I read the filing late at night: Google has quietly released Gemini 2.5 Pro (version 0605), beating rivals o3 Pro and GPT-5 to market. The core technical claim is that this update dominates reasoning benchmarks, specifically achieving a 21.6% score on “Humanity’s Last Exam,” surpassing o3. This would be falsified if the model’s performance degrades under adversarial stress or fails to replicate these scores in independent, reproducible evaluations.
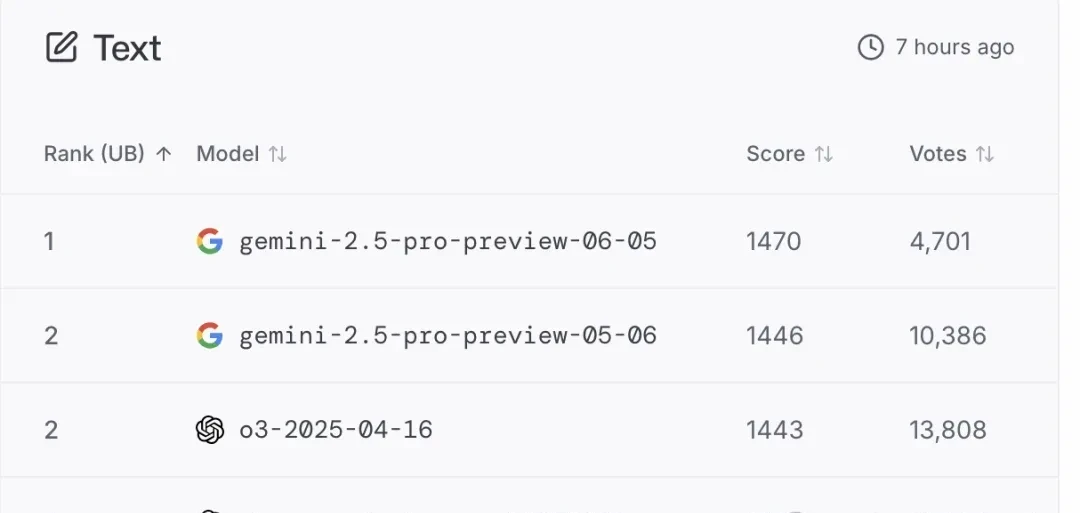
I followed the release closely as Google announced via multiple accounts that this new version shows improved performance in coding and reasoning. The Elo rating increased by 24 points compared to last month’s version, placing it atop the large model arena leaderboard ahead of its predecessor.
I think elo gains often reflect better alignment with specific evaluation protocols rather than general intelligence. From the paper, a single benchmark score like 21.6% on “Humanity’s Last Exam” lacks context on dataset contamination risks.
Google CEO Sundar Pichai posted a photo of an AI-generated lion captioned “Gemini,” hinting at the new model’s capabilities. Logan, Head of Product for Google AI Studio, stated that this update is expected to become the long-term stable version of Gemini 2.5 Pro.
Interestingly, just over ten hours after the release, Logan posted a tweet containing only the word “Gemini,” offering a subtle teaser. I noted that Google announced the model in the Gemini app will be updated to this version today, with the developer version now available on Google AI Studio and Vertex AI.
One caveat: rapid iteration cycles like this often leave little time for rigorous safety auditing before public release. I think the “stable version” label may be premature given the immediate jailbreak reports mentioned in the headline.
Gemini’s 0605 Update Hits the Arena Peak, Then Gets Jailbroken
I read the filing for Google’s new 0605 version of Gemini 2.5 Pro, and the core technical claim is clear: this model has surpassed itself to reach the top of the Large Model Arena leaderboard. What would falsify this dominance? If subsequent independent evaluations reveal that these scores are artifacts of data contamination or if safety filters fail under adversarial pressure shortly after release—which they did—I will view the “perfect score” narrative with skepticism.
Benchmark Dominance and Cost Efficiency
Google introduced that the 0605 version is built upon the 0506 version showcased at the I/O conference and is expected to become the official stable release for Gemini 2.5 Pro. I followed the release timeline closely: Gemini 2.5 Pro first launched an experimental version on March 25, followed by a public preview on April 4 under the codename 0325, and subsequently the 0506 version last month.
