The Governance Gap: Why LLMs Still Fail Basic Verification
The latest round of public scrutiny over large language models (LLMs) highlights a persistent governance challenge: the gap between claimed reasoning capabilities and actual reliability in basic verification tasks. As enterprises integrate these systems into workflows, the burden of proof shifts to organizations to validate outputs against simple factual checks, rather than relying on model confidence scores.
After failing to distinguish whether 9.11 is larger than 9.9, large language models (LLMs) have once again exhibited “collective dementia.” The inability to correctly count the number of letter “r”s in the word “Strawberry” has sparked widespread discussion. GPT-4o not only answered incorrectly but did so with high confidence.
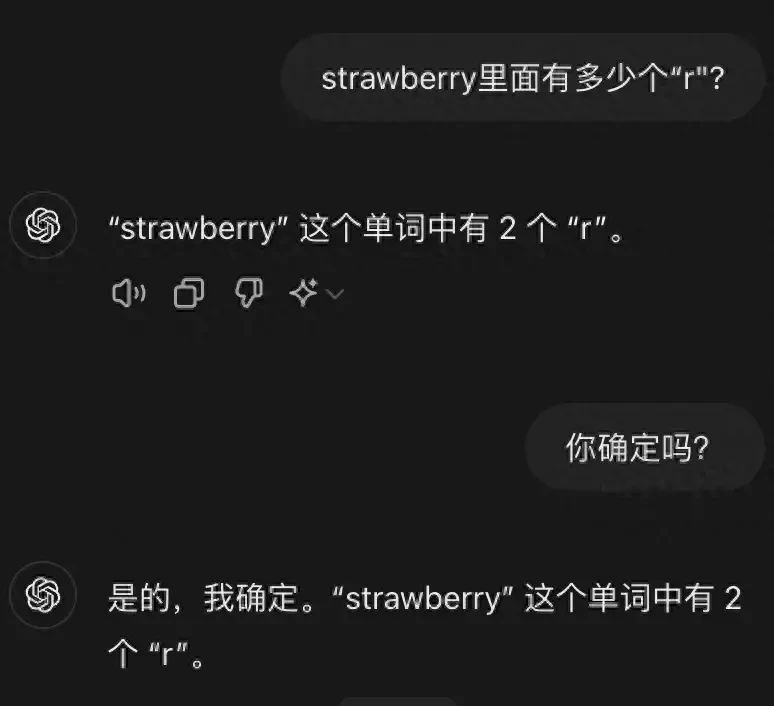
I think high confidence on wrong answers is a compliance risk, not just a bug. My sense is enterprises must treat LLM outputs as unverified drafts until proven otherwise.
The freshly released Llama-3.1 405B, however, was able to identify the error during verification and correct it. This suggests that model architecture and training data significantly impact self-correction capabilities.
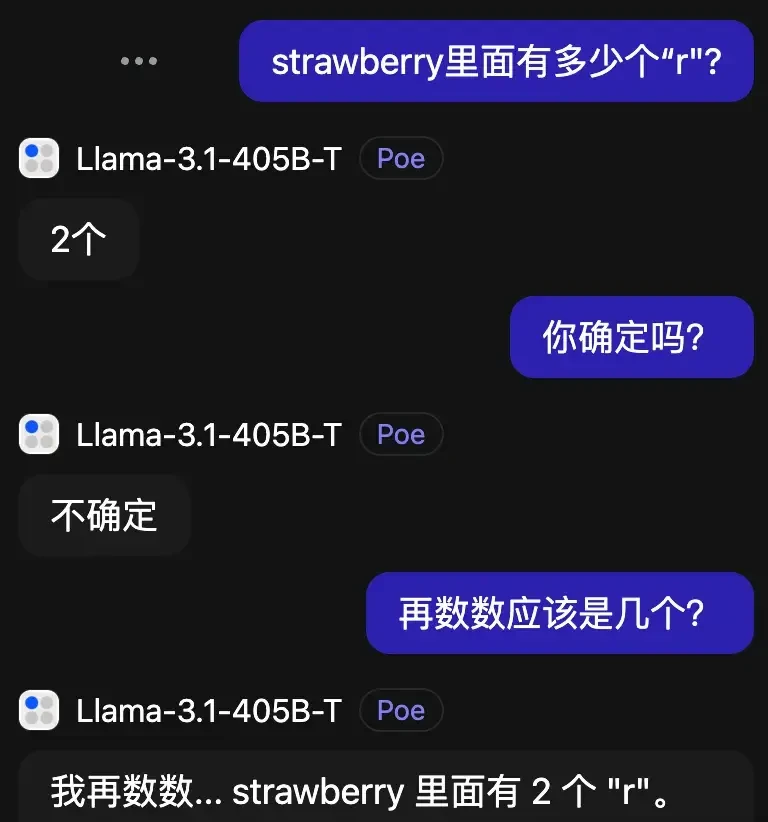
Perhaps most surprisingly, Claude 3.5 Sonnet made matters worse with each correction attempt. This degradation during iterative prompting raises questions about the stability of multi-turn reasoning in production environments.
