4B Small Model Surpasses Claude 4 in Math Reasoning; 700-Step RL Training Approaches 235B Performance | HKU, ByteDance Seed & Fudan University
What’s the Difference Between a 4B Model and Top-Tier Commercial LLMs in Mathematical Reasoning?
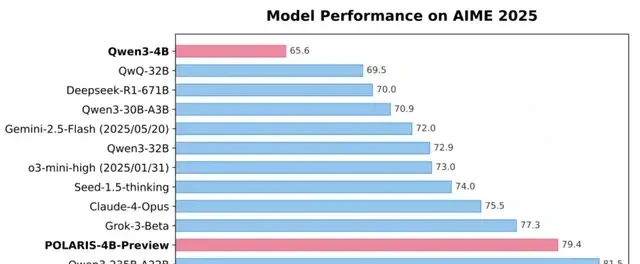
I read the release from the University of Hong Kong NLP team, working with ByteDance Seed and Fudan University. They have published Polaris, a reinforcement learning (RL) training recipe that claims to punch well above its weight class. By scaling RL, Polaris enables a 4B model to achieve mathematical reasoning scores of 79.4 on AIME25 and 81.2 on AIME24. These numbers surpass numerous commercial large language models such as Seed-1.5-thinking, Claude 4 Opus, and o3-mini-high (as of January 31, 2025).
The lightweight nature of Polaris-4B allows it to be deployed on consumer-grade graphics cards. The detailed blog post, training data, model weights, and code have all been open-sourced. Links are provided at the end of this article.
I think lab benchmarks don’t account for the latency penalties of running complex RL loops in real time. In the field, consumer GPUs can handle inference, but not necessarily the compute-heavy training cycles required to maintain these scores.
Parameter Configuration Centered on the Target Model
Previous RL training recipes, such as DeepScaleR, have demonstrated the powerful effects of scaling RL on weaker base models. However, can scaling RL replicate such significant improvements for currently state-of-the-art open-source models (such as Qwen3)? The Polaris research team provides a clear answer: Yes! Specifically, through just 700 steps of RL training, Polaris successfully enabled Qwen3-4B to approach the performance of its 235B counterpart in mathematical reasoning tasks.
When applied correctly, RL holds immense potential for development. The secret to Polaris’s success lies in this principle: both training data and hyperparameter settings must be tailored specifically to the model being trained.
What I watch for is a 700-step sprint is a proof of concept, not a robust pipeline for production-grade reliability. I think matching a 4B model to a 235B’s reasoning requires massive compute overhead that rarely fits unit economics.
Training Data Construction
The Polaris team discovered that for the same dataset, base models with different capabilities exhibit a mirror-image distribution of difficulty levels. For each sample in the DeepScaleR-40K training set, researchers used two models—R1-Distill-Qwen-1.5B and R1-Distill-Qwen-7B—to reason through the problem eight times each. They then counted the number of correct answers to measure the difficulty level of each sample.
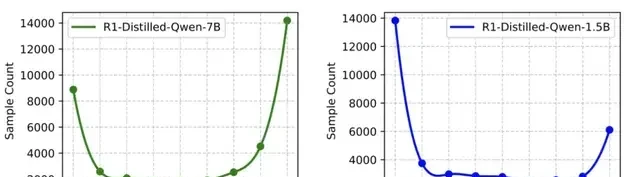
Experimental results showed that most samples were located at the extremes (8/8 correct or 0/8 correct). This means that while the dataset was challenging for the 1.5B model, it was insufficient to effectively train the 7B model. Polaris proposes constructing a data distribution slightly biased toward harder problems, shaped like an inverted “J.” Distributions overly skewed toward easy or hard problems result in samples that offer no advantage occupying too large a proportion of each batch.
The team filtered open-source datasets DeepScale-40K and AReaL-boba-106k, removing all samples with 8/8 correct answers, ultimately forming an initial dataset of 53K samples.
