Stanford Clinical AI Benchmark: DeepSeek Outperforms Google and OpenAI
When a Chinese model tops a US-led clinical benchmark, it signals that the Asia-Pacific region is no longer just consuming Western AI infrastructure—it is defining its own standards for high-stakes medical reasoning. This shift ripples directly into global supply chains for healthcare IT and regulatory compliance frameworks across APAC markets.
Stanford’s latest comprehensive evaluation of large language models reveals a surprising hierarchy: DeepSeek R1 takes first place with a 66% win rate!
The results stunned international observers, primarily because this assessment focuses on the daily work scenarios of clinical doctors, rather than being limited to traditional medical licensing exam questions. This distinction is critical for understanding real-world utility versus theoretical knowledge.
To conduct a proper evaluation, the methodology had to be comprehensive in all aspects.
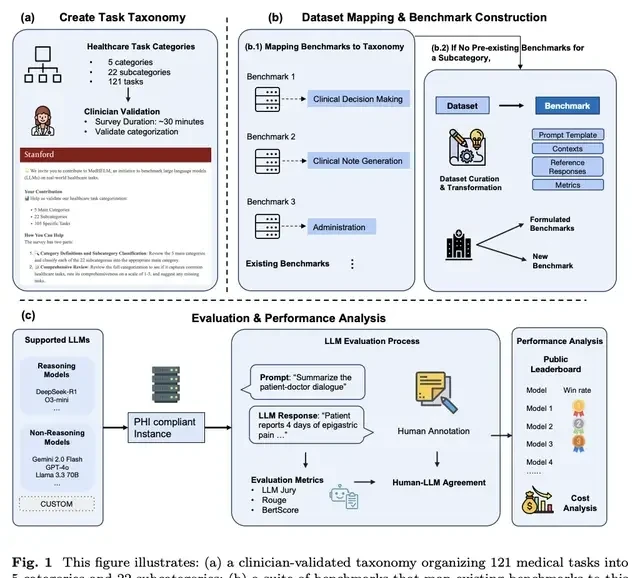
The team constructed MedHELM, a comprehensive evaluation framework containing 35 benchmark tests that cover medical tasks across 22 subcategories. This granularity allows for a more nuanced assessment of model capabilities than single-score metrics often provide.
This classification system was validated by clinicians and developed with the participation of 29 licensed physicians from 14 medical specialties, ensuring clinical relevance over pure data science optimization.
The author list is extensive, including researchers from Stanford University School of Medicine, Stanford Health Care, the Stanford Center for Research on Foundation Models (CRFM), and Microsoft. This collaboration highlights the ongoing tension between academic rigor and corporate resource allocation in AI safety research.

The 31-page paper concludes that among nine cutting-edge large models, including DeepSeek R1, o3-mini, and Claude 3.7 Sonnet, DeepSeek R1 leads with a 66% win rate and a macro-average score of 0.75.
For the current benchmark results, the team has also created a publicly accessible leaderboard to encourage transparency in model performance claims.
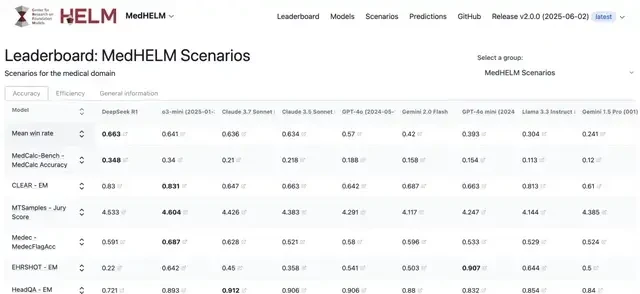
In addition to DeepSeek R1 leading the pack, o3-mini follows closely with a 64% win rate and the highest macro-average score of 0.77; Claude 3.5 and 3.7 Sonnet achieved win rates of 63% and 64%, respectively. The margin between these top-tier models is negligible, suggesting that architectural differences matter less than fine-tuning strategies in clinical contexts.
After reviewing the specific research, netizens expressed that these evaluations are very helpful for distinguishing marketing hype from actual diagnostic support capabilities.

