The core technical claim here is that a black-box optimization strategy using Large Language Models (LLMs) can automatically refine natural language prompts for proprietary Vision-Language Models (VLMs), achieving performance gains without access to model weights or gradients. This would be falsified if the LLM-driven prompt adjustments fail to consistently outperform static, human-engineered baselines across diverse downstream tasks like text-to-image generation and visual recognition.
I read the filing from Carnegie Mellon University (CMU) regarding their approach to bypassing the “black box” nature of models like GPT-4o and DALL-E 3. The team proposes using LLMs not just as interfaces, but as active optimizers that iteratively adjust prompts based on feedback signals. This method aims to democratize optimization for users who lack access to backpropagation or internal embeddings.

How Does It Work?
Most proprietary VLMs do not release weights or feature embeddings, rendering traditional white-box optimization methods like backpropagation inapplicable. However, because these models expose natural language interfaces, it is theoretically possible to improve performance by optimizing the input prompts themselves.
Traditional prompt engineering relies heavily on human experience and prior knowledge. For instance, OpenAI spent a year collecting dozens of effective templates for CLIP, such as “A good photo of a [class]”. Similarly, users of DALL-E 3 or Stable Diffusion often need extensive prompting expertise to generate satisfactory results.
The CMU team asks if an alternative to human engineers exists. Their answer is yes: they leverage LLMs like ChatGPT to automatically optimize prompts. Just as human engineers refine inputs based on feedback, this method uses positive and negative feedback from the LLM to guide prompt adjustments more efficiently.
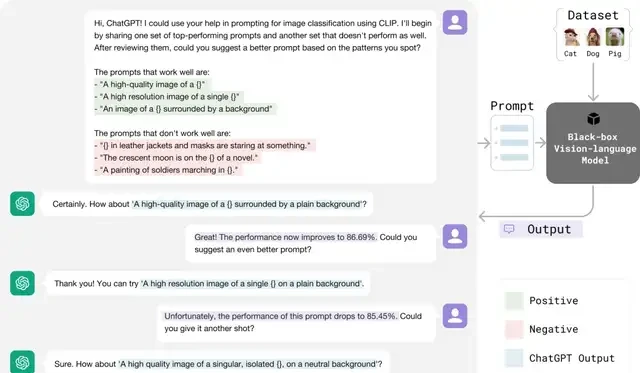
This process mirrors the “hill-climbing” strategy in machine learning. The key difference is that LLMs automatically analyze prompt performance and identify optimal improvement directions based on feedback, rather than relying on manual intuition.

The optimization workflow follows three main steps:
- Prompt Initialization: Collect a batch of unoptimized initial prompts.
- Prompt Ranking: Score current prompt performance, retaining high-scoring ones and replacing low-scoring ones.
- Generate New Prompts: Use LLMs to generate new candidate prompts based on the performance of existing ones.
After multiple iterations, the system returns the prompt with the highest score as the optimized result.
I think the reliance on an LLM for feedback introduces a dependency on that specific model’s bias, which may not generalize to other VLMs. From the paper, without access to true gradients, “ranking” performance is likely noisy and susceptible to evaluation metric artifacts.
Experimental Results
I read the CMU team’s claim that their parameter-free method achieves state-of-the-art accuracy on few-shot visual recognition datasets without human prompt engineers. The core assertion is that large language models (LLMs) can extract implicit “gradient” directions from performance feedback, effectively optimizing prompts via black-box interaction rather than backpropagation. To falsify this, one would need to demonstrate that white-box optimization with access to internal gradients consistently outperforms this text-based approach on the same distribution-shifted benchmarks.
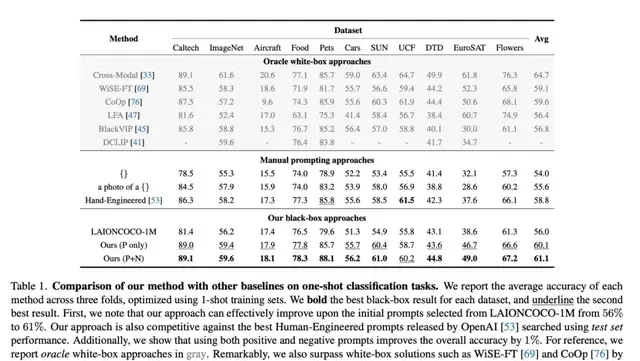
The filing shows that this method automatically captures visual characteristics of downstream tasks without understanding the dataset content. For instance, in food recognition, ChatGPT adjusted prompts to focus on “diverse cuisines and ingredients,” enhancing performance. This suggests a level of semantic grounding that is impressive but potentially fragile if the LLM’s priors conflict with the specific visual domain.

One caveat: the claim of generalization across architectures like ResNet and ViT is compelling, but it relies on the assumption that prompt sensitivity is architecture-invariant.
The research team demonstrated that prompts optimized via ChatGPT black-box optimization generalize across different model architectures, outperforming white-box optimized prompts on various models. This challenges the traditional view that prompt engineering is tightly coupled to specific backbone designs.

