I think the claim of a perfect score demands rigorous third-party verification before enterprises trust it for high-stakes reasoning. My sense is splitting the model into Instruct and Thinking variants clarifies use cases but complicates procurement compliance checks. What concerns me is that enterprises must verify which version is deployed in production to ensure accurate benchmark alignment.
Qwen3-Max Delivers Perfect Math Scores; Seven-Model Family Update Raises Governance Questions
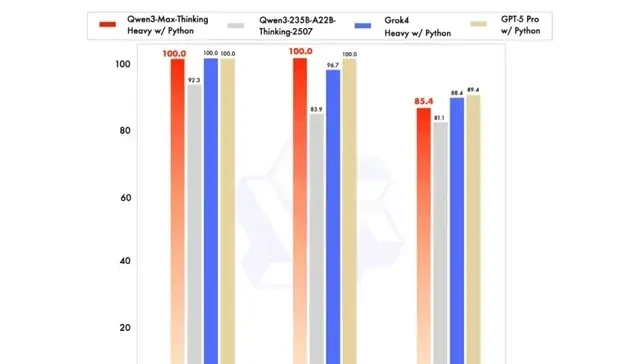
The release of Qwen3-Max marks a significant shift in the competitive landscape, bringing with it immediate questions about verification standards and model accountability. For the first time, a domestic large language model has reportedly achieved a 100% score on both the AIME25 and HMMT mathematics evaluation benchmarks. This achievement places Qwen3-Max at the forefront of mathematical reasoning capabilities among homegrown models.
The architecture remains consistent with the previously released Qwen3-Max-Preview, maintaining a parameter count in the trillions. However, this official launch introduces a critical structural distinction: the model is now split into two distinct versions.
- Instruct Version
- Thinking Version
This bifurcation is not merely cosmetic; it dictates how enterprises should evaluate performance for specific workloads. The “perfect mathematics score” cited in the announcement was achieved exclusively by the Thinking Version. This distinction is vital for governance teams assessing whether a model’s reasoning depth matches its intended application, particularly in regulated sectors where audit trails of thought processes are required.
Meanwhile, the Instruct Version demonstrated strong practical utility, scoring 69.6 on the SWE-Bench evaluation. This metric tests large models’ ability to solve real-world problems via coding, placing Qwen3-Max in the global top tier for software engineering tasks. Furthermore, it scored 74.8 on the Tau2 Bench test, which evaluates Agent tool-calling capabilities. Notably, this performance surpassed that of Claude Opus 4 and DeepSeek V3.1, signaling a competitive shift in agentic workflows.
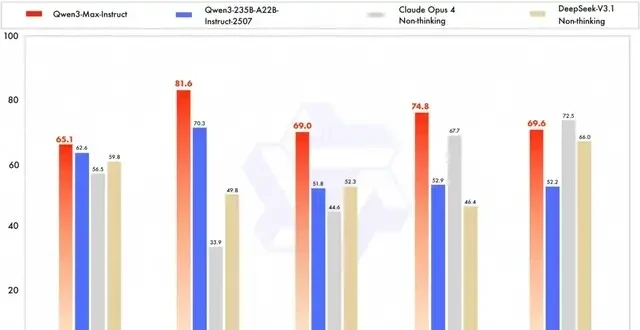
While the technical metrics are impressive, they underscore a broader trend: as models become more powerful and specialized, the burden of proof shifts to the user. Enterprises cannot simply assume that “Qwen3-Max” refers to a single monolithic capability. The distinction between Instruct and Thinking modes requires explicit configuration verification in deployment pipelines.