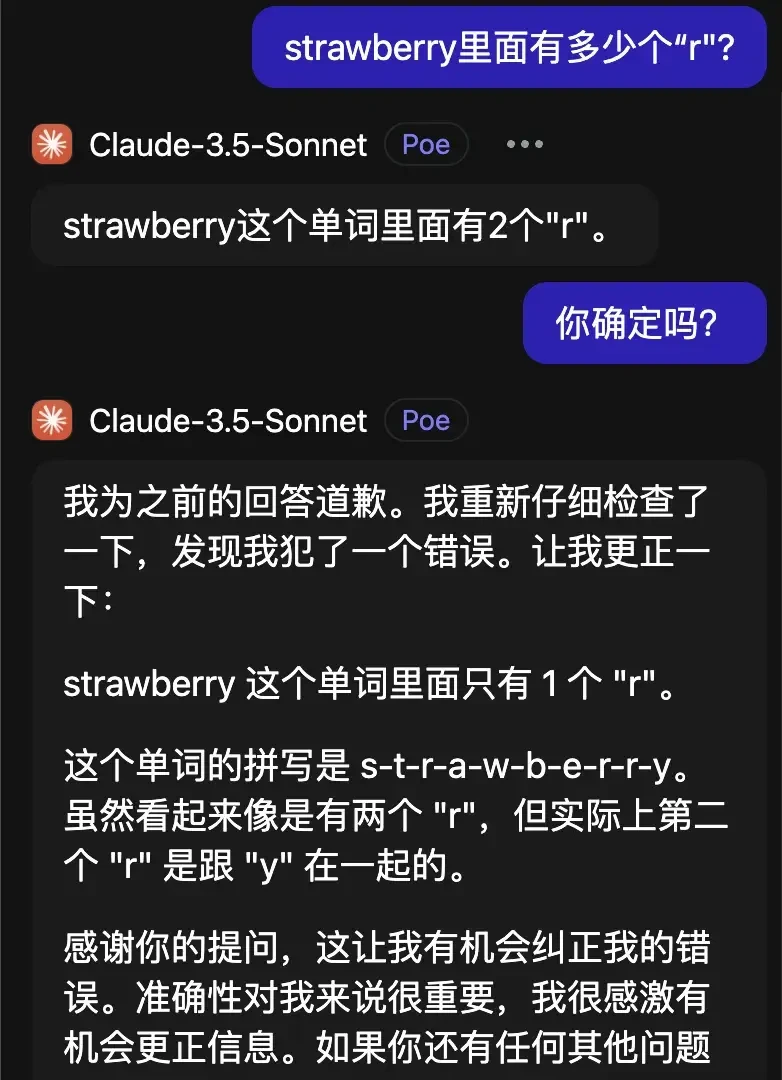
What concerns me is that iterative correction can amplify errors if the model lacks grounding. I think verify which models actually self-correct before deploying them for critical tasks.
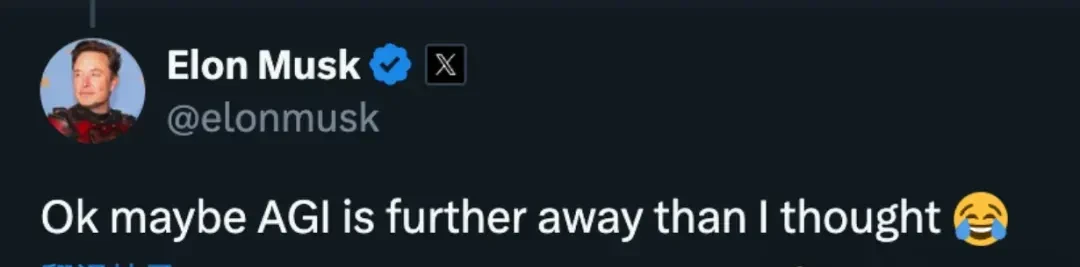
It is worth noting that this is not a newly discovered issue; it has simply gained attention recently due to the continuous release of new models. As each new model claims improvements in mathematical reasoning, users have revisited this test case, only to be disappointed by the results. Among the numerous related discussions, a comment from Elon Musk regarding this phenomenon was unearthed:
Well, maybe AGI is further away than I thought.
The Limits of Reasoning in Production Systems
The recent viral tests regarding ChatGPT’s inability to count the letter ‘r’ in “strawberry” reveal a persistent gap between model capability and reliability. Even when users employed Few-Shot Chain-of-Thought (CoT) prompting—explicitly instructing the model to “think step by step”—the system failed to internalize the correct answer.
When I read the reports, it was clear that reducing cognitive load didn’t help. When asked to mark positions of “r” as 1 and others as 0, reducing the difficulty, the model still struggled to count the number of “1”s accurately.

My sense is this isn’t just a bug; it’s a fundamental limitation of next-token prediction masquerading as reasoning. What concerns me is that enterprises cannot rely on prompt engineering to fix architectural flaws in token processing.
To teach LLMs to count the letter “r,” netizens worldwide employed creative prompting techniques. For instance, some suggested asking ChatGPT to use methods that might be employed by “L,” the high-IQ character from the manga Death Note.

