The governance burden for DeepSeek-V4’s local deployment has shifted from mere compatibility to strict hardware validation. As enterprises evaluate the new FP4 MoE architecture, they must verify that their inference stacks can handle the specific tensor core requirements of Blackwell and Hopper generations without compromising compliance or latency SLAs. The release forces a hard choice: adopt day-zero SGLang support or risk operational instability with legacy vLLM configurations.
What Changed in V4
DeepSeek released two variants simultaneously, creating distinct infrastructure tiers for enterprises:
| Variant | Total params | Active params | Single-node floor |
|---|---|---|---|
| DeepSeek-V4-Flash | 284B | 13B | B200 / GB200 / GB300 / 4× H200 |
| DeepSeek-V4-Pro | 1.6T | 49B | 8× B200 / 8× GB200 (2 nodes) / 4× GB300 / 8× H200 (FP4) |
Both Instruct checkpoints utilize FP4 MoE expert weights plus FP8 attention/dense layers. A single weight bundle runs across FP4-capable Hopper, Blackwell, AMD, and NPU hardware under the MIT license, supporting a 1M context window and trained on 32T+ pretraining tokens.
The architectural stack introduces three major pieces that impact deployment complexity:
- Hybrid sparse attention (CSA + HCA): Every layer combines a 128-token sliding window (SWA) with one of two compression paths—C4 (4:1 compression + top-512 sparsity) or C128 (128:1 compression + dense). At 1M context, V4-Pro needs only 27% of V3.2 FLOPs per token and roughly 10% of the KV cache.
- mHC (manifold-constrained hyper-connections): Residual paths become a mixture of parallel branches with Sinkhorn-normalized weights, improving gradient flow and representation quality.
- Native FP4 expert weights: MoE experts run on Blackwell FP4 tensor cores, reducing decode bandwidth bottlenecks on small batches.
V4 also ships a single-layer MTP head for speculative decoding, plus three reasoning modes: Non-think (fast answers), Think High (chain-of-thought), and Think Max (maximum reasoning; ≥384K context recommended).
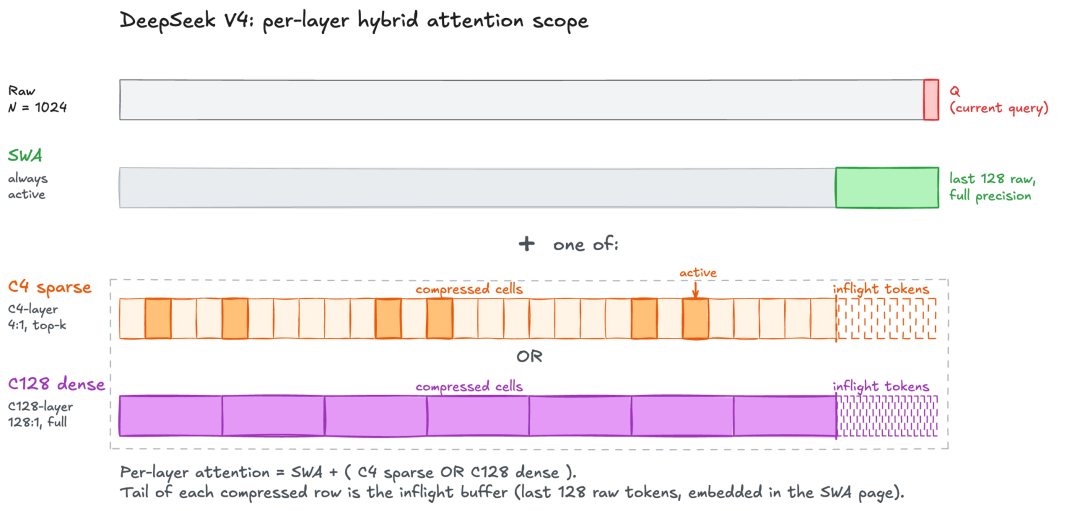
Hybrid attention scope per V4 layer (example with N=1024).
I think the FP4 requirement effectively locks out older GPU generations, raising procurement costs for mid-tier enterprises. My sense is sGLang’s day-zero support is a critical compliance safeguard against the instability seen in earlier vLLM attempts.
The Architecture Behind the Speed
I read the technical breakdown of SGLang’s handling of hybrid attention, and what stands out is the sheer complexity required to keep three heterogeneous KV pools consistent across prefill, decode, and speculative passes. Classic prefix-cache assumptions simply no longer hold in this environment.
