The robotics sector needs a reality check, and Fei-Fei Li is delivering one. Her team just released ESI-Bench, a benchmark that strips away the illusion of current AI capabilities in embodied spatial intelligence. This isn’t just another dataset; it’s a stress test for the perception-action loop that defines true physical agency.

Previous spatial benchmarks were flawed by design. They fed models optimal observations, assuming perfect input conditions that rarely exist in the real world. ESI-Bench changes the dynamic by turning the observer into an actor. It forces systems to close the perception-action loop, mirroring how humans actually navigate and interact with physical spaces. This shift from passive recognition to active engagement is critical for evaluating progress in embodied AI.
The framework evaluates four dimensions of core human spatial cognitive abilities. By doing so, it provides a systematic way to measure what matters: not just seeing, but understanding space through movement and interaction.

The paper’s conclusion is blunt and necessary. Current AI is excellent at interpreting images, but it is still far from possessing “spatial intelligence” that involves moving, touching, and actively seeking answers. This gap between visual recognition and physical agency remains the primary bottleneck for robotics adoption. Investors should note that while computer vision has matured, embodied intelligence is still in its infancy.
Honestly, eSI-Bench exposes the hollowness of current spatial AI claims. I think the perception-action loop is now the only metric that matters for robotics.
The Shift from Watching to Doing
I read the release notes for ESI-Bench, and the distinction is stark. Current benchmarks treat AI like a passive observer—showing it an image and asking if object A is left of object B. That tests visual acuity, not intelligence.
Fei-Fei Li’s team argues this is insufficient. Humans don’t just look; we move. We walk around objects, open drawers, and pour liquids to understand capacity. ESI-Bench forces AI agents into that same “Perception-Action Loop.” The agent must act to gather evidence before it can answer.

The benchmark is built on OmniGibson, using assets from BEHAVIOR-1K. It covers 10 task categories and 29 sub-categories across 3,081 instances. The core premise is mandatory action. An agent cannot sit idle waiting for a better angle; it must decide where to go and what to manipulate.
The way I see it, passive vision models will fail here because they lack the motor control to verify spatial truths.
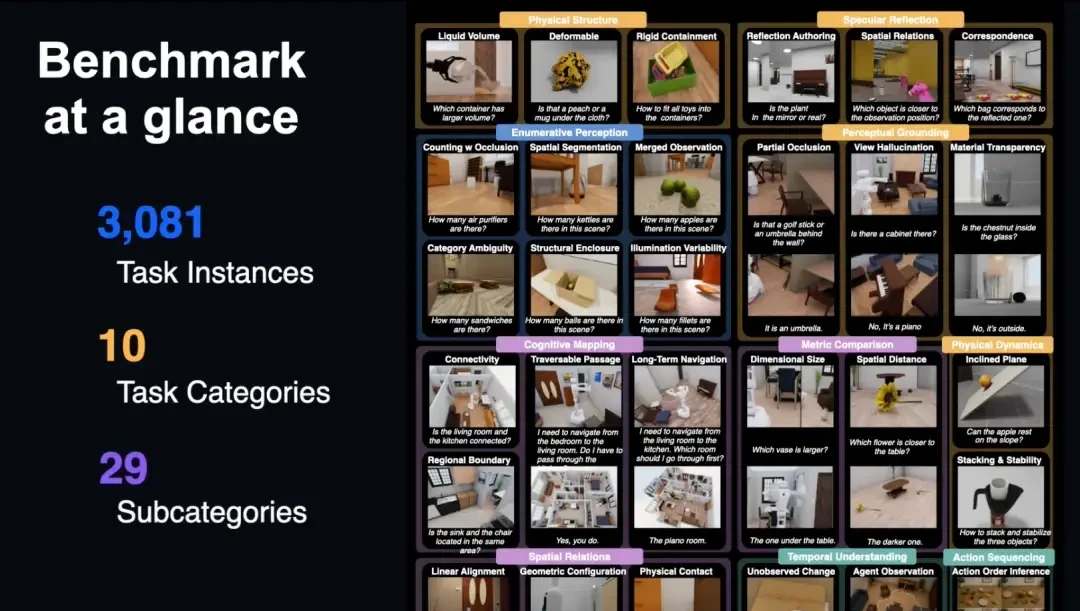
The tasks are grounded in Spelke’s four core knowledge systems: object representation, layout and geometry, number representation, and goal-directed action. These are the spatial intuitions humans possess from infancy. ESI-Bench demands that AI replicate this active reasoning process.