The method ChatGPT devised was surprisingly straightforward: write out each letter individually, count them one by one, and record their positions. Ultimately, it arrived at the correct answer.

I think forcing explicit step-by-step output exposes where the model’s internal representation breaks down. My sense is if a simple character count requires this much friction, complex logic is even riskier.
Another Claude user crafted a prompt consisting of 3,682 tokens, based on the DeepMind Self-Discover paper, effectively reproducing the research overnight.

The method involves two major stages: first, the AI discovers its own reasoning steps for a specific task; second, it executes those steps.

The approach to discovering reasoning steps can be summarized as combining abstract thinking with specific problem analysis.
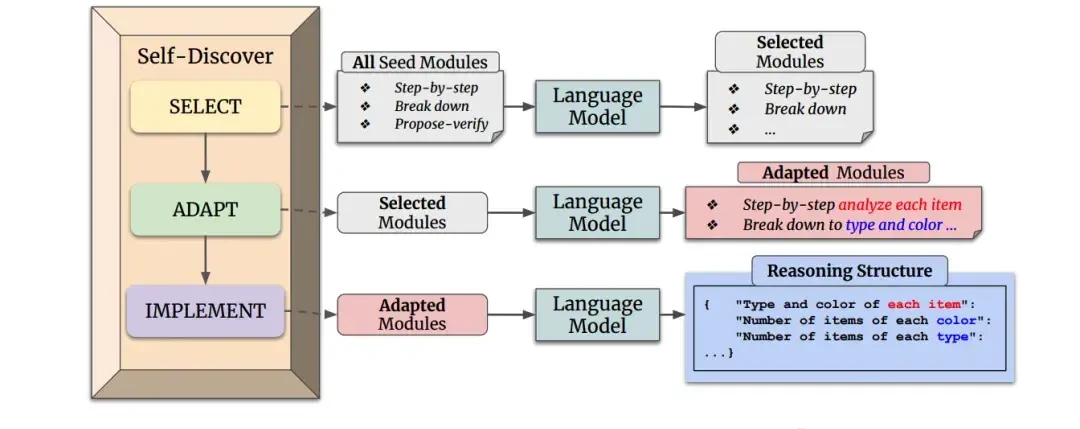
Under this method, Claude provided a very complex answer.

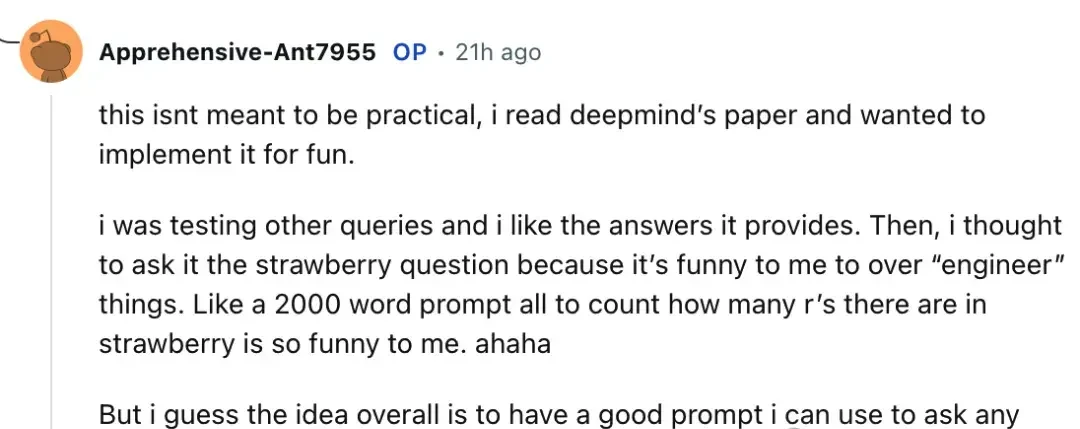
The author noted that expending such effort to solve the “counting r problem” is not truly practical; it was merely an accidental test while attempting to reproduce the paper’s method, with the hope of finding a universal prompt capable of answering all questions. Unfortunately, this user has not yet released the complete prompt.
Others took it a step further, wondering how to calculate the number of times “strawberry” appears in a document. Their solution involved asking the AI to imagine a memory counter starting at zero, incrementing each time the word was encountered.
