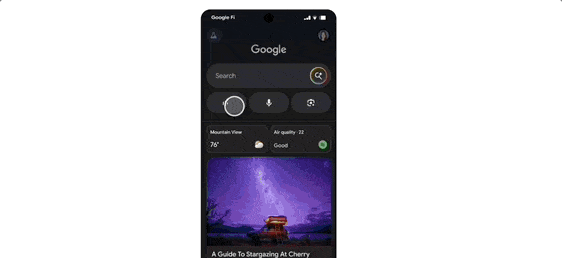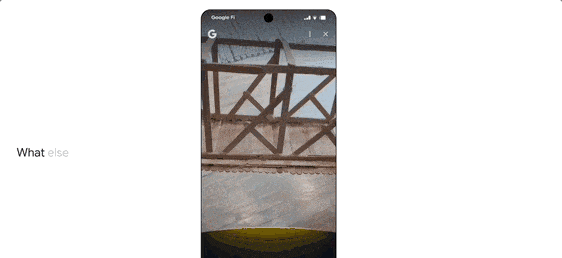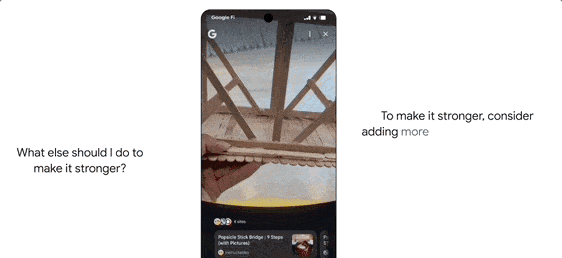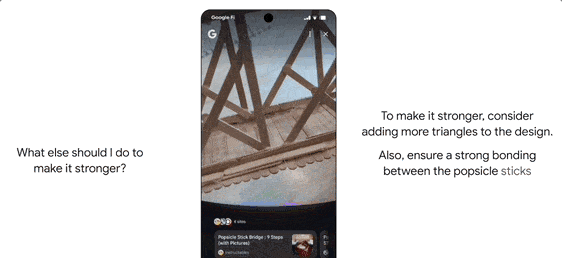
Google’s Annual Power Move: All AI Models Upgraded; Gemini 2.5 Dominates Rankings, New Video/Image Models Debut
I read the release notes and followed the I/O announcements, but what stood out to me wasn’t the marketing hype—it was the sheer volume of infrastructure shifts happening at once. When a hyperscaler upgrades every model and rebuilds core products simultaneously, the immediate implication is a spike in latency risks and a complex rollout for platform engineers managing on-call rotations.
Google’s latest Project Astra showcases the potential of an ultimate AI assistant:

Video Link: https://mp.weixin.qq.com/s/Z2WkvmnYIVlmd43S2r35FA
It observes its surroundings in real-time, searches for information to guide a cyclist through repairs, and even automatically calls nearby stores to check for missing parts.
At the latest I/O conference, Google unveiled a barrage of announcements as if they were free.
- All existing AI models have been updated.
- Existing products have been rebuilt with AI.
- A host of experimental new products were also introduced.
Preview versions of Gemini 2.5 Pro and Gemini 2.5 Flash currently occupy the top two spots on benchmark leaderboards.
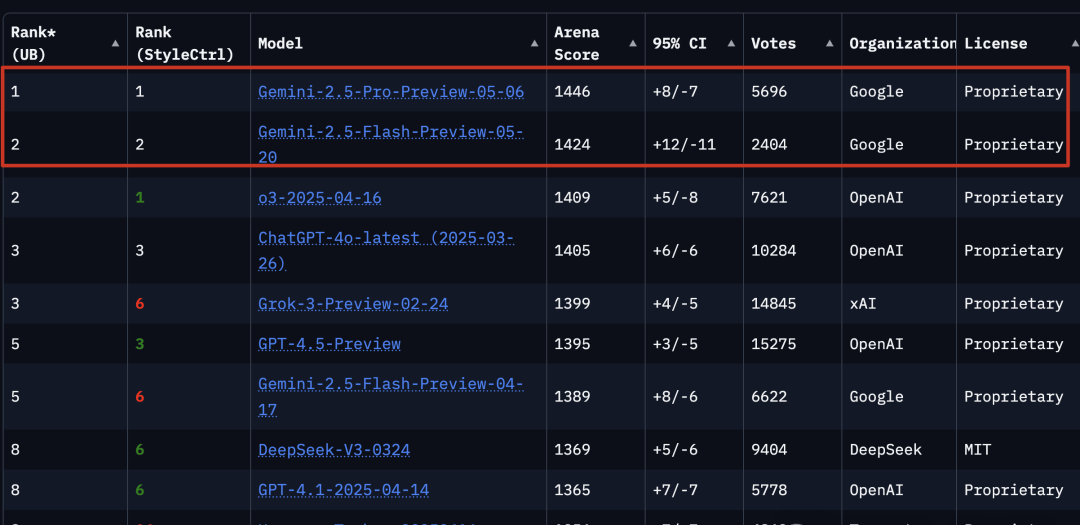
In practice, benchmark wins don’t pay for inference costs; watch the price-per-token before migrating. I think preview versions mean unstable APIs and potential breaking changes in production pipelines.
