Google’s Annual Showcase: All AI Models Upgraded; Gemini 2.5 Dominates Top Spots, New Video/Image Models Debut
When Google upgrades its entire stack at once, the creative class doesn’t just get better tools—they get a new set of dependencies to manage. The shift from discrete models to integrated agents changes who controls the workflow: it shifts power from the prompter to the platform orchestrating the context.
Native multimodal input and output, autonomous agents, deep web search… What happens when all cutting-edge AI capabilities are fused into a single ecosystem?
I followed Google’s latest Project Astra demonstration closely. It showcases an ultimate AI assistant that observes its surroundings in real-time, searches for information to guide a cyclist through repairs, and even automatically calls nearby stores to check inventory if parts are missing.

Video Link: https://mp.weixin.qq.com/s/Z2WkvmnYIVlmd43S2r35FA
At the latest I/O conference, Google unveiled a barrage of announcements as if they were free. The strategy is clear:
- All existing AI models have been updated.
- Existing products have been rebuilt with AI.
- A host of experimental new products have also been introduced.
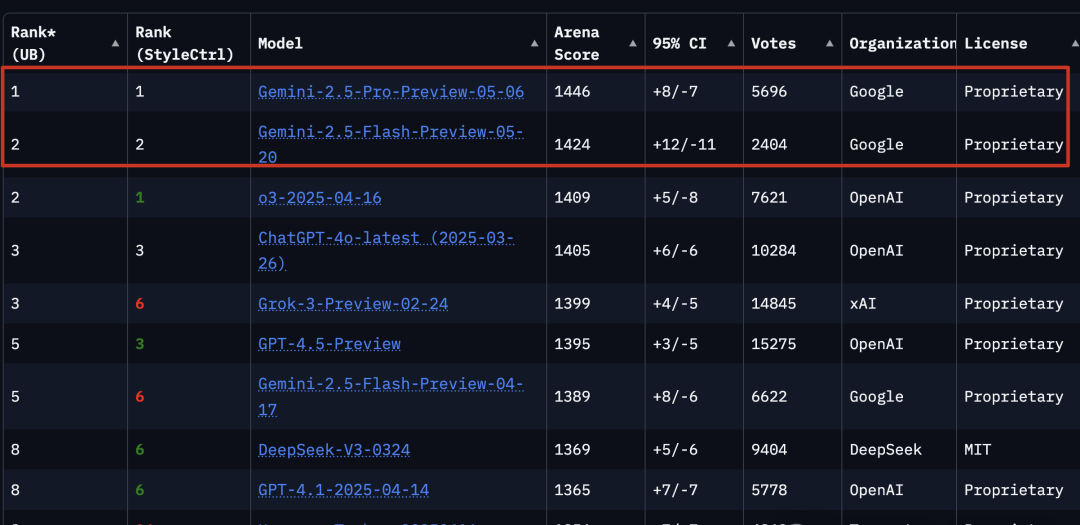
The preview versions of Gemini 2.5 Pro and Gemini 2.5 Flash currently occupy the top two spots on benchmark leaderboards, signaling a massive leap in reasoning capabilities that will likely redefine what users expect from enterprise-grade AI.
I think benchmark dominance doesn’t guarantee fair compensation for the data used to train these reasoning engines.
The Veo 3 video generation model achieves native integration of video and audio. Beyond music and sound effects, it can generate dialogue voices between characters, with lip-syncing synchronized to the visuals—a significant step toward reducing post-production friction for independent filmmakers.

Video Link: https://mp.weixin.qq.com/s/Z2WkvmnYIVlmd43S2r35FA
The Imagen 4 image generation model produces richer images with more nuanced colors and realistic details, pushing the boundary of photorealism further than previous iterations.

…
In terms of traditional products, Google Search has added an end-to-end AI search mode. This integrates reasoning and multimodal analysis capabilities to break down questions into sub-problems and issue multiple queries simultaneously for deeper web exploration, potentially altering how creators source references and verify facts.

Video Link: https://mp.weixin.qq.com/s/Z2WkvmnYIVlmd43S2r35FA
For creators, automated search agents may obscure the original human creators behind the snippets they aggregate.
Google Meet, the video conferencing platform, now supports real-time bilingual dubbing while preserving the speakers’ original voice tones. English-Spanish support is available in the initial rollout, with more languages to follow, raising immediate questions about consent and vocal rights in global collaborations.
Video Link: https://mp.weixin.qq.com/s/Z2WkvmnYIVlmd43S2r35FA
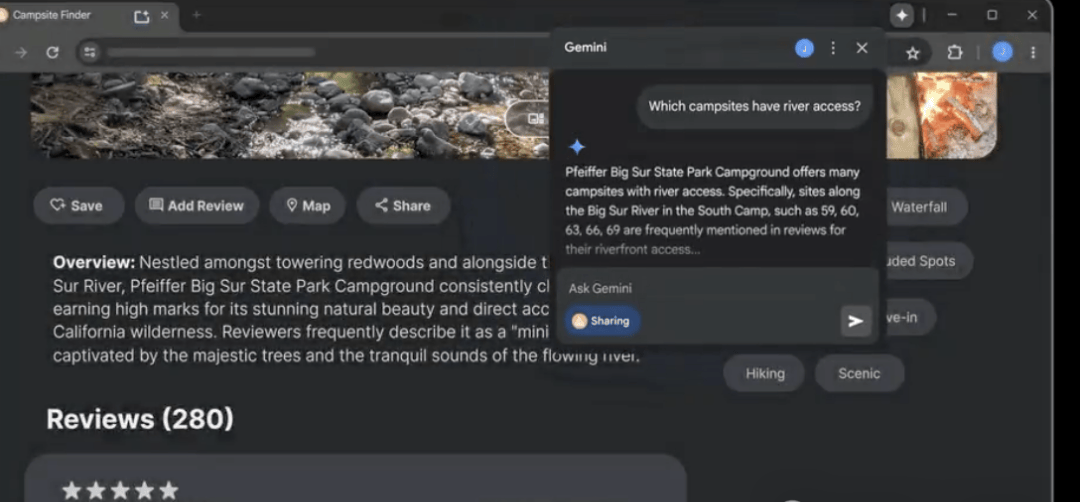
The Chrome browser now integrates the Gemini model directly, allowing users to quickly summarize content or complete tasks based on the current webpage context without switching tabs. This tight integration makes AI assistance ubiquitous but also increases the risk of accidental data leakage across sensitive workflows.