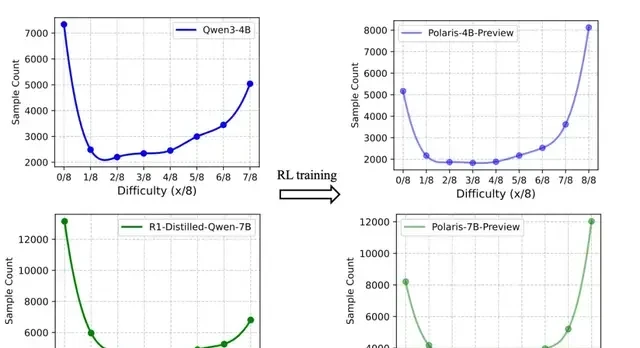
Although a good initial dataset was obtained, it is not the “final version” of the training data. During reinforcement learning training, as the model’s “mastery rate” over training samples increases, difficult problems become easy ones. To address this, the research team introduced a dynamic data update strategy during training. The pass rate for each sample was updated in real-time based on reward calculations. At the end of each training stage, samples with excessively high accuracy were removed.
Tuning Temperature for Real Exploration
I read the HKU and ByteDance Seed paper on Polaris, and what stood out was their insistence that standard sampling settings are choking model potential. In RL training, diversity isn’t just a nice-to-have; it’s the engine that prevents models from getting stuck in deterministic loops early on. Most labs default to top-p=1.0 and temperature t=1.0 or 0.6, assuming maximum variety is automatic. That assumption is wrong for high-stakes reasoning.
In the field, lab charts look clean until you try this on a noisy edge device. What I watch for is diversity metrics don’t pay the bills if the robot crashes. I think we need robust unit economics, not just higher N-gram scores.
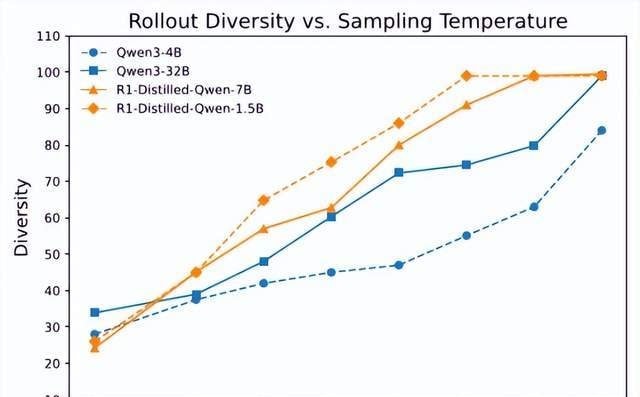
The Polaris team ran experiments to map the relationship between sampling temperature, accuracy, and path diversity. They used the Distinct N-gram metric (n=4) to quantify trajectory variety—scores near 1.0 mean high diversity, while lower scores indicate repetitive, stuck behavior. The data showed that higher temperatures boost diversity, but the effect varies wildly by model architecture. For instance, a temperature of 0.6 clearly failed to generate sufficient diversity for the models tested.
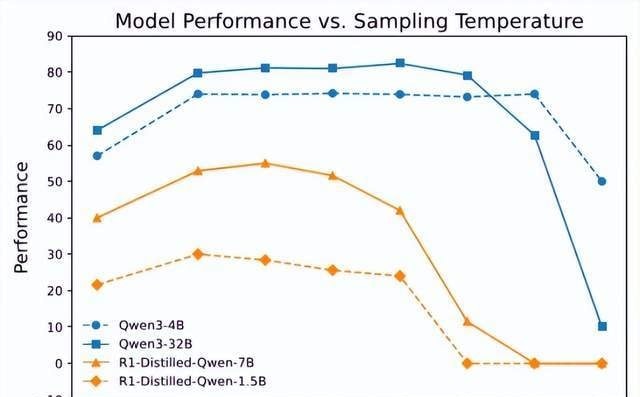
However, cranking up the temperature is not a free lunch. Performance followed a “low-high-low” curve as temperature increased. A setting of 1.0 was too aggressive for Deepseek-R1-distill models but slightly conservative for Qwen3 series models. This confirms that ideal temperature design requires fine-tuning per model; there is no single hyperparameter that fits all architectures.
In the field, one-size-fits-all hyperparameters are a relic of the demo era. I’d rather see a robot adapt its own safety margins than chase a generic score.
