Enterprises must verify that their vendors can demonstrate this “emergence” reliably before integration.
I think the speed of progress demands stricter governance frameworks for enterprise adoption. My sense is emergence is unpredictable, making pre-deployment risk assessments critical for liability. What concerns me is that benchmark scores are high, but real-world reliability remains the true test.
Sun Maosong’s talk was titled “Generative AI and Large Models: Frontier Trends, Core Challenges, and Development Paths.” He frankly admitted that addressing this topic is difficult because everyone worldwide is discussing it; he offered some superficial insights in return.
Deep learning entered the era of pre-trained models and large models around 2017. Only eight years have passed since then.
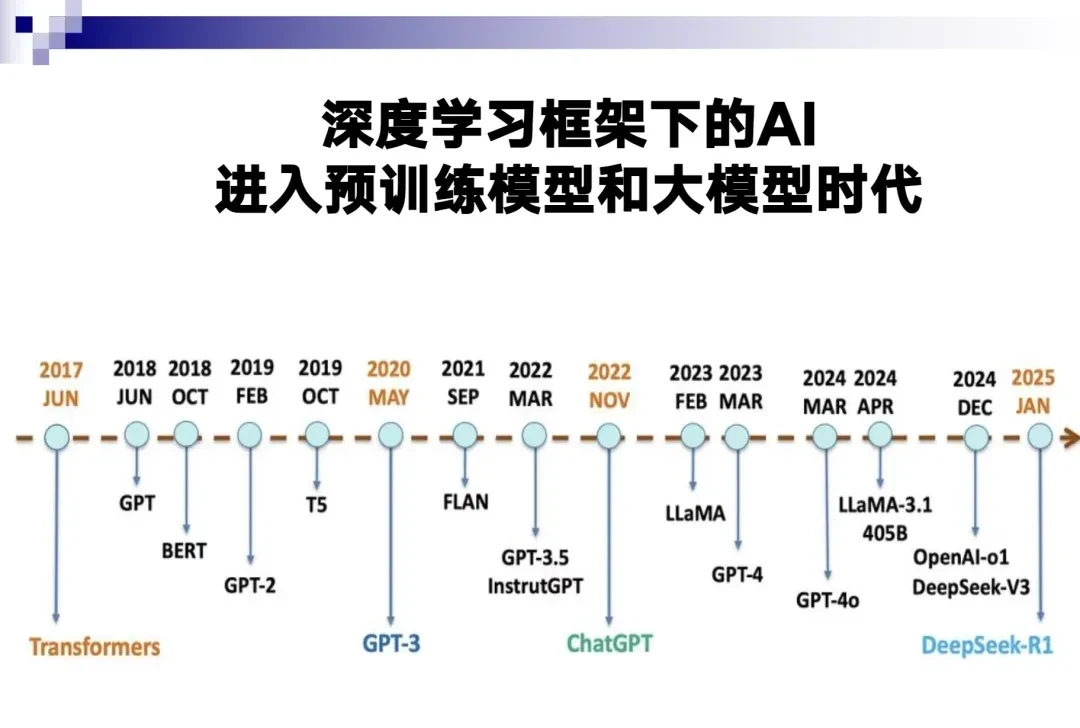
There are several key milestones in these eight years:
-
GPT-3 was released approximately five years ago;
-
ChatGPT has been out for about three years;
-
DeepSeek emerged just one year ago.
We have traversed multiple stages in these eight years, echoing the ancient saying: “If you can renew yourself today, do so every day, and keep renewing.” This basically describes the normal state of large model development in recent years.
Especially in recent years, through long chain-of-thought reasoning, the ability of large models to solve complex tasks has risen sharply, presenting a scene where thousands of sails compete.
Why are we so obsessed with large models? Their most important characteristic is: as models and data volumes grow larger, capability emergence generally occurs—a phenomenon absent in previous models.
Once capability emergence happens, it becomes a non-linear change; you never know when or why it suddenly takes off.