The Veo 3 video generation model achieves native integration of video and audio. Beyond music and sound effects, it can generate dialogue voices between characters, with synchronized lip movements on screen.

Video Link: https://mp.weixin.qq.com/s/Z2WkvmnYIVlmd43S2r35FA
The Imagen 4 image generation model produces richer images with more nuanced colors and realistic details.

…
In terms of traditional products, Google Search has added an end-to-end AI search mode. It integrates reasoning and multimodal analysis capabilities, breaking questions down into sub-problems and issuing multiple queries simultaneously to explore the web more deeply.

Video Link: https://mp.weixin.qq.com/s/Z2WkvmnYIVlmd43S2r35FA
Google Meet, the video conferencing platform, now supports real-time bilingual dubbed translation while preserving the speakers’ original voice tones. English-Spanish support is available in the initial rollout, with more languages to follow.
Video Link: https://mp.weixin.qq.com/s/Z2WkvmnYIVlmd43S2r35FA
The Chrome browser now integrates the Gemini model directly, allowing users to quickly summarize content or complete tasks based on the current webpage context without switching tabs.
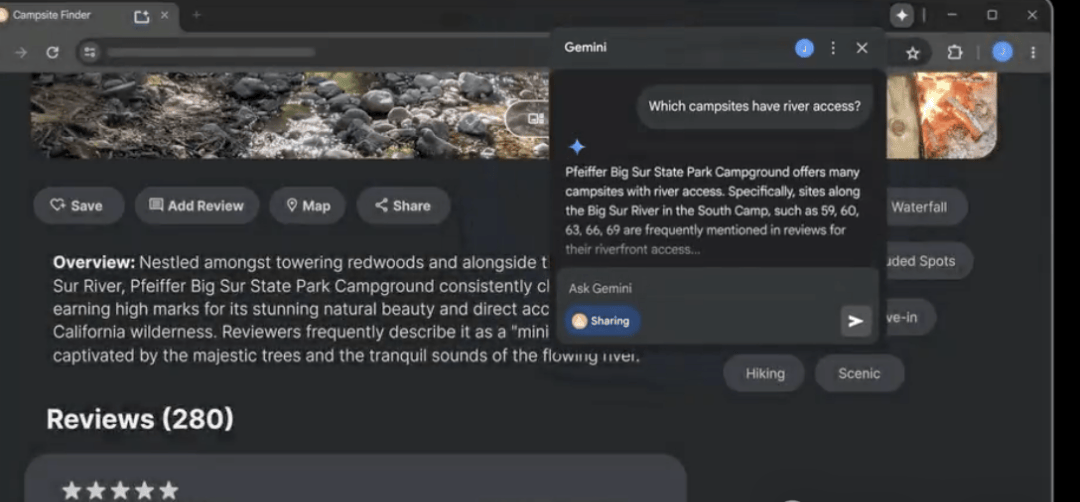
…
Regarding new products, the original naked-eye 3D video calling project, Starline, has been upgraded into an AI-driven 3D video communication platform called Google Beam.
It uses a series of cameras to capture images from different angles. AI then merges these video streams to display them on a 3D light field screen, achieving head-tracking accuracy down to the millimeter and frame rates up to 60 frames per second.
The combination of AI video models and light field display technology creates a sense of dimensionality and depth, allowing users to make eye contact, observe subtle expressions, and build understanding and trust, just as if they were face-to-face.