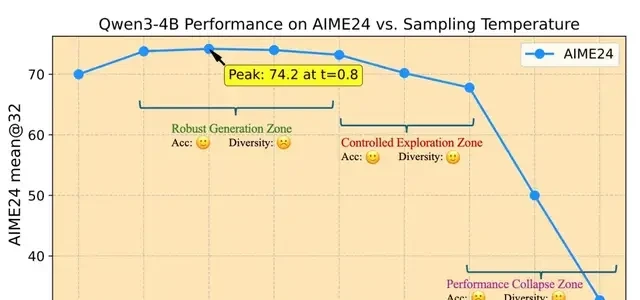
Based on these trends, the team defined three temperature zones:
- Robust Generation Zone: Minimal performance fluctuation; this is where test-time decoding usually lives.
- Controlled Exploration Zone: Slight performance drop compared to the robust zone, but significantly higher diversity. This is the sweet spot for training temperatures.
- Performance Collapse Zone: Temperatures here cause sharp drops in accuracy.
The proposal is to start training in the Controlled Exploration Zone rather than the safe Robust Generation Zone.
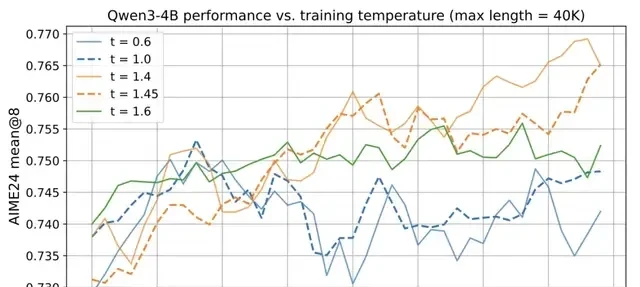
Common settings like t=0.6 or t=1.0 are too low, restricting the exploration space and limiting Reinforcement Learning potential. Consequently, Polaris sets the initial training temperature for Qwen3-4B to 1.4. This higher baseline forces the model to explore broader reasoning paths that standard decoding would ignore.
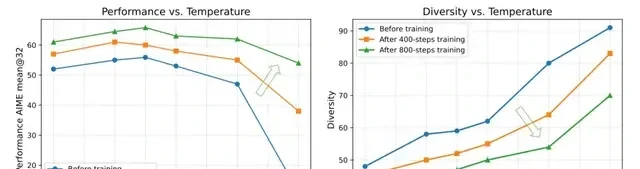
As training converges, diversity naturally shifts. The proportion of shared N-grams across paths increases, narrowing the exploration space. Using a static initial temperature throughout leads to insufficient diversity in later stages. To address this, the Polaris team proposes a strategy for dynamic adjustment, though the text cuts off before detailing the specific decay or scaling mechanism.
The Temperature Treadmill
I read the paper from HKU, ByteDance Seed, and Fudan University, and what stood out was their approach to dynamic sampling temperatures during reinforcement learning (RL) training. Rather than letting the model settle into a single mode, they employ a search method similar to initializing temperature before each stage begins. This ensures that the diversity score at the start of subsequent stages remains comparable to that of the first stage.
For example, if the diversity score at the beginning of the first stage is 60, Polaris will select a temperature in each subsequent stage that pulls the diversity score back up to 60 for training. It’s a closed-loop control system for creativity, forcing the model to keep exploring rather than converging too early on safe, low-diversity answers.
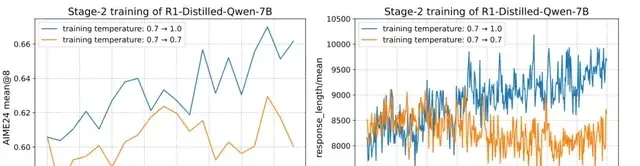
Comparative experiments show that using a single temperature throughout training yields inferior results compared to multi-stage temperature adjustment. Multi-stage temperature adjustment not only leads to better RL training outcomes but also ensures more stable increases in response length. This suggests that rigid hyperparameters are the bottleneck, not compute budget.
What I watch for is dynamic cooling prevents early convergence on lazy answers. I think stability matters more than peak performance in production. In the field, lengthier responses don’t always mean better reasoning.