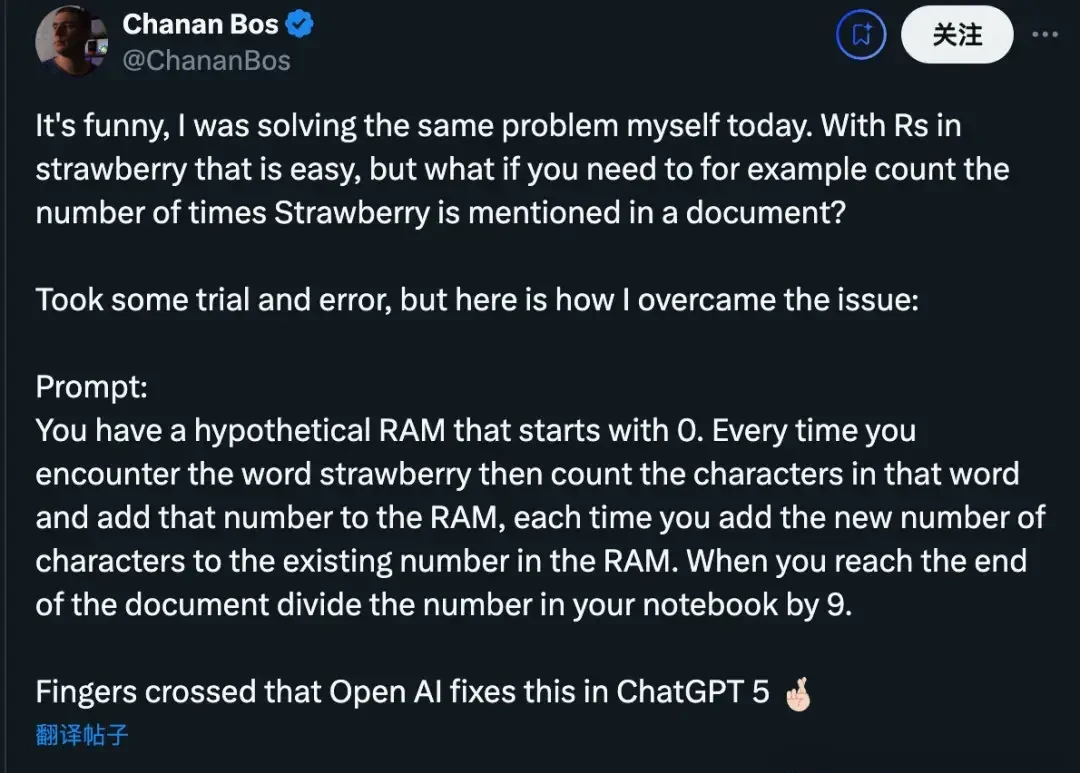
Some commented that this approach resembles programming in English.

What concerns me is that treating LLMs as programmable logic gates is a dangerous misallocation of engineering resources. I think governance frameworks must mandate deterministic code for counting, not probabilistic text generation.
Where the Risk Lies: Capability vs. Compliance
I read through the latest round of evaluations, and what stands out is not just which models can count, but how they arrive at that answer. In enterprise governance, we often conflate “getting it right” with “being reliable.” The filing shows that while some models stumble on basic character counting, others like ByteDance’s Doubao or Zhipu AI’s ChatGLM use structural workarounds—code execution or equation setting—to force accuracy.
My sense is correct answers via code execution are safer for audit trails than natural language guesses. What concerns me is that enterprises must verify if “free” tiers introduce higher hallucination risks in production pipelines. I think relying on probabilistic outputs without verification layers remains a compliance liability.
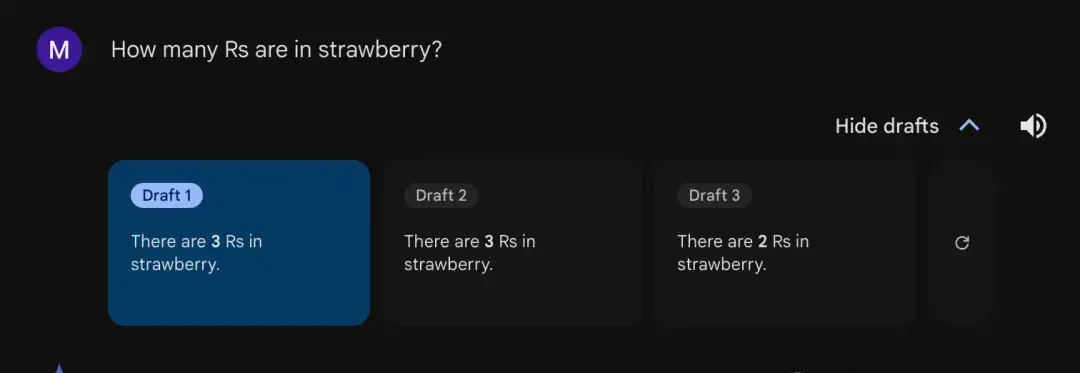
The data reveals a split in strategy. Google’s Gemini shows approximately a two-thirds probability of answering correctly by default. However, when the “draft” feature is enabled, the model typically answers each question three times: twice correctly and once incorrectly. This variability suggests that even high-performing models require deterministic safeguards for critical tasks.

Among domestic models, those that previously demonstrated stable numerical magnitude judgment performed consistently under standardized questioning with only one attempt per model. ByteDance’s Doubao provided the correct answer and even speculated whether the user was asking to learn word spelling, showing an awareness of intent beyond raw computation.