…
Regarding new products, the original naked-eye 3D video calling project, Starline, has been upgraded into an AI-driven 3D video communication platform called Google Beam.
It uses a series of cameras to capture footage from different angles. AI then merges these video streams to present them on a 3D light field display, achieving head-tracking accuracy down to the millimeter and frame rates up to 60 frames per second.
The combination of AI video models and light field display technology creates a sense of dimensionality and depth, allowing users to make eye contact, observe subtle expressions, and build understanding and trust, just as if they were face-to-face. This level of fidelity demands high-bandwidth infrastructure that may exclude creators in developing regions.

Additionally, there is Jules, an asynchronous AI coding assistant that allows human users to focus on other tasks while it operates in the background. This shifts the developer’s role from writer to reviewer, changing the nature of creative contribution in software engineering.
There is also Flow, an AI filmmaking tool that integrates multiple multimodal mo

The wearable arms race has a new contender. Google is partnering with eyewear labels Gentle Monster and Warby Parker to debut AI glasses that sit at the intersection of fashion and persistent computing. These aren’t just smart specs; they are camera, microphone, and speaker-equipped devices designed to work in tandem with smartphones. The value proposition is clear: access apps without ever reaching into your pocket.
Powered by the Gemini model, these glasses promise a level of ambient awareness that feels both convenient and intrusive. They can see and hear your every move, understand context, remember details, and provide assistance throughout the day. This shifts AI from a tool you pick up to an environment you inhabit.

