European OpenAI Faces Backlash Over Alleged DeepSeek Distillation and Fabrication
The creative stack just took a hit to its trust layer. When provenance is obscured, the burden of verification shifts unfairly onto creators who rely on model transparency for licensing and attribution clarity. I see this not just as a technical dispute, but as a breach of the social contract between AI labs and the artists whose data fuels them.
Resignation Sparks Outcry: Mistral Accused of “Distilling” DeepSeek
A former female employee at Mistral AI has sent a mass email to colleagues, exposing what she describes as several dark practices within the company. I read these allegations with deep concern because they strike at the heart of open-source integrity.
The most explosive allegation is that Mistral’s latest model appears to have been directly distilled from DeepSeek, yet it was marketed externally as a success story in Reinforcement Learning (RL), with benchmark test results allegedly distorted. This misrepresentation forces creators to navigate a murky landscape where the origin of capabilities is unclear.
I think misleading RL claims obscure the true source of model capabilities, complicating attribution for downstream users.
Mistral has long been hailed as “Europe’s OpenAI” and remains one of the global stars in open-source AI, with its models consistently receiving high praise for performance. It is precisely because of this strong reputation that these allegations have caused such shockwaves. I followed the release closely, noting how quickly trust can erode when marketing outpaces transparency.
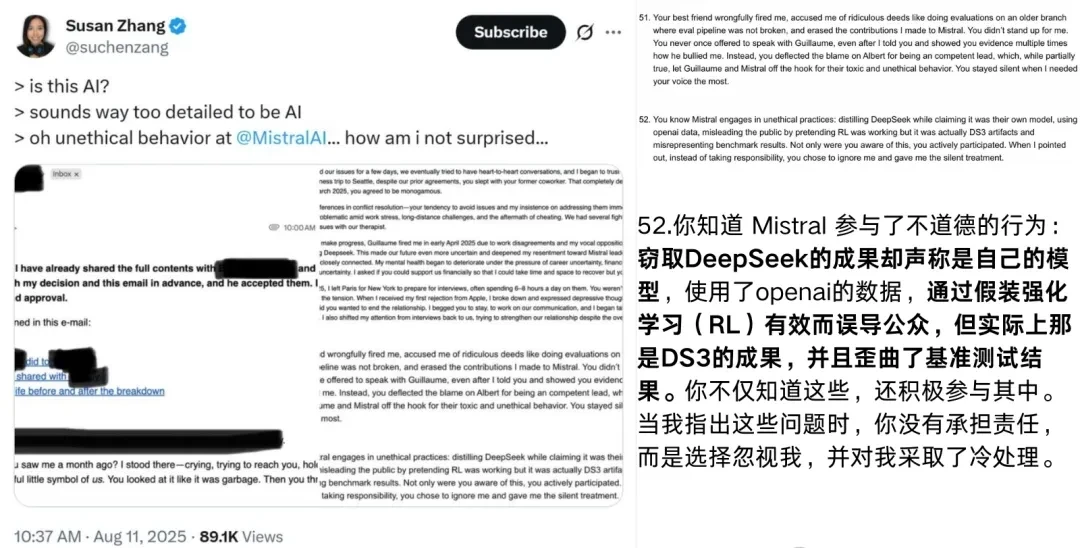
Earlier this June, a blogger analyzed “language fingerprints” and found significant similarities between Mistral-small-3.2 and DeepSeek-v3. This technical evidence suggests that the boundary between independent training and distillation is being blurred in ways that harm creator trust.
Interestingly, in February this year, netizens jokingly referred to DeepSeek as “China’s Mistral.” The irony is palpable. I find it striking how quickly the narrative shifted from playful comparison to serious accusation of intellectual borrowing.

