I read the release notes for Tencent’s new open-source heavyweight, but my eyes are on what actually runs in production versus what looks good in a slide deck. The industry is obsessed with parameter counts, yet unit economics and deployment stability remain the real bottlenecks for embodied AI systems that need to think fast and cheap.
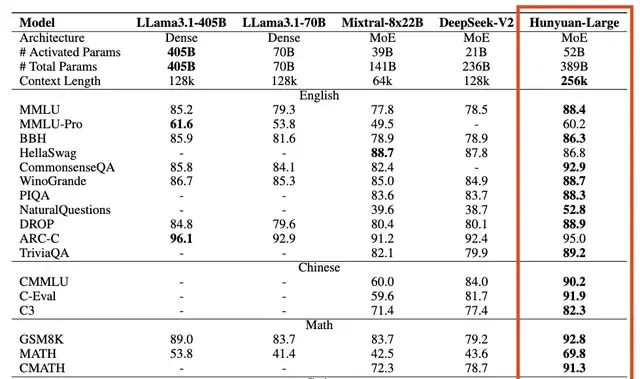
Hunyuan-Large arrives with 389 billion total parameters and only 52 billion activated parameters, positioning it as the largest open-source Mixture of Experts (MoE) model on the market today.
It claims benchmark scores that surpass open-source flagships like Llama 3.1 405B, while supporting a context length one tier higher, reaching 256k tokens.
Although Hunyuan-Large is not yet Tencent’s internal flagship model, the company states that its underlying technology shares the same lineage as the Hunyun large language model:
Many details have been refined through internal business applications before being open-sourced. For example, features such as AI long-document reading in Tencent’s Yuanbao App are derived from this technology.
Releasing a model of this scale completely open-source and free for commercial use demonstrates significant sincerity.

This time, Tencent has open-sourced three versions of Hunyuan-Large: the pre-trained model, the fine-tuned model, and an FP8 quantized fine-tuned model.
The release has sparked heated discussion in the open-source community. Thomas Wolf, Chief Scientist at Hugging Face, strongly recommended it and summarized several key highlights.
- Strong mathematical capabilities
- Extensive use of carefully crafted synthetic data
- In-depth exploration of MoE training, utilizing shared experts and summarizing the Scaling Laws for MoE.
Among developers, some have immediately begun downloading and deploying the model, while others hope that Tencent’s entry into the fray will intensify competition in open-source models, thereby forcing Meta to produce better models.
Tencent simultaneously released a technical report, where many technical details have also drawn discussion.
For instance, it calculates the Scaling Law formula for MoE: C ≈ 9.59ND + 2.3 × 10⁸D.
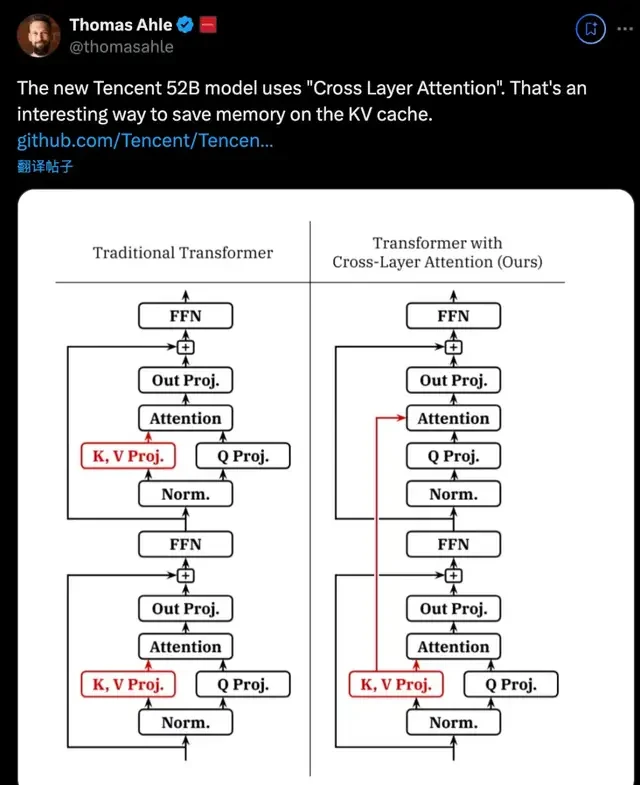
Another example is the use of Cross-Layer Attention (CLA) to reduce KV cache memory usage.
Below is a summary of the highlights from the press conference presentation and the technical report.
I think big numbers don’t fix broken supply chains or unreliable sensors in the real world. I want to see inference costs drop before I trust these scaling laws on hardware. In the field, synthetic data is great until it meets the messy reality of physical deployment.