Extending the Chain of Thought
I read how Qwen3-4B struggled with long-context training during its RL phase. The model’s pre-training context was capped at 32K tokens, but Polaris pushed the maximum training length to 52K. In practice, less than 10% of samples hit that ceiling, meaning very little actual long-text training occurred.
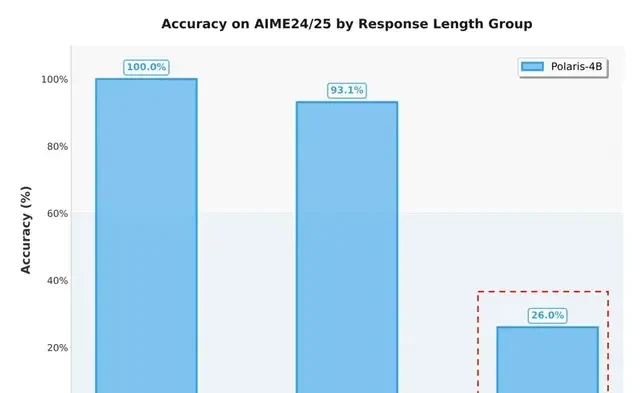
To test long-text generation, the Polaris team used 60 problems from AIME 2024/25. They ran 32 reasoning attempts per problem, totaling 1,920 samples. These were split into three groups by length: short (under 16K), medium (16K–32K), and long (over 32K).
The results showed that accuracy for the long-text group was only 26%. This indicates a significant performance drop when generating Chain-of-Thought responses beyond the pre-training context. The team concluded that RL struggles with long contexts, likely due to insufficient training data in that range.
What I watch for is lab benchmarks love long chains; field deployments hate the latency and cost they bring.
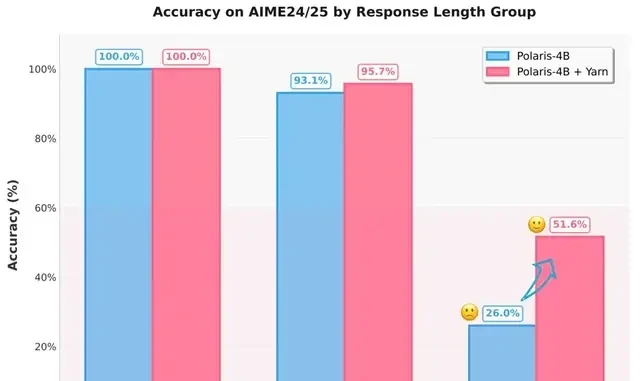
To fix this scarcity, the researchers introduced length extrapolation technology. By adjusting RoPE (Rotary Position Embedding), the model can handle sequences longer than those seen during training at inference time. They used YaRN as the method with an expansion factor of 1.5:

Applying this strategy increased accuracy for responses over 32K tokens from 26% to over 50%.
I think extrapolation tricks the attention mechanism but doesn’t create new reasoning skills.
Multi-Stage Training Dynamics
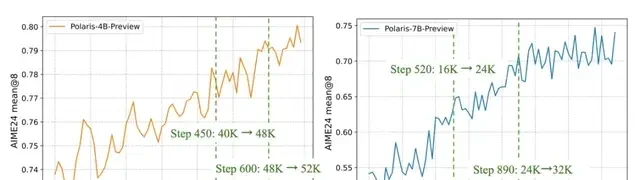
Polaris uses a multi-stage training approach. Initially, the model uses a shorter context window; once performance converges, the length is gradually increased to broaden reasoning capabilities. While this can work, selecting the right initial maximum length is critical because base models vary in token utilization efficiency.
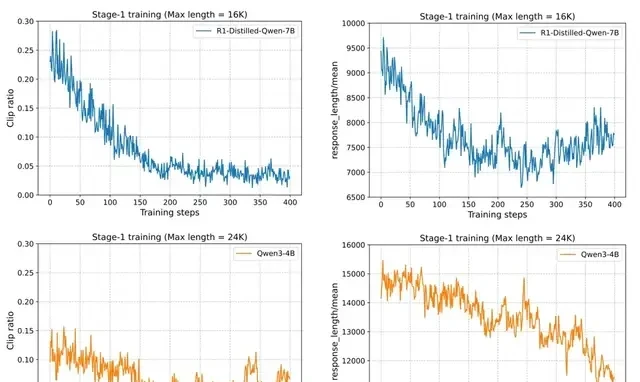
Experiments showed that for DeepSeek-R1-Distill-Qwen-1.5B and 7B, shorter response lengths worked well. However, for Qwen3-4B, performance dropped sharply when the response length was only 24K, even with a truncation rate below 15%. This decline was difficult to recover from in later stages.