If an endeavor does not produce performance emergence, it may remain unremarkable. But once emergence occurs, it can leave competitors far behind. Yet, whether this will happen cannot be predicted in advance. This is the most charming yet perplexing aspect of large models.
Development has been rapid in recent years. Text-based and image-text multimodal large models have nearly flattened all benchmarks.
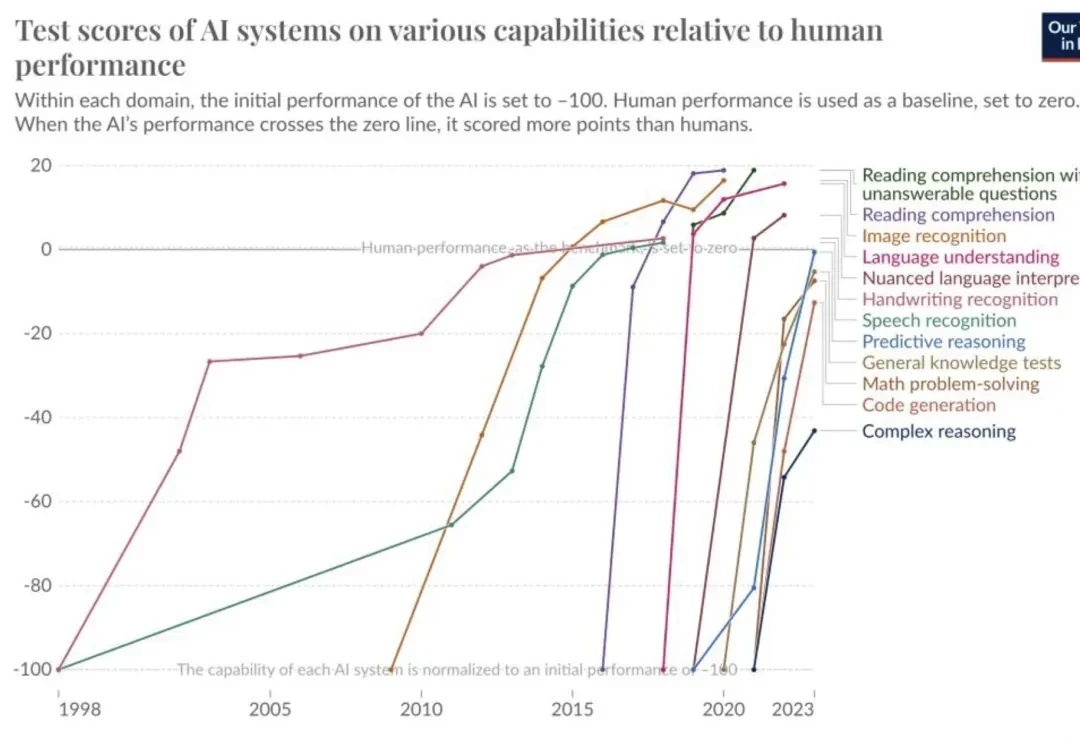
There is a benchmark called “Humanity’s Last Exam,” designed to stump AI by collecting difficult questions from around the world—problems that have never appeared before and have no answers online.
Top human experts might score only five points on such tests, but current large models can achieve scores of thirty or forty.
It can be anticipated that in the coming years, machines will not be stumped by any exam with standard answers. This reflects the development status of text-based large models.
The progress of code large models is equally rapid. In this year’s International Collegiate Programming Contest (ICPC), the human first-place winner was outperformed by a large model. Additionally, everyone has witnessed the impressive performance of multimodal large models.
Overall, text, code, and multimodal large models have reached a fairly high level of basic capability, constituting the “basic landscape” of AI discussion today.
In his book Thinking, Fast and Slow, Daniel Kahneman proposed the famous System 1 (fast system) and System 2 (slow system).