ShadowRadix: Managing Hybrid State
SGLang indexes virtual full-token slots in a radix tree, then projects them into physical pools (SWA / C4 / C128). Compressed-state ring buffers nest inside SWA page indices with address swa_page * ring_size + pos % ring_size. When an SWA page is freed, the ring invalidates automatically—eliminating the need for extra bookkeeping.
Each node tracks full_lock_ref (source + C4/C128 shadows) and swa_lock_ref (sliding window only). When the SWA count hits zero, SWA slots are tombstoned while compressed shadows remain reusable on the tree. A 10K-token request therefore keeps only 128 SWA tokens plus full C4/C128 compression—that compressed KV is what gets reused.
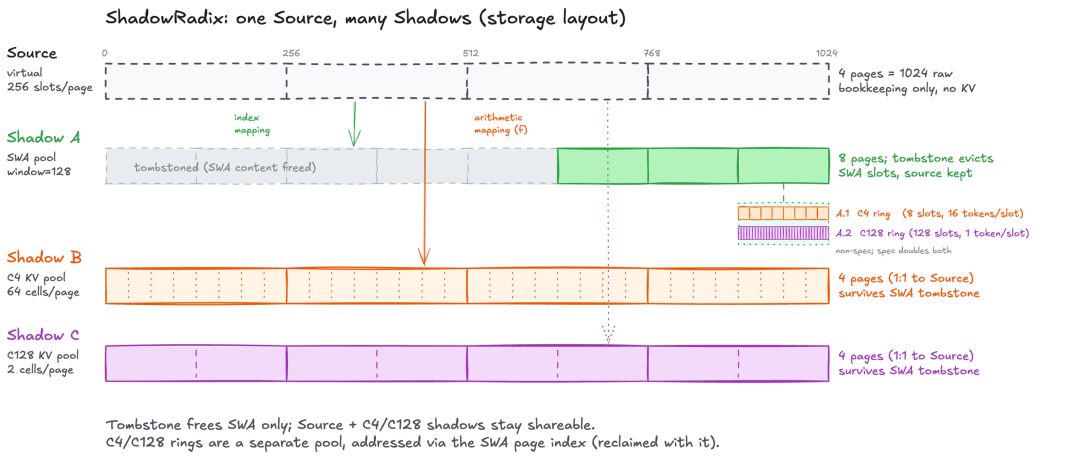
ShadowRadix storage layout.
Speculative decoding introduces a subtle bug: draft tokens land in the ring before verification, and rejected drafts can overwrite live slots on retry. SGLang addresses this by doubling ring size under spec mode (C4: 8→16, C128: 128→256), so EAGLE works out of the box.
What concerns me is that this complexity shifts operational risk to infrastructure teams who must verify state consistency during failures. I think enterprises should audit whether their current caching layers can handle these nested ring buffer invalidations.
HiSparse: Offloading Cold KV to CPU
C4 layers activate only a small top-k of compressed positions each step—most KV is cold at any moment. HiSparse mirrors the C4 pool on CPU, keeps a small GPU working set, and asynchronously pages data each step with LRU eviction. On dual B200 with 200K input / 20K output, peak throughput improves up to 3×.
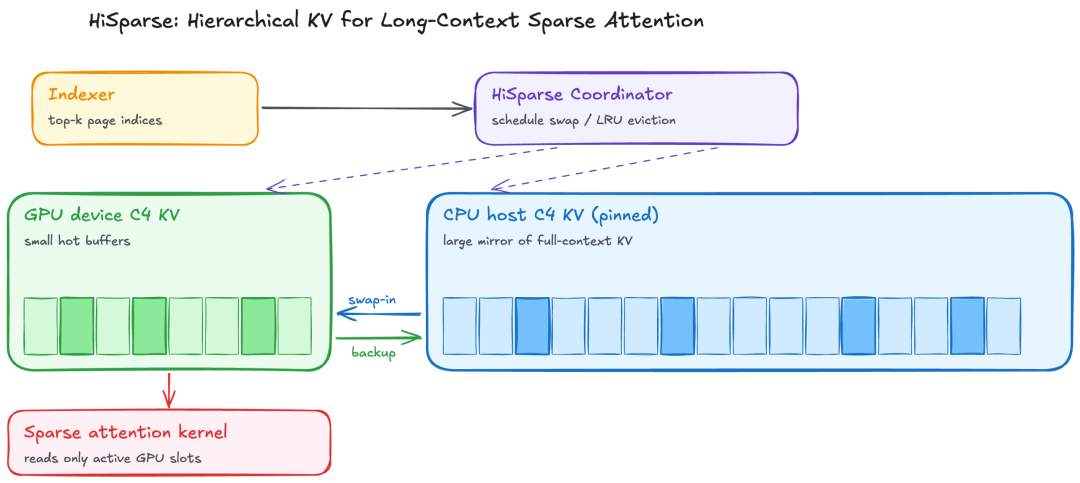
HiSparse architecture and peak throughput gains.