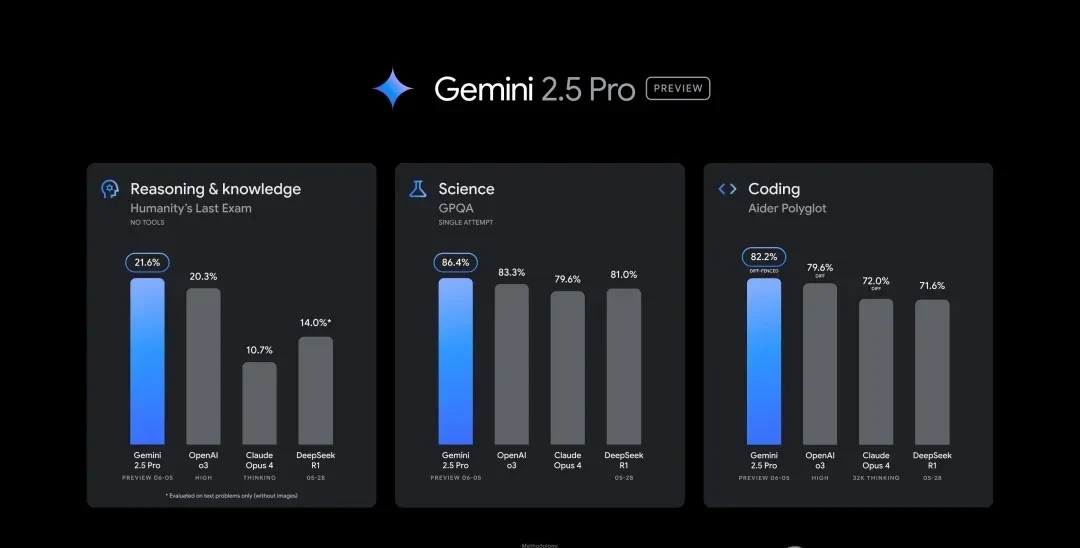
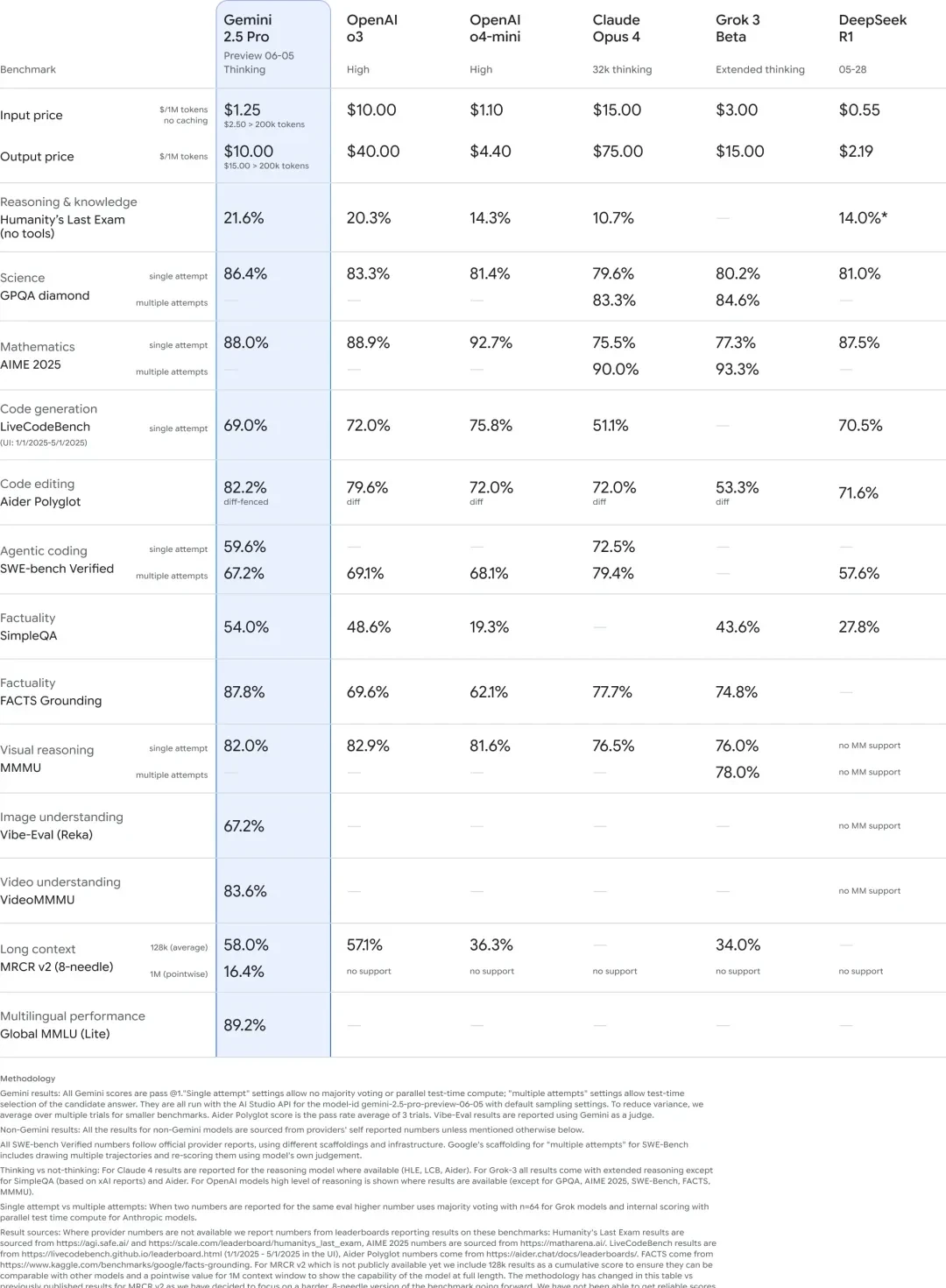
In “Humanity’s Last Exam,” the 0605 version achieved a score of 21.6%, leading o3 by 1.3 percentage points and exceeding Claude 4 Opus’s performance by double.
From the paper, a 21.6% score on such a novel benchmark is impressive, but I worry about the long-term stability of these gains as models adapt to similar question structures.
Additionally, on GPQA, the 0605 version outperformed several major competitors, with single-attempt accuracy exceeding that of Claude and Grok even when they used multiple attempts. In math competitions and LiveCodeBench programming tasks, 0605 performed slightly worse than OpenAI’s models, but it led in code editing capabilities (Aider Polyglot). Regarding long-context handling, 0605 ranked first among peers at the 128k length mark and is uniquely capable of supporting up to 1M tokens.