The Math Behind the Scale
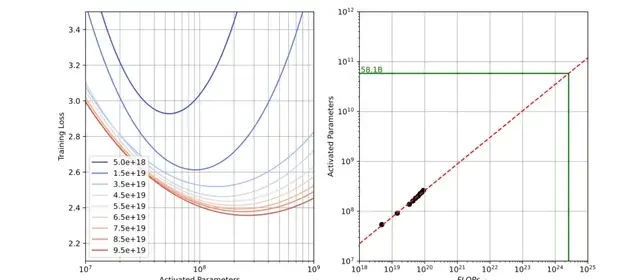
The formula they published is stark: $C \approx 9.59ND + 2.3 \times 10^8D$. It’s not just dense scaling; it’s MoE with a tax. Compared to the traditional $C=6ND$, Tencent bumped the coefficient from 6 to 9.59. That jump accounts for routing overhead—the cost of switching between experts. They also added a constant term, $2.3 \times 10^8D$. This covers attention calculation costs in long-sequence MoE models.
To find the sweet spot, they didn’t guess. They trained models with activated parameters ranging from 10M to 1B. The data volume hit up to 100 billion tokens. Using isoFLOPs curves, they looked for efficiency under a fixed budget. They also factored in real-world batch sizes. The math pointed to an optimal activation of roughly 58.1B parameters.
What I watch for is routing overhead eats margin before the model even sees data. I think a constant term for attention suggests scaling isn’t linear anymore. In the field, 52B activations is a safe buffer, not a performance peak.
Hunyuan-Large settled on 52B activated parameters. The curve near the optimum is smooth, offering tolerance around that 58.1B mark. Practical constraints drove this choice: compute limits and training stability. Deployment efficiency had to balance with raw power.
Routing and Training Strategies
The technical report details Hunyuan-Large’s specific “MoE methodology.” It’s not just about size; it’s about how tokens are handled.
Hybrid Routing Strategy: Hunyuan-Large uses a mix of shared and specialized experts. Each token activates one shared expert and one specialized expert. The shared expert handles general knowledge for all tokens. Specialized experts activate dynamically via top-k routing for task-specific work.
Expert Recycling Routing Strategy: Traditional MoE models often discard too many tokens due to overload. Tencent designed an expert recycling mechanism to fix this. It maintains balanced loads across the network. This ensures training stability and faster convergence. It also helps fully utilize the training data.
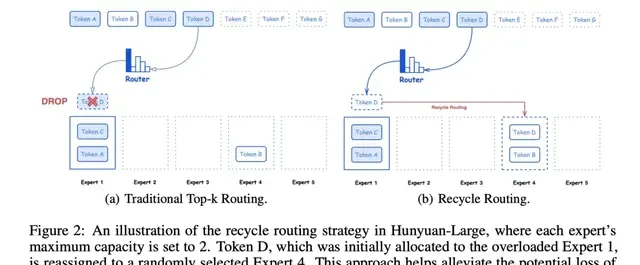
Expert-Specific Learning Rate Adaptation Strategy: Not all experts are created equal. Different experts handle vastly different token counts. Tencent assigns them different learning rates accordingly. Shared experts get larger learning rates. This ensures each sub-model learns effectively from the data. It contributes directly to overall performance rather than stagnating.
Synthetic Data: The Pipeline vs. Reality
The Hunyuan team claims a rigorous four-step synthesis pipeline—generation, evolution, answer creation, and filtering—to fuel their 389B parameter MoE model. I read the release notes carefully to see if this “high-quality” label holds water outside of a controlled lab environment. The process starts with seed data across multiple domains, then evolves instructions for clarity and density before specialized models generate answers. Finally, critique models and self-consistency checks filter the output.
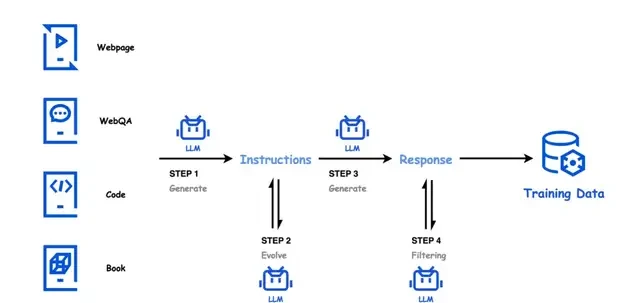
In the instruction generation phase, the team used high-quality data sources as seeds to ensure diversity. Next is the instruction evolution phase, where clarity and information density are improved, low-resource domains expanded, and difficulty gradually increased. In the answer generation phase, specialized models of varying scales generate professional answers for different fields. Finally, in the answer filtering phase, critique models evaluate quality while self-consistency checks ensure high standards.