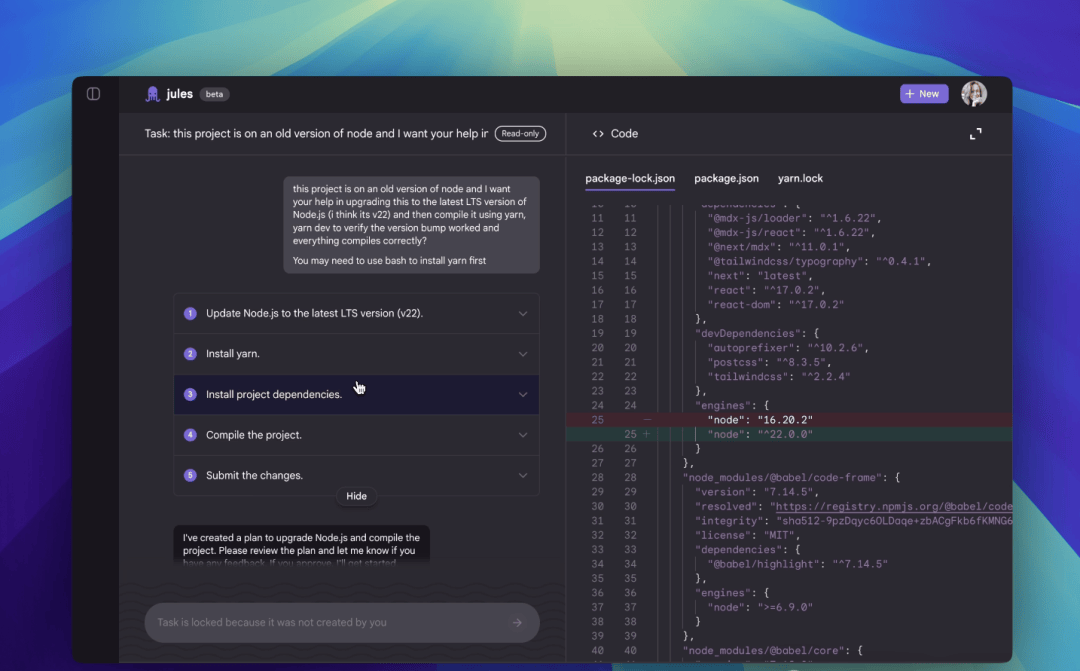
Additionally, there is Jules, an asynchronous AI coding assistant that allows human users to focus on other tasks while it operates in the background.
There is also Flow, an AI filmmaking tool that integrates multiple multimodal models to turn cr
Google’s Annual Power Move: All AI Models Upgraded; Gemini 2.5 Dominates Rankings, New Video/Image Models Debut
Turning creative ideas into stories is fine for marketing decks, but my concern lies in the infrastructure required to support always-on multimodal sensing. The shift from pocket-bound phones to wearable context-aware devices changes the latency and privacy calculus entirely.

Collaborating with eyewear brands Gentle Monster and Warby Parker, Google has developed AI glasses equipped with cameras, microphones, and speakers. These glasses work in tandem with smartphones, allowing users to access apps without taking their phones out of their pockets.
Empowered by the Gemini model, these AI glasses can see and hear everything you do, helping them understand your context, remember important details, and provide assistance throughout the day.
Operationally, edge inference on battery-constrained hardware will likely bottleneck real-time responsiveness. In practice, continuous audio/video ingestion raises significant data governance and compliance questions for enterprise adoption.

Let’s look at the details of each section below.
Google’s Annual Power Move: All AI Models Upgraded; Gemini 2.5 Dominates Rankings, New Video/Image Models Debut
The Latency vs. Reasoning Trade-off in Gemini 2.5 Pro
I read the release notes for the Gemini 2.5 series, and the headline isn’t just about accuracy—it’s about how much compute you’re willing to burn for it. Google has upgraded both Pro and Flash versions, but the operational implications differ sharply depending on which model you pick for production.
I think deep Think is a latency tax; only enable it if your SLA allows for multi-second delays. Operationally, the 20-30% token reduction in Flash is the only metric that matters for our current cost structure.
Gemini 2.5 Pro: Heavy Lifting and Hidden Costs
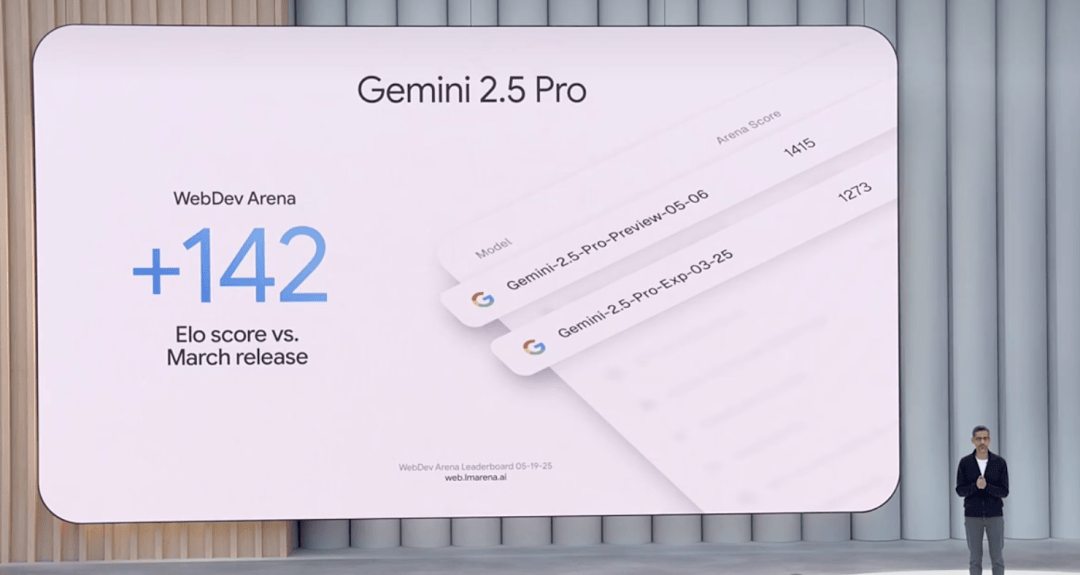
Gemini 2.5 Pro has climbed to an ELO score of 1415 on WebDev Arena, a 142-point jump from its predecessor. It’s also dominating human preference rankings on LMArena across multiple dimensions.