On licensing, wearable AI captures visual data without explicit consent, complicating model training ethics. I think context-aware assistants may devalue human curators who currently filter daily information flows. For creators, hardware partnerships prioritize consumer convenience over creator rights to their own likeness in public spaces.
Details on each component are discussed below.
The Gemini 2.5 Series: A Leap in Reasoning and Control
I watched Google roll out the Gemini 2.5 series, a move that shifts power toward platforms capable of deeper reasoning and native audio synthesis. For creators, this isn’t just about better chat; it’s about models that can control computers and speak with distinct voices, raising immediate questions about attribution and workflow integration.
Gemini 2.5 Pro: Dominating Benchmarks and Education
The upgrades to Gemini 2.5 Pro are substantial, particularly in coding and academic reasoning. It leads the WebDev Arena leaderboard with an ELO score of 1415, marking a 142-point jump from its predecessor.
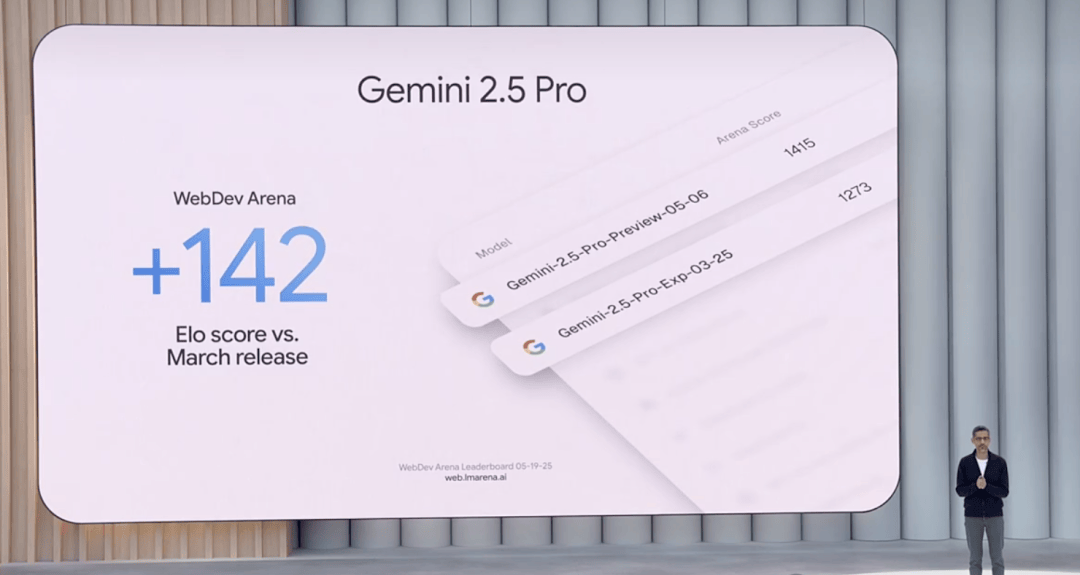
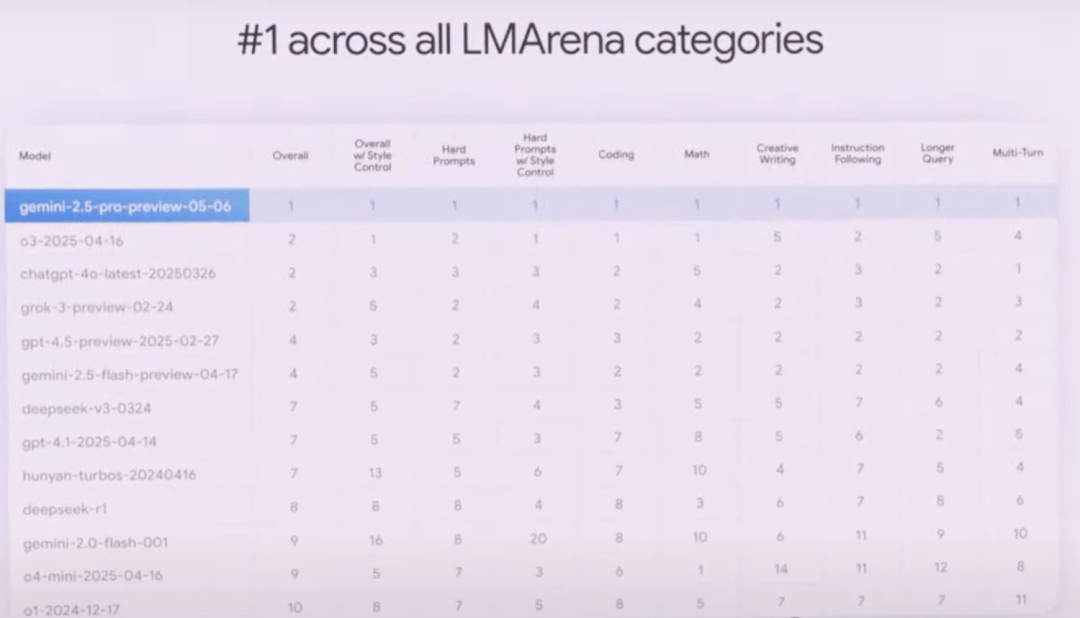
It also commands top spots on LMArena, which measures human preference across various dimensions:
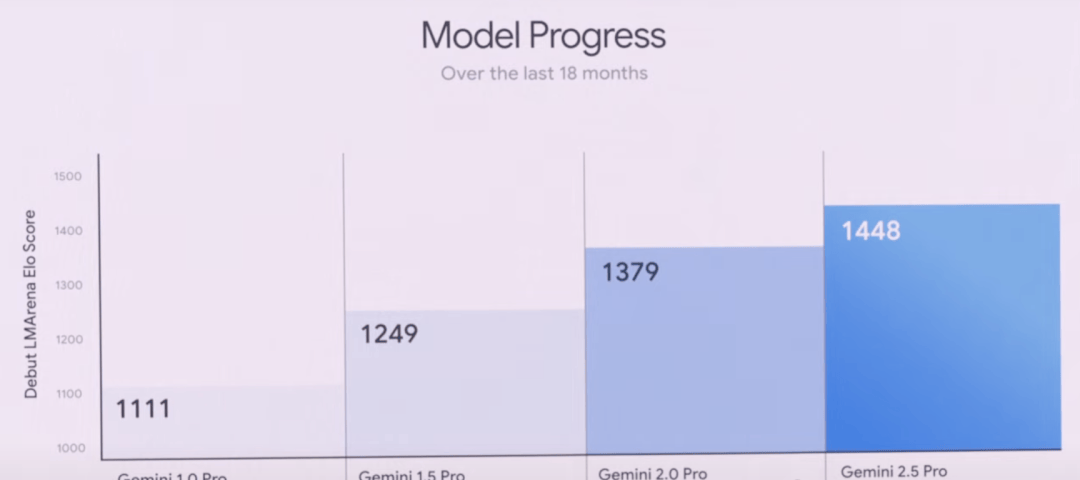
With a million-token context window, the Pro version offers superior long-context and video understanding. It also integrates Google’s LearnLM model series, developed with education experts. In direct comparisons of pedagogy and effectiveness, educators favored the 2.5 Pro across various scenarios.
A key addition is the new Deep Think enhanced reasoning mode. This technology allows the model to consider multiple hypotheses simultaneously before responding. The results are stark: it achieved impressive scores on the difficult 2025 USAMO math benchmark, showed advantages in LiveCodeBench programming tests, and scored 84.0% on the multimodal MMMU benchmark.
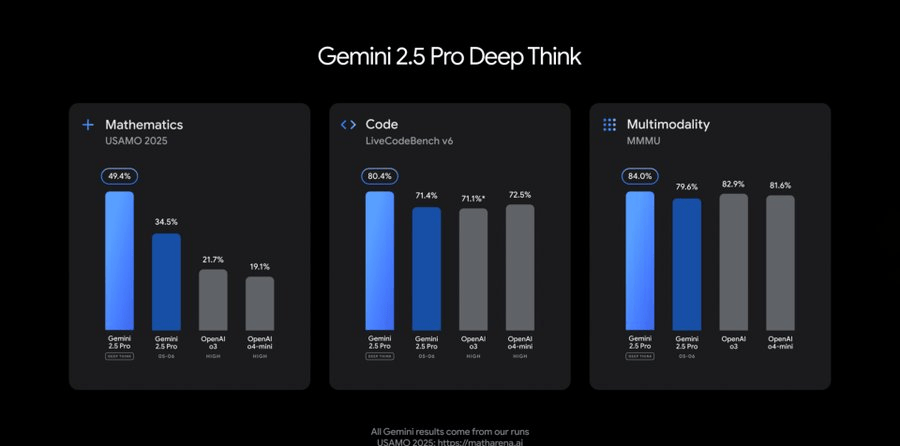
However, Google notes that Deep Think requires extended frontier safety evaluations. Currently, this feature is restricted to trusted testers via the Gemini API only.