Consider “rigid containment.” An agent sees containers with small openings or internal dividers. It must approach, lean in, or pick up the container to see if items fit. The answer isn’t in a single static image; it requires physical verification.

Then there is “liquid volume.” Two cups may look identical externally. The agent must pour water into them or lift them to gauge weight and true capacity. This design philosophy rejects the idea that correct answers exist within a single frame of reference.
Honestly, if your model can’t simulate physical interaction, it’s not ready for real-world deployment.

The team highlights three key advancements over previous work. First, the shift from spatial perception to spatial capability. Agents are evaluated on whether they know which specific capabilities to deploy to solve tasks.
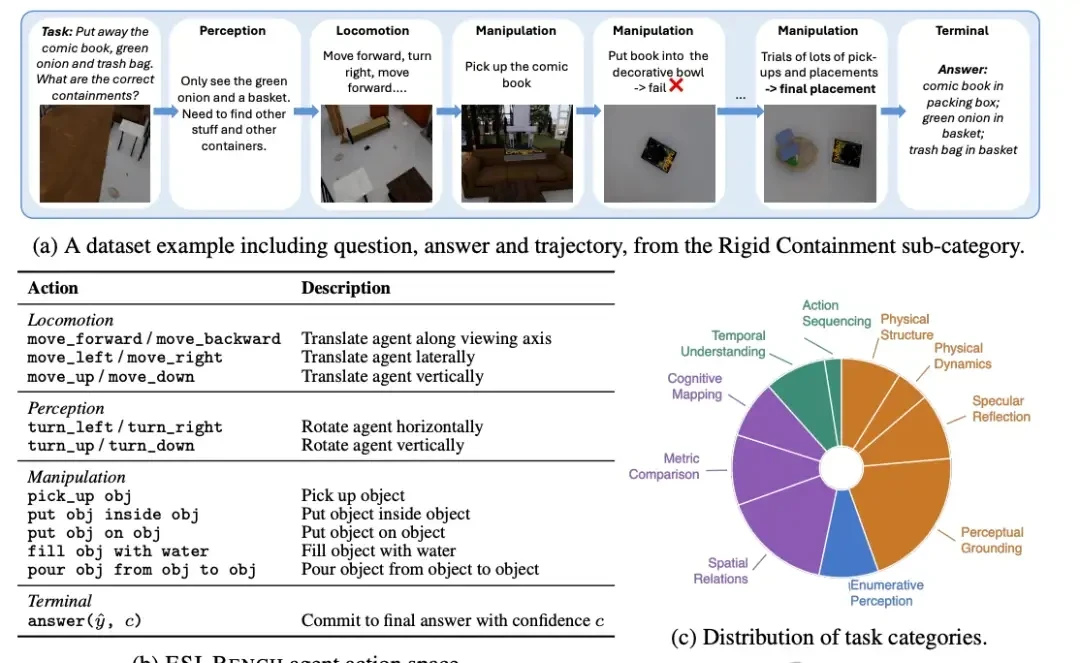
Second is selective perception. Agents must determine which observations are worth acquiring. They need to prioritize relevant information over redundant inputs, filtering out noise in complex environments.

Finally, resolving perceptual ambiguity. Agents must reason through misleading observations to infer hidden spatial structures and physical constraints that go beyond direct sight. This is where the gap between current AI and human-like reasoning widens significantly.
I think valuation depends on who builds the first model that masters this loop without hallucinating physics.
