I Follow the Shift: Kaiming He Takes First Team Lead at MIT with Mingyang Deng
Kaiming He’s New Team Effort Arrives After Joining MIT as Associate Professor!

Enabling autoregressive models to abandon vector quantization in favor of continuous values for image generation. By borrowing concepts from diffusion models, the team proposes Diffusion Loss.

I read the recent developments surrounding Kaiming He’s transition to academia. Since joining MIT as an Associate Professor, he has participated in several computer vision papers, but these were collaborations with teams such as that of MIT Professor Wojciech Matusik. I note that this marks a governance shift: for the first time, Kaiming He is leading the team himself.
This structural change brings a familiar and formidable name into his direct leadership circle:
Mingyang Deng, an IMO (International Mathematical Olympiad) and IOI (International Olympiad in Informatics) double gold medalist, known in the competitive programming community as “Guai Shen” (Obedient God).

I followed the background on Mingyang Deng, who is currently an undergraduate at MIT. Based on his enrollment timeline, he is likely a senior this year. Consequently, many netizens speculate that if he continues to pursue a PhD at MIT, he may join Kaiming He’s team. I see this as a potential consolidation of high-impact research under one academic roof, raising questions about IP ownership and future commercial licensing.
Here is a detailed introduction to what this paper investigates.
I think academic leadership shifts often signal new compliance boundaries for industry partners. Enterprises should verify who holds the rights to any resulting generative models. I watch how MIT handles student-led AI research with care. This team structure suggests tighter control over novel diffusion techniques.
My Read on Autoregressive Shifts and Governance Risks
I see a fundamental shift in how we approach generative modeling, moving away from discrete tokenization toward continuous spaces. The burden of proof now lies with enterprises to verify if these new architectures meet their specific latency and quality SLAs. I read the technical details closely because this changes the compliance landscape for model transparency. We must ask who is accountable when a continuous latent space produces ambiguous outputs.
My sense is this technical pivot reduces information loss but increases complexity in audit trails. What concerns me is that enterprises should verify if “continuous” outputs remain interpretable under current regulations. I think the speed gains are real, but governance frameworks lag behind architectural changes.
Rethinking Autoregressive Foundations: From Discrete to Continuous
The traditional consensus held that autoregressive image generation relied heavily on Vector Quantization (VQ). I followed the lineage of this approach, noting that early iterations like DALL·E v1 utilized the classic VQ-VAE method. However, Kaiming He’s team at MIT challenges this orthodoxy. They argue that the core mechanism—predicting the next token based on previous values—has no necessary connection to whether those values are discrete or continuous.
The critical insight is that as long as we can model the probability distribution of tokens via a measurable loss function and sample from it, the data type becomes secondary. I find this distinction vital for understanding the new direction. The team identified significant drawbacks in traditional vector quantization:
- It demands a discrete vocabulary and complex objective functions, making training sensitive to gradient approximations.
- Quantization errors introduce information loss, degrading reconstruction quality.
- Discrete tokens restrict expressive power by forcing categorical distributions.
