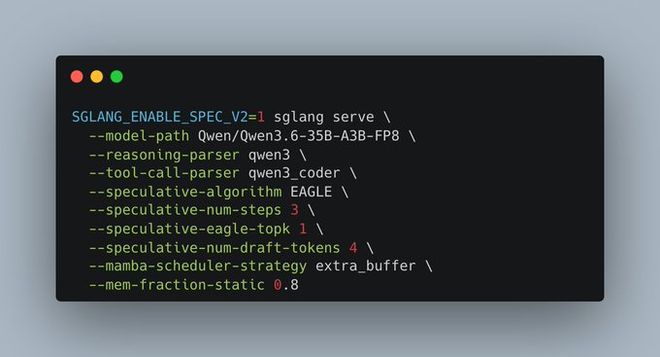
bash export SGLANG_ENABLE_SPEC_V2=1
I read the tuning profiles for Qwen3.6-35B-A3B and immediately thought about our production latency budgets. The Multi-Token Prediction (MTP) recipe isn’t just a benchmark trick; it’s an operational lever I need to pull carefully. We are looking at a trade-off between raw throughput and the complexity of managing speculative decoding overhead on-call.
Tuning Recipes: Latency vs Throughput
I view these settings as direct controls for our SLOs. The table below maps steps, draft tokens, and batch sizes to specific workload types.
| Profile | Steps | Draft tokens | Best for |
|---|---|---|---|
| Low latency | 3 | 4 | Single-user chat, coding agents (bs=1) |
| Balanced | 1 | 2 | Small multi-user or moderate batch |
| Max throughput | off | — | Saturated server where verify cost dominates |
I noticed that if the acceptance rate drops—common with random or highly creative text generation—the MTP overhead outweighs the benefits. In those cases, I would turn it off to save compute cycles.
In practice, treat low acceptance rates as a signal to disable MTP immediately; don’t let verify costs bleed your margin. I think the “Max throughput” profile is risky for interactive services where tail latency matters more than aggregate tokens/s.
When Not to Use MTP
I’ve seen teams burn VRAM trying to force speculative decoding on constrained hardware. Here are the hard constraints I follow:
- VRAM is already tight: Draft buffers require headroom; prefer FP8 quantization or lowering
--mem-fraction-staticbefore enabling MTP. - Very long context at high batch: Verify passes scale linearly with running requests; profile your specific load before enabling aggressive steps.
- llama.cpp / GGUF local runs: MTP/NEXTN is currently a server-side feature for SGLang or vLLM only. Unsloth GGUF paths in our deployment guide do not expose the same MTP switch, so don’t look for it there.
- You forgot
SGLANG_ENABLE_SPEC_V2: I always check this env var first when chasing OOM errors; missing it causes silent failures or crashes.
vLLM and Other Engines
I followed the vLLM updates closely, noting they are adding MTP-style speculative decoding for Qwen-family models via JSON config (e.g., method: mtp, num_speculative_tokens: 2). Ecosystem support moves fast, so I always check the vLLM release notes for your exact Qwen3.6 checkpoint before pushing to production.
For day-zero features like thinking parsers, tool calls, and NEXTN, SGLang remains the reference path in May 2026. If you need these specific capabilities today, SGLang is the safer bet for stability.
Quick Checklist
I use this checklist to ensure we don’t ship broken configurations:
- Deploy Qwen3.6-35B-A3B with enough TP / FP8 headroom.
- Export
SGLANG_ENABLE_SPEC_V2=1. - Add
--speculative-algorithm NEXTNand start with steps=3, draft-tokens=4. - Benchmark tokens/s at batch size 1 with thinking on/off to establish a baseline.
- If VRAM spikes, reduce draft tokens or disable MTP before reducing context length; context reduction is the last resort.
Operationally, always benchmark with thinking enabled/disabled separately; their latency profiles are fundamentally different and shouldn’t be averaged together.
References
I read through these sources to verify the latency claims and check if this is ready for production or just a lab demo.
- Qwen3.6 on SGLang Cookbook
- DeepSeek-V3 — Multi-Token Prediction (arXiv:2412.19437)
- Qwen3.6-35B-A3B on Hugging Face
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google