Let’s look at more details below.
The Clinical Gauntlet: How MedHELM Tests Real-World Readiness
The results from Stanford’s latest clinical benchmark ripple beyond Silicon Valley, signaling that US tech giants are facing stiff competition for global healthcare contracts. I think this suggests the era of unchecked AI dominance in medical diagnostics is ending faster than anticipated.
I followed the release of MedHELM, a comprehensive evaluation framework named after Stanford’s previous HELM project but tailored specifically for clinical workflows. The study’s core contribution lies in its clinician-validated classification system, which mirrors the actual logic used by doctors on duty.
The system operates across three hierarchical levels to capture the nuance of medical practice:
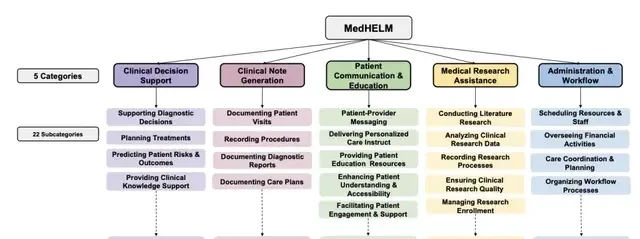
- Category: Broad domains, such as “Clinical Decision Support.”
- Subcategory: Related task groups, like “Supporting Diagnostic Decisions.”
- Task: Discrete operations, for example, “Generating Differential Diagnoses.”
Initially, clinicians reorganized tasks from a Journal of the American Medical Association (JAMA) review into functional themes. This created an initial framework of 5 categories, 21 subcategories, and 98 tasks. However, validation revealed gaps. Twenty-nine practicing clinicians from 14 specialties surveyed the system for logical consistency and comprehensiveness.
Based on their feedback, the team expanded the framework to 5 categories, 22 subcategories, and 121 tasks. This final structure covers clinical decision support, case generation, patient communication, research assistance, and workflow management. Notably, 26 clinicians reached a 96.7% agreement rate on these subcategory classifications.
The second major innovation is the evaluation suite itself, built upon this classification system. It contains 35 benchmark tests, comprising:
- 17 existing benchmarks
- 5 benchmarks reconstructed from existing datasets
- 13 newly developed benchmarks
What stood out to me was that 12 of the 13 new benchmarks utilize real-world Electronic Health Record (EHR) data. This directly addresses the critical shortage of authentic medical data in previous AI evaluations. The suite covers all 22 subcategories, with access levels determined by data sensitivity: 14 public tests, 7 requiring approval, and 14 private datasets.
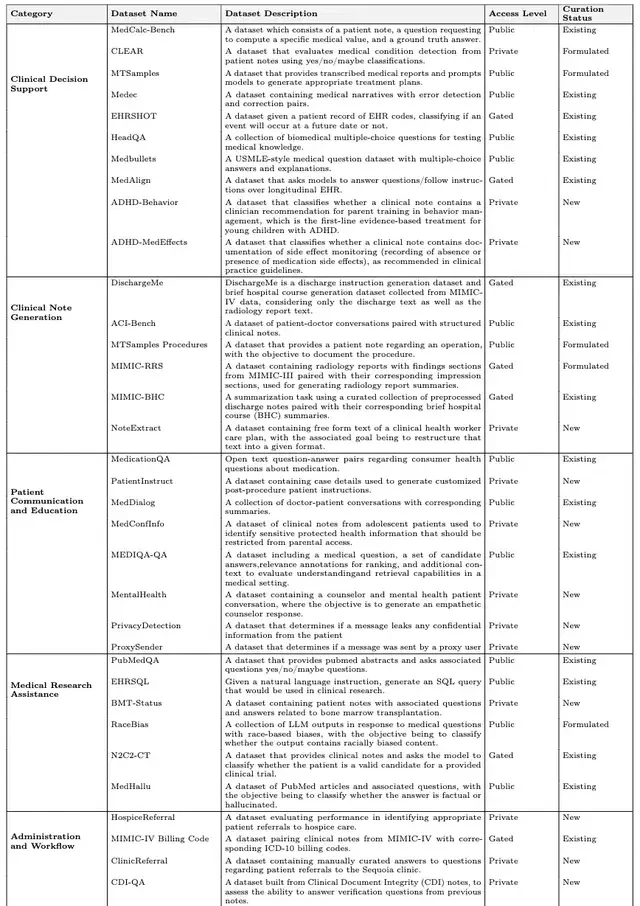
With the exam questions prepared, the research team systematically evaluated nine cutting-edge large language models. From an APAC angle, real-world EHR data is a scarce resource; controlling it may become as strategic as controlling semiconductor fabrication capacity.