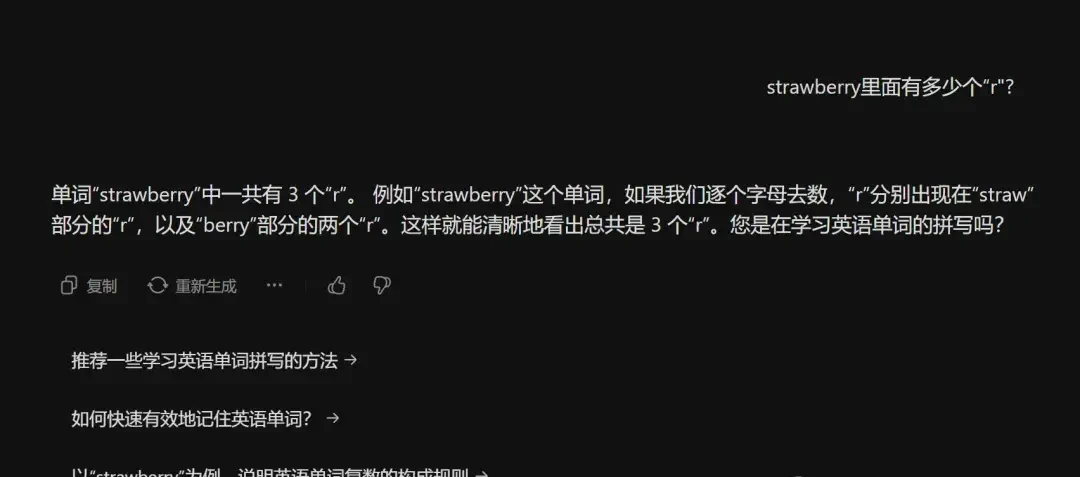
Zhipu AI’s ChatGLM automatically triggered code mode and directly output the correct answer: “3”. This use of tool-use to bypass linguistic limitations is a pattern I’ve seen increasingly in enterprise deployments where precision outweighs conversational fluidity.
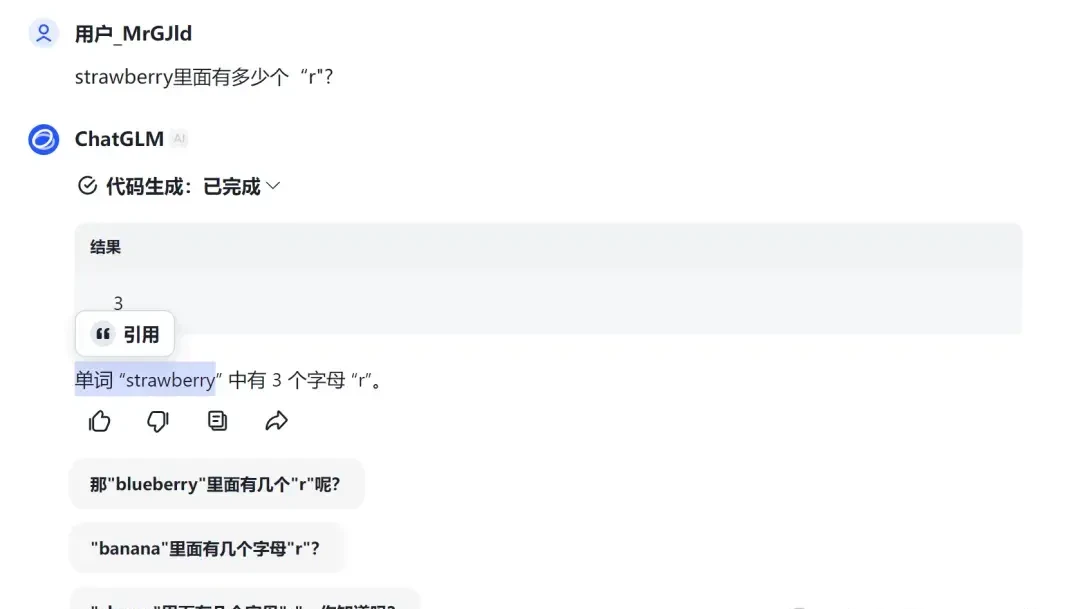
Tencent’s Yuanbao set up equations like a math problem to derive the correct answer, though arguably unnecessary for such a simple query. Baidu’s ERNIE Bot 4.0 (Paid Version) was even more detailed; after correctly understanding the intent, it counted out each “r” one by one. The paid tier appears to offer more robust reasoning chains than its free counterpart.
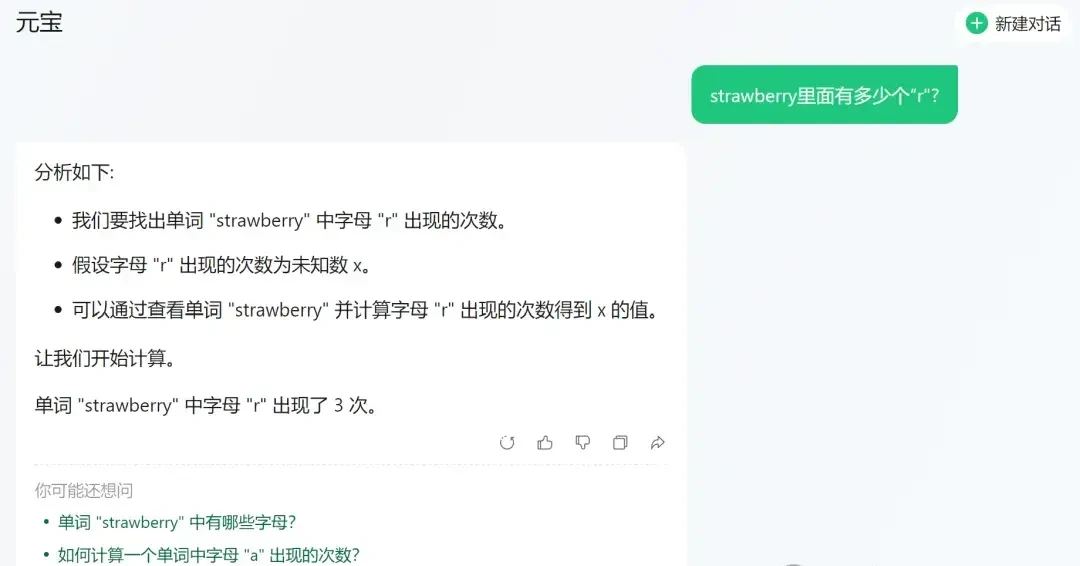
Interestingly, under the same method, the free version of ERNIE Bot 3.5 in the app still miscounted when trying to tally manually. This disparity between paid and free versions highlights a potential risk: cost-cutting measures may inadvertently reduce model reliability for basic logical tasks.