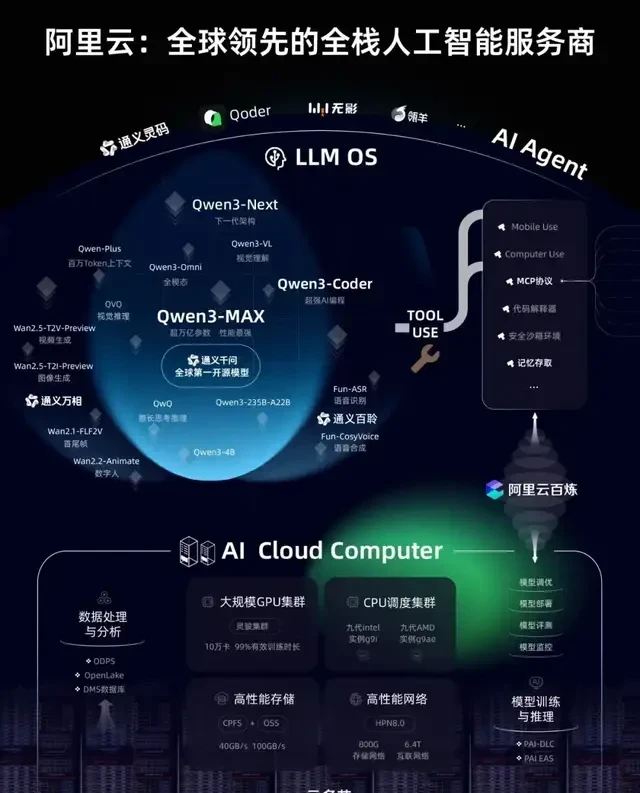
The release did not stop at Qwen3-Max. As I followed the announcements from the recent Apsara Conference, it became clear that if Qwen3-Max is the “fire,” then the Tongyi team also unveiled many other “stars” within its family. This broader update suggests a comprehensive overhaul of their model lineup, requiring governance teams to audit not just the flagship, but the entire ecosystem for consistency and compliance.
Qwen3-VL: The First Star of the Qwen3 Family
The governance burden shifts immediately with this release. As I followed the early morning launch of Qwen3-VL, it became clear that Alibaba is testing the waters of open-source accountability in visual AI. Enterprises must now verify how these models handle liability when their outputs—like generated code or identified objects—are used in regulated environments.
The first “star” emerging from the Qwen3-Max lineage is this visual understanding model, Qwen3-VL. It was open-sourced early this morning, making it fresh off the press, yet it has certainly been one of the most anticipated releases in our sector.
Specifically, this model is named Qwen3-VL-235B-A22B, and it arrives in both Instruct and Reasoning versions. The Instruct version achieves performance that matches or exceeds Gemini 2.5 Pro across multiple mainstream visual perception benchmarks, while the Reasoning version delivers SOTA (State-of-the-Art) results on various multimodal reasoning evaluation baselines.
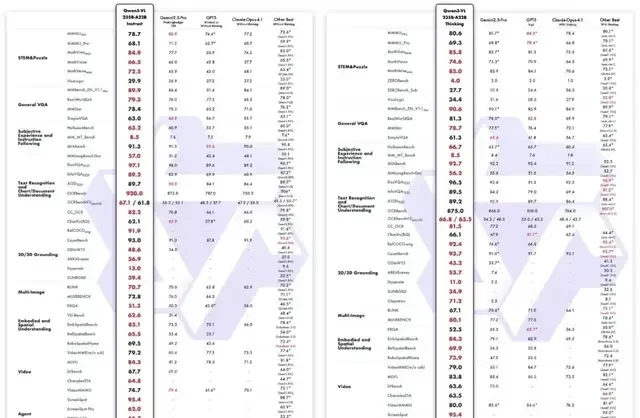
Additionally, the Instruct version of Qwen3-VL-235B-A22B supports visual reasoning (reasoning with images), showing improved scores across four benchmark tests.
