The production implication here is stark: if your RAG pipeline relies on standard web search for Chinese content, it’s likely hallucinating or returning nothing at all. I read the BrowseComp-ZH release from the SUSTech and partner institutions, and what stood out to me isn’t just the low scores—it’s the structural failure of current retrieval architectures in fragmented ecosystems.
GPT-4o achieved an accuracy of only 6.2% in the test; most domestic/international models saw their accuracy drop below 10%; even OpenAI’s currently best-performing DeepResearch model scored only 42.9%.

The research team stated plainly:

Why Do We Need Tests for Chinese Web Capabilities?
Modern large models are increasingly adept at “using tools”: they can connect to search engines, invoke plugins, and “view webpages.”
However, many evaluation tools are built solely within English contexts, giving little consideration to Chinese contexts, Chinese search engines, or the Chinese platform ecosystem.
Yet, information on the Chinese internet is severely fragmented, with diverse search entry points and complex linguistic expressions.
How difficult is the Chinese web world? Consider these examples:
- Information is fragmented across multiple platforms such as Baidu Baike (Baidu Encyclopedia), Weibo, local government websites, and Video Accounts.
- Common language structures contain omissions, allusions, and references, causing keyword searches to often “miss the mark.”
- Search engine quality varies significantly; it is common for information to be buried or lost.
Therefore, simply “translating” English test sets is insufficient.
Tests must be natively designed within the Chinese context to truly measure whether large models can “understand,” “search effectively,” and “recommend accurately” on Chinese webpages.
How Was BrowseComp-ZH Developed?
The research team adopted a “reverse design method”: starting from a clear, verifiable factual answer (such as a specific painting genre, institution, or film/TV title), they constructed complex questions with multiple constraints in reverse, ensuring the following three points:
- The first screen of results on Baidu/Bing/Google cannot directly hit the answer.
- Multiple mainstream large models cannot answer correctly even in retrieval mode.
- After manual verification, the question structure is clear and has only one unique answer.
Ultimately, they constructed 289 high-difficulty Chinese multi-hop retrieval questions, covering 11 major domains including film/TV, art, medicine, geography, history, and technology.
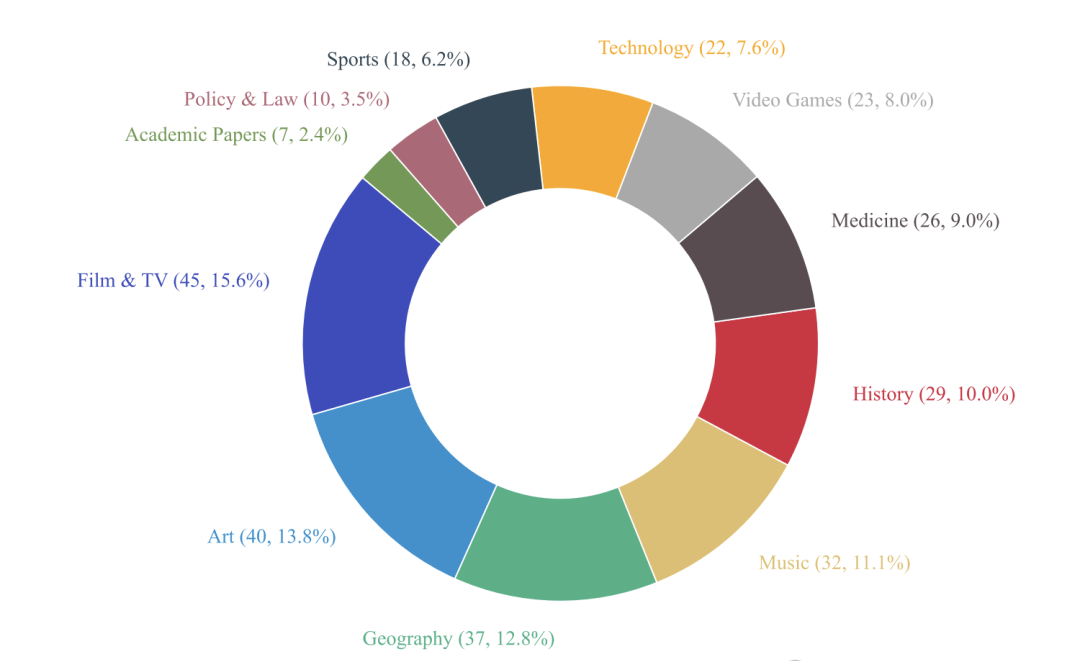