Fei-Fei Li Strikes Again: The ImageNet for Spatial Intelligence Arrives
What did we find? 3 Core Conclusions
I read the latest benchmarks from Fei-Fei Li’s team, and they are dismantling the current hype around multimodal reasoning. They tested state-of-the-art models like GPT-5 and the Gemini series on ESI-Bench. The results expose a critical flaw in how we build spatial AI: perception is cheap; action is expensive.
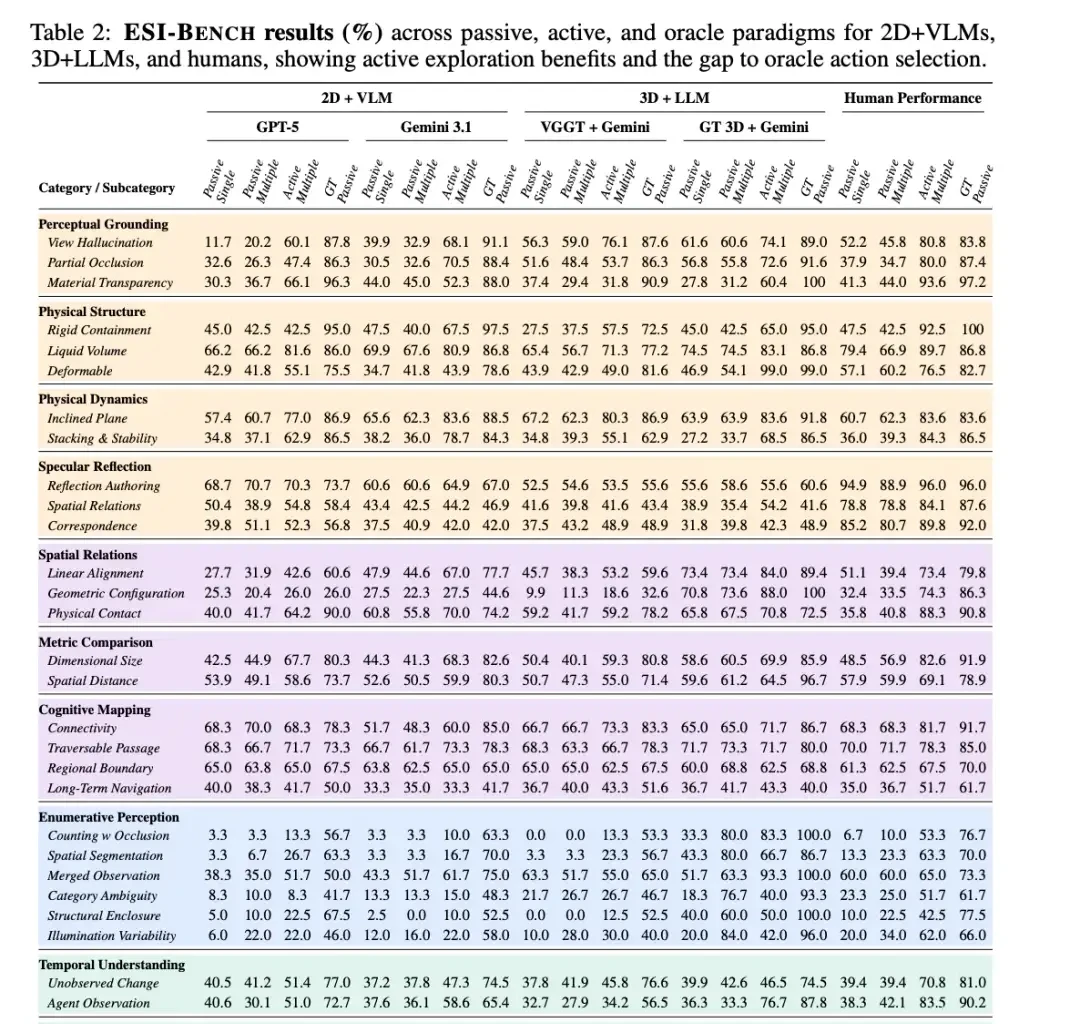
This chart shows accuracy across three paradigms in ESI-Bench: passive perception, active exploration, and Oracle. It compares 2D+VLM, 3D+LLM, and human baselines. Here are the takeaways that matter for your roadmap.