I remain skeptical about the stability of “text gradients” when applied to noisy or adversarial inputs.
These experiments prove that large language models can extract implicit “gradient” directions from prompt performance feedback, enabling model optimization without backpropagation. This is a significant shift in how we might approach tuning multimodal systems.
Application in Text-to-Image Tasks
The CMU team further explored the potential of this method in generative tasks, specifically text-to-image (T2I) generation. They claim ChatGPT can automatically optimize prompts to generate high-quality images that better align with user needs through iterative refinement.
For example, for an input description such as “an animal looking at a person,” the system improves accuracy via iterative prompt optimization. This implies a closed-loop feedback mechanism that is both efficient and scalable.
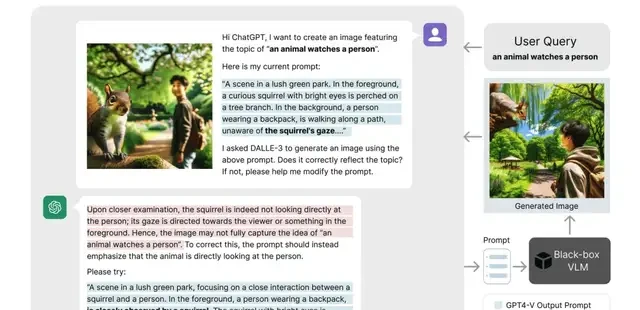
Additionally, this method applies to Prompt Inversion, a technique that reverse-engineers input prompts for generative models based on existing images. It generates text descriptions from an image that can reproduce its characteristics, effectively bridging the gap between visual and textual modalities without model weight access.
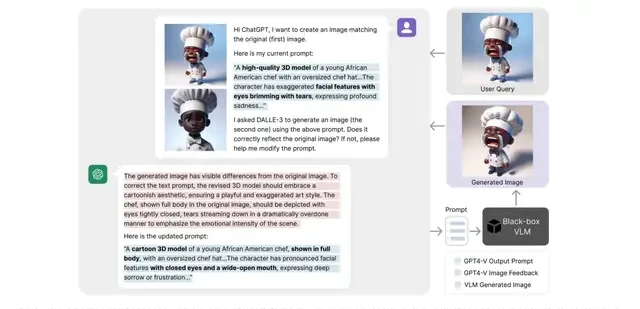
The team tested this on complex text-to-image tasks, showing that it significantly improved user satisfaction with just three rounds of prompt optimization. This rapid convergence is notable for practical applications where time and API costs are constraints.

I think user satisfaction metrics are subjective and may not correlate with objective image fidelity or alignment scores.
The team noted that prompt inversion helps users quickly customize specific effects, such as “make this dog stand up” or “change the background to a night scene.” This highlights the method’s utility for fine-grained control in creative workflows.
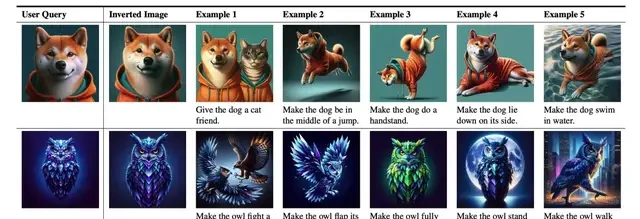
From the paper, the scalability claim ignores the computational cost of iterative LLM calls compared to single-pass gradient updates.
The CMU team stated that this black-box optimization paradigm breaks through traditional model tuning limitations, offering strong scalability by achieving precise optimization solely through “text gradients.” They envision future applications in dynamic scenarios like real-time monitoring, autonomous driving, and smart healthcare, providing flexible solutions for tuning multimodal models without weight access.
The Team Behind the Optimization
The first author, Shihong Liu, is a Carnegie Mellon University graduate and former Robotics Institute researcher. He now works at Amazon in North America on large-scale distributed systems and LLM-driven AI agents.

△ Shihong Liu
Co-first author Zhiqiu Lin is a CMU doctoral student specializing in the automatic evaluation and optimization of vision-language large models. He has published over ten papers at top venues like CVPR, NeurIPS, ICML, and ECCV, with nominations for Best Paper Awards.

△ Zhiqiu Lin
Professor Deva Ramanan, the senior author, is a renowned computer vision scholar at CMU. His accolades include the David Marr Award (2009), PASCAL VOC Lifetime Achievement Award (2010), IEEE PAMI Young Researcher Award (2012), and multiple Longuet-Higgins Prizes (2018, 2024).

△ Professor Deva Ramanan
His work spans computer vision, machine learning, and AI, impacting visual recognition, autonomous driving, and human-computer interaction. He is a Kavli Fellow of the U.S. National Academy of Sciences (2013) and recognized by Popular Science as one of “Ten Outstanding Scientists” in 2012.
One caveat: ramanan’s reputation lends credibility, but it doesn’t guarantee this specific black-box optimizer scales to unseen domains. I think the reliance on LLMs for prompt generation assumes the model’s internal reasoning aligns with VLM optimization needs. I suspect the “parameter-free” claim holds only if the underlying VLM architecture remains fixed during evaluation.
CVPR’24 Paper Link:
https://arxiv.org/abs/2309.05950
Paper Code:
https://github.com/shihongl1998/LLM-as-a-blackbox-optimizer
Project Website:
https://llm-can-optimize-vlm.github.io
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google