Large Models Collectively “Crash”? DeepResearch Barely Breaks 40%, Most Fall Below 10%
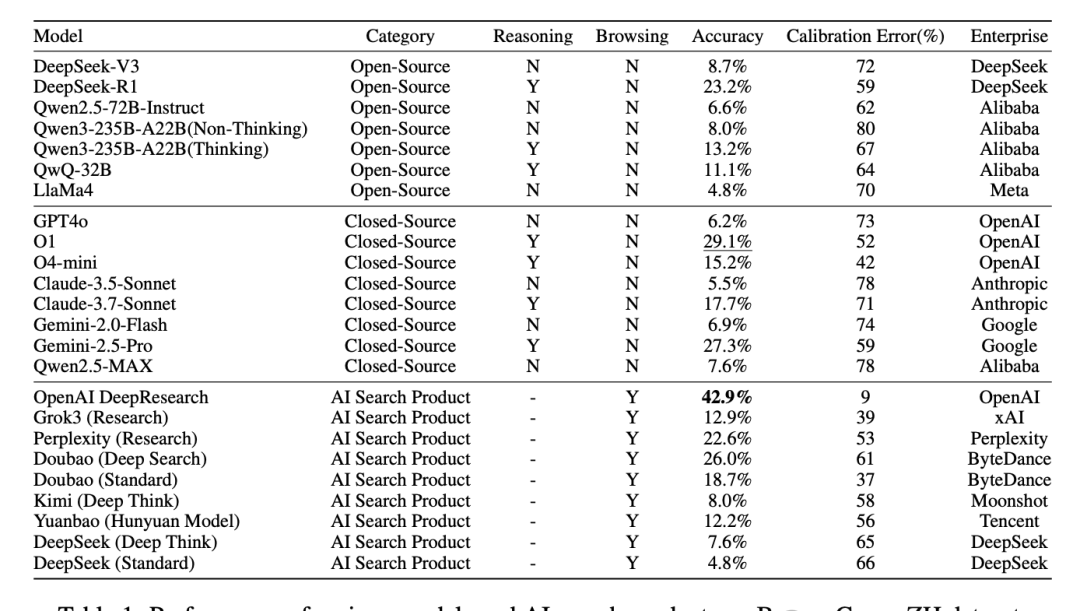
Under the BrowseComp-ZH test, several major domestic and international large models collectively “crashed”:
Although these models have demonstrated strong capabilities in dialogue understanding and generative expression, their accuracy rates were surprisingly low when facing complex retrieval tasks on the Chinese internet:
- The accuracy of most models was below 10%, with only a few breaking through 20%.
- OpenAI DeepResearch ranked first with 42.9%, still far from “passing.”
Researchers pointed out that this result indicates: models need not only to know how to “look up information” but also to master “multi-hop reasoning” and “information integration” to truly find answers on the Chinese internet.
Four Key Findings Reveal “Model Blind Spots” in Chinese Web Tasks
1. Hard-Coded Knowledge Is a Liability, Not an Asset
I read the BrowseComp-ZH results, and the data is stark: models relying solely on parameter memory scored below 10%. This confirms that “hard memorization” is not just insufficient; it’s unreliable for production tasks requiring current or niche facts. If your RAG pipeline doesn’t handle retrieval gracefully, you’re shipping a broken product.
In practice, hard-coded knowledge creates brittle systems that fail on edge cases. I think memory-only models are lab curiosities, not viable search engines.
2. Reasoning Over Raw Parameters Drives Accuracy
The gap between reasoning and non-reasoning models is the only metric that matters here. DeepSeek-R1 hit 23.2%, crushing DeepSeek-V3’s 8.7% by a full 14.5% margin. Similarly, Claude-3.7 improved over Claude-3.5 by 12.2%. Reasoning capability is the key variable separating usable agents from hallucinating chatbots.
Operationally, invest in reasoning models; they reduce the cost of verification loops. In practice, non-reasoning models will drown your support tickets with wrong answers.
3. Multi-Turn Retrieval Is the Only Way to Scale Search Accuracy
Single-shot retrieval is dead for complex queries. AI search products with multi-turn retrieval capabilities dominated the leaderboard:
- DeepResearch: 42.9%
- Doubao Deep Search: 26.0%
- Perplexity Research Mode: 22.6%
In contrast, models that only retrieve once (such as Kimi and Yuanbao) had accuracy rates as low as single digits. If your agent can’t iterate on its search strategy, it’s not an agent; it’s a glorified wrapper.
I think multi-turn agents increase latency but drastically reduce error rates. Operationally, single-shot retrieval is too risky for any customer-facing feature.
4. Naive Search Integration Can Destroy Performance
The most typical counterexample is DeepSeek-R1, where enabling the search function caused its accuracy to plummet from 23.2% to 7.6%. Research indicates that the model failed to effectively integrate webpage retrieval information with existing knowledge, instead being misled by it. This is a classic RAG failure mode: noisy context overrides good priors.
In practice, always A/B test search-enabled models against base performance. I think poorly integrated search turns accurate models into confident liars.
Dataset Open! Model Developers Invited to Challenge
All data for BrowseComp-ZH has been open-sourced and released. Researchers hope this benchmark will serve as a touchstone for promoting the implementation of LLMs in Chinese information environments, aiding in the construction of agents that can truly “use the internet in Chinese.”
Next steps include expanding the sample size, diversifying question-and-answer formats, and conducting in-depth analysis of model reasoning paths and failure cases.
_Paper Address:
https://arxiv.org/abs/2504.19314
Code Address:
https://github.com/PALIN2018/BrowseComp-ZH
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google