How Did the Evaluation Results Turn Out?
The evaluation revealed significant differences in model performance. I followed the release closely to understand how these metrics translate into real-world utility for healthcare providers across Asia-Pacific and beyond.
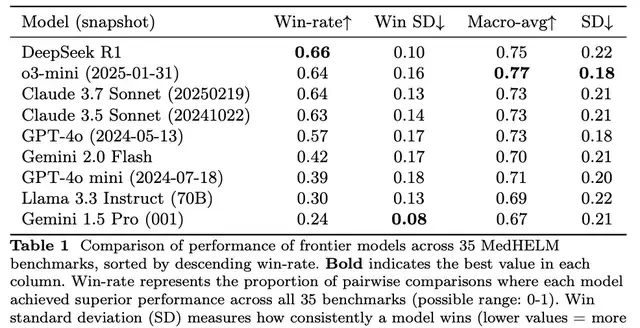
DeepSeek R1 performed best, leading with a 66% win rate in pairwise comparisons, achieving a macro-average score of 0.75 and a low standard deviation for win rates (0.10).
Here, the “win rate” refers to the proportion of times a model outperformed others across all 35 benchmark tests in pairwise comparisons. The “standard deviation of win rates” measures the stability of the model’s victories (lower value = higher stability). The macro-average score is the average performance score across all 35 benchmarks. The standard deviation reflects fluctuations in model performance across different benchmarks (lower value = higher consistency across benchmarks).
o3-mini followed closely, performing particularly well in clinical decision support benchmarks, ranking second with a 64% win rate and the highest macro-average score of 0.77.
Claude 3.7 Sonnet and 3.5 Sonnet achieved win rates of 64% and 63%, respectively, both with a macro-average score of 0.73; GPT-4o had a win rate of 57%; Gemini 2.0 Flash and GPT-4o mini had lower win rates of 42% and 39%, respectively.
Additionally, the open-source model Llama 3.3 Instruct had a win rate of 30%; Gemini 1.5 Pro ranked last with a 24% win rate, but it exhibited the lowest standard deviation in win rates (0.08), indicating the most stable competitive performance.
The team also presented a heatmap showing each model’s standardized scores across the 35 benchmarks, where dark green indicates higher performance and dark red indicates lower performance.
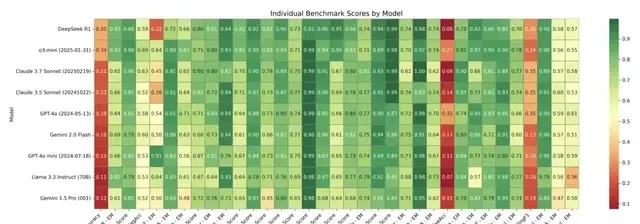
The results show that models performed poorly in the following benchmarks:
- MedCalc-Bench (calculating medical values from patient records)
- EHRSQL (generating SQL queries for clinical research based on natural language instructions—originally designed as a code generation dataset)
- MIMIC-IV Billing Code (assigning ICD-10 codes to clinical cases)
They performed best in the NoteExtract benchmark (extracting specific information from clinical records).
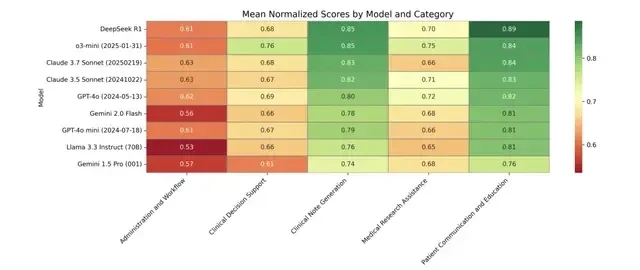
Deeper analysis revealed distinct hierarchical differences in model performance across different task categories.
