Why Are Leading Domestic AI Model Developers Choosing CPUs?
The rapid acceleration of artificial intelligence development is no longer confined to Silicon Valley; it is reshaping supply chains and cost structures across the Asia-Pacific region. As domestic Chinese vendors pivot toward CPU-based inference to survive a brutal price war, they are highlighting a global inefficiency: the over-reliance on scarce GPUs for tasks that modern processors can handle cheaply. This shift from pure performance chasing to pragmatic economics signals a maturation in how AI infrastructure is valued globally.
I think the GPU shortage has created artificial scarcity, pushing vendors toward underutilized CPU resources. From an APAC angle, china’s “cent-era” pricing pressures force efficiency innovations that Western firms are only now considering. Globally, data cleaning and preprocessing remain CPU-bound bottlenecks often ignored in pure inference benchmarks.
The update speed of both large models and AI applications is now so rapid that it feels impossible to keep up: Sora, Suno, Udio, Luma… major applications are being released one after another. As data from an InfoQ survey indicates, although AIGC (AI-Generated Content) is still in its early stages, the market size has begun to take shape:
The market is expected to reach 450 billion RMB by 2030. AIGC applications are flourishing across multiple sectors, gradually penetrating from general scenarios into industry-specific depths.
While the rapid development of the entire industry is undoubtedly a positive sign, the competition for specific applications and large model implementations has become increasingly fierce. For instance, recently, major model vendors engaged in an intense “price war,” competing on who could offer the lowest prices, even pushing large model pricing into the “cent era” (extremely low cost).
Compounded by OpenAI’s recent “supply cutoff” incident, domestic vendors have intensified their efforts to promote “easy migration” plans and increased incentives such as free token giveaways. The root cause lies in the current trend where applications are king, particularly the need to deploy businesses quickly at minimal costs. So, how can large model players achieve a balance between being fast, high-quality, and cost-effective? This brings us back to an unavoidable factor that accounts for the absolute majority of costs—computing power.

When it comes to training and inference for large models, many people’s first reaction is to think of GPUs. Admittedly, GPUs hold certain advantages in high performance, but their “hard flaws” are also quite obvious: insufficient supply and high prices. How can this bottleneck be broken? Baidu Intelligent Cloud’s Qianfan Large Model Platform, a top-tier player in domestic large models, has offered its own solution with better “cost-effectiveness”:
Except for a few major clients pursuing peak performance from large models, most enterprises and institutions need to comprehensively evaluate the usage effects, performance, and cost-efficiency—commonly referred to as “price-performance ratio”—when adopting large models.
Regarding computing power deployment, Xin Zhou, General Manager of Baidu Intelligent Cloud’s AI and Big Data Platform, believes:
The use of CPUs for running AI has actually been prevalent since the early days; GPU popularity is only a recent phenomenon.
In many scenarios, although GPUs offer high-density computing capabilities, practical tests show that modern high-end CPUs are fully capable of handling these tasks.
Moreover, the entire AI business workflow involves not just large model computations but also preliminary stages like data cleaning, where CPUs play a crucial role.
In short, in the era of large models, CPUs have become even more important than before and are one of the key factors enabling large models and applications to be deployed “fast, well, and cheaply.” So, how does this perform in practice? Let’s continue reading.
Why Domestic Leaders Are Betting on CPUs
The shift toward central processing units in Asia-Pacific’s generative AI sector signals a pragmatic recalibration of infrastructure spending. As enterprises move from pilot projects to scaled deployment, the focus is shifting from raw peak performance to sustainable operational economics. I followed this trend closely as major platforms prioritize accessibility over specialized hardware exclusivity.
I think cPU adoption reflects a broader global cost-control strategy in AI inference. From an APAC angle, this trend reduces supply chain dependency on scarce GPU inventories. Globally, lower barriers to entry democratize AI access for mid-sized enterprises.
With the explosion of domestic AIGC applications, Baidu Intelligent Cloud’s Qianfan Large Model Platform has played an indispensable role. As a “one-stop” service platform for enterprises to use large models, Qianfan has been used by over 120,000 clients since its launch in March last year, with 20,000 optimized models and 42,000 incubated applications.
These applications cover numerous scenarios such as education, finance, office work, and healthcare, providing strong support for industry digital transformation.