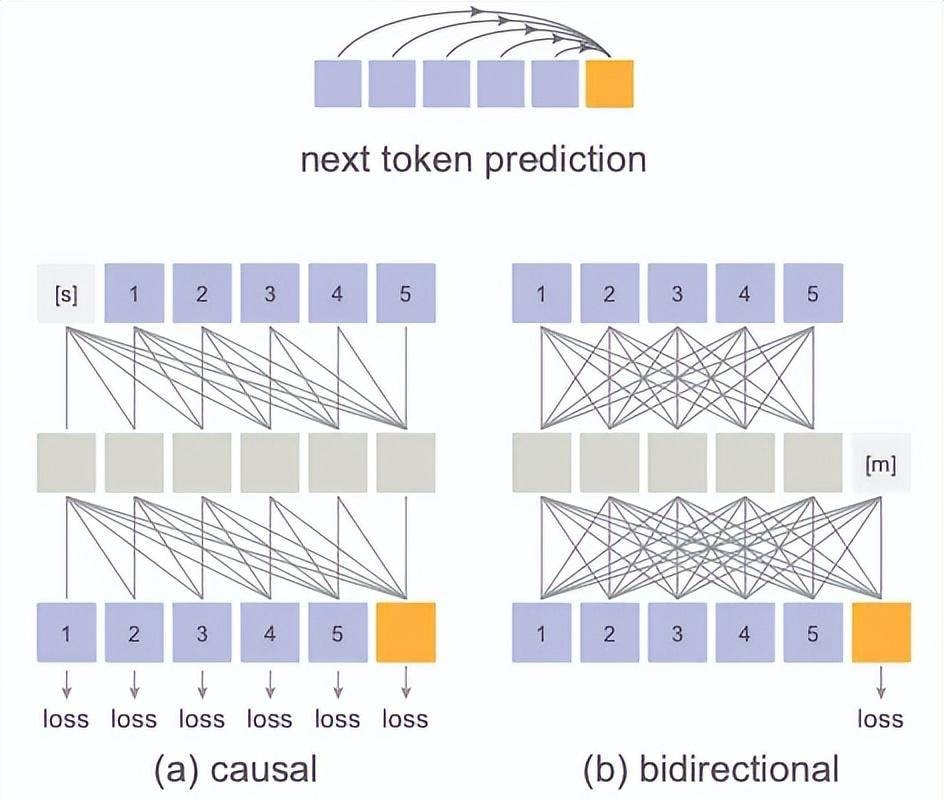
To solve this, the team introduced Diffusion Loss. Inspired by diffusion models, this approach eliminates discrete tokenizers entirely. I read this as a move to apply autoregressive principles directly to continuous value spaces for image generation.

Technically, the autoregressive model outputs a latent variable $z$ to condition a small denoising MLP network. Through reverse diffusion, this network learns to sample continuous value tokens $x$ from $z$. This process naturally models complex distributions, bypassing categorical limitations. The denoising network and autoregressive model are trained end-to-end. I noted that the chain rule propagates loss back to the autoregressive model, optimizing it to output the best conditional $z$.
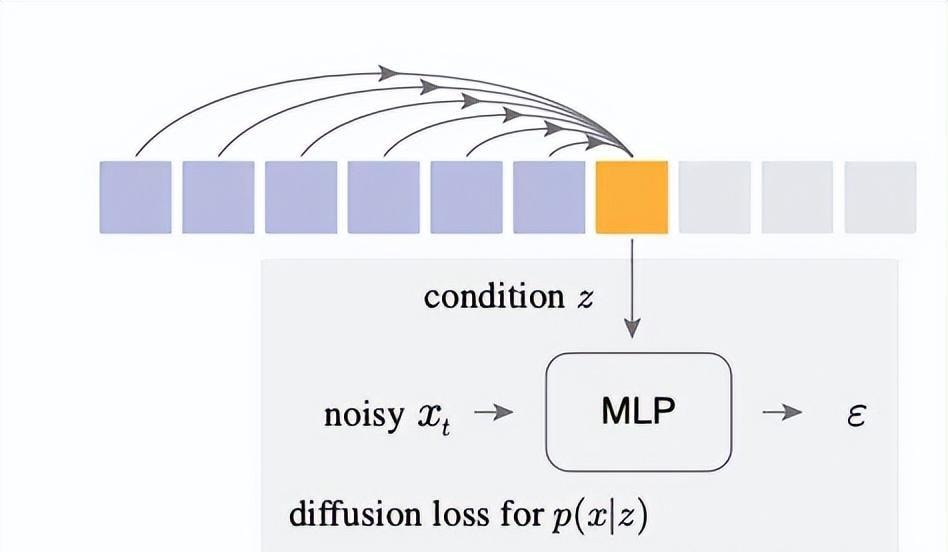
This framework unifies various autoregressive variants. It works with standard Autoregressive (AR), randomly ordered AR, and the Masked Auto-Regressive (MAR) method favored by He. MAR can predict multiple tokens simultaneously at random positions while integrating seamlessly with diffusion loss. I see this as a generalized autoregressive model where all variants predict unknown tokens based on known ones.