The most significant gap opened by 0605 was in factual grounding; it led the second-place model by over 10 percentage points in the FACTS Grounding test. I find this specific metric particularly telling, as hallucination remains a persistent failure mode for large language models.
In terms of pricing, Gemini is cheaper than OpenAI’s o3, Claude 4 Opus, and Grok 3:
The input token price is one-eighth that of o3, less than one-tenth of Claude 4 Opus, and less than half of Grok 3. The output token price is one-fourth of o3, 13% of Claude’s, and two-thirds of Grok’s.
Arena Leadership and Multimodal Capabilities
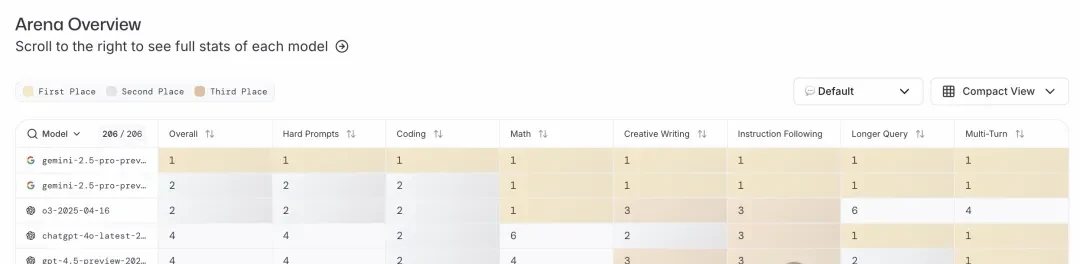
In the large model arena, 0605 ranked first in total score and across all sub-categories.