On licensing, restricted access to advanced reasoning limits early adopters’ ability to audit model behavior before public release.
Gemini 2.5 Flash: Efficiency and Accessibility
The 2.5 Flash version has also been upgraded, showing gains in reasoning, multimodal capabilities, coding, and long-context handling. Google claims it is more efficient, reducing token usage by 20-30%.
The new 2.5 Flash is now available for preview on Google AI Studio, Vertex AI, and the Gemini app.
New Features: Audio, Computer Control, and Developer Tools
The Gemini 2.5 series introduces several features that change how we interact with AI outputs.
1. Native Audio Output & Live API Improvements
The Live API preview now supports audiovisual input and native audio conversations, allowing for more natural dialogue experiences. Models can adjust tone, accent, and speaking style to make emotional changes audible.
Google has also introduced new text-to-speech (TTS) features for both 2.5 Pro and 2.5 Flash. For the first time, multi-speaker support is available via native audio output. This enables dual voice synthesis, simulating two different characters speaking simultaneously or alternately across 24 languages.
This TTS feature is now live in the Gemini API.
I think multi-voice synthesis lowers barriers for content creation but complicates rights management when voices are indistinguishable from human actors.
2. Computer Control Capabilities
Google is integrating Project Mariner’s computer control capabilities into the Gemini API and Vertex AI. It supports multitasking, executing up to 10 tasks simultaneously. A new “Learn and Repeat” function allows the AI to learn how to automate repetitive tasks.
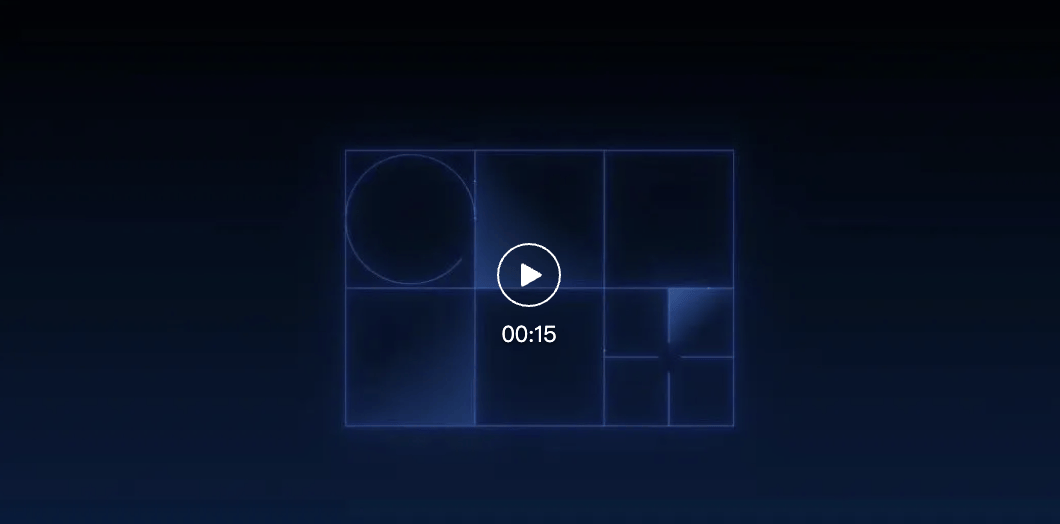
Video Link: https://mp.weixin.qq.com/s/Z2WkvmnYIVlmd43S2r35FA
For creators, automated computer control introduces significant friction for creators who rely on manual, precise editing workflows without risk of unintended AI actions.
3. Three Practical Features Added to Gemini 2.5 to Enhance Developer Experience:
- Thought summaries: These organize the model’s raw thought process into a clear format with titles, key details, and information on model actions (such as tool calls), helping developers gain greater transparency into how the model thinks.
- Thinking budgets: This allows developers to control how many tokens the model uses for thinking
The Push Toward a “World Model”
As I followed the release details from Google’s annual showcase, one direction stood out clearly: the move toward general-purpose simulation. Demis Hassabis, CEO of Google DeepMind, outlined that the team is actively working to expand their best Gemini models into what they call a “world model.” This isn’t just about generating static images or text; it’s about enabling AI to plan and imagine new experiences by understanding and simulating the world in a manner akin to the human brain.
On licensing, simulated worlds could automate complex scene generation, reducing manual layout work for designers. I think if these models handle planning, prompt engineers may see their role shift toward curation rather than creation.
This ambition is supported by technical strides like Gemini SDK compatibility with MCP tools, which facilitates easier integration with open-source ecosystems. By lowering the barrier to entry for developers, Google aims to accelerate how these advanced capabilities are adopted across different creative and technical workflows.