Through this four-step synthesis process, the Hunyuan team could generate a large volume of high-quality, diverse instruction-answer data pairs, providing rich and premium data support for MoE model training. This data synthesis method not only improved training efficiency but also significantly enhanced model performance across various downstream tasks.
What I watch for is synthetic data often lacks the messy nuance required for robust real-world deployment. I think self-consistency checks are good, but they can reinforce existing biases in the seed data. I want to see how this synthetic training handles edge cases that don’t fit standard templates.
Long-Document Capability: Scaling Context Windows
To achieve powerful long-text processing capabilities, the Hunyuan team adopted several strategies during training, specifically focusing on extending context windows without losing basic proficiency. First is phased training. The first phase processed 32K token texts, while the second phase extended text length to 256K tokens. In each phase, approximately 10 billion tokens of training data were used to ensure the model could fully learn and adapt to texts of different lengths.
Regarding training data selection, 25% consisted of natural long texts, such as books and code, to provide realistic long-text samples; the remaining 75% was standard-length data. This data combination strategy ensured that while acquiring long-text understanding capabilities, the model maintained basic processing abilities for standard-length texts.
Additionally, to better handle positional information in ultra-long sequences, the Hunyuan team optimized position encoding. They adopted RoPE (Rotary Position Embedding) and expanded the base frequency to 1 billion during the 256K token phase. This optimization effectively handles positional information in ultra-long sequences, enhancing the model’s understanding and generation capabilities for long texts.
Beyond evaluation on public datasets, the Hunyuan team developed a long-text evaluation dataset named “Penguin Scroll.” “Penguin Scroll” includes four main tasks: information extraction, information localization, qualitative analysis, and numerical reasoning.

Unlike existing long-text benchmark tests, “Penguin Scroll” offers several advantages:
- Data Diversity: It includes long texts from various real-world scenarios, such as financial reports, legal documents, and academic papers, with lengths up to 128K tokens.
- Task Comprehensiveness: The dataset covers tasks at multiple difficulty levels, constructing a comprehensive classification system for long-text processing capabilities.
- Conversational Data: It introduces multi-turn conversational data to simulate real-world long-text Q&A scenarios.
- Multilingual Support: It provides bilingual Chinese-English data to meet multilingual application needs.
In the field, a 256K context window is impressive on paper, but inference costs will likely limit its daily use. I remain skeptical of synthetic benchmarks until we see performance on uncurated enterprise documents.
Inference Acceleration Optimization
To make the Hunyuan-Large MoE model actually usable without burning through GPU budgets, the team leaned heavily on KV Cache compression. It’s not just about raw parameters anymore; it’s about fitting 389B weights into hardware that doesn’t cost a small fortune to run.
They combined Grouped-Query Attention (GQA) and Cross-Layer Attention (CLA). GQA sets eight KV head groups to compress the head dimension, while CLA shares the cache every two layers to cut down on memory usage across dimensions. The result is a 95% reduction in KV cache memory with performance staying largely intact. That kind of efficiency gain matters more than any benchmark score when you’re trying to deploy this at scale.

What I watch for is compressing cache is necessary, but does it break edge cases in real-world queries? I think a 95% memory drop is impressive if the latency penalty isn’t hidden elsewhere. I want to see how this holds up under concurrent user load, not just single requests.
Post-Training Optimization
The pre-training gets the headlines, but the post-training phase is where models usually fall apart in production. Tencent used a two-stage approach: Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF).
For SFT, they ingested over 1 million high-quality data points covering math, reasoning, Q&A, and programming. They didn’t just dump data; they applied rule-based filtering, model-based filtering, and manual review to keep the noise out. The process ran for three rounds, with the learning rate decaying from $2e-5$ to $2e-6$. This slow decay helps utilize the data without overfitting to specific patterns that don’t generalize.
The RLHF phase is trickier. They combined offline and online Direct Preference Optimization (DPO). Offline training used pre-built preference datasets for controllability, while online training generated responses using the current policy model, selecting the best one via a reward model to boost generalization. To stop the model from gaming the system—a common issue known as “reward hacking”—they employed an Exponential Moving Average (EMA) strategy. This ensures smoother convergence during training, which is critical for stability in deployment.
In the field, reward hacking is a persistent bug; EMA helps but doesn’t eliminate the risk of degenerate outputs. I’m skeptical about “manual review” scaling to millions of data points without human error creeping in.
One More Thing
At the press conference, Kang Zhanhui, Head of Algorithms for Tencent’s Hunyuan Large Model, dropped a hint about what comes next. After releasing this massive 389B parameter model, Tencent plans to gradually open-source smaller-sized versions. This is a strategic move to cater to individual developers and edge-side deployments where running a giant MoE model isn’t feasible.

They also simultaneously open-sourced a 3D large model. If you’re interested in spatial reasoning or embodied AI applications, you can learn more about that here.
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google