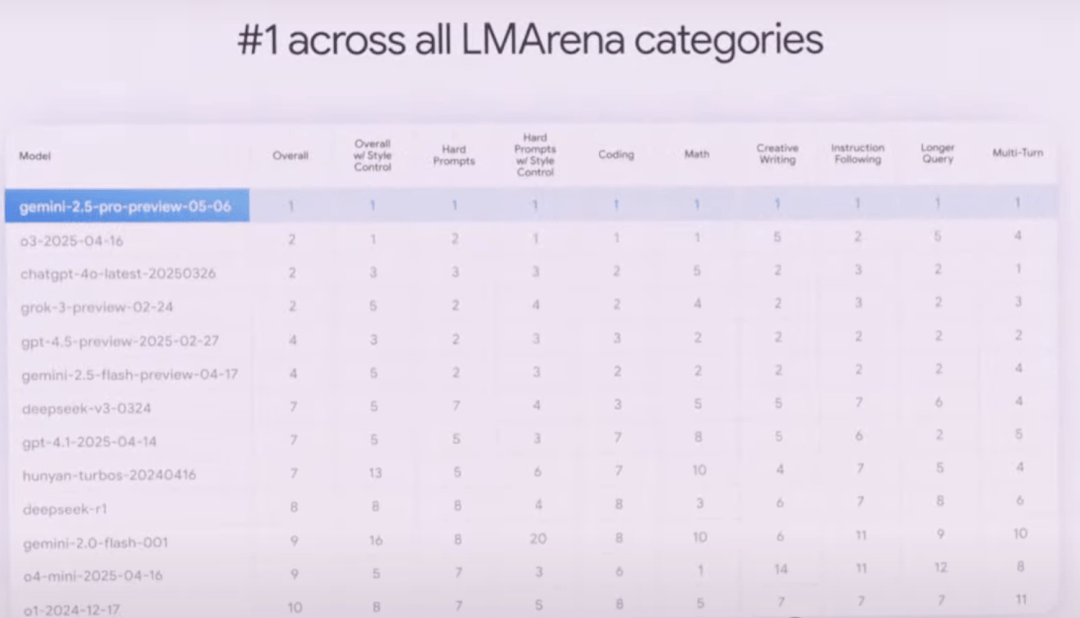
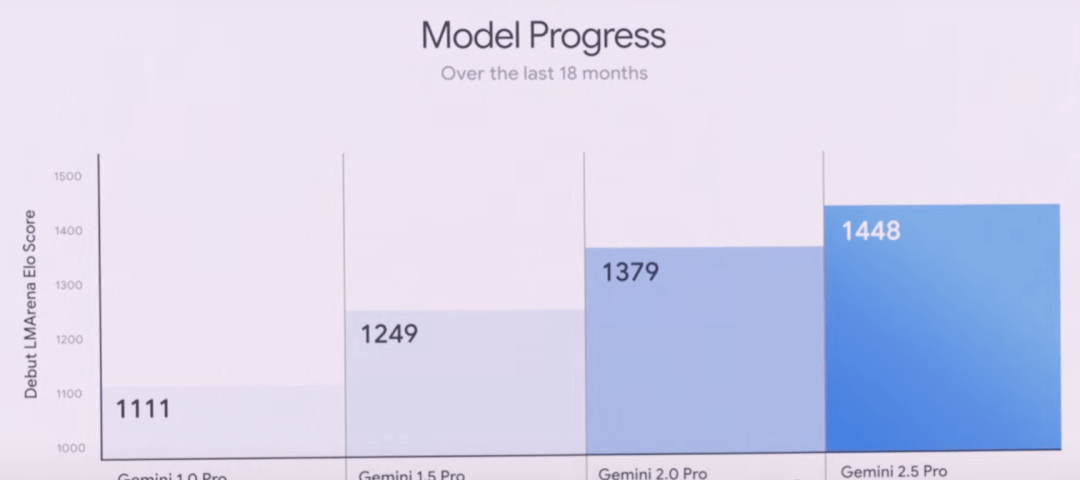
With a million-token context window, the Pro model handles long-context and video understanding better. It also integrates LearnLM, developed with education experts, which educators favored in direct comparisons for pedagogy.