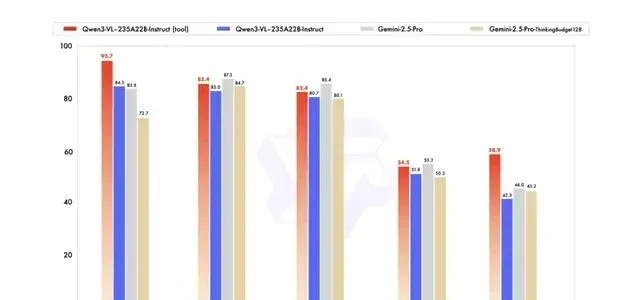
Upon seeing these results, netizens exclaimed:
Qwen3-VL is truly a monster (too powerful).
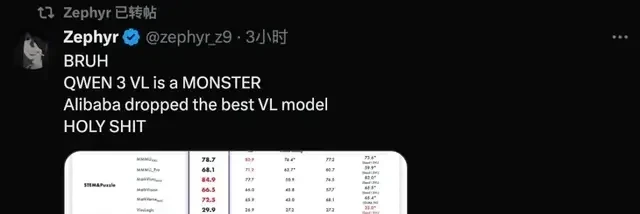
Real-world test results are now available for scrutiny. For example, when fed a hand-drawn webpage sketch, Qwen3-VL quickly generates the corresponding HTML and CSS:
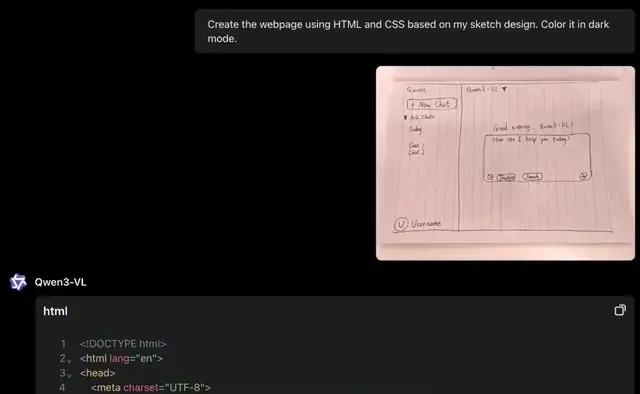
Or consider this image:

With the following task for Qwen3-VL:
Identify all instances belonging to the following categories: “head, hand, male, female, glasses.” Report bounding box coordinates in JSON format.
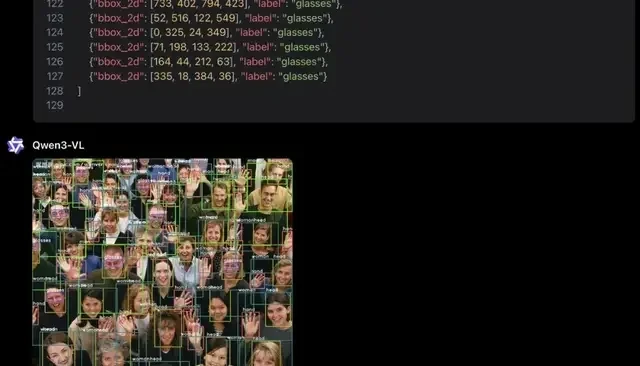
Qwen3-VL also handles more complex video understanding tasks with ease:

You can learn more through the video below:
Video link: https://mp.weixin.qq.com/s/nkNXwpDxxvFVleQ3yB-g5w
I think open-sourcing SOTA vision models accelerates competitive pressure but complicates audit trails for enterprises. My sense is the “monster” label suggests capabilities that may outpace current internal governance frameworks. What concerns me is that enterprises should verify the JSON output stability before integrating this into automated compliance workflows.
From a technical perspective, Qwen3-VL retains its native dynamic resolution design but features updated structural components.