After years of development, machines now possess strong capabilities in both System 1 and System 2, laying a very important foundation for AI to move beyond the text world toward embodied intelligence. Specifically, without System 1’s perceptual abilities, machines would be “bewildered” upon entering the real world and unable to do anything.
We often mention the Turing Test from 1950. At the linguistic level, it can be said that this test has been passed.
However, during the same period, Norbert Wiener, the father of cybernetics, proposed another equally important viewpoint in Cybernetics:
For a machine to possess intelligence, it must enter the real world. It needs to perceive this world, interact with it, receive rewards or punishments through feedback, and continuously self-adjust and self-learn based on these experiences. Only through this process can true intelligence form.

Today, we have certain conditions to put Wiener’s cybernetics into practice, which will elevate AI to a new level.
An old saying goes, “Speech is easy, action is hard,” and the poet Lu You wrote, “What is learned from books is supe
Tsinghua’s Sun Maosong: Big Tech Can Scale, Others Should Focus on Vertical Applications | MEET2026
The burden of proof in AI development is shifting from mere capability to embodied execution. As we analyze the latest insights from Tsinghua University’s Sun Maosong at MEET2026, it becomes clear that the industry must distinguish between theoretical proficiency and practical application. The question is no longer just what models can say, but how they can act—and who is accountable when those actions fail in real-world scenarios.
The Gap Between Speech and Action
Sun Maosong argues that while artificial intelligence has mastered “speech,” it struggles with “action.” He notes that there is a qualitative difference between the two modes of operation. Language models are exceptionally good at generating text, but once they move to physical or logical action, significant challenges emerge.
He references an old saying: “Knowledge is difficult, action is easy.” This highlights the paradox where acquiring information seems straightforward, yet applying it correctly is often harder than expected. Although large models are currently very proficient in “speech”—as if all global knowledge has been parameterized and stored within them—their “knowledge” remains incomplete and unsystematic, lacking self-awareness.
I think enterprises must audit AI outputs for systemic gaps before trusting them with critical decisions. My sense is the illusion of comprehensive knowledge poses a significant compliance risk in regulated industries.
The Challenge of Embodied Intelligence
Without any “knowledge,” “action” is meaningless. However, although the “knowledge” of large models is imperfect, they have acquired about 70-80% of it. Therefore, in embodied intelligence, it may be possible to pursue the “unity of knowledge and action.”
This suggests that while we are not at full autonomy, we are close enough to attempt integration. The goal is no longer just to retrieve information but to act upon it with sufficient accuracy to justify deployment. This transition requires rigorous validation frameworks that go beyond traditional benchmarking.
What concerns me is that governance frameworks must evolve to cover the 20-30% gap in model knowledge. I think vendors should disclose their confidence intervals for action-based AI tasks clearly.
The Core Challenge: Unity of Knowledge and Action
Moving from “speech” to “knowledge” is much more difficult. This constitutes today’s greatest challenge for AI: How to properly handle the relationship between “speech,” “action,” and “knowledge,” achieving the “unity of knowledge and action”?
For enterprises, this means evaluating vendors not just on their language capabilities but on their ability to bridge the gap to actionable outcomes. The focus should shift toward vertical applications where the cost of error is manageable and the value of integration is high. Big tech may scale broadly, but others must prove they can act reliably in specific domains.
My sense is procurement teams should prioritize vendors with transparent action-validation protocols. What concerns me is that regulatory bodies need clearer standards for “embodied” AI liability.
Tsinghua’s Sun Maosong: Big Tech Can Scale, Others Should Focus on Vertical Applications | MEET2026
The High Cost of Scaling and the Wall Street Anxiety
The fundamental premise of AI development rests on Scaling Laws—leveraging large models, massive datasets, and immense computing power. Recently, this framework has expanded to include pre-training, post-training, and test-time scaling. However, there is a critical prerequisite: this scaling must be effective.