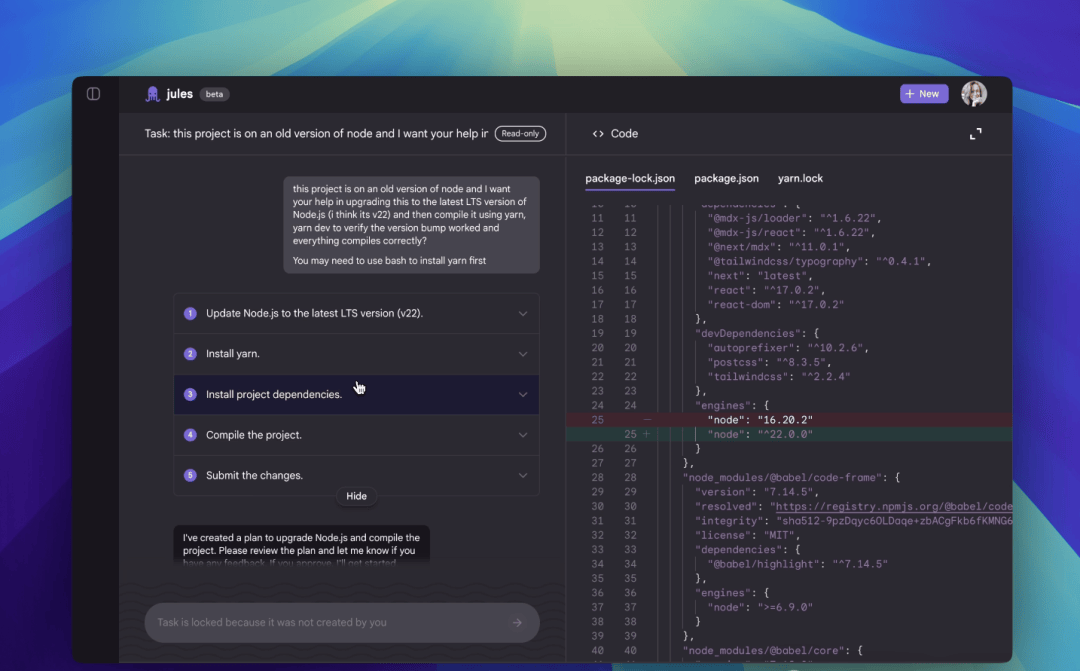
The Asynchronous Code Assistant Jules
Who wins when code review becomes a background task? Developers gain time, but the friction of trusting an AI with private repositories remains high. Jules, Google’s new asynchronous coding agent, has officially entered public beta, letting developers worldwide test it immediately.
I followed the release notes closely: Jules doesn’t just chat; it clones your codebase into a secure Google Cloud virtual machine (VM). This architecture is designed to give it full context of your project without exposing raw data to the model directly. It can write tests, build features, generate audio update logs, fix bugs, and manage dependency versions—all while you focus on other tasks.
For creators, private code stays private by default; Jules does not use it for training. This is a crucial baseline for enterprise adoption.
When Jules finishes its work, it presents the plan, reasoning process, and changes for your review. Powered by Gemini 2.5 Pro, it leverages state-of-the-art coding reasoning to handle complex multi-file changes and concurrent tasks within that isolated cloud VM environment.
The public beta is currently free, though usage limits apply. Paid plans are expected once the platform matures. For those skeptical of “black box” coding assistants, this isolation model offers a tangible step toward safer integration.
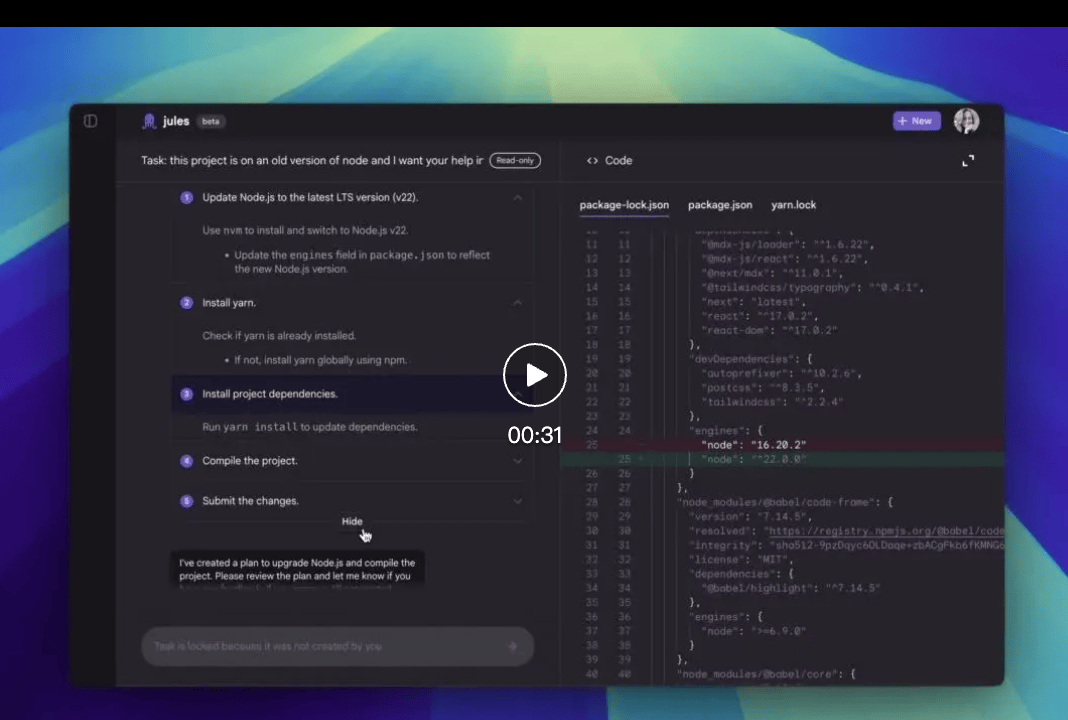
Video Link: https://mp.weixin.qq.com/s/Z2WkvmnYIVlmd43S2r35FA
Google’s Annual Showcase: All AI Models Upgraded; Gemini 2.5 Dominates Top Spots, New Video/Image Models Debut
Google Search Introduces AI Mode
For creators and researchers alike, the shift toward autonomous agents in search is a double-edged sword: it promises efficiency but threatens to bypass the human touchpoints that drive traffic and visibility. I watched Google unveil AI Mode at I/O, marking its full rollout in the United States as a fundamental rebuild of the search engine around Gemini 2.5.