In the education sector, Qianfan empowers applications like question generation, online grading, and problem analysis, significantly improving teaching and exam preparation efficiency. For example, users can provide reference materials and set question types and difficulty levels; the platform then automatically generates high-quality test questions. Interactive problem explanations offer personalized learning guidance tailored to each student’s weak points.
In office scenarios, Qianfan collaborates with leading industry partners to create innovative applications like intelligent writing assistants. These tools can quickly generate professional documents such as recruitment copy, marketing plans, and data reports based on user-input keywords. They also focus on various writing scenarios, intelligently generating thesis outlines, project reports, and brand promotional drafts, greatly enhancing the efficiency of administrative and marketing staff.
Healthcare is another major application track for Qianfan. Models trained on medical knowledge bases can automatically generate interpretations of health checkup reports, explaining indicators in plain language and providing personalized health guidance. This allows ordinary people to better understand their physical condition and achieve “autonomous health management.”
It is evident that Qianfan has achieved the “last mile” implementation of AI models across multiple fields. So, how does Qianfan support so many AI applications? The answer is: Making CPU a viable choice for customers and democratizing the benefits of “cost-effectiveness” across all industries.
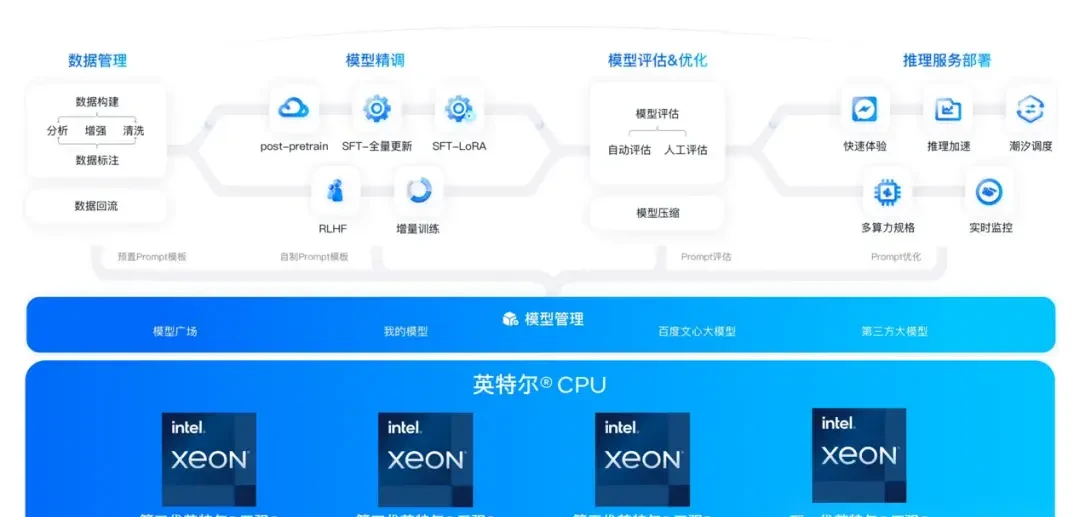
Baidu Intelligent Cloud explains this approach as follows:
Currently, there is still a significant demand for offline LLM applications in the industry, such as generating article summaries, abstracts, and data analysis. Compared to online scenarios, offline scenarios often utilize idle computing resources on platforms. They have lower latency requirements but are more sensitive to inference costs; therefore, users tend to prefer low-cost, easily accessible CPUs for inference.
Cloud platforms like Baidu Intelligent Cloud host a large number of CPU-based cloud servers. Releasing the AI computing potential of these CPUs helps improve resource utilization and meets users’ needs for rapid LLM model deployment.

Regarding performance, taking Llama-2-7B as an example, the Token throughput on fourth-generation Intel® Xeon® Scalable processors can exceed 100 TPS, representing a 60% improvement over third-generation models.