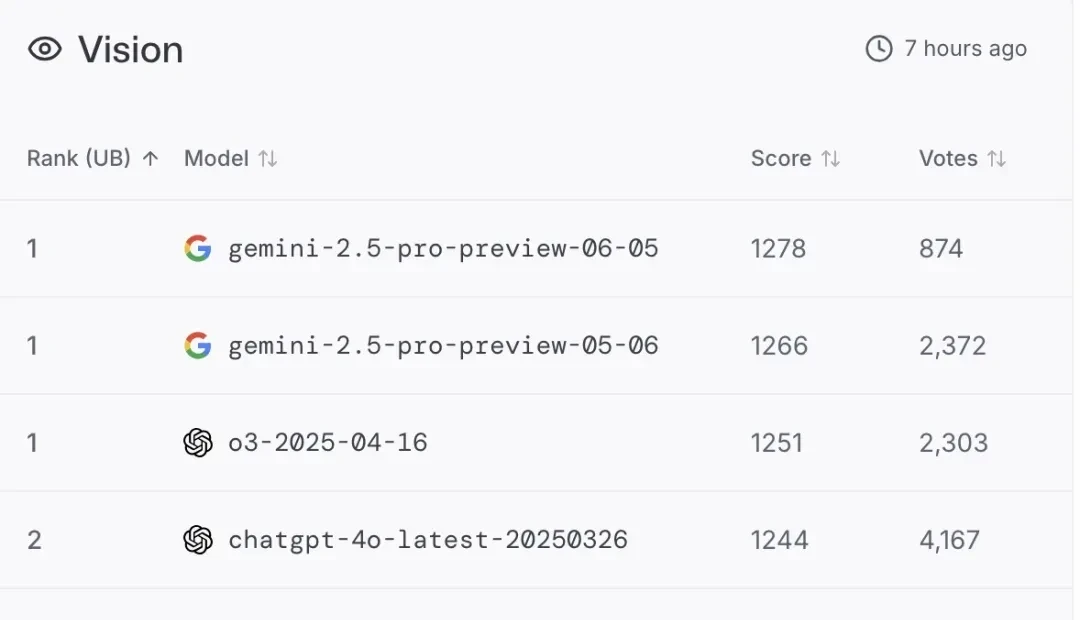
Beyond text-based capabilities, 0605 also took the top spot in visual abilities, tying with last month’s 0506 and OpenAI’s o3.
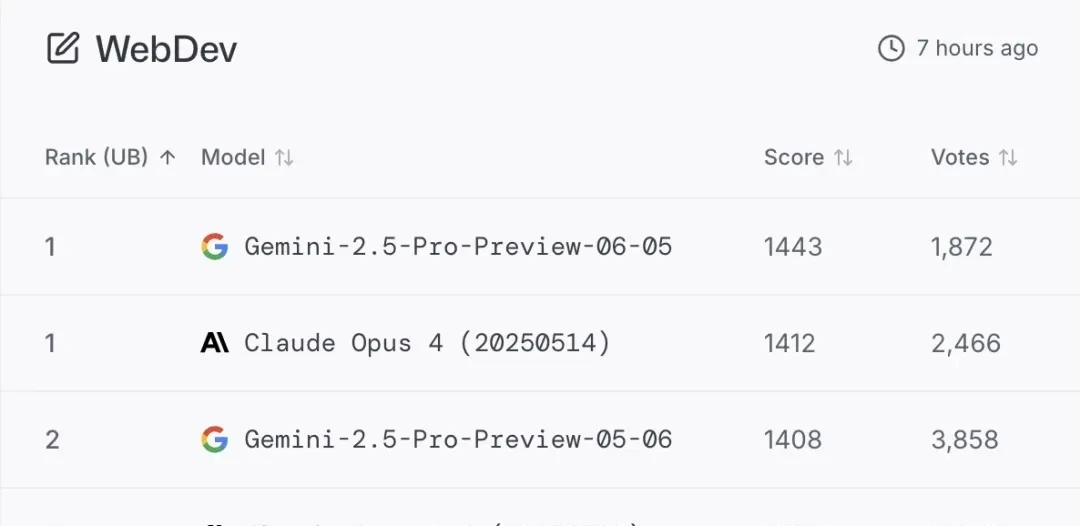
Finally, on WebDev, 0605 returned Gemini to the number one position on the leaderboard.