First, perception is not the bottleneck; action is.
The data confirms that active exploration works. Agents spontaneously developed spatial strategies without extra instructions. They moved behind objects to see them (move-behind), switched to top-down views (top-down), picked up items (pick-up), or poured liquids to check contents (pour-out).

In partial occlusion tasks, Gemini 3.1’s accuracy jumped from 14.6% to 95.1% with the optimal viewing angle. This proves inherent perceptual capabilities are strong. Given the right perspective, models understand what they see.
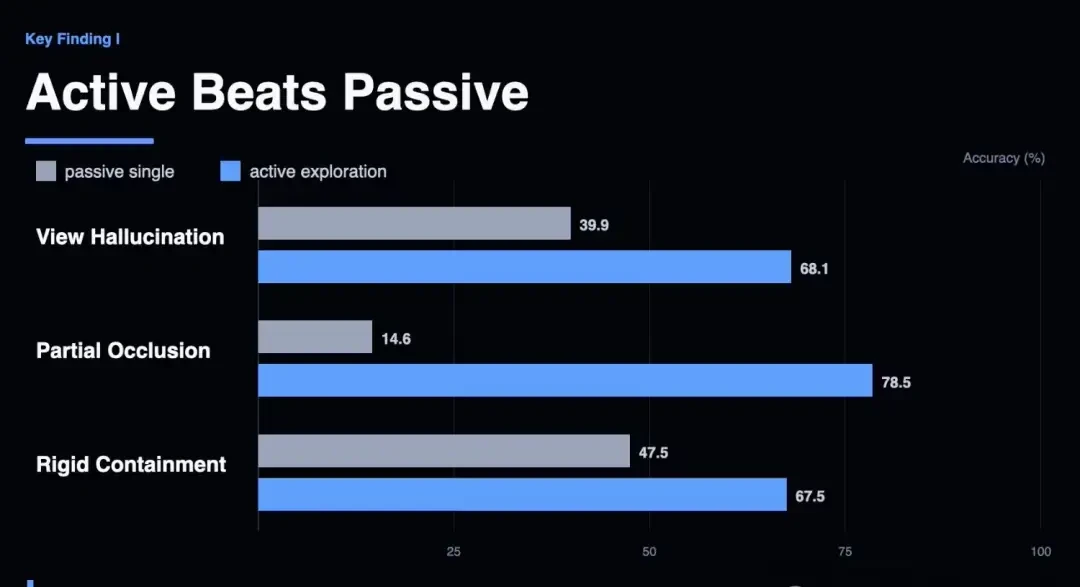
The problem is models cannot find that perspective themselves. Worse, passive multi-view strategies are harmful. Showing GPT-5 random-angle images dropped its spatial distance accuracy from 53.9% to 49.1%. More pictures meant lower scores.
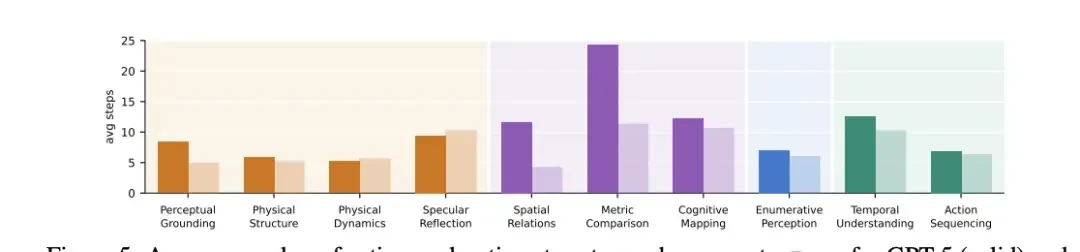
△ Average steps required for GPT-5 and Gemini 3.1 to reach the correct answer during active exploration
The team calls this “Action Blindness.” A poor action creates a bad perspective, triggering worse actions in an irreversible cascade. In structural enclosure tasks, the gap between active exploration and “God’s eye view” is 49.7%.