In the field, starting small and scaling up often locks in suboptimal reasoning patterns.
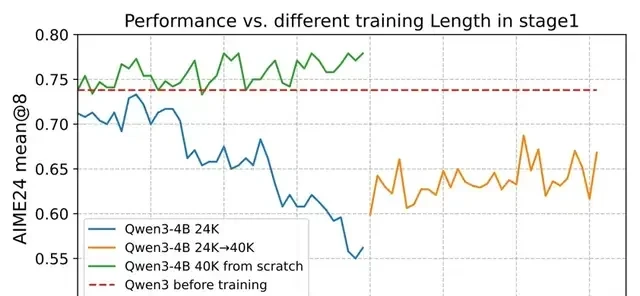
The team found it safer to encourage the model to “think longer” from the start. For Qwen3-4B, starting with a 40K response length yielded steady improvements. This contrasted sharply with schemes that started at 24K or transitioned from 24K to 40K.
Key Takeaway: When computational resources allow, start directly with the maximum decoding length recommended by the official repository.
The Benchmarks Don’t Lie, But the Cost Does
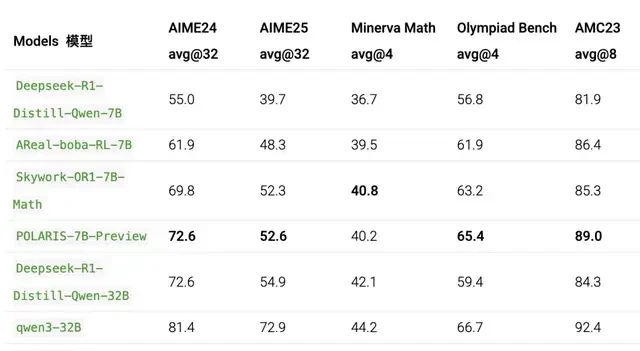
I read the Polaris release notes, and what stands out is not just the raw scores, but the specific configuration required to get them. The model demands a higher sampling temperature and longer response lengths than Qwen3; every other variable was held constant to ensure a fair comparison. For the AIME 24 and AIME 25 benchmarks, the reported figures represent the average performance across 32 distinct runs—a level of statistical rigor that usually gets skipped in marketing decks.
What I watch for is higher temperature means more tokens burned per answer. Longer responses kill latency on edge devices.
The results are stark: Polaris pushed a mere 4B parameter model to achieve 79.4 on AIME 25 and 81.2 on AIME 24. This performance surpasses numerous commercial large language models, allowing it to perform best in most evaluations despite having a fraction of the compute footprint. It is one thing to beat a closed-source giant in a controlled lab setting; it is another to do so with a model small enough to potentially fit on hardware that doesn’t require a dedicated data center rack.
I think beating Claude 4 on math is impressive, but can it hold the line under load? In the field, 32 runs prove consistency, not necessarily real-world robustness.
The underlying philosophy here—POLARIS—is presented as a post-training recipe for scaling reinforcement learning on advanced reasoning models. The team from HKU, ByteDance Seed, and Fudan University is suggesting that clever training loops matter more than sheer model size. If this approach holds up when deployed outside the benchmark environment, it could shift the unit economics of AI reasoning significantly.
notion address: https://honorable-payment-890.notion.site/POLARIS-A-POst-training-recipe-for-scaling-reinforcement-Learning-on
Advanced-ReasonIng-modelS-1dfa954ff7c38094923ec7772bf447a1
Blog URL: https://hkunlp.github.io/blog/2025/Polaris/
Code Repository: https://github.com/ChenxinAn-fdu/POLARIS
Hugging Face Hub: https://huggingface.co/POLARIS-Project
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google