This isn’t just an update; it is end-to-end AI search. By leveraging query fan-out technology, the system automatically decomposes complex questions into multiple sub-topics, searching them simultaneously. This approach allows for a deeper, more comprehensive mining of web information than traditional keyword matching ever could.
Google previewed several powerful features coming to this new paradigm:
Deep Search can autonomously initiate hundreds of searches, synthesize cross-domain data, and generate expert-level reports with detailed citations. It effectively automates the heavy lifting of manual research.

Search Live introduces an interactive layer where users tap the “Live” icon in AI Mode and ask questions via their phone camera. The AI interprets visual content to provide real-time voice answers alongside relevant resource links.
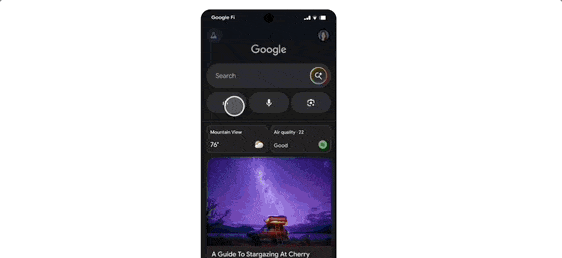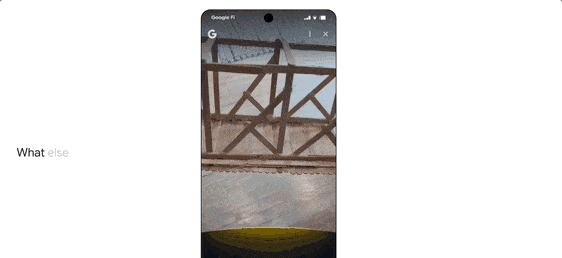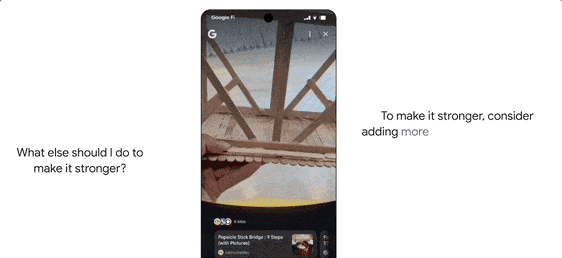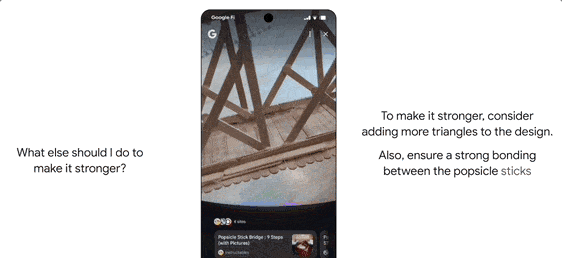
The integration of Agent capabilities marks a significant leap in user workflow friction reduction. For instance, if you want to buy concert tickets, you simply state your request. AI Mode scours ticketing platforms, identifies the best options, and pre-fills order details. You only need to confirm the option that meets your requirements to complete the purchase on your preferred website.
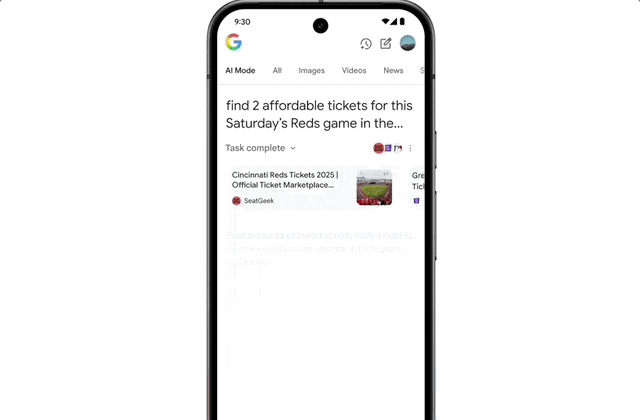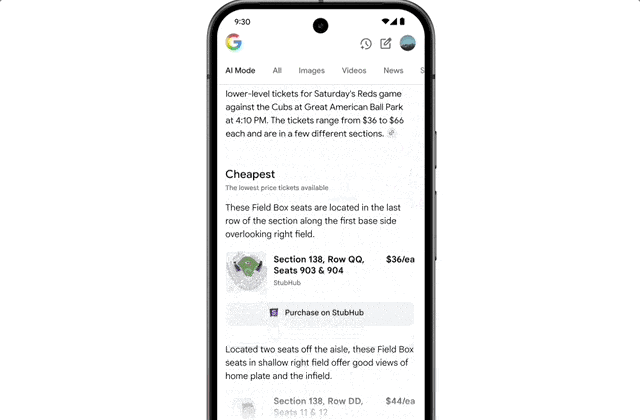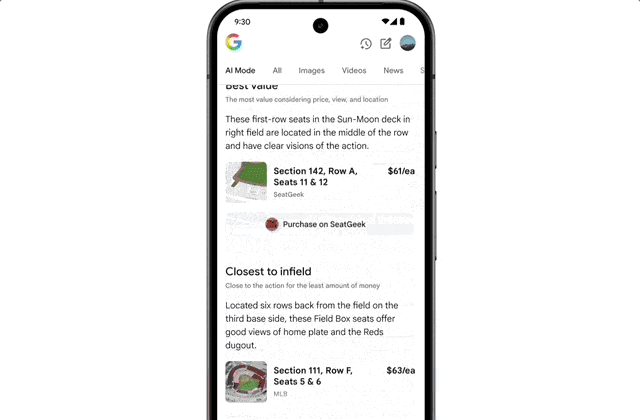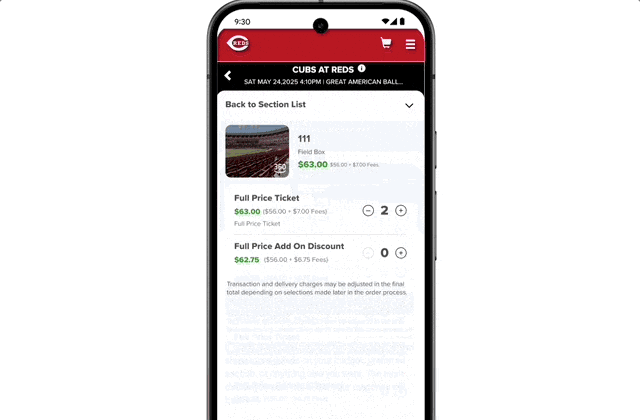
On licensing, autonomous agents bypassing direct clicks could starve niche creators of referral traffic. I think brands must optimize for AI-generated summaries, not just traditional SEO snippets.