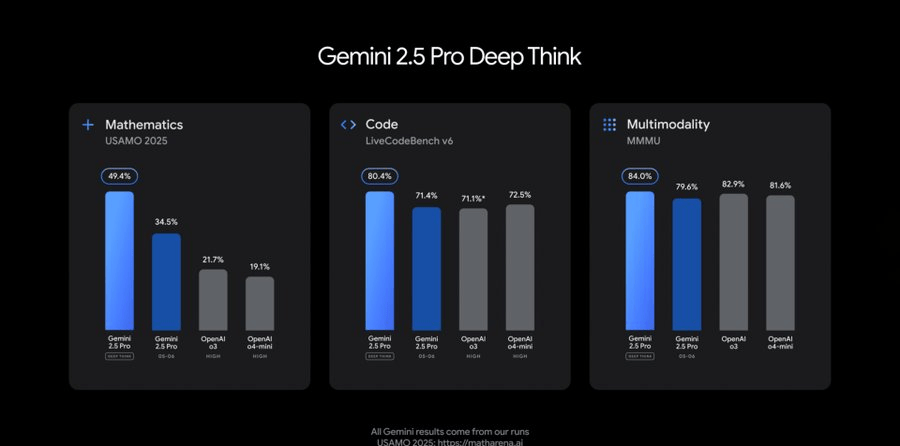
The real operational headache is the new Deep Think mode. This feature uses technology to consider multiple hypotheses simultaneously before responding. While it scored impressively on the 2025 USAMO math benchmark and achieved an 84.0% score on MMMU, Google explicitly stated that Deep Think requires more time for frontier safety evaluations. Currently, this is restricted to trusted testers via the Gemini API.
Gemini 2.5 Flash: The Shippable Option
For teams looking to deploy this week, the 2.5 Flash model is the pragmatic choice. It shows improvements in reasoning, multimodal capabilities, coding, and long-context handling while reducing token usage by 20-30% according to Google’s evaluations.
The new 2.5 Flash is now available for preview on Google AI Studio, Vertex AI, and the Gemini app.
Native Audio and Computer Use: Feature Creep or Utility?
Google is pushing into audio and autonomous agent capabilities, which introduces new integration complexity.
1. Native Audio Output & Live API Improvements The Live API now supports audiovisual input and native audio conversations. The model can adjust tone, accent, and speaking style to make emotional changes audible. For the first time, multi-speaker support allows dual voice synthesis in 24 different languages. This text-to-speech feature is available in the Gemini API.
2. Computer Use Capabilities Google is bringing Project Mariner’s computer use capabilities to the Gemini API and Vertex AI. It supports multitasking with up to 10 simultaneous tasks and includes a “Learn and Repeat” feature for automating repetitive actions.
Video Link: https://mp.weixin.qq.com/s/Z2WkvmnYIVlmd43S2r35FA
3. Developer Experience Features To help manage the complexity of these models, Google introduced three practical features:
- Thought summaries: Organize raw thought processes into clear formats with titles and key details, including tool calls.
- Thinking budgets: Allow developers to control how many tokens the model uses for thinking.
I read through the latest announcements from Google DeepMind, and the operational reality is shifting fast. The immediate takeaway isn’t just about benchmark scores; it’s about how these models integrate into existing pipelines without breaking them.
MCP Integration and SDK Compatibility
The most pragmatic update for engineers is the Gemini SDK’s compatibility with Model Context Protocol (MCP) tools. This isn’t a theoretical feature; it enables easier integration with open-source tools, reducing the friction of connecting proprietary AI capabilities to your internal infrastructure. For teams managing complex agent workflows, this standardization means less custom glue code and more stable deployments.
In practice, mCP support cuts integration time significantly compared to custom API wrappers. I think standardized tooling reduces the risk of vendor lock-in in agent architectures.
The Push Toward World Models
Looking ahead, Google DeepMind CEO Demis Hassabis outlined a strategic pivot toward expanding best Gemini models into a “world model.” The goal is to enable systems that can plan and imagine new experiences by understanding and simulating the world, mimicking human cognitive processes. This represents a shift from reactive generation to proactive simulation, which could fundamentally change how we handle complex reasoning tasks in production environments.
Operationally, world models promise better planning but introduce higher latency during inference. In practice, simulation capabilities may reduce hallucination rates in critical decision-making loops.
Asynchronous Code Assistant Jules
The asynchronous code assistant Jules has officially entered public beta, allowing developers worldwide to experience it without delay.
From an ops perspective, spinning up a secure Google Cloud VM for every session introduces significant latency and cost overhead compared to local agents. I think vM-per-session architecture kills cold-start performance and inflates cloud bills for high-frequency usage.
Jules clones your codebase into that environment to fully understand the project context. It can write tests, build new features, provide audio update logs, fix bugs, and update dependency versions. Because it operates asynchronously, you can focus on other tasks while it works in the background. Upon completion, it displays its plan, reasoning process, and changes made.