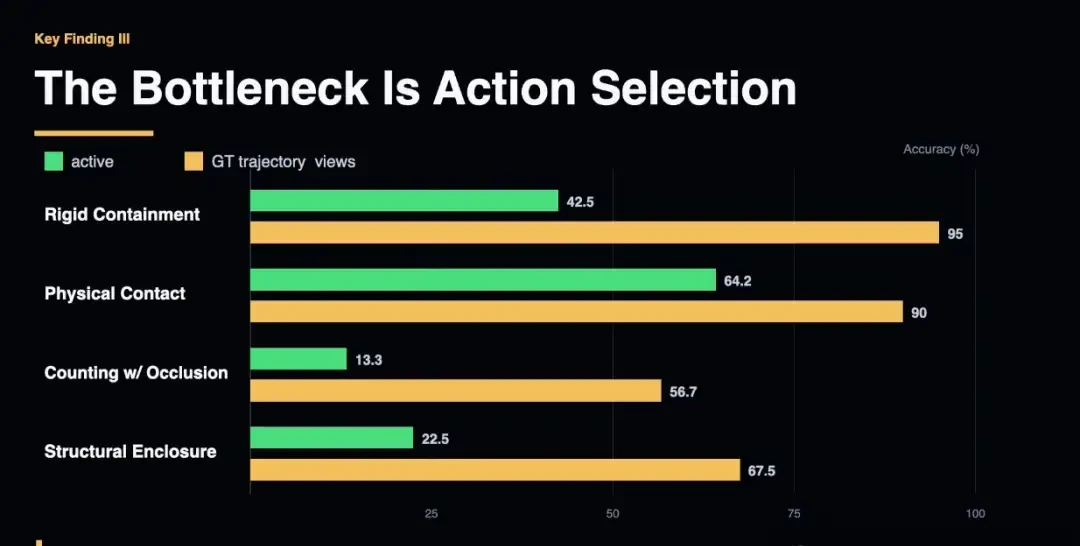
The way I see it, vendors selling “vision-only” spatial agents are ignoring the action layer entirely.
The bottleneck isn’t weak visual models; it is nearly non-existent action strategies. If your stack relies on static image analysis, you are already obsolete for embodied tasks.
Second, 3D reconstruction is not a panacea; imperfect 3D is worse than 2D.
Many embodied AI teams try to reconstruct 3D scenes first, then reason on the map. Ground-truth 3D (perfect geometry) does help. Gemini scored 44.0% in 2D and 60.4% in 3D for material transparency tasks. That is a 16.4 percentage point gain. Precise depth information has natural advantages.
But real-world reconstruction fails. The team used the state-of-the-art VGGT model to reconstruct scenes and fed them into reasoning models. Results were dismal. In geometric configuration tasks, the 2D baseline scored 27.5%, while VGGT’s scene map scored only 9.9%.
