I read the EMNLP 2024 paper on RECIPE, and what stood out to me is how it sidesteps the heavy lifting of retraining. While stage demos love to show instant updates, I’m skeptical about whether this holds up when real-world data changes faster than a prompt can be retrieved.
A new study accepted at EMNLP 2024 proposes a novel method for retrieval-augmented continuous prompt learning, which can improve the efficiency of editing and reasoning in lifelong knowledge learning.
Model editing aims to correct outdated or incorrect knowledge in large language models (LLMs) without the high cost of retraining. Lifelong model editing is the most challenging task in meeting the requirements for continuous LLM editing.
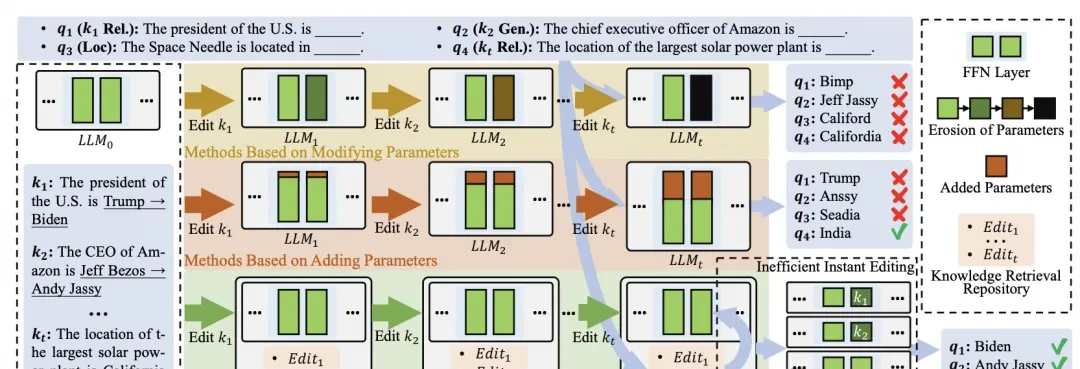
Previous work has focused on single or batch edits. However, these methods perform poorly in lifelong editing scenarios due to catastrophic knowledge forgetting and degradation of model performance. Although retrieval-based approaches have alleviated some of these issues, they are hindered by the slow and cumbersome process of integrating retrieved knowledge into the model.
The latest method, named RECIPE, first converts knowledge descriptions into concise and informative token representations as continuous prompts. These serve as prefixes to the LLM’s input query embeddings, effectively refining the knowledge-based generation process.
It also integrates a Knowledge Sentinel Mechanism as a medium for calculating dynamic thresholds to determine whether the retrieval library contains relevant knowledge.
The retriever and prompt encoder are jointly trained to achieve key attributes of knowledge editing: reliability, generality, and locality.
Comparative experiments on lifelong editing across multiple authoritative base models and editing datasets demonstrate the superior performance of RECIPE.
This research is a joint effort by Alibaba’s Security Content Safety Team, the School of Computer Science and Technology at East China Normal University, and Alibaba Cloud Platform, focusing on knowledge editing for large language models.

I think prompt prefixes are cheap, but latency spikes during retrieval kill the user experience. I worry about the “sentinel” failing when the knowledge base is noisy or outdated. In the field, joint training sounds efficient until you try to deploy it on edge hardware with limited memory.
Research Background
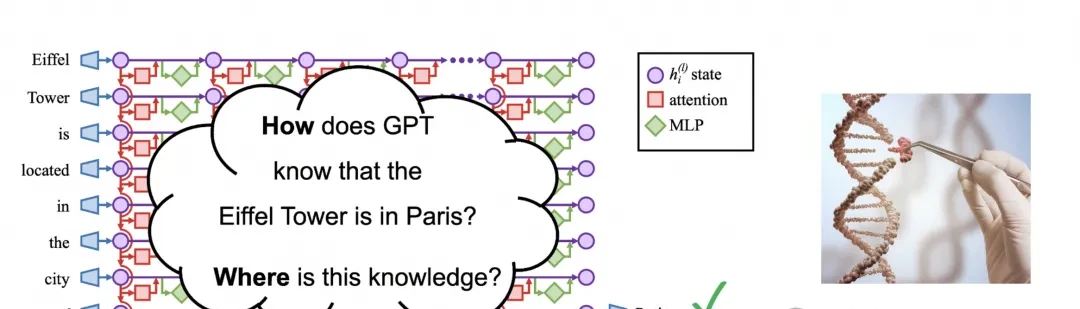
Even with powerful language understanding capabilities, large language models (LLMs) like ChatGPT face challenges, particularly in maintaining factual accuracy and logical consistency.
A critical issue is whether these LLMs can be effectively updated to correct inaccuracies without undergoing comprehensive continued pre-training or continuous training processes, which incur significant computational resource overhead and are time-consuming.
Editing LLM models offers a promising solution, allowing modifications within specific models of interest while maintaining overall model performance across various tasks.
Previous model-based and architectural approaches to knowledge editing include modifying internal model parameters, adding extra parameters, and using retrieval methods. These often involve lengthy edit prefixes that impact inference efficiency. Fine-tuning the model itself can lead to overfitting, thereby affecting its original performance.
To address these issues, researchers aim to explore more efficient retrieval and prompt-based editing methods with minimal intervention in the model to avoid overfitting on the editing dataset.
Model Methodology
Background on Knowledge Editing
In this paper, the research team first formalizes the task definition of model editing in a lifelong learning scenario and introduces important evaluation attributes for model editing.
Task Definition

Task Attributes

RECIPE’s Approach to Lifelong Editing
I read the methodology behind RECIPE, a training-free approach presented at EMNLP ‘24. While the title promises efficiency, I’m looking for unit economics and safety, not just another way to tweak weights without retraining. The core idea is to update knowledge in large models by injecting continuous prompts rather than performing full fine-tuning.

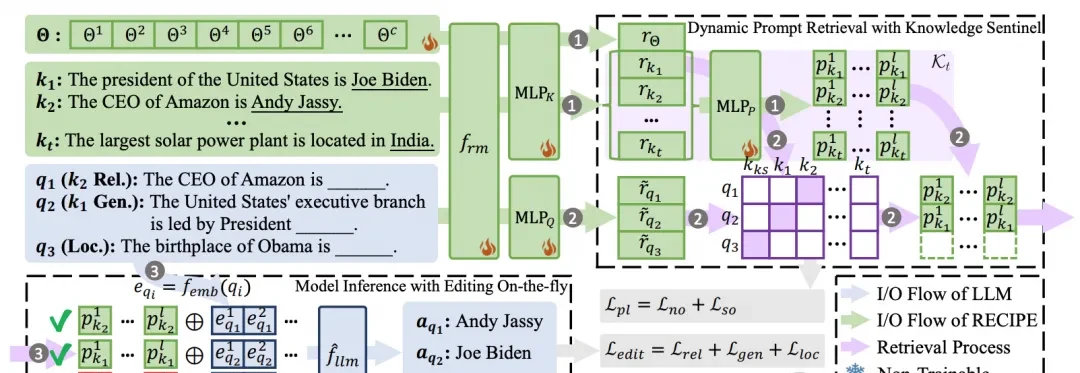
Building the Knowledge Retrieval