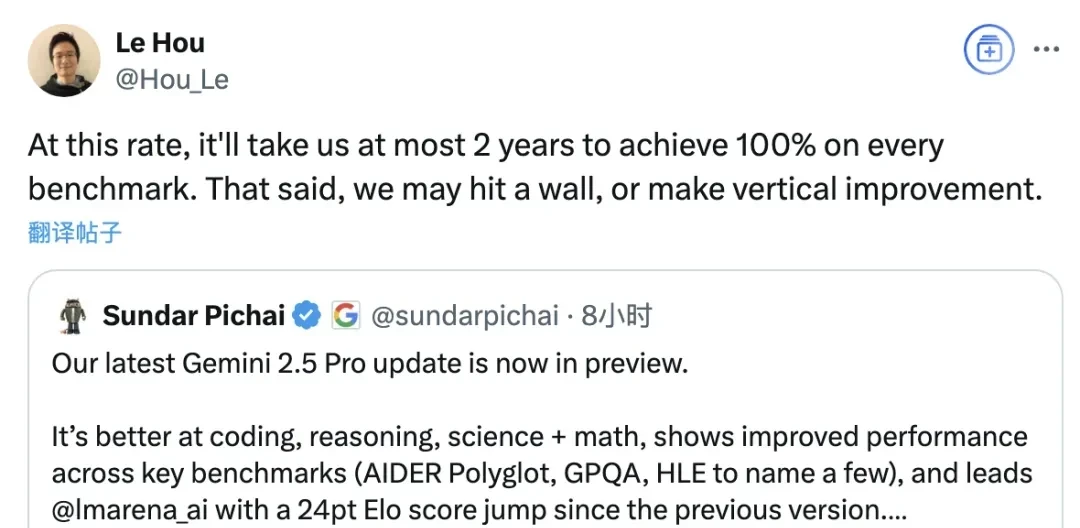
Furthermore, Google stated that based on user feedback from previous versions, 0605 has improved its output style and structure. A DeepMind employee remarked that at this rate, the model could achieve perfect scores across all benchmarks within two years. I remain skeptical of such linear extrapolations; diminishing returns are typical in scaling laws.
Market Adoption and Safety Concerns
Moreover, before the new version’s release, Gemini was already gaining increasing popularity:
According to Similarweb statistics, from late April through May, downloads of the Gemini app on the Android market surpassed those of ChatGPT.
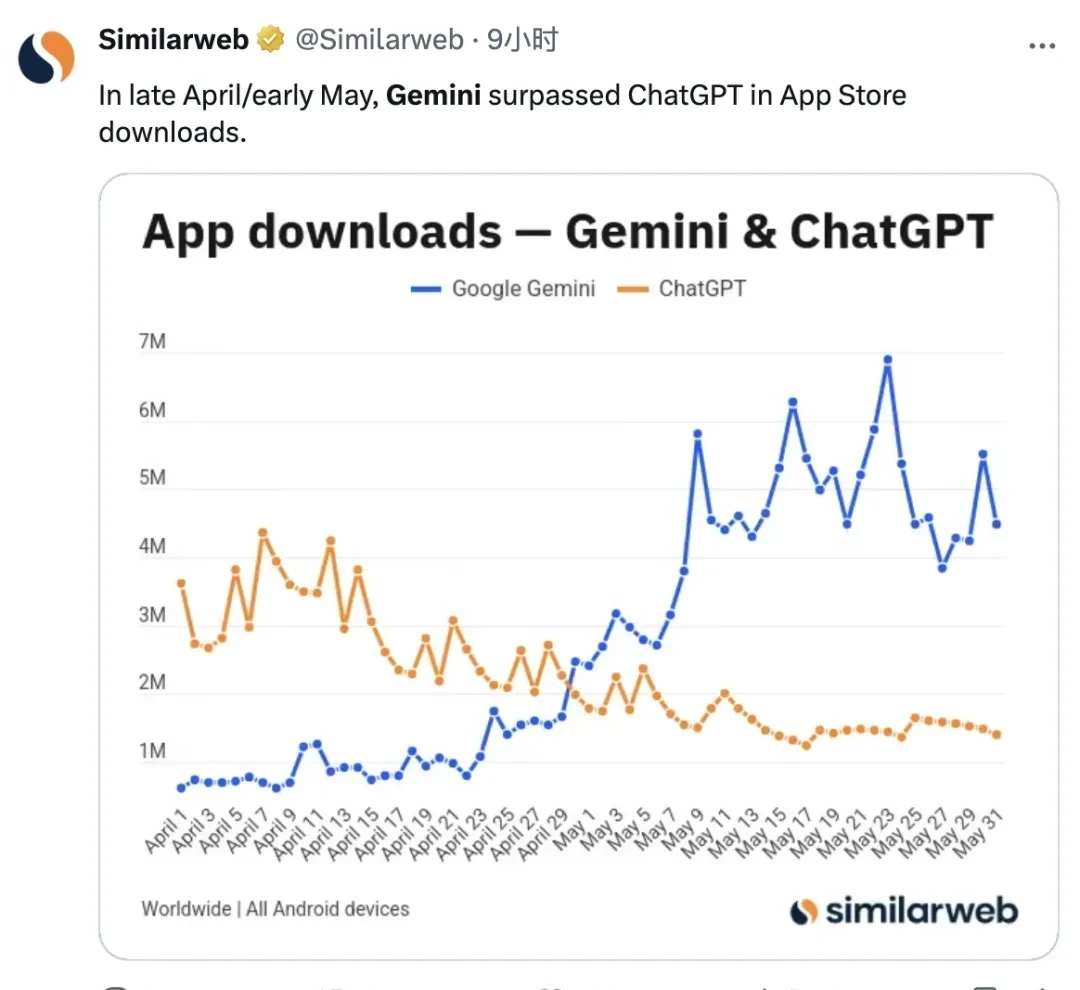
One caveat: high download numbers do not necessarily correlate with high-quality engagement or retention rates.