Every system hits a bottleneck. Once performance saturates, Scaling Laws may fail; pouring more capital into that stage yields diminishing returns or even losses. I noted earlier that large models might exhibit “emergence.” If emergence occurs, the investment pays off. But if it doesn’t, we are burning cash for nothing. How far these laws can stretch remains a massive unknown. The cost of supporting such scale is astronomical—draining capital and consuming vast amounts of electricity.
On November 3rd, France’s Les Echos published an article titled: “Huge Investments in AI Make Wall Street ‘Sweat Cold.’” Wall Street typically sweats from heat; to describe it as “sweating cold” signals the sheer magnitude of these risks. The report highlights staggering figures:
-
OpenAI’s current computing capacity is approximately 2 GW;
-
It plans to increase this by a factor of 125 by 2033, reaching 250 GW;
-
The corresponding investment scale could reach up to $10 trillion, excluding electricity costs.
Consider the physical reality: the average power generation capacity of one nuclear reactor is less than 1 GW. 250 GW equals 250 nuclear reactors. This represents an aggressively risky level of capital deployment.
The dilemma is stark: We cannot afford not to keep up; if emergence occurs, we could be left far behind. But keeping up might be financially unsustainable.
I think enterprises must audit their ROI on compute spend before committing to this arms race. My sense is the $10 trillion figure highlights a systemic risk that regulators are likely monitoring closely.
The Limits of Next Token Prediction and Embodied Intelligence
The challenge deepens when we consider embodied intelligence. Fei-Fei Li proposed “spatial intelligence,” which essentially refers to the physical action mentioned earlier. This field faces significant theoretical and practical hurdles: How far can Next Token Prediction go?

Text is generated entirely through Next Token Prediction. Later reinforcement learning techniques are built upon this foundation. Image and video generation also rely heavily on this strategy to a large extent. This approach is nearly perfect for text, despite occasional hallucinations; it has reached expert-level proficiency. However, it becomes less effective with images, requiring cooperation with other strategies. Video generation is even more difficult; generating a 10-minute logically coherent video remains quite challenging.
When moving to embodied intelligence, prospects become highly uncertain. Language succeeded because it is a linear sequence with the characteristic of “discrete infinity.” For example, the word “apple” primarily has two meanings: the fruit or the specific company. Its semantic reference is clear, word boundaries are distinct, and sentence sequences are linear, making Next Token Prediction very effective.
But this does not work for images. It is unclear where the relatively explicit tokens in an image are located; instead, they must be treated as “patches.” For instance, a 3x3 black block could be part of clothing, a corner of a desk, or an icon on a screen. Its semantic reference is highly uncertain. Moreover, it lacks holistic integrity; this black block might consist of a swarm of black ants or just a small portion of a patch on clothing.
Moving to video, which transitions from two dimensions to three, becomes even more difficult. Embodied intelligence operates in four dimensions—three-dimensional space plus time. The world is vast and ever-changing. Whether Next Token Prediction can handle such complex scenarios is uncertain.
I believe it is impossible for humanoid robots to autonomously complete relatively complex open-ended tasks in the real world within the next five years. For example, building an embodied robot capable of caring for the elderly at home? That is far too difficult.
Turing Award winner Geoffrey Hinton recently said something while discussing AI and unemployment:
If someone suggests you become a plumber, do not easily reject that advice.
This suggestion is reasonable given the uncertainty in automating physical labor.
What concerns me is that vendors claiming general-purpose robot autonomy within five years are likely overstating their capabilities. I think enterprises should verify if “spatial intelligence” claims are backed by rigorous safety benchmarks.
Tsinghua’s Sun Maosong: Big Tech Can Scale, Others Should Focus on Vertical Applications | MEET2026
The conversation shifted from speculative general intelligence to the gritty reality of embodied AI. Sun Maosong, a central figure in China’s academic AI landscape, drew a sharp line between what is theoretically possible and what is operationally viable for enterprises today. The burden of proof now lies with developers who must demonstrate utility within constrained domains rather than chasing AGI myths.