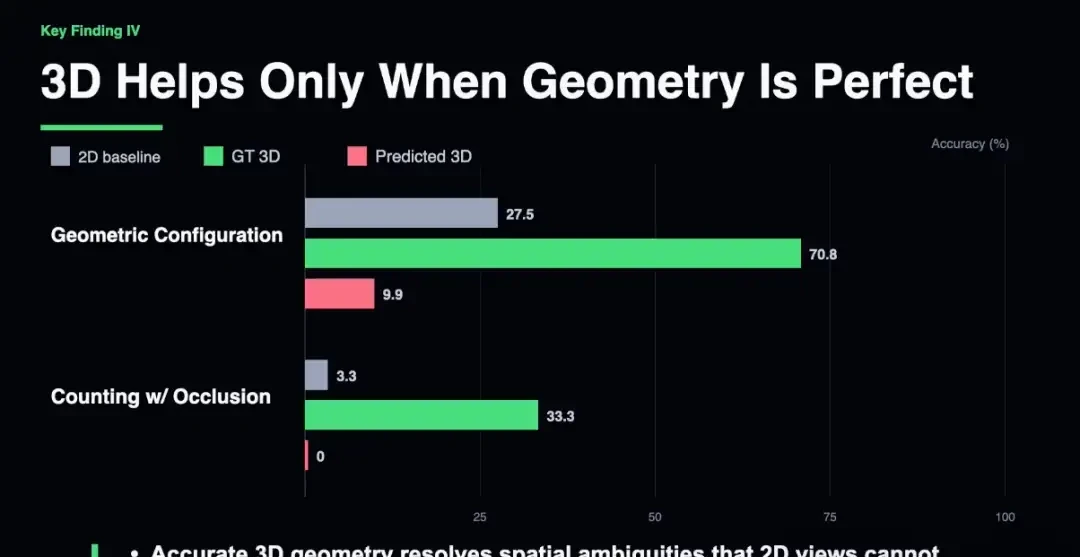
Imperfect 3D is a negative failure. Geometric artifacts, occlusion errors, and depth biases encode distorted information into scene maps. This feeds “toxic” inputs to the reasoning model. 2D provides less info but remains undistorted. If reconstruction quality is subpar, it performs worse than raw 2D.
Honestly, don’t bet on 3D reconstruction until VGGT-level fidelity becomes commodity hardware.
The cost of geometric error outweighs the benefit of depth data in current models. Your engineering budget is better spent on robust 2D grounding than fragile 3D pipelines.
Third, metacognitive defects: Models do not know if they have seen enough.
The paper includes experiments comparing agents and humans on spatial reasoning gaps. The core issue remains: models lack the self-awareness to stop exploring or start reasoning at the right time. They continue acting blindly until failure is inevitable.
Fei-Fei Li Strikes Again: The ImageNet for Spatial Intelligence Arrives
The results reveal a critical nuance in the current AI arms race: while models are closing the perceptual gap with humans, they remain fundamentally broken at active reasoning. This distinction matters because it signals that scaling visual encoders alone will not solve spatial hallucinations. We need to stop treating “seeing” and “thinking about what we see” as the same problem.
In specific categories, the model’s passive performance can even match or surpass human performance. Under real trajectory conditions, Gemini achieved 88.4% accuracy in partial occlusion tasks, compared to 87.4% for humans; GPT-5 reached 96.3% in material transparency tasks, while humans scored 97.2%.
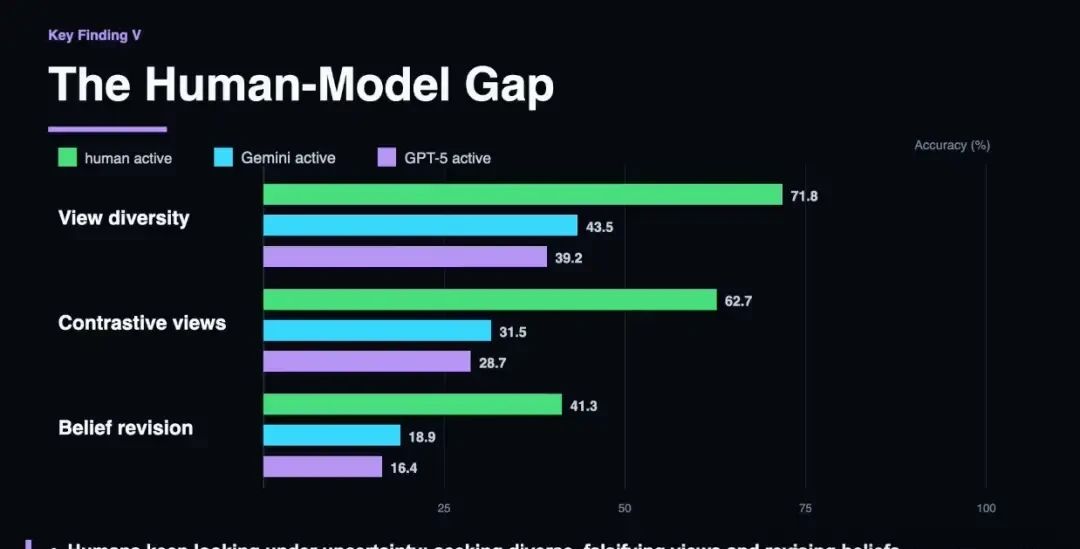
However, in active exploration scenarios, the gap widens significantly. Humans outperform models due to clear observation goals and stopping criteria, with their active exploration performance closely mirroring their passive performance under real trajectories. For instance, in physical contact tasks, human accuracy was 88.3%, while GPT-5 scored only 64.2%; in material transparency tasks, humans achieved 93.6% accuracy, whereas Gemini 3.1 scored just 52.3%.