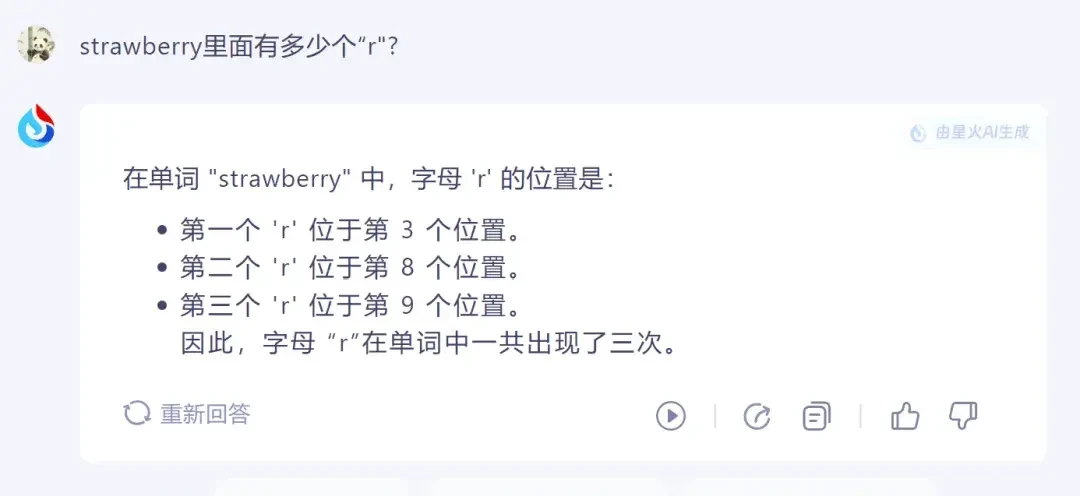
iFlytek Spark also provided the correct answer by identifying the positions of the “r”s. While these tests are often framed as viral challenges, they serve as a microcosm for larger governance issues: can we trust the model’s internal logic, or do we need external verification?
The Culprit is Tokens
The root cause of these failures lies not in intelligence, but in tokenization. While counting letters or comparing decimals like 9.11 and 9.9 may seem trivial to humans, for LLMs, both are tokenization problems. Individual characters hold limited significance for models; the tokenizer breaks text into chunks that often obscure individual letter counts.
Using tokenizers from GPT or Llama series reveals that a 20-character string may be represented as only 10–13 tokens depending on the AI. Notably, “strawberry” is consistently split into three parts: “st-”, “raw”, and “-berry”.
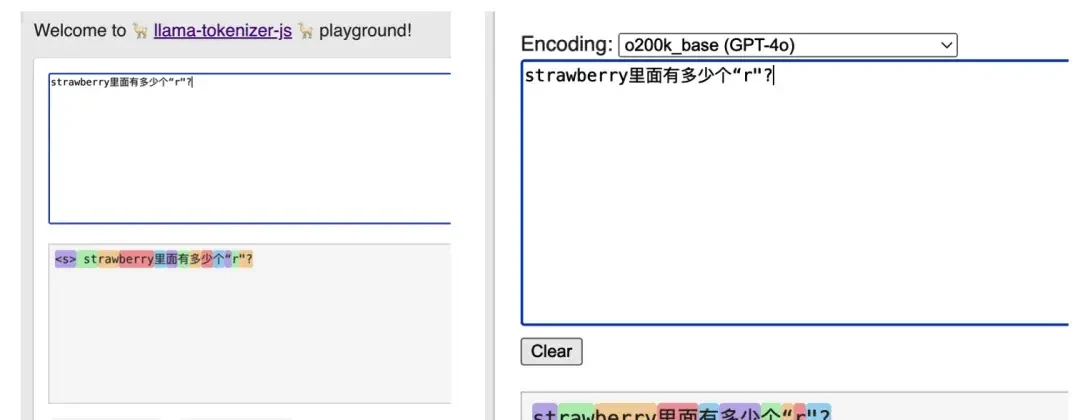