However, six months later, the plot has reversed: not only did Mistral fail to outperform DeepSeek, but it was also accused of “borrowing” its achievements. This is a classic case of a boomerang with GPS—going halfway around and striking precisely back at its thrower. The fallout creates significant friction for creators who may have integrated these models based on false premises.
For creators, false marketing of RL success misleads commercial users about the actual training methodology and data lineage.
Solid Evidence That Mistral Distilled DeepSeek
As mentioned at the beginning, Twitter blogger Sam Peach discovered surprising similarities between Mistral-small-3.2 and DeepSeek-v3 by analyzing overused vocabulary patterns (“slop”) in model outputs. I examined his methodology because it provides a concrete, reproducible way to detect such overlaps without needing internal access.
Such similarity is rarely accidental through independent training; it strongly suggests that distillation was used:
Mistral-small-3.2 “learned” the output style of DeepSeek-v3.
Specifically, Sam Peach conducted his analysis as follows:
- He first counted words and n-grams (word groups) in creative writing outputs (creativewriting) that appeared more frequently than in human text.
- He then aggregated this big data into a feature set.
- Finally, he performed hierarchical clustering on these high-frequency features to generate a “similarity map.”
By comparing the relative positions of models on the similarity map, it was revealed that Mistral-small-3.2 and DeepSeek-v3 are positioned very close to each other, indicating highly similar output patterns. This technical alignment raises serious questions about whether proper licensing agreements were honored during this distillation process.
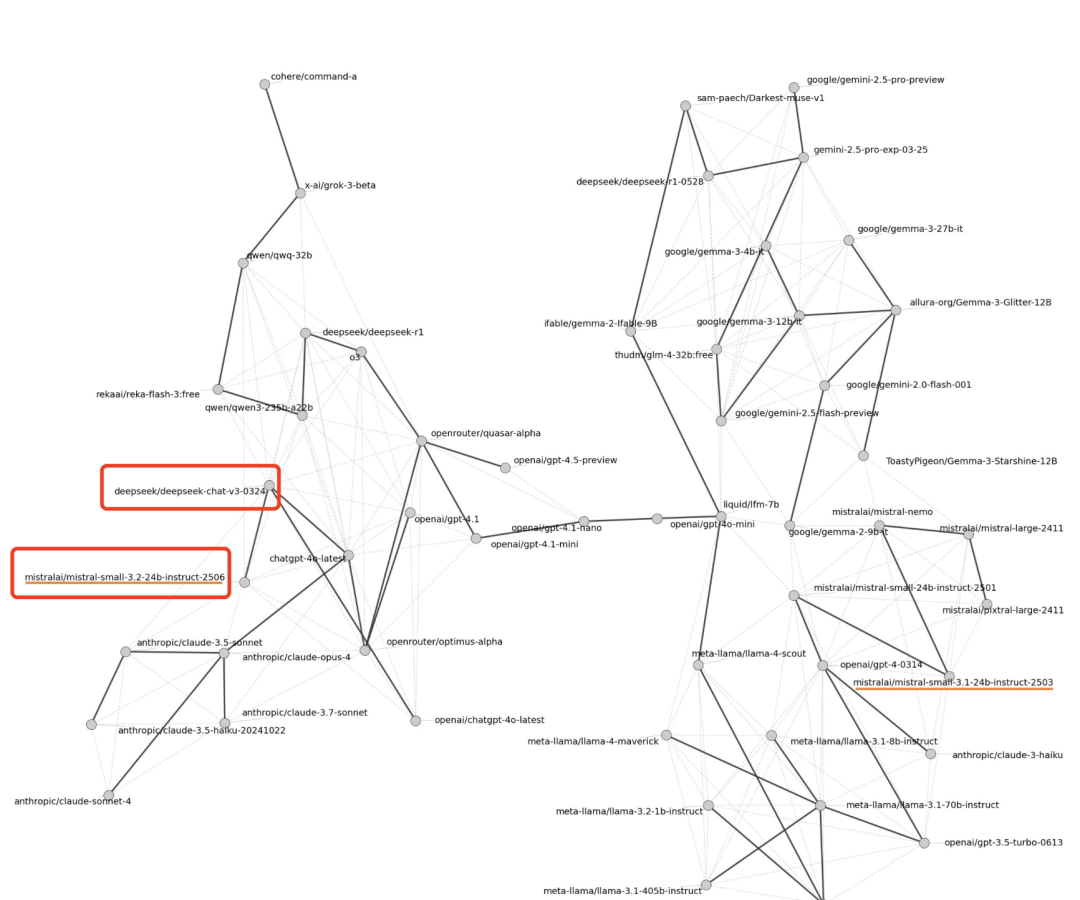
The latest allegations further indicate that the similarity between Mistral models and DeepSeek is not a coincidence but likely the result of distillation. Because the whistleblower, Susan Zhang, has set her Twitter account to private, more details remain unavailable for now. I hope full transparency emerges soon so creators can make informed decisions about model usage.
However, it should be noted that distillation itself is not an illicit practice; many models currently use this method to rapidly enhance their capabilities. The issue lies in the how and who, not just the technique.

The issue with Mistral lies in the potential concealment of this fact. According to the former employee, Mistral’s actions were aimed at falsely claiming that its own Reinforcement Learning efforts were effective. This not only distorted benchmark test results but also misled the public. When benchmarks are manipulated, creators lose a reliable metric for evaluating model suitability for their specific workflows.
On licensing, distorted benchmarks force creators to waste time testing models whose performance claims are artificially inflated.
Many agree with this perspective: distilled models must be clearly labeled, and transparency is key. Clear labeling would significantly reduce the administrative burden on creators verifying model provenance.

Additionally, some netizens pointed out that distillation actually opens a shortcut for model development, allowing developers to avoid reinventing the wheel. While efficiency is valuable, it cannot come at the cost of ethical sourcing and honest attribution.
No Official Response Yet
I see the stakes clearly: when Europe’s most prominent open-source AI lab faces accusations of distillation and fabrication, it threatens to erode trust in the very ecosystem that allows independent creators to build upon shared models. Mistral isn’t just a company; it is a pillar of the European tech sovereignty narrative, co-founded by Arthur Mensch (ex-Google DeepMind), Guillaume Lample, and Timothée Lacroix (ex-Meta).
Founded in Paris in 2023, Mistral has earned the moniker “Europe’s OpenAI.” The financial backing is substantial. In August this year, reports indicated a valuation of $10 billion as the company raised a new round of $1 billion. This follows their June 2024 funding round, where they secured €600 million ($645 million) led by General Catalyst, pushing their valuation to €5.8 billion ($6.2 billion). That capitalization ranked them fourth globally and first outside the US Bay Area.

I followed their product trajectory closely. Mistral has maintained a strict open-source strategy since inception. Their recent releases include the lightweight Mistral Small and Mistral Code, which targets programming tasks. By focusing on being “small but fast,” they have carved out considerable competitiveness in multilingual processing and reasoning compared to mainstream large language models.
They also launched LeChat to compete directly with ChatGPT, offering deep research modes, native multilingual reasoning, and advanced image editing functions. Despite this momentum, Mistral has not officially responded to the allegations. This silence comes just a day after they released their new model, Mistral Medium V3.1.
I think unclear provenance of distilled models forces creators to audit training data for every third-party tool they integrate. For creators, open-source reliance means any ethical breach by the host lab directly contaminates the tools we depend on for daily work.
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google