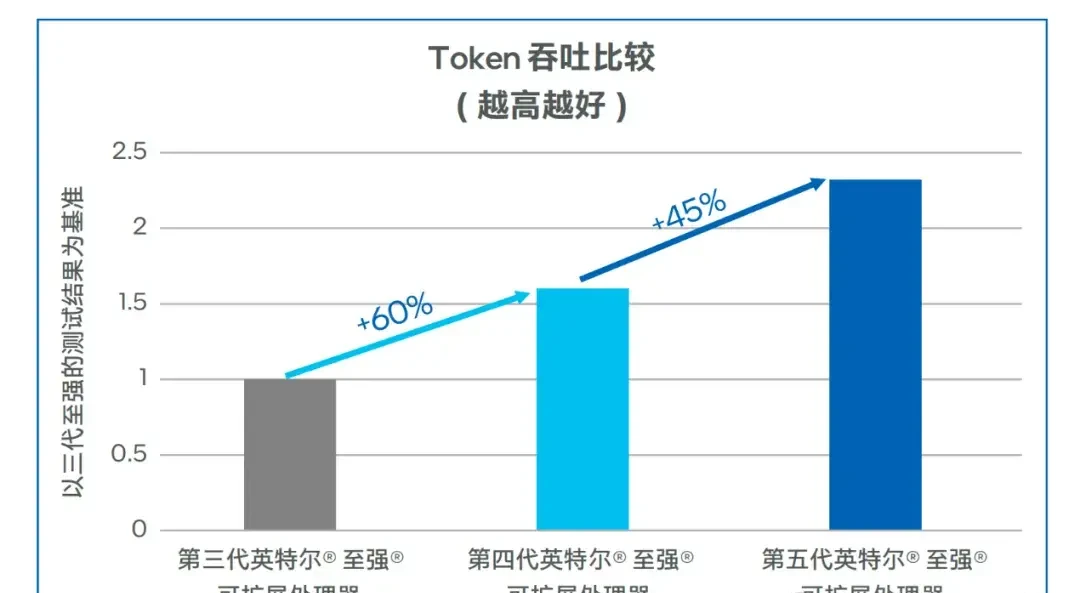
△ Llama-2-7B Model Token Throughput Output
In low-latency scenarios, under equal concurrency, the first-token latency of fourth-generation Xeon® Scalable processors can be reduced by more than 50% compared to third-generation models. After upgrading to fifth-generation Xeon® Scalable processors, throughput increased by approximately 45%, while first-token latency decreased by about 50%.
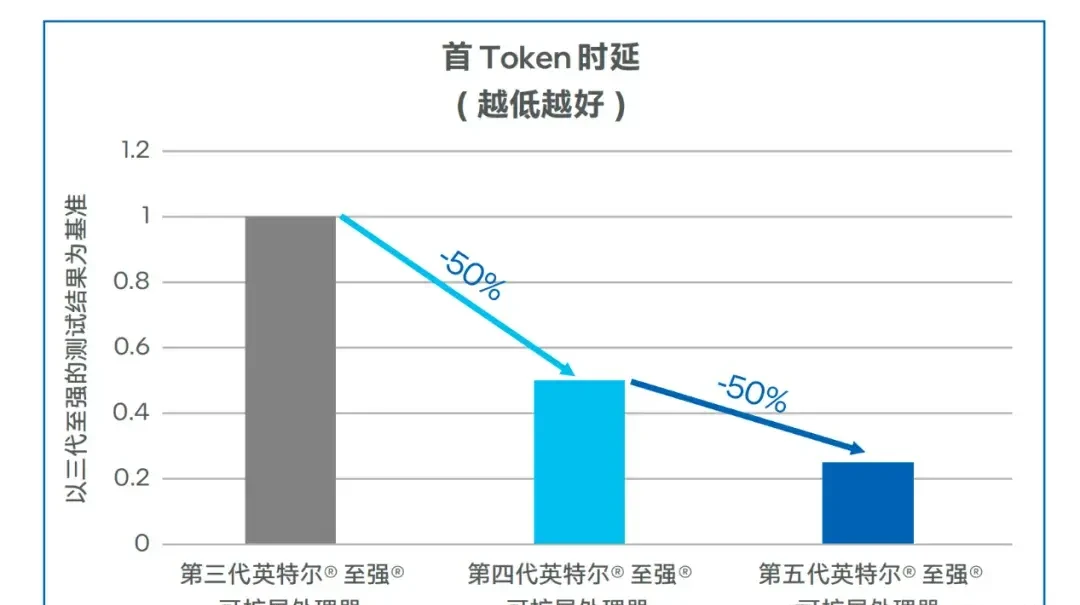
△ Llama-2-7B Model First-Token Latency
Furthermore, the Qianfan Large Model Platform team stated based on practical experience:
For LLM models with a scale below 30 billion parameters, Intel® Xeon® Scalable processors can be adopted to achieve good performance experiences.