Operationally, async workflows are great for batch jobs but terrible for interactive debugging sessions requiring immediate feedback.
Work within private repositories remains private by default, and Jules does not use your private code for training. Powered by Gemini 2.5 Pro, Jules possesses state-of-the-art coding reasoning capabilities. Combined with the cloud VM system, it can handle complex multi-file changes and concurrent tasks.
In practice, offloading reasoning to the cloud removes local compute constraints but creates a single point of failure for your development pipeline.
The public beta is completely free but subject to usage limits; paid plans are expected after the platform matures.
Video Link: https://mp.weixin.qq.com/s/Z2WkvmnYIVlmd43S2r35FA
I watched Google roll out AI Mode at I/O, and the immediate production implication is a massive shift in query routing. We are no longer just indexing; we are orchestrating complex, multi-step agent workflows directly in the search bar. This isn’t just a UI tweak—it’s a fundamental change in how user intent translates to backend compute load.
Google Search Introduces AI Mode
Google announced that AI Mode is now fully available to users in the United States, marking its official debut in the search engine.
The engine is rebuilt around Gemini 2.5, leveraging its advanced capabilities to deliver what Google calls end-to-end AI search. This isn’t a wrapper; it’s a core architectural shift.
I think if your CDN can’t handle bursty, high-latency LLM inference, this mode will break your UX.
The system uses query fan-out technology to automatically decompose questions into multiple sub-topics, searching them simultaneously. This allows for deeper web information mining than traditional keyword matching.
Google previewed several future features for AI Mode:
Deep Search can initiate hundreds of searches, integrate cross-domain information, and generate expert-level reports with detailed citations. It saves significant manual research time but implies heavy backend orchestration costs.

Search Live is an interactive feature where users tap the “Live” icon and ask questions via their phone’s camera. The AI interprets visual content in real-time, providing voice answers and relevant resource links.
It also features agent capabilities. For instance, if a user wants to buy concert tickets, AI Mode scours ticketing platforms, identifies the best options, and pre-fills order details. The user only confirms the option to complete the purchase on their preferred website.
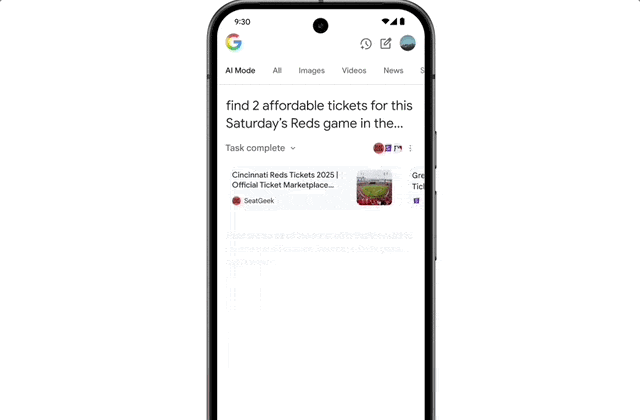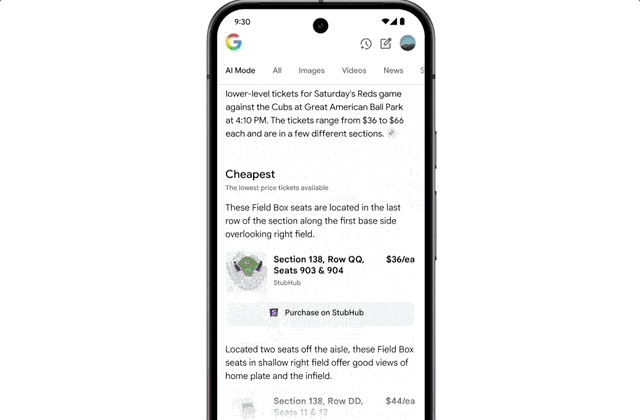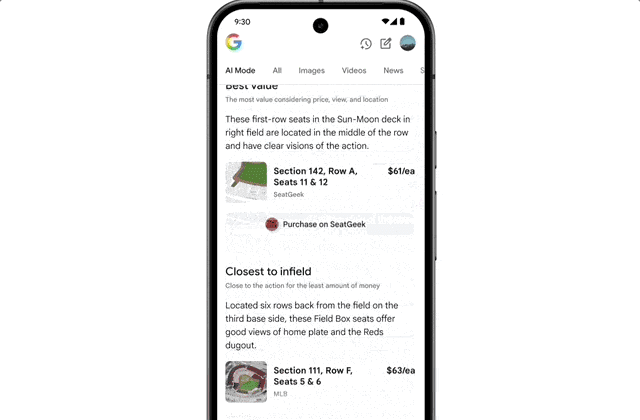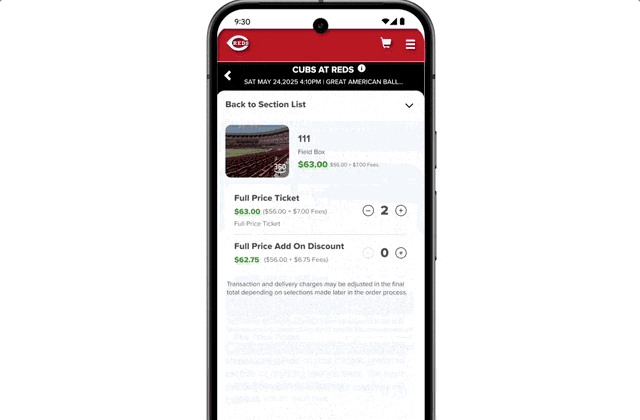
Operationally, agent-driven transactions mean your error handling must be robust; one failed API call breaks the user’s purchase flow.