Google also highlighted a new shopping experience powered by AI Mode. This combines Gemini’s intelligence with the Shopping Graph, integrating over 50 billion high-quality product listings to help users browse, organize needs, and filter products efficiently.
When users decide to purchase, a new smart checkout feature facilitates transactions based on budget-friendly prices. By clicking “Track Price” on any product page and setting parameters such as size, color, and budget, users receive notifications when the price drops. After confirming purchase details and clicking “Buy for Me,” the system automatically adds the item to the cart and completes checkout securely via Google Pay.
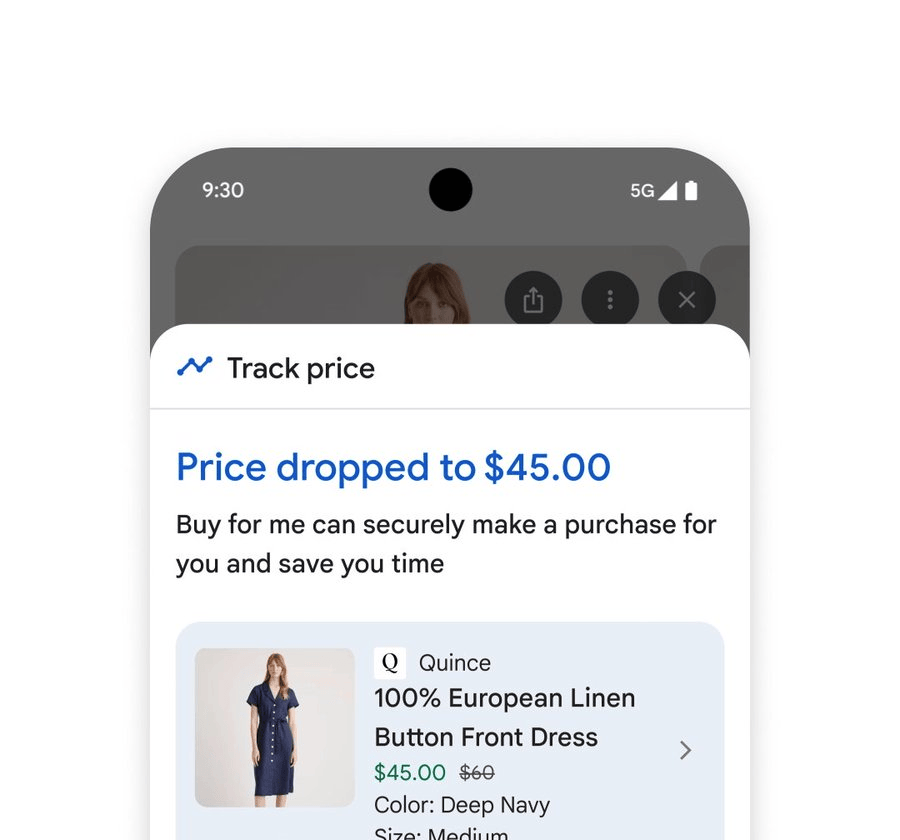
Additionally, when buying clothes, it offers a virtual try-on tool that supports user selfies. By uploading a selfie, users can virtually try on countless garments, with the AI model accurately rendering the drape and folds of different materials.

For creators, virtual try-ons may reduce return rates but complicate attribution for fashion affiliates. On licensing, the “Buy for Me” feature centralizes commerce, potentially sidelining independent retailers.
The New Creative Stack: Who Wins When Google Upgrades the Tools?
As Google rolls out its latest multimodal upgrades, we are watching a shift in who controls the pipeline. For creators, the question isn’t just about better pixels—it’s about whether these new tools streamline your workflow or complicate your licensing rights. I followed the release closely to see where the friction lies for independent artists versus enterprise users.
Upgrades to Video and Image Generation
In the multimodal sector, Google unveiled its latest video generation model, Veo 3, and image generation model, Imagen 4.