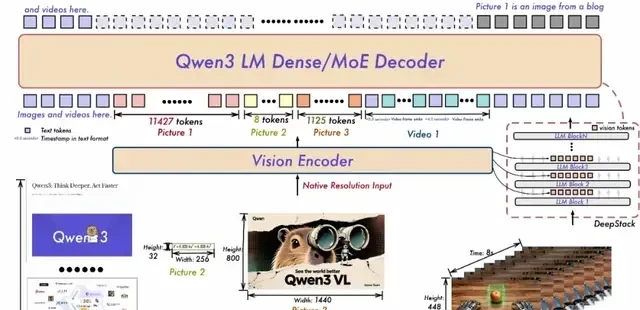
First, it adopts MRoPE-Interleave. The original MRoPE divided dimensions in the order of time (t), height (h), and width (w), concentrating temporal information in high-frequency dimensions. Qwen3-VL interleaves t, h, and w to achieve full-frequency coverage, enhancing long-video understanding while maintaining image comprehension capabilities.
Second, it introduces DeepStack, which fuses multi-layer features from ViT to enhance visual detail capture and text-image alignment. The team expanded single-layer injection of visual tokens into the LLM to multi-layer injection, optimizing feature tokenization by tokenizing outputs from different ViT layers separately before inputting them into the model. This preserves multi-level visual information from low to high levels. Experiments show this design significantly improves performance across various visual understanding tasks.
Third, video temporal modeling has been upgraded from T-RoPE to a text-timestamp alignment mechanism. By interleaving “timestamps” with “video frames,” it achieves fine-grained alignment between frame-level time and visual content, natively supporting both “seconds” and “HMS” output formats. This improves the model’s semantic perception and temporal accuracy in complex sequential tasks such as event localization, action boundary detection, and cross-modal temporal question answering.
Full-Modal: Open-Source Release of Qwen3-Omni
Although Qwen3-Omni was open-sourced early yesterday morning, it also made its debut at the Apsara Conference, highlighting its full-modal capabilities.
It is the first native end-to-end full-modal AI model, unifying text, images, audio, and video within a single architecture, achieving SOTA levels across 22 audio-video benchmarks.
The currently open-sourced versions include:
- Qwen3-Omni-30B-A3B-Instruct
- Qwen3-Omni-30B-A3B-Thinking
- Qwen3-Omni-30B-A3B-Captioner
Furthermore, several specialized large models derived from Qwen3-Omni have been developed.
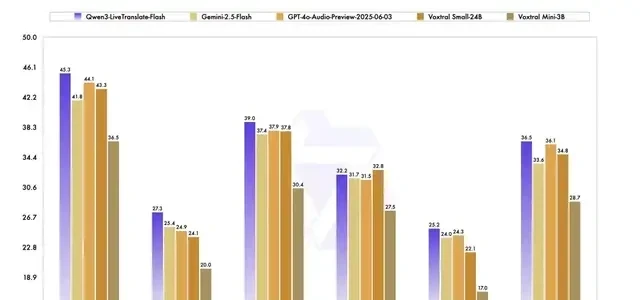
For instance, the newly released Qwen3-LiveTranslate is one such model—a visual, auditory, and vocal full-modal simultaneous interpretation system.
It currently supports offline and real-time audio-video translation across 18 languages.
Public test results show that Qwen3-LiveTranslate-Flash has surpassed models like Gemini-2.5-Flash and GPT-4o-Audio-Preview in accuracy:
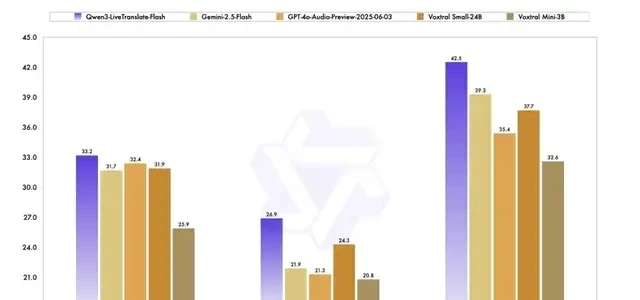
Even in noisy environments, Qwen3-LiveTranslate-Flash maintains robust performance:
To experience the specific effects, see the practical demonstration below:
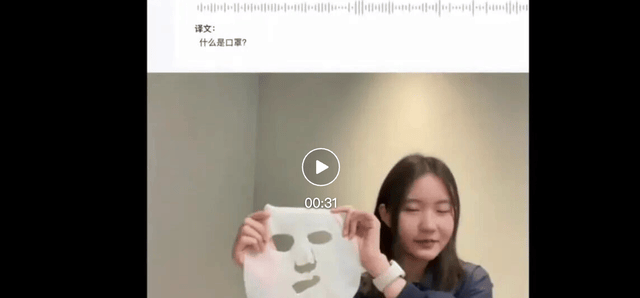
Video link: https://mp.weixin.qq.com/s/nkNXwpDxxvFVleQ3yB-g5w
Original English: What is mask? This is mask. This is mask. This is mask. This is Musk.