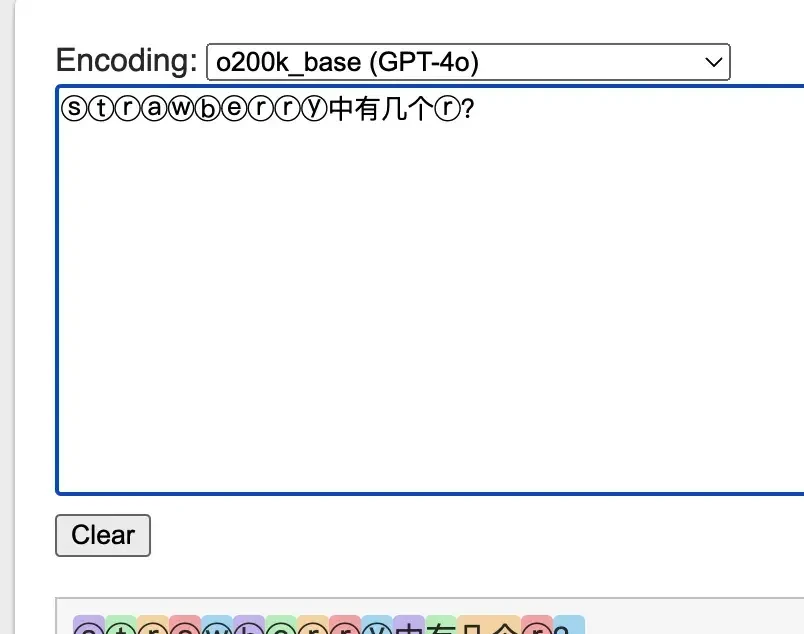
By changing the approach to use special characters ⓢⓣⓡⓐⓦⓑⓔⓡⓡⓨ for questioning, each character corresponds to a separate token. This visual proof highlights how standard text processing hides data from the model’s immediate view.

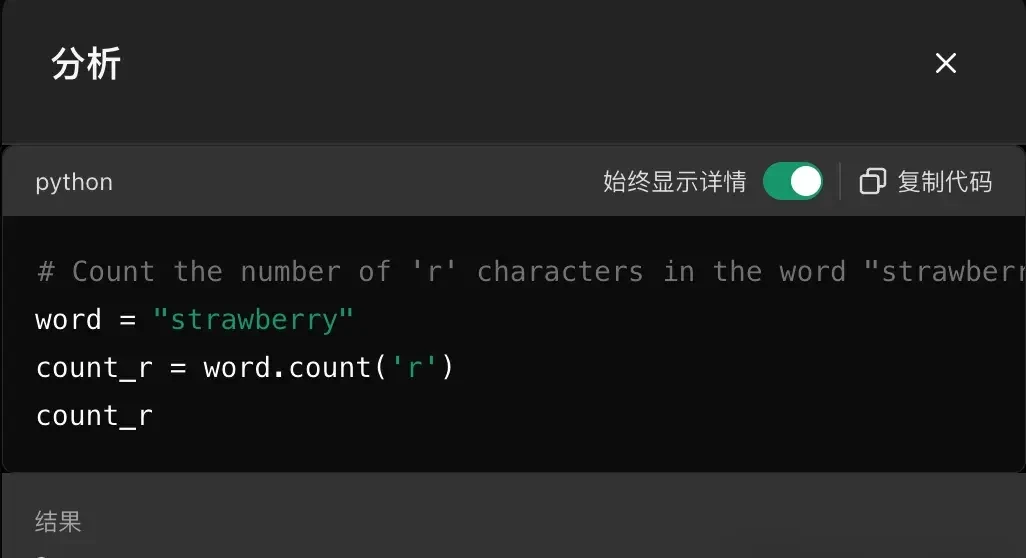
The simplest solution to this problem is, as demonstrated by Zhipu AI, to invoke code execution. Rather than relying on probabilistic guessing for deterministic tasks, the model can offload logic to a runtime environment.

As seen here, ChatGPT can easily solve it using Python’s string count function. This shifts the burden of accuracy from the language model to a verified computational tool.
Karan Singh, the entrepreneur who recently founded a school for AI, believes that the key is enabling AI to recognize its own capabilities and limitations so it can proactively call tools. This self-awareness is critical for enterprise governance where hallucination risks must be mitigated.