The Reality Check on Embodied Intelligence
Sun offered a sobering comparison to ground expectations: current AI capabilities remain distant from the practical, adaptive problem-solving skills of even a human plumber. This is not a dismissal of progress, but a clarification of scope. The technology is nowhere near replicating the nuanced, unstructured decision-making required in general physical labor.
Feasible Paths: Simplicity Over Complexity
So, what is actually feasible? Sun suggested that success lies in simplifying the task space. He pointed to dexterous robotics as a prime example. While handling complex manipulation is out of reach for now, executing relatively single and simple tasks with high precision is entirely possible. It is not easy, but it is achievable.
My sense is enterprises should stop betting on general-purpose robots and start investing in specialized automation. What concerns me is that the ROI on simple, repetitive physical tasks will likely precede complex dexterity breakthroughs. I think governance frameworks must account for the limited safety boundaries of these constrained systems.
This leads to a crucial strategic pivot: embodied intelligence will operate within limited domains and applications. However, Sun emphasized that the development space within those niches is still sufficient to drive significant value. We must act according to our capabilities, advance despite difficulties, but maintain appropriate limits in both progress and retreat. This is not just a technical guideline; it is a risk management strategy for capital allocation.
The World Model Hurdle
The industry often speaks of building “world models”—internal representations of how the physical world works—but Sun flagged this as an extremely difficult, if not currently impossible, task. There is no clear feasible technical path to achieving robust, generalizable world models at scale today.
In the short term, we are stuck relying on Next Token Prediction (NTP). While NTP has driven recent LLM advancements, applying it to physical embodiment requires order-of-magnitude increases in computing power and data requirements. This creates a significant barrier to entry for smaller players who cannot match the infrastructure spend of big tech.
My sense is the compute cost of scaling NTP for robotics may price out all but the largest enterprises. What concerns me is that without a new architectural paradigm, progress will be linear, not exponential.
A Glimmer of Hope: Emergence?
Despite these constraints, Sun left room for uncertainty. He noted that if capability emergence occurs again—meaning sudden leaps in performance due to scale or new techniques—robots might gain a higher degree of freedom even in relatively open task spaces. This is the wildcard. If emergence happens, the current limits on embodied AI could be shattered overnight.
Until then, the strategy remains clear: focus on vertical applications where tasks are simple, data is abundant, and compute costs are manageable. The era of general-purpose physical AI is not here; the era of specialized, constrained automation is.
Tsinghua’s Sun Maosong: Big Tech Can Scale, Others Should Focus on Vertical Applications | MEET2026
”Embrace the Broad, Master the Detailed”
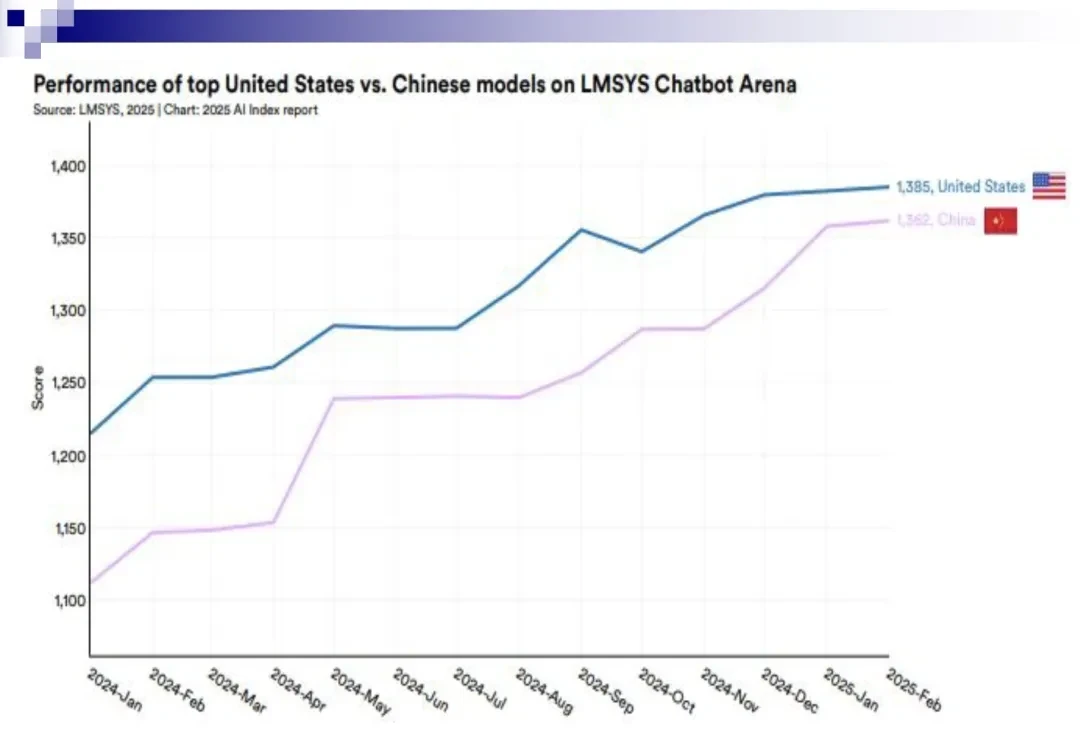