Veo 3 achieves native audio-visual synchronization for the first time. Whether it is traffic noise on city streets, bird songs in a park, or character dialogue, all can be generated via text prompts.
Users simply need to tell a short story using a prompt, and the model generates vivid video clips.
From text/image prompts to simulating real-world physical effects and precise lip-syncing, Veo 3 performs exceptionally across all dimensions.
I think native audio sync reduces the tedious post-production burden on indie filmmakers.
Veo 3 is now available to US Ultra subscribers, and enterprise users can access it via the Vertex AI platform.

Video Link: https://mp.weixin.qq.com/s/Z2WkvmnYIVlmd43S2r35FA
Alongside the new model, Veo 2 has added several new features, including reference-driven video generation, camera control, image expansion, and object addition/removal. These features are already available in Flow and will be launched on the Vertex AI API within the next few weeks, with integration into more products over the coming months.
Google’s latest image generation model, Imagen 4, combines speed and precision. It is ten times faster than its predecessor, producing images with stunning fine details—from complex fabrics and water droplets to animal fur—while excelling in both realistic and abstract styles.
For creators, tenfold speed improvements help professionals iterate rapidly without burning through API credits.

Imagen 4 supports various aspect ratios and up to 2K resolution. Its text spelling and typography capabilities have significantly improved, making it easy to create greeting cards, posters, and comics.
On licensing, improved typography lowers the barrier for creators who need quick graphic assets without hiring designers.

Imagen 4 is currently live on the Gemini app, Whisk, Vertex AI, and other platforms.
Additionally, Google introduced Flow, a next-generation AI filmmaking tool designed for creatives. It integrates Google’s most powerful visual models (Veo, Imagen, and Gemini).
Flow boasts excellent prompt-following capabilities, outputting stunning cinematic visuals. The underlying Gemini model makes prompt input intuitive and user-friendly; users can describe their creative vision in everyday language, import their own assets to create characters, or use Imagen’s text-to-image functionality to generate story elements within Flow.
Once a character or scene is created, these elements can be reused coherently across different clips and scenes, or new shots can be initiated from a single scene image.
I think asset reuse features are crucial for maintaining visual consistency in long-form AI projects.

Video Link: https://mp.weixin.qq.com/s/Z2WkvmnYIVlmd43S2r35FA
Starting today, US Google AI Pro and Ultra subscribers can be the first to use Flow.
The Scale of Adoption
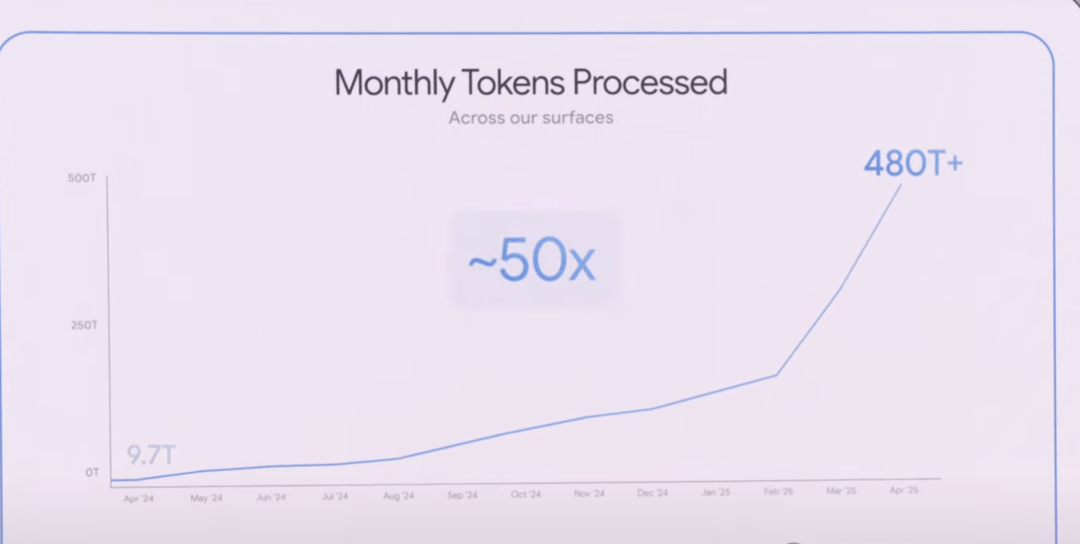
During the keynote, CEO Sundar Pichai revealed a significant statistic.
In April last year, Google’s products and model APIs processed a combined 9.7 trillion tokens per month.
Over the past year, this figure has grown 50-fold, now processing over 480 trillion tokens monthly.
For creators, as token volume explodes, platforms must clarify commercial usage rights to protect creator livelihoods.
The world is adopting artificial intelligence faster than ever before.
Video Replay: https://www.youtube.com/watch?v=o8NiE3XMPrM_
Google’s Annual Showcase: All AI Models Upgraded; Gemini 2.5 Dominates Top Spots, New Video/Image Models Debut
The Creative Stack Shifts Again
As I reviewed the final details of Google’s annual showcase, it became clear that the balance of power in the generative media stack is tilting once more. With Gemini 2.5 securing top spots and new video and image models debuting, the question isn’t just about capability—it’s about who gets to control these tools and how they impact the livelihoods of creators relying on stable, licensed workflows.
References
I’ve compiled the official sources below for those looking to verify the technical claims or explore the press materials directly.
- Google I/O 2025 Press Site.prezly — google-i-o-2025-press-site.prezly.com/
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google