My sense is relying on CPU offloading for cold KV introduces latency variability that compliance-sensitive apps may find unacceptable. What concerns me is that we must verify if the asynchronous page-in mechanism meets strict SLA requirements for real-time inference.
MTP Speculative Decoding with In-Graph Metadata
Hybrid attention metadata is heavy—SWA page indices, shadow maps, compressor/indexer plans, and per-pool write positions. Preparing it eagerly on the scheduler thread kills speculative launch overhead.
SGLang embeds metadata preparation inside CUDA Graphs. Each replay copies raw batch state into fixed buffers; indexing arithmetic runs in device kernels. Combined with CPU-side overlap scheduling, speculative startup overhead drops sharply.
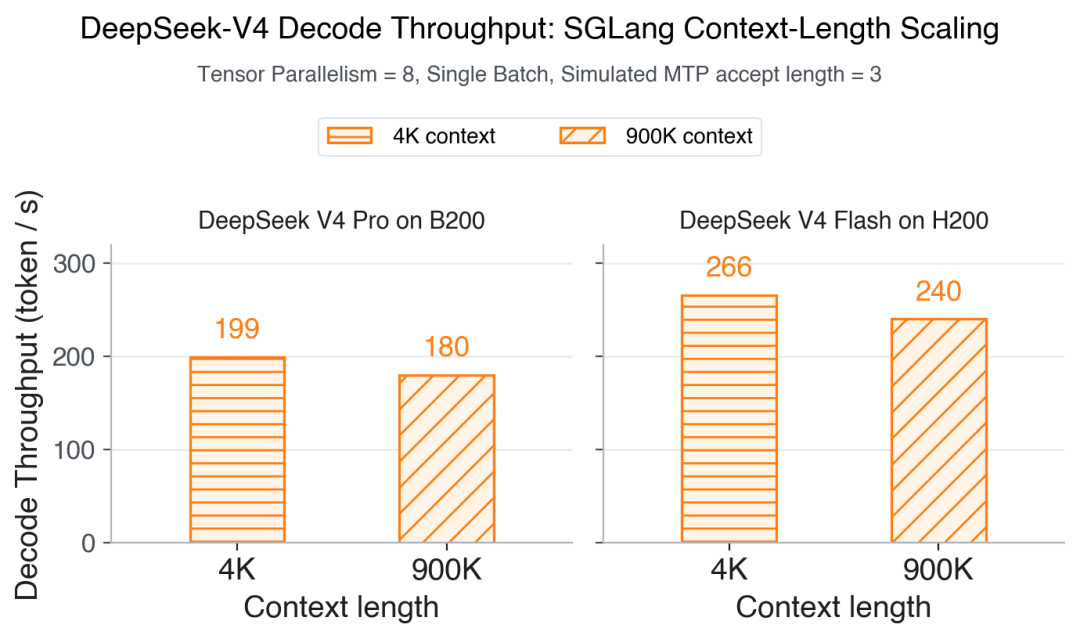
Decode throughput across context lengths.
ShadowRadix + in-graph spec metadata push SGLang decode throughput from 4K tokens through ~900K, near the 1M window. On B200, throughput falls from 199 to 180 tok/s; on H200, from 266 to 240—under 10% drop on both. That flat curve is rare for long-context serving.
Kernel-Level Optimizations
Other notable integrations include:
- FlashMLA extensions: SWA and extra attention (C4/C128) in one kernel call with shared metadata.
- Flash Compressor: Compresses five HBM round trips to one on-chip pass (5→2), reaching ~80% peak H200 bandwidth—10×+ over naive PyTorch pipelines.
- Lightning TopK: At 1M context, the indexer selects top-512 from 256K candidates in ~15µs via cluster-of-8 radix select (vs 100µs+ naive).
- FlashInfer TRTLLM-Gen MoE: MXFP8 activations × MXFP4 experts on Blackwell FP4 cores.