In clinical case generation tasks, most models achieved high scores ranging from 0.74 to 0.85; they also performed excellently in patient communication and education tasks, with scores between 0.76 and 0.89. Performance was moderate in medical research assistance (0.65–0.75) and clinical decision support (0.61–0.76), while scores were generally lower in management and workflow (0.53–0.63).
This difference reflects that free-text generation tasks (such as clinical case generation and patient communication) are better suited to leverage the natural language advantages of large language models, whereas structured reasoning tasks require stronger domain-specific knowledge integration and logical reasoning capabilities.
For the 13 open-ended benchmarks, the team adopted an LLM-jury evaluation method.
To assess the effectiveness of this method, the team collected independent ratings from clinicians on some model outputs. Specifically, they selected 31 instances from ACI-Bench and 25 from MEDIQA-QA to compare clinician scores with the jury’s composite scores.

The results showed that the LLM-jury method achieved an intraclass correlation coefficient (ICC) of 0.47 with clinician scores. This not only exceeded the average consistency among clinicians themselves (ICC=0.43) but also significantly outperformed traditional automated evaluation metrics such as ROUGE-L (0.36) and BERTScore-F1 (0.44).
The team concluded that LLM juries reflect clinical judgment better than standard lexical metrics, proving their effectiveness as a substitute for clinician scoring.
Cost-effectiveness analysis was another innovation of this study. Based on public pricing as of May 12, 2025,
Cost Efficiency in Clinical AI: The Claude Advantage
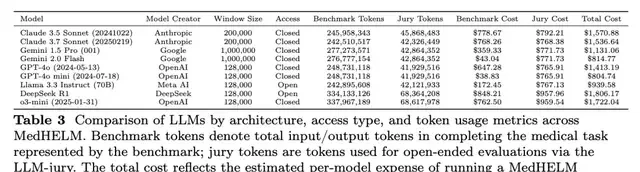
The team estimated the cost required for each model by combining the total input tokens consumed during benchmark execution and the maximum output tokens used in the LLM-jury evaluation process.
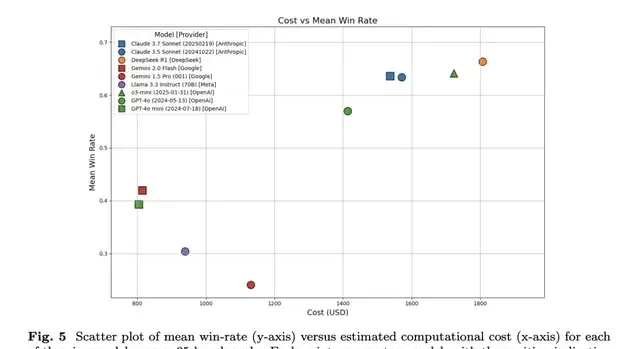
As expected, non-reasoning models GPT-4o mini ($805) and Gemini 2.0 Flash ($815) were cheaper, with win rates of 0.39 and 0.42, respectively.
Reasoning models were more expensive; DeepSeek R1 ($1,806) and o3-mini ($1,722) achieved win rates of 0.66 and 0.64, respectively.
Overall, Claude 3.5 Sonnet ($1,571) and Claude 3.7 Sonnet ($1,537) performed well in terms of cost-effectiveness, achieving a win rate of approximately 0.63 at a lower cost.
Globally, anthropic’s pricing strategy balances performance with accessibility for enterprise healthcare adoption. I think high inference costs remain a barrier for widespread clinical deployment in emerging markets. From an APAC angle, token-based billing models obscure the true operational expense of complex medical reasoning tasks.
Those interested in more details can refer to the original paper.
Paper Link: https://arxiv.org/pdf/2505.23802
Blog Link: https://hai.stanford.edu/news/holistic-evaluation-of-large-language-models-for-medical-applications
Leaderboard Link: https://crfm.stanford.edu/helm/medhelm/latest/#/leaderboard
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google