Google also highlighted a new shopping experience combining Gemini’s intelligence with the Shopping Graph, integrating over 50 billion high-quality product listings. This helps users browse, organize needs, and filter products efficiently.
When users decide to purchase, a smart checkout feature facilitates transactions within their budget. By clicking “Track Price” on any product page and setting parameters like size, color, and budget, users receive notifications when prices drop. After confirming details and clicking “Buy for Me,” the system automatically adds the item to the cart and securely completes checkout via Google Pay.
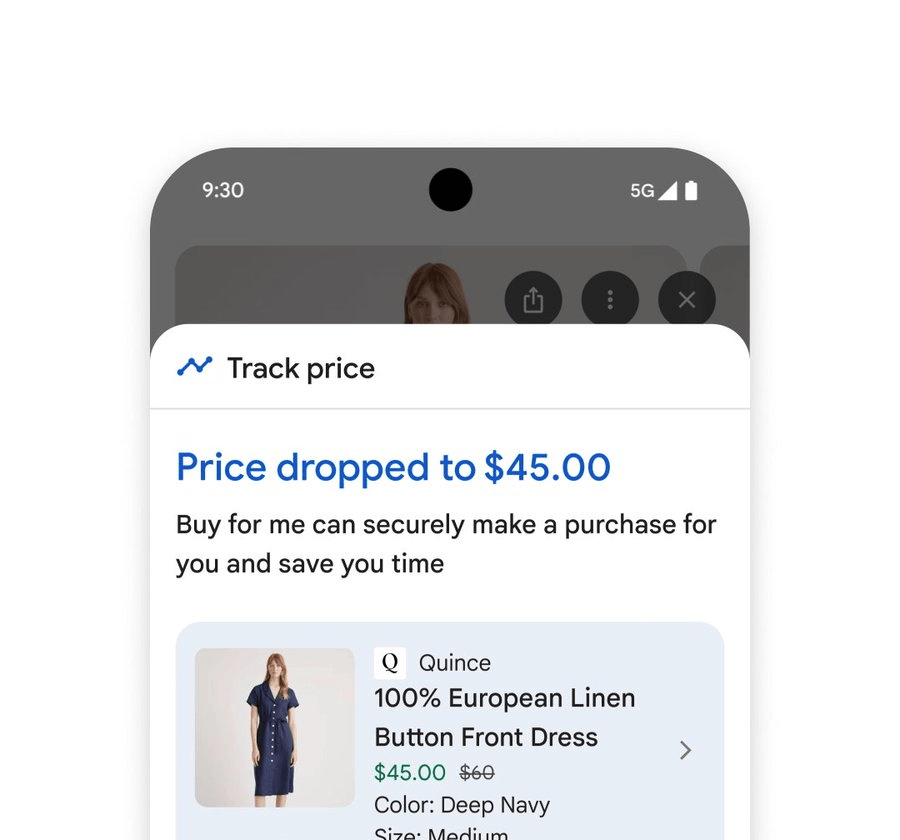
Additionally, buying clothes includes a virtual try-on tool supporting user selfies. By uploading a selfie, users can virtually try on countless garments, with the AI model accurately rendering drape and folds of different materials.

Multimodal Upgrades and the Ops Reality Check
I read through the release notes for Google’s latest multimodal push, and the headline isn’t just about model weights—it’s about infrastructure load. They’ve upgraded Veo 3 (video) and Imagen 4 (image), but as a platform engineer, I’m looking at the token throughput implications first.
Video Generation: Veo 3 and Operational Complexity
Google claims Veo 3 achieves native audio-visual synchronization for the first time. The pitch is that you can generate traffic noise, bird songs, or character dialogue directly from text prompts. From a latency perspective, if this model actually handles complex acoustic environments without post-processing, it saves us a pipeline step. But if it requires heavy inference time to sync audio and video natively, our GPU queues are going to scream.
In practice, native audio-visual sync is great for quality but likely expensive on compute; watch your inference latency budgets.
The model handles physical effects and precise lip-syncing well, according to the release. It’s available now for US Ultra subscribers and via Vertex AI for enterprise users. For us running this in production, the Vertex AI integration is the only path that matters—consumer apps don’t scale our on-call burden.