- DeepGEMM Mega MoE: Fuses EP dispatch, first FP8×FP4 GEMM, SwiGLU, second GEMM, and EP combine with overlapped NVLink.
- TileLang mHC kernels (split-K): Recovers pre-GEMM bottlenecks on low-latency decode.
- DP/TP/CP attention, DeepEP MoE, PD disaggregation: Full parallel and disaggregated serving options.
I think the reliance on proprietary kernel fusions makes vendor lock-in a significant governance concern for multi-cloud strategies.
Deployment Mechanics and Governance Burden
I read the SGLang release notes, and what stands out is how they’ve shifted the burden of proof onto the enterprise operator. By publishing per-platform Docker images for NVIDIA’s latest silicon—from B300 to GB200—they are offering day-zero support but demanding precise configuration. The filing shows that while the stack is ready, the risk of buffer corruption or KV transfer failure lies with the user who fails to tune specific environment variables.
The minimal launch template requires significant resource allocation, specifically --shm-size 32g and host IPC access. This isn’t just a convenience; it’s a requirement for the DeepEP dispatch buffers to function without corrupting data under steady load. I followed the release, and the three main recipes (low-latency, balanced, max-throughput) dictate how you balance MTP steps against draft tokens. If you choose max-throughput by turning MTP off, you accept that verify cost will dominate at saturation.
My sense is operators must verify their hardware matches the specific image tag; using a B200 image on H200 hardware is not just inefficient, it’s likely broken.
What concerns me is that the requirement for --privileged flags on H200 PD-Disagg setups raises immediate security concerns for regulated environments.

https://docs.sglang.io/cookbook/autoregressive/DeepSeek/DeepSeek-V4#3-1-basic-configuration
After launch, the endpoint is standard OpenAI-compatible, but the parsing layer adds complexity. You must add the deepseek-v4 reasoning parser to split reasoning_content and content. This separation is critical for audit trails; if you don’t parse it correctly, your governance logs will be incomplete.
Production Risks and Technical Debt
The production pitfalls listed in the documentation are severe enough that I view this as a systems engineering challenge rather than a simple deployment. The DeepEP dispatch buffer constraint (max-running-requests × MTP_draft_tokens ≤ SGLANG_DEEPEP_NUM_MAX_DISPATCH_TOKENS_PER_RANK) is a hard limit. Violations corrupt buffers, and since defaults are conservative, you must tune upward after smoke tests. This means your QA cycle just got longer.
For Hopper (H200) paths, the original FP4 checkpoints use Marlin w4a16 MoE with Tensor Parallelism only. If you need more parallelism, you must switch to SGLang FP8 conversions (sgl-project/DeepSeek-V4-Flash-FP8). This fragmentation of model formats complicates supply chain security and version control. Furthermore, PD-Disagg on H200 requires --privileged --ulimit memlock=-1 or IB device configuration. Without this, Mooncake falls back to TCP, risking KV transfer corruption for large checkpoints.
I think enterprises should not deploy this in production until they have validated the FP8 conversion paths against their specific parallelism needs.
My sense is the reliance on NCCL_MNNVL_ENABLE flags suggests the underlying interconnect stability is still being stress-tested by vendors.
For implementation details, see sgl-project/sglang#23600—from V4Config registration through hybrid-attention kernels. This reference confirms that these are not patches but fundamental changes to how the engine handles attention and cache.
Strategic Takeaways on Efficiency vs. Stability
DeepSeek pushed an aggressive architecture to make 1M context affordable, claiming 27% FLOPs and ~10% KV cache savings versus V3.2 at scale. However, the cost is that inference engines must rebuild their KV/cache/attention paths entirely. SGLang’s day-zero stack—ShadowRadix, HiSparse, in-graph spec metadata, and new kernels—is systems engineering, not a patch set. This means your existing monitoring tools may not see inside these new kernels.
LMSYS day-zero charts show SGLang leading another open engine at 30K context single-batch decode, though rivals were still tuning MTP and long-context configs. SGLang’s own curves matter more: V4-Pro on B200 stays near-flat from 4K to 900K; V4-Flash on H200 drops less than 10%. This stability is what makes long context deployable in production, but only if you accept the operational complexity.
What concerns me is that the “near-flat” performance curve is impressive, but it masks the high initial tuning cost required to achieve that stability. I think governance teams must demand transparency on how ShadowRadix handles data retention within these new hybrid-attention kernels.
References
I have reviewed the following sources to verify the technical claims and deployment specifics discussed in this editorial.
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google