Moreover, by leveraging abundant CPU resources and reducing reliance on AI accelerator cards, the total cost of ownership (TCO) for LLM infere
The Quiet Shift to CPU Inference
As I followed the release details, a clear pattern emerged: latency services are being lowered significantly, particularly excelling in offline LLM inference scenarios. This technical nuance suggests that for many domestic developers, the immediate need is not raw training throughput, but efficient, cost-effective deployment where GPUs may be overkill or scarce.
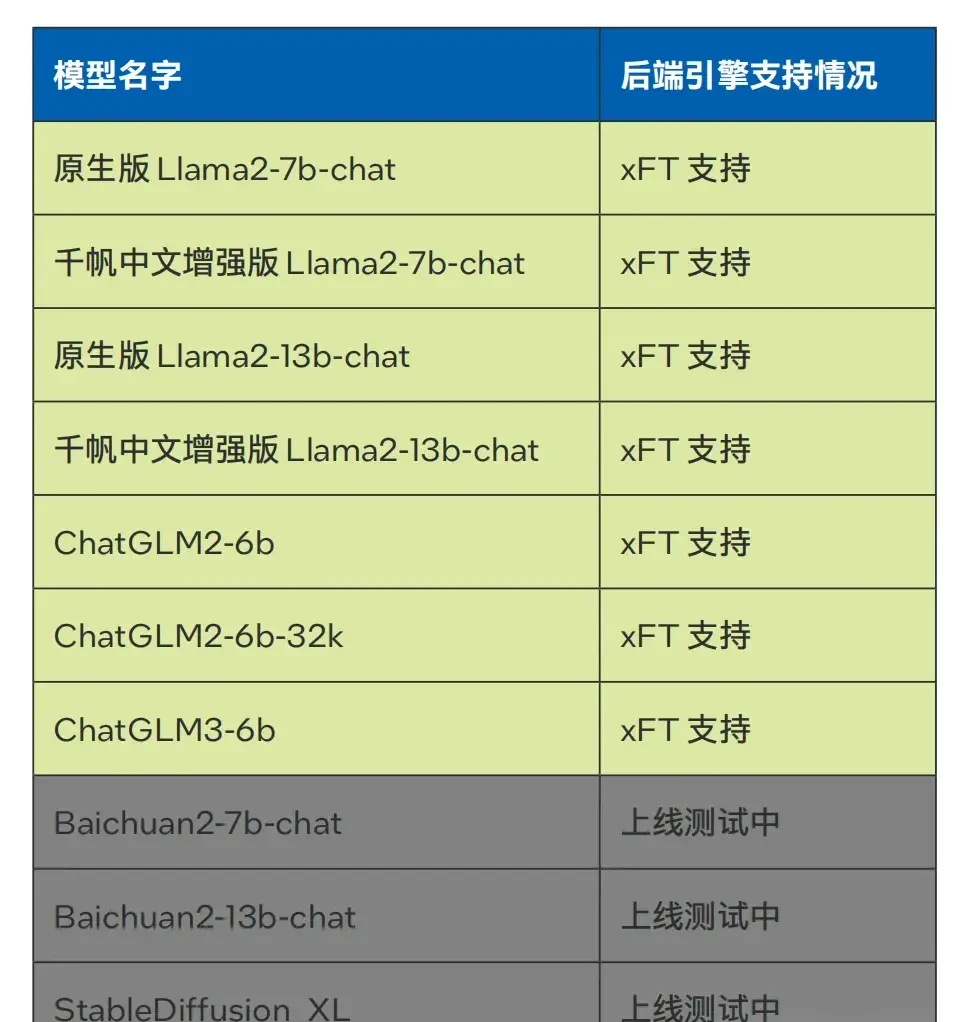
Furthermore, the Qianfan Large Model Platform has expanded its scope beyond Baidu’s own ERNIE models. It now integrates many mainstream large models from other providers, indicating a broader ecosystem shift toward hardware agnosticism in deployment layers.
This indirect validation confirms that fifth-generation Intel® Xeon® Scalable processors meet the rigorous performance standards required by major domestic AI platforms. The reliance on CPU-based inference for these top-tier models signals a pragmatic recalibration of infrastructure priorities across the region.
I think this trend mirrors Western efforts to optimize inference costs using specialized CPU instructions. From an APAC angle, it challenges the assumption that GPU dominance is absolute for all deployment stages. Globally, supply chain diversification often drives such hardware-agnostic platform strategies.