The strategic landscape for AI development is becoming increasingly bifurcated. While the United States pursues massive scale, domestic leaders like DeepSeek and Qwen have demonstrated that Chinese capabilities are closing the gap with American counterparts. This divergence forces a critical governance question: who bears the burden of proof when scaling strategies stall?
Sun Maosong invokes the classical Chinese maxim: “Embrace the broad, master the detailed.” In his view, “embracing the broad” represents the current U.S. strategy of deploying 100,000 to millions of GPUs. This approach requires capital investments so vast that even Wall Street finds them difficult to sustain indefinitely. However, if this path triggers an emergent breakthrough at a critical juncture, it could secure a generational lead for its proponents.
For China, adopting this “frontal confrontation” strategy is viable only for a handful of domestic tech giants with exceptional resources. Even then, the journey would be arduous. While the performance gap in large language models between China and the U.S. is currently small, Sun argues that significant uncertainty remains regarding the viability of the “embrace the broad” strategy over the next few years.
I think capital intensity creates a moat that only state-backed or mega-cap entities can maintain long-term. My sense is enterprises must verify if their vertical data justifies the cost against open-source baselines like Qwen.
Against this backdrop, Sun posits that focusing on vertical AI applications—“mastering the detailed”—is the sound strategic choice for China at present. With open-source foundational models already established, deep integration across various industries is feasible and could lead to global leadership. However, he warns against expecting immediate results from off-the-shelf large models. In some cases, vertical domains may even necessitate new AI algorithms, meaning “mastering the detailed” can itself be a form of “embracing the broad.”

Sun outlines a clear path forward for the industry:
- A small number of teams with exceptional resources should continue following international frontiers in the “embrace the broad” direction.
- The vast majority of AI companies must focus their primary efforts on “mastering the detailed.”
Vertical application development is highly challenging but carries lower risk. Sun believes China has conditions to outperform the United States in this area, citing rich application scenarios, a strong industrial base, and the intelligence and diligence of its workforce as competitive advantages in “mastering the detailed.”
Conversely, “embracing the broad” depends on whether the education system can cultivate talent capable of 0-to-1 innovations—a complex issue tied to answering Qian Xuesen’s famous question. Sun suggests it is acceptable to pause on that front for now, perfecting “mastering the detailed” first before pivoting back while keeping a close eye on frontier developments.
He concludes by affirming that those engaged in “mastering the detailed” are doing excellent work and focusing on what should be prioritized at present. These are his personal observations, which he acknowledges may not be entirely accurate.
What concerns me is that governance frameworks must adapt to vertical-specific risks rather than relying solely on model-level safety. I think leaders should audit their reliance on open-source weights for compliance with evolving data sovereignty laws.
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google