Before Visual Enhancement: What is a face mask? This is a face mask, this is a face mask, this is a face mask, this is a face mask.
After Visual Enhancement: What is a mask? This is a facial mask, this is a face mask, this is a theatrical mask, this is Musk.
Netizens were visibly stunned:
It’s getting a bit creepy now.

Beyond translation, the new version of Qwen3-Image-Edit—nicknamed “Qwen Banana”—is also a fascinating model.
It supports multi-image fusion, offering various combinations such as “person + person,” “person + product,” and “person + scene.” It has also enhanced single-image consistency for people, products, and text.
Moreover, it natively supports ControlNet, allowing users to change character poses via keypoint maps and easily fulfill outfit-changing requirements.

I think enterprises must verify if these open weights comply with local data residency laws. My sense is the “creepy” accuracy gains raise immediate consent issues for biometric processing. What concerns me is that governance teams should audit the training data for the 18 supported languages.
Coding: Upgrade of Qwen3-Coder
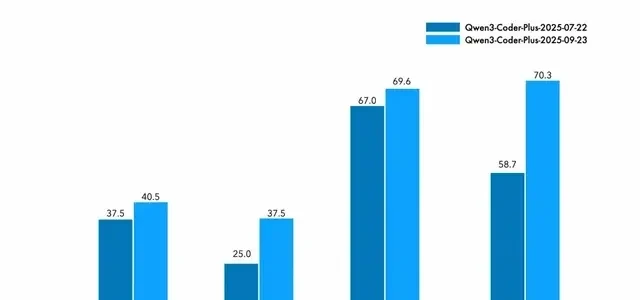
The newly upgraded Qwen3-Coder-Plus employs a “combo” strategy, jointly training with Qwen Code and the Claude Code system.
This approach has significantly boosted its performance; compared to previous versions, scores have increased across all benchmark tests:
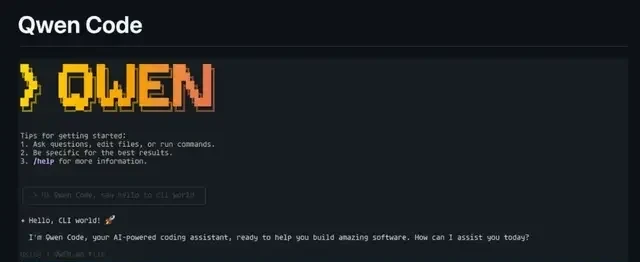
At the same time, its associated coding product, Qwen Code, has also been upgraded to support multimodal models and sub-agents.
In other words, you can now input images when using Qwen Code:
Netizens have already begun real-world testing. The 3D pagoda generated by Qwen3-Coder-Plus looks like this:

I think joint training with Claude Code requires strict IP clearance before enterprise adoption. I followed the release notes; the multimodal input feature needs clear liability boundaries.
AIME’25 Perfect Score! Qwen’s Seven-Model Release Sparks Major Family Update
The Strategic Pivot: From Open Source to ASI Dominance
The burden of proof has shifted from mere benchmarking to strategic capability claims. Alibaba Cloud is no longer just competing on open-source speed; it is defining the architectural future of enterprise AI through aggressive consolidation and efficiency metrics.