By analyzing the exploration trajectories of models and humans, the team found that humans exhibit stronger cognitive caution: they gather more observations before making judgments, actively seek perspectives that might falsify current hypotheses, and lower their confidence in ambiguous situations. Models, on the other hand, stop exploring too early. Even when evidence is ambiguous, they make high-confidence judgments after only a few steps, leading to spatial hallucinations contrary to the scene’s actual state.

The models’ overconfidence is exacerbated by directional biases in action selection: instead of probing orthogonal angles or seeking perspectives that could overturn initial impressions, models repeatedly move in the same direction, accumulating redundant information rather than effective observations. The team characterizes this as a metacognitive defect: the model does not know what it does not know. It lacks an innate “skepticism mechanism,” unable to assess whether current information is sufficient or adjust beliefs based on contradictory evidence. This issue differs fundamentally from perceptual capabilities and represents a more foundational challenge that cannot be solved merely by stronger visual encoders or additional exploration steps.
I think passive perception is commoditized; active reasoning remains the true moat for enterprise AI. The way I see it, current models lack metacognition, making them unreliable for high-stakes spatial tasks.
The Team Behind the Push
This isn’t just another academic exercise. It’s a coordinated strike by Stanford’s elite to define spatial intelligence before competitors catch up. I read the author list, and it signals serious institutional weight behind this dataset push.

Lead author Yining Hong anchors the effort. She is a postdoctoral researcher at Stanford, advised by Yejin Choi, with close guidance from Leonidas Guibas, Jiajun Wu, and Fei-Fei Li. Her background bridges hard engineering and creative discipline—she holds a Ph.D. in Computer Science from UCLA and an undergraduate degree in Electronic Engineering from Shanghai Jiao Tong University. Notably, she is also a professional musician who tours with her band and served as Social Chair for CVPR 2026, organizing the conference reception and musical performances.

Jiageng Liu brings the UCLA perspective. He is a Ph.D. student in the Mobility Lab at UCLA, having completed his undergraduate studies at Zhejiang University’s Zhu Kezhen Honors College and the Turing Class of the School of Computer Science and Technology, earning a bachelor’s degree in Artificial Intelligence.
Han Yin rounds out the core team. He is an undergraduate student at Tsinghua University majoring in Computer Science and Technology, currently interning at Stanford University.

The senior author list confirms the pedigree. Stanford professors Fei-Fei Li, Jiajun Wu, and Yejin Choi appear on the author list.


Additional contributors include Professor Manling Li from Northwestern University and Professor Leonidas Guibas from Stanford University.
Honestly, the author lineup proves this is a Stanford-led offensive, not just an academic curiosity. I think yining Hong’s dual background in engineering and music suggests a holistic approach to spatial data.
References
I reviewed the source materials to verify the technical claims and access the public resources for this report.
- ESI-Bench: Towards Embodied Spatial Intelligence that Closes the Perception-Action Loop — Spatial intelligence unfolds through a perception-action loop: agents act to acquire observations, and reason about how observations vary as a function of action. Rather than passively processing what is seen, they actively engage with their environment.
- esi bench.github — esi-bench.github.io/
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google