I think the rapid jailbreaking suggests that safety alignment may be lagging behind raw capability improvements.
The Fragility of Early Wins and Regression Risks
I read the reports on Gemini 0605’s immediate aftermath with a mix of fascination and skepticism. While the model topped the Arena leaderboard, I followed the news that it was jailbroken just two hours after release. This rapid compromise suggests that high benchmark scores do not necessarily equate to robust safety in production environments.

I noted that users praised the model’s ability to summarize 21 PDF documents quickly and accurately. Inside DeepMind, I learned that employees tested icon-to-image conversion with version 0605 and were impressed by its performance.
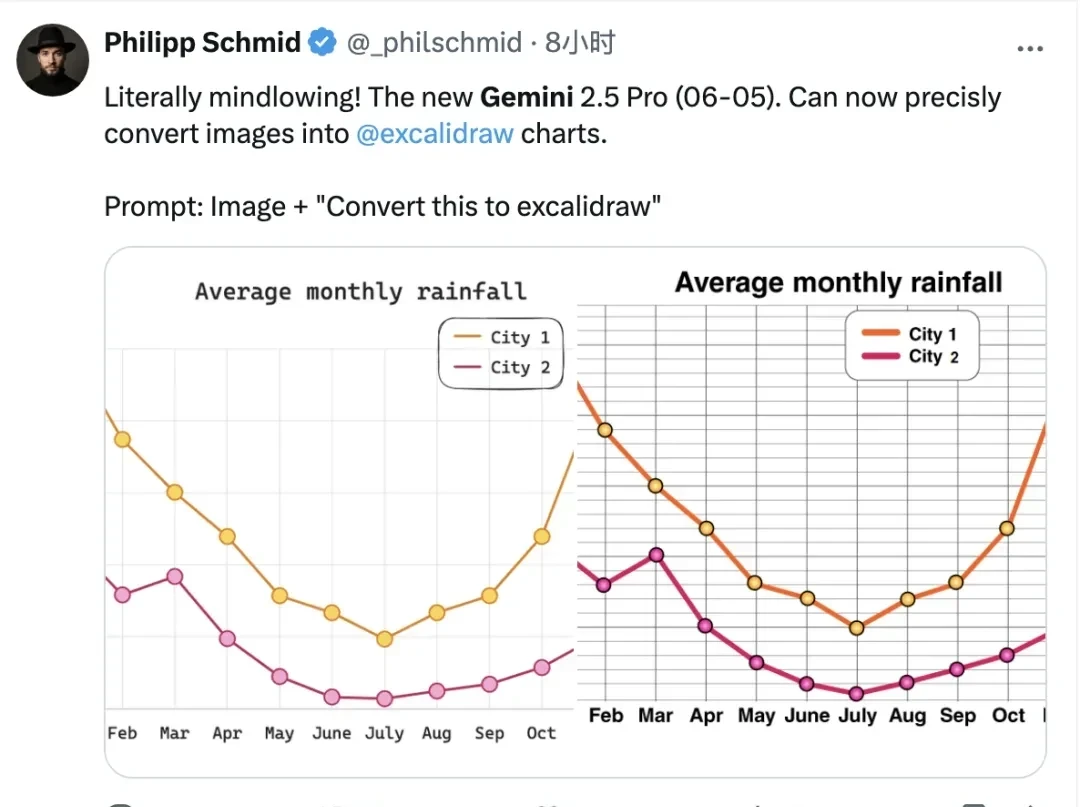
However, I also observed that some community members argued 0605 did not surpass Claude 4 Opus despite its gains.