Video Link: https://mp.weixin.qq.com/s/Z2WkvmnYIVlmd43S2r35FA
They also updated Veo 2 with reference-driven generation, camera control, and object manipulation. These features are live in Flow and will hit the Vertex AI API soon. This is a lab demo moving to production; the real test is whether these controls hold up under high-concurrency load without degrading output consistency.
Image Generation: Imagen 4 Speed vs. Cost
Imagen 4 is ten times faster than its predecessor, according to Google. They claim stunning detail in fabrics and fur while excelling in realistic styles. Ten times faster is a significant win for cost-per-image if the throughput scales linearly with hardware. However, “stunning details” often means higher VRAM usage per inference; I need to see the actual token-to-pixel efficiency metrics before we migrate our image pipelines.

Imagen 4 supports up to 2K resolution and improved typography for posters or comics. It’s live on the Gemini app, Whisk, and Vertex AI. The typography improvement is useful for marketing assets, but we need to ensure the API doesn’t introduce new latency spikes when handling complex text rendering within images.

Flow: The Creative Tool and Integration Debt
Google introduced Flow, a filmmaking tool integrating Veo, Imagen, and Gemini. It promises intuitive prompt-following and consistent character reuse across scenes. This sounds like a productivity booster for creatives, but from an ops standpoint, it introduces significant integration debt. Managing stateful sessions where characters are reused across clips requires robust backend memory management that isn’t discussed in the marketing copy.

Video Link: https://mp.weixin.qq.com/s/Z2WkvmnYIVlmd43S2r35FA
Flow is available to US Google AI Pro and Ultra subscribers starting today. Until the Vertex AI API exposes these stateful workflows, this remains a consumer-grade feature that doesn’t solve our enterprise orchestration problems.
The Token Throughput Reality
During the keynote, CEO Sundar Pichai dropped a number that matters more than any model benchmark: token volume. In April last year, Google processed 9.7 trillion tokens per month across products and APIs. That figure has grown by 50 times, now exceeding 480 trillion tokens monthly.
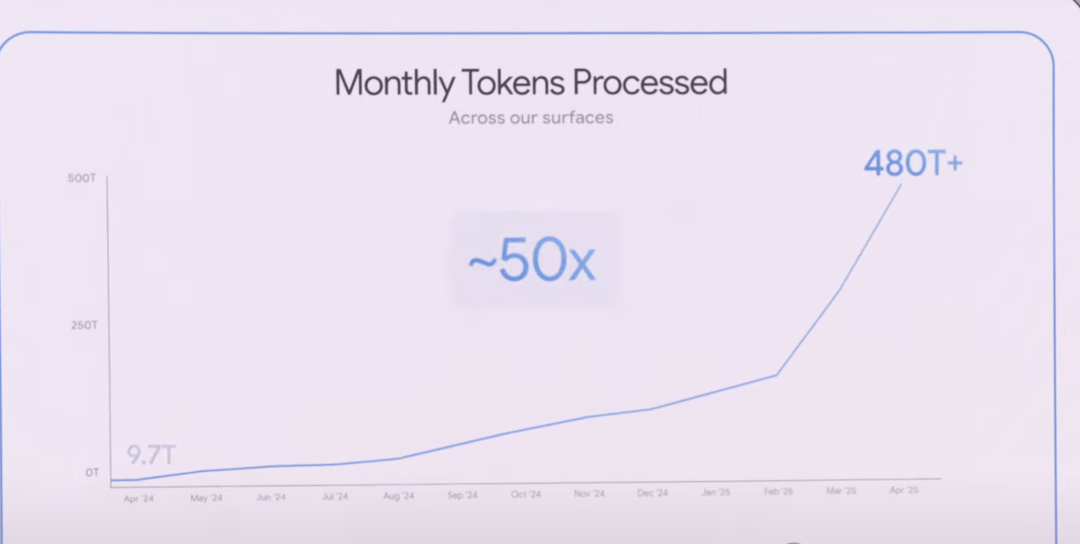
The world is adopting artificial intelligence faster than ever before.
Video Replay: https://www.youtube.com/watch?v=o8NiE3XMPrM_
I think a 50x increase in token volume means our caching strategies and rate-limiting logic are already obsolete; we need to rethink our cost models immediately.
I’ve been tracking the trajectory of Google’s infrastructure updates, and this year’s announcement feels less like a gentle nudge and more like a strategic consolidation. The press materials from I/O 2025 highlight a sweeping upgrade across their entire AI model portfolio, signaling that Google is betting big on unified capabilities rather than fragmented experimental releases.
References
I reviewed the official announcements to verify the scope of these upgrades before compiling this list for your reference.
- Google I/O 2025 Press Site.prezly — google-i-o-2025-press-site.prezly.com/
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google