Why Domestic AI Leaders Are Betting on CPUs
Baidu Intelligent Cloud’s Qianfan Large Model Platform is not merely an inference engine; it is a platform covering the entire lifecycle of large models.
I followed how Qianfan structures its services—data annotation, model training and evaluation, inference, application integration, rapid orchestration, and plugins. This full-stack approach changes the economics of deployment. In this context, fully utilizing the widely deployed CPU resources on the platform is a more cost-effective choice compared to deploying dedicated accelerators solely for large model inference.
For the vast number of offline large model application demands on Qianfan—such as generating article summaries, abstracts, or evaluating multiple models’ effects—these requirements do not have strict latency needs but often face memory bottlenecks. Using CPUs makes memory expansion more convenient and allows for the utilization of idle computing resources during off-peak times, further improving resource utilization and reducing total cost of ownership.
Against this backdrop, the design of performance-intensive general-purpose computing application loads (similar to P-Core performance cores) in fifth-generation Intel® Xeon® Scalable processors becomes particularly critical. Compared to E-Cores (efficiency cores), P-Cores adopt a design focused on maximizing performance, capable of handling very heavy workloads while also supporting AI inference acceleration.
I think the shift toward CPU-based inference highlights the global struggle with GPU supply constraints and cost volatility. From an APAC angle, this strategy suggests that not all AI workloads require specialized silicon to be commercially viable.
The adoption of this design in fifth-generation Xeon® Scalable processors is not just talk; it involves hardware-software co-optimization with comprehensive consideration across all aspects. On the hardware side, Intel® AMX (Advanced Matrix Extensions) technology is specifically optimized for the massive matrix multiplication operations involved in deep learning within large model inference. It can be understood as “Tensor Cores inside the CPU.”
With Intel® AMX, each processor clock cycle can complete up to 2048 INT8 operations, an eightfold improvement over the previous generation’s AVX512_VNNI instructions. More importantly, the Intel® AMX accelerator is built directly into the CPU core, bringing matrix storage and computation closer together. This feature reduces latency when processing subsequent tokens in large model inference, enhancing end-user experience.
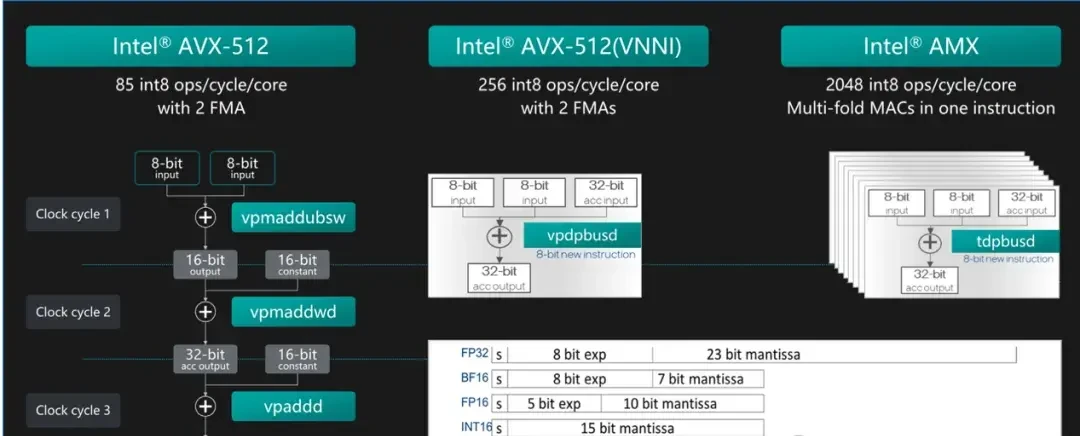
△ Intel® AMX enables more efficient AI acceleration
On the software side, Baidu Intelligent Cloud’s Qianfan Large Model Platform has introduced xFasterTransformer (xFT), a large model inference software solution deeply optimized for the Intel® Xeon® Scalable platform, using it as the backend inference engine. The main optimization strategies are as follows:
- Fully utilizing instruction sets such as AMX/AVX512 to efficiently implement core operators like Flash Attention
- Adopting low-precision quantization to reduce data access volume and leverage the advantages of INT8/BF16 operations
- Supporting multi-machine, multi-card parallel inference for ultra-large-scale models
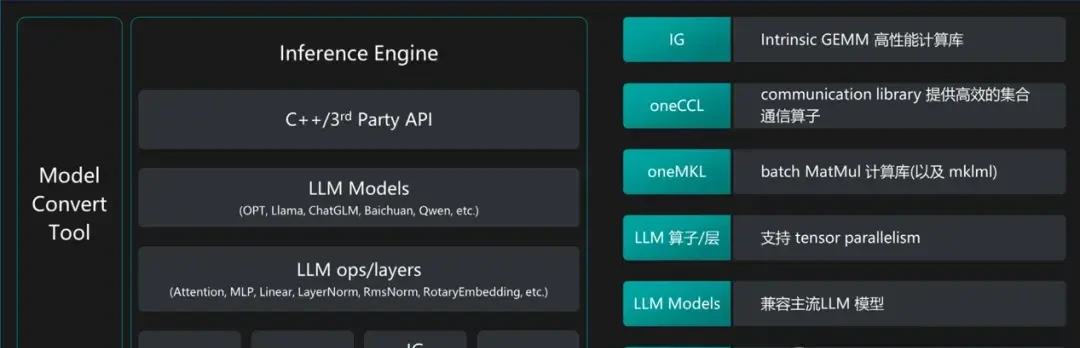
△ Intel® Xeon® Scalable Processor LLM Inference Software Solution
Finally, it is worth noting that choosing a hardware platform affects not only the initial procurement cost but also subsequent maintenance costs and even talent reserve expenses. As Baidu Intelligent Cloud states, high-cost-performance computing infrastructure works in tandem with advanced large model algorithms and platform software, allowing upper-layer developers to apply and build their businesses more smoothly, thereby maximizing the commercial value of cloud computing platforms.