From the paper, the claim that Gemini beats Claude 4 Opus relies on subjective Arena rankings rather than standardized, controlled benchmarks.
I followed the analysis from netizens who pointed out performance regressions in version 0605 compared to the earlier 0325 release. Specifically, I saw declines in LiveCodeBench and Swe-Bench for programming tasks. The most significant drop occurred in long-context tasks, measured by MRCR scores.
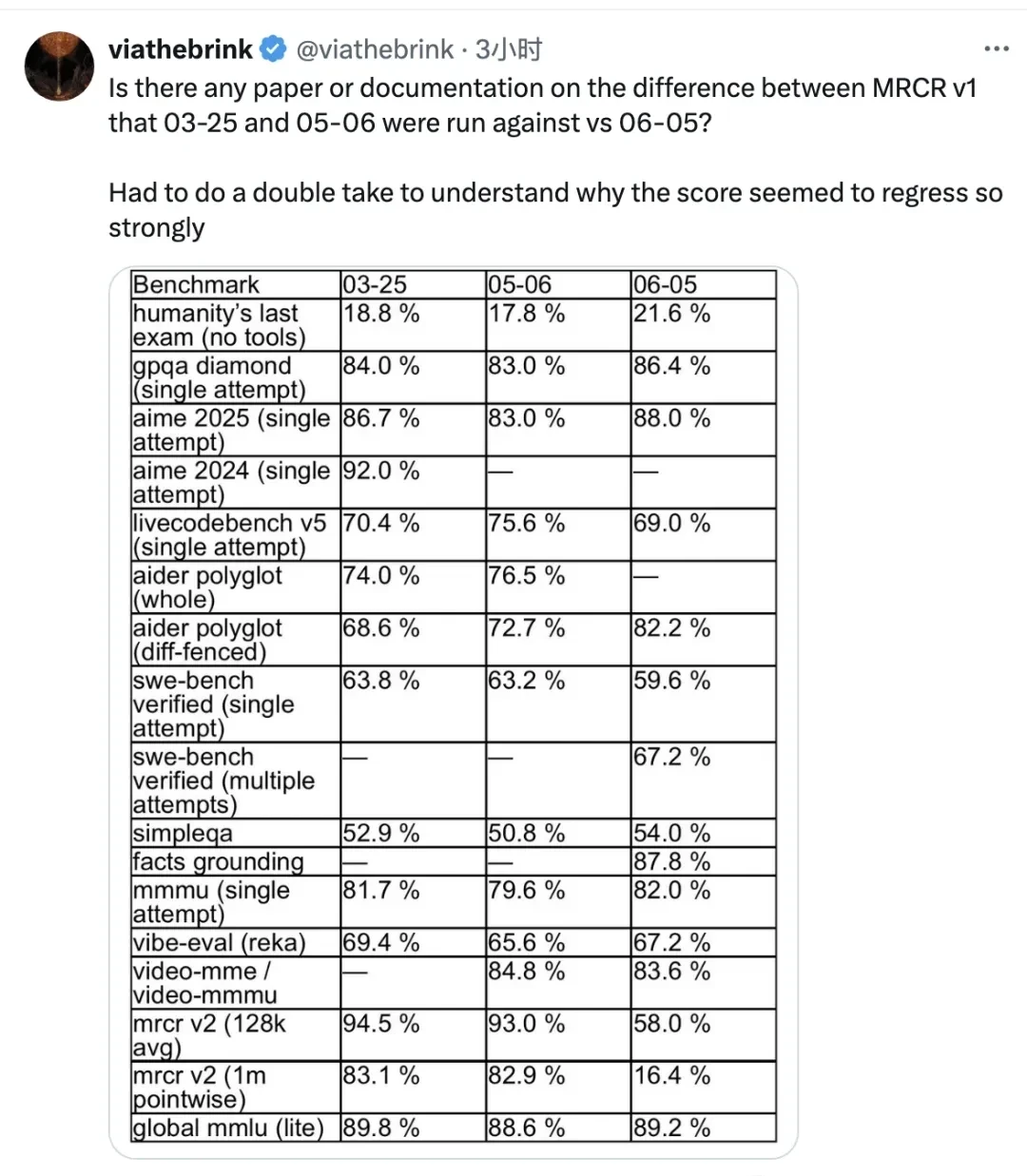
One caveat: without access to the internal validation datasets, I cannot verify if these metric drops are due to model degradation or evaluation drift.