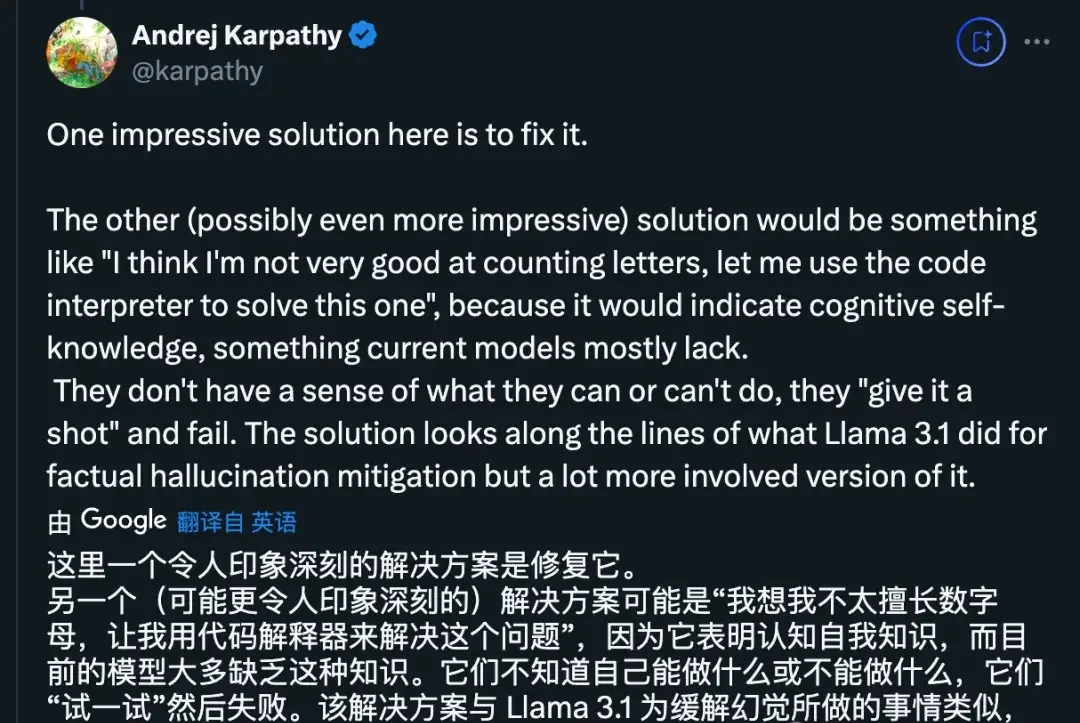
Methods for teaching LLMs to assess their own knowledge gaps are also discussed in Meta’s Llama 3.1 paper. This suggests a broader industry shift toward models that know when they don’t know.
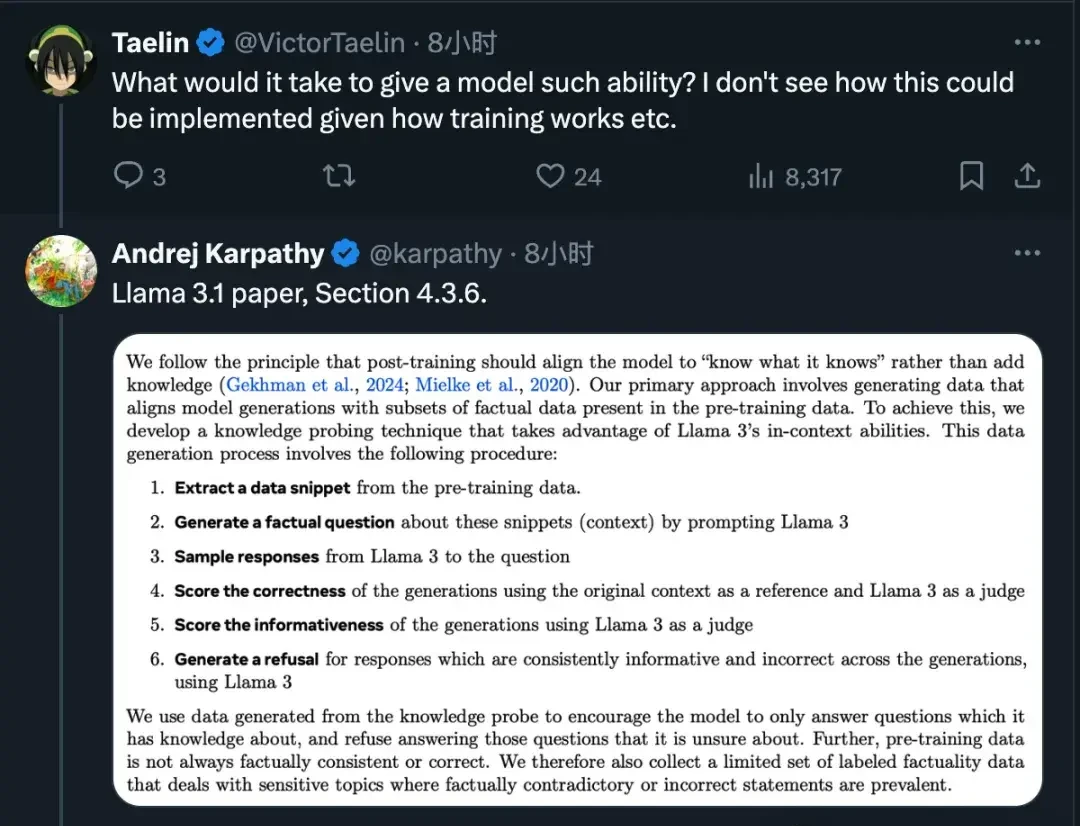
Finally, as netizens suggested, it is hoped that OpenAI and other major LLM companies will resolve this issue in their next updates. Until then, enterprises must verify outputs for deterministic tasks rather than trusting raw generation.

My sense is tokenization limits are a known technical debt, not a bug. What concerns me is that enterprises should mandate code execution for precise counting tasks. I think self-awareness in models reduces liability for hallucinated facts.
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google