Globally, talent availability for general-purpose CPU architecture is broader than that for niche accelerators. I think this holistic view of TCO challenges the industry’s singular focus on raw inference speed.
Why Are Leading Domestic AI Model Developers Choosing CPUs?
The Strategic Pivot to General-Purpose Compute
As large models migrate from experimental labs into industrial workflows, the narrative is shifting. They are no longer exclusive “toys” for a select few but essential tools for mass consumption. This transition demands infrastructure that balances performance with affordability and ease of deployment. For me, this highlights a critical commercial reality: “fast, high-quality, and cost-effective” operations are now the linchpin for large model viability.
To achieve this balance, the choice of computing infrastructure is paramount.
While traditional wisdom dictates that dedicated accelerators are the “standard configuration” for AI, tight supply chains and soaring costs are eroding their competitive edge. In contrast, well-optimized high-end CPUs offer sufficient power for inference while providing a broader deployment foundation, a mature software ecosystem, and robust security safeguards. Consequently, industry players are increasingly favoring this approach.
From an APAC angle, supply chain constraints are forcing a pragmatic re-evaluation of hardware dependencies across global markets. Globally, the shift toward general-purpose compute reduces vendor lock-in risks for multinational enterprises.
Intel® Xeon® series processors exemplify this trend. Their established x86 ecosystem allows millions of developers to leverage existing tools and frameworks, bypassing the need to learn specialized accelerator stacks. This significantly lowers development complexity and migration costs. Furthermore, enterprise users can exploit multi-layered security technologies built into CPUs for full-stack protection from hardware to software—a level of data privacy difficult for dedicated accelerators to match.
Therefore, fully leveraging CPUs for inference is a key strategy for the AIGC industry to overcome computing barriers and drive adoption. It transforms AI from a capital-intensive “money-burning game” into inclusive technology. As ecosystems mature, this model will create value for more enterprises and inject new momentum into industrial development.
Beyond direct acceleration, CPUs efficiently handle critical end-to-end pipeline steps like data preprocessing and feature engineering. Many databases supporting machine learning and graph analysis are built on CPU architectures. For instance, Intel® Xeon® Scalable Processors integrate Intel® Advanced Matrix Extensions (Intel® AMX) alongside engines like Intel® QuickAssist Technology (Intel® QAT) for compression and Intel® In-Memory Analytics Accelerator (Intel® IAA). By offloading specific tasks, these features improve CPU utilization and overall workload performance.
Thus, building “fast, accurate, and stable” AI applications relies not only on dedicated accelerators but also on the superior general-purpose capabilities of CPUs to unlock full system potential.
To popularize this shift, our desk has launched the “Most ‘In’ AI” column. This series will interpret the topic through technical education, industry case studies, and practical optimization strategies. We aim to help readers understand how to better utilize CPUs to enhance performance and efficiency in large model applications.

— End —
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google