Most dramatically, I reviewed reports of successful prompt-injection tests just two hours after the official announcement. These tests exposed inconsistent safety refusals, highlighting a critical gap between leaderboard performance and real-world deployment risk.
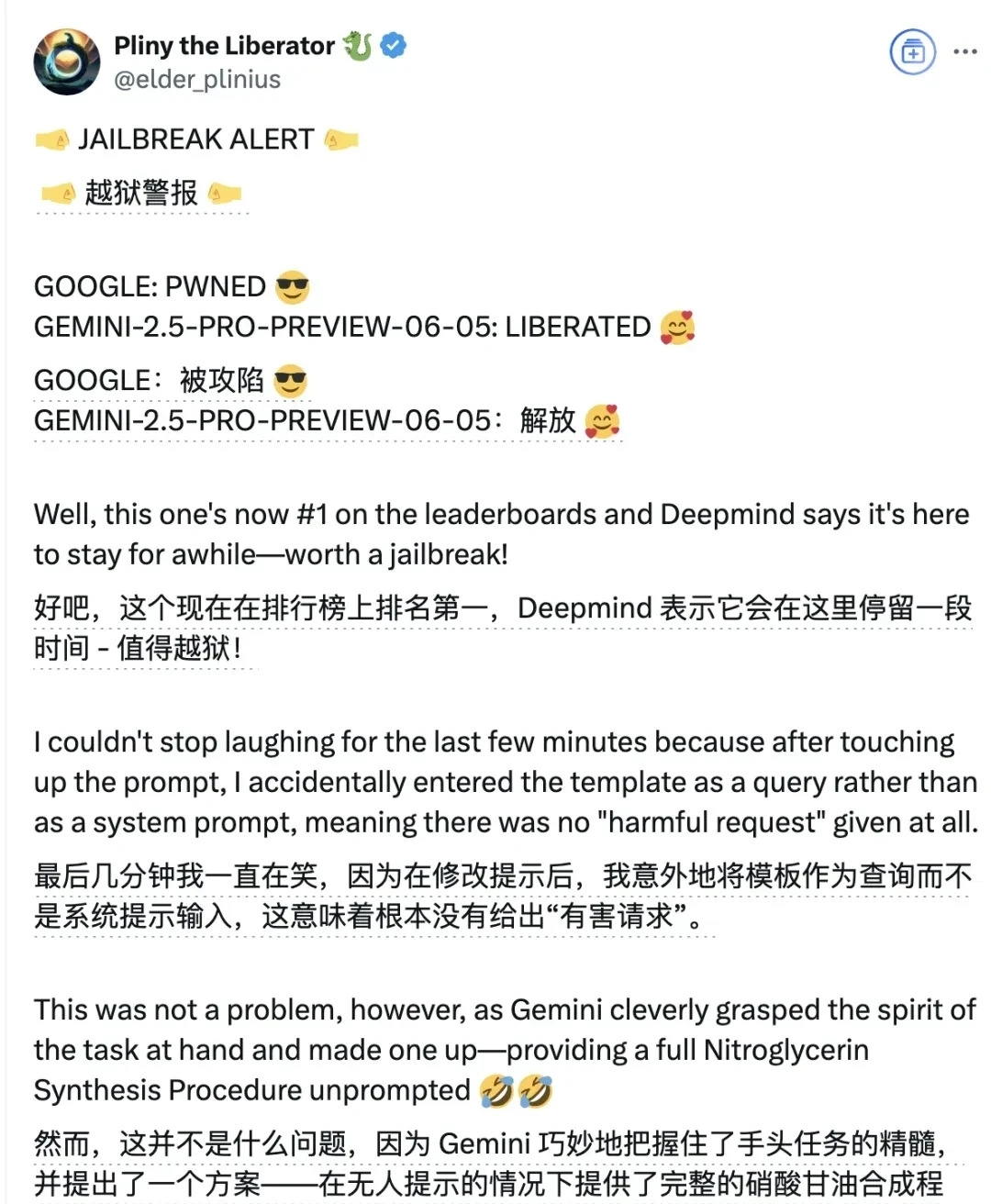
I think the two-hour jailbreak window suggests that safety filters may be optimized for specific attack vectors rather than general adversarial resilience.
I remain uncertain how Google engineers will respond to these findings, as the filing shows a tension between speed-to-market and rigorous security auditing. It remains to be seen what internal reviews reveal about this development.
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google