To summarize, the highlights from this Apsara Conference…
First, from the day before yesterday until now, Alibaba’s Tongyi Qianwen has successively released and open-sourced nearly ten models of varying sizes, leaving industry insiders both domestic and international in awe of Alibaba Cloud’s open-source speed.
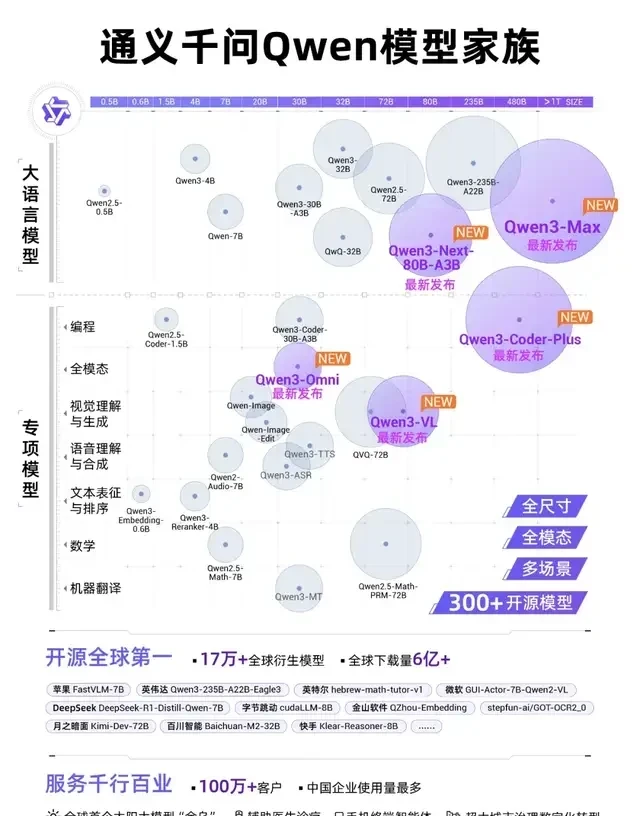
That said, after listening to the speech by Wu Yongming, Chairman and CEO of Alibaba Cloud Intelligence Group, we realized that Tongyi Qianwen’s ambitions extend far beyond this.
Wu stated that achieving Artificial General Intelligence (AGI) is already a certainty, but this is merely the starting point; the ultimate goal is to develop Artificial Superintelligence (ASI) capable of self-iteration and comprehensive superiority over humans.
To achieve ASI, Wu outlined a path beginning with the internet, progressing through four stages:
The first stage is the emergence of intelligence (learning from humans), followed by autonomous action (assisting humans), then self-iteration (surpassing humans), and finally, Artificial Superintelligence (ASI).

Furthermore, Wu offered a forward-looking perspective:
Large models will become the next-generation operating system, natural language will be the source code of the future, and AI Cloud will be the next-generation computer.
In the future, there may only be 5–6 super cloud computing platforms worldwide.
However, one point must be clear: The stronger the AI, the stronger humanity becomes.
My sense is enterprises should verify if these ASI timelines impact current procurement contracts or SLA expectations. What concerns me is that the consolidation into 5–6 platforms suggests a high risk of vendor lock-in for global firms. I followed the release notes; the shift to self-iteration requires rigorous governance frameworks we do not yet have.
Efficiency Metrics: Qwen3-Next Architecture Analysis
Oh, by the way, Tongyi Qianwen’s new generation of foundational model architecture—Qwen3-Next—was officially released today!
Its total parameter count is approximately 80B. However, with only 3B parameters activated, its performance rivals that of Qwen3-235B.
In terms of computational efficiency, it is simply on another level.
Compared to the dense model Qwen3-32B, its training costs have been reduced by over 90%, while long-text inference throughput has increased more than tenfold.
It must be said that the future of large model training and inference efficiency is about to become much more interesting.
I think verify the “3B activated” claim with independent benchmarks before assuming cost savings are realizable at scale.
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google