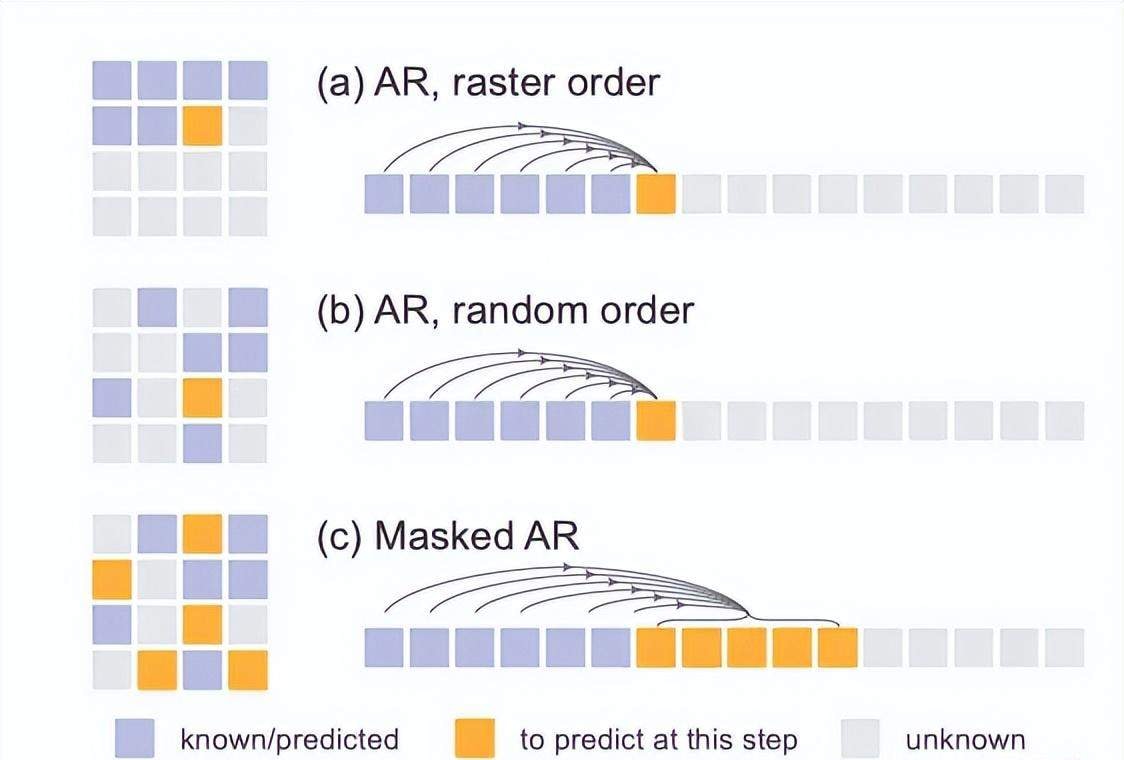
By removing vector quantization, the team achieved powerful results with sequence modeling speed. I reviewed their extensive experiments on AR and MAR variants. The data shows diffusion loss provides a stable 2-3x improvement over cross-entropy loss. Small models hit an FID score of 1.98, while large models set a new State-of-the-Art (SOTA) record of 1.55.
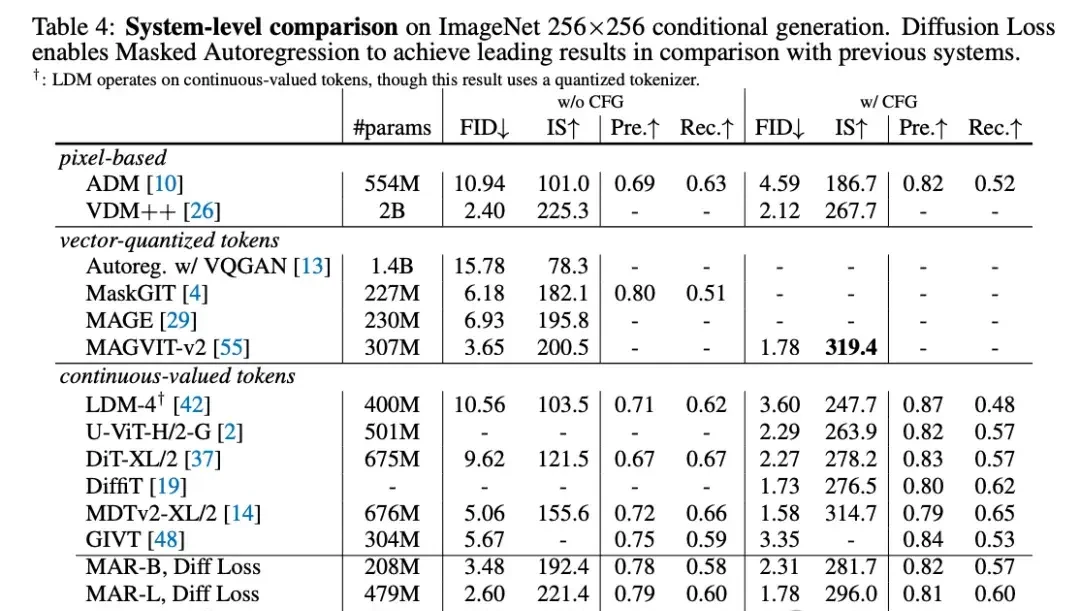
The generation speed is notable: 256×256 images are produced in less than 0.3 seconds per image. This efficiency stems from autoregressive sampling steps being far fewer than diffusion models, combined with a small denoising network. I consider this performance metric critical for enterprise deployment considerations.
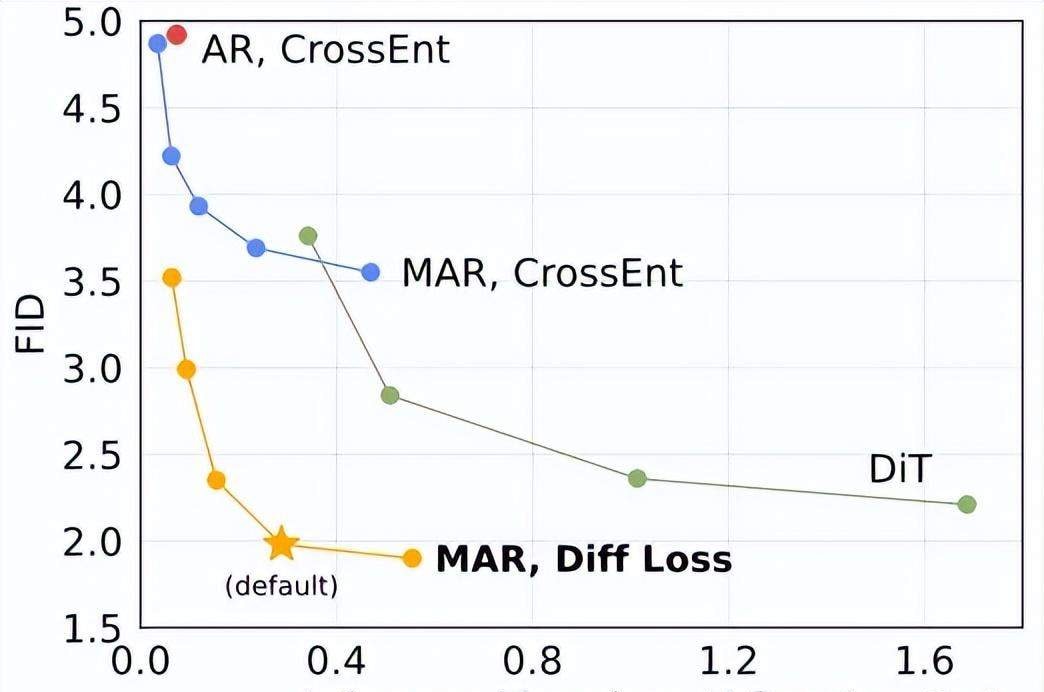
I read the latest developments from Kaiming He’s new initiative at MIT, and what stands out is the structural shift in how we approach token modeling. This project marks his first team leadership role here, bringing together high-caliber talent like double Olympiad gold medalist Mingyang Deng. I followed the release notes closely to understand how this architecture diverges from current industry standards.
The core innovation lies in how the system handles data relationships. To summarize, this work models the correlations between tokens via autoregression and pairs it with a diffusion process to model the distribution of each token. This differs from standard latent space diffusion models that use a single large diffusion model to model the joint distribution of all tokens. Instead, it performs local diffusion, demonstrating significant potential in terms of effect, speed, and flexibility.
My sense is local diffusion reduces computational overhead compared to monolithic joint modeling. What concerns me is that enterprises should verify if this hybrid approach scales for enterprise-grade latency requirements. I think the inclusion of Olympiad-level talent suggests a focus on mathematical rigor over quick hacks.
Of course, there is still room for further exploration with this method. The team notes that performance on certain complex geometric understanding tasks needs improvement. I see this as a critical governance checkpoint; if the model struggles with spatial reasoning, it may not yet be safe for high-stakes applications requiring precise structural accuracy.
Who Is in Kaiming He’s Team?
I followed the announcements regarding Kaiming He’s new research group at MIT, and I see he is assembling a formidable team. The burden of proof for innovation now shifts to these researchers as they join his lab.
Tianhong Li, an alumnus of Tsinghua University’s Yao Class and a current MIT PhD student, will join Kaiming He’s group in September 2024 as a postdoctoral researcher.

Mingyang Deng, currently an undergraduate majoring in Mathematics and Computer Science at MIT.
He won a gold medal at the IMO in his freshman year of high school and a gold medal at the IOI in his senior year. He is one of the few double gold medalists in the competition community and was the third person in IOI history to achieve a perfect score.
Mingyang Deng’s current research focus is machine learning, particularly understanding and advancing generative foundation models, including diffusion models and large language models.
However, his personal website does not yet reveal his next steps.
My sense is elite talent concentration raises the bar for peer review standards. What concerns me is that we must verify if academic accolades translate to industrial-grade reliability. I think enterprises should watch how these researchers handle data governance in new models.
One More Thing
Kaiming He’s job talk at MIT attracted significant attention. I noted that he mentioned his future work direction would be AI for Science, sparking heated discussions within the industry.

Now, Kaiming He’s first paper in the AI for Science (AI4S) direction has arrived: Reinforcement Learning + Quantum Physics.
Applying Transformer models to dynamic heterogeneous quantum resource scheduling problems, utilizing self-attention mechanisms to process sequence information of qubit pairs. They trained reinforcement learning agents in a probabilistic environment to provide dynamic, real-time scheduling guidance, ultimately significantly improving quantum system performance—more than three times better than rule-based methods.

In this way, Kaiming He has not neglected either his renowned field of Computer Vision or his exploration of new domains such as AI for Science. Two flowers blooming simultaneously.
My sense is cross-domain AI requires strict validation against physical laws. I urge enterprises to audit these models for safety before deployment.
Paper:
https://arxiv.org/abs/2406.11838
Kaiming He’s New AI Generation Project: First Team Leadership at MIT, Featuring Double Olympiad Gold Medalist Mingyang Deng
References
I have reviewed these sources to verify the technical claims and team credentials mentioned in this report.
- Tianhong Li
- Mingyang Deng — lambertae.github.io/
- Dynamic Inhomogeneous Quantum Resource Scheduling with Reinforcement Learning — A central challenge in quantum information science and technology is achieving real-time estimation and feedforward control of quantum systems. This challenge is compounded by the inherent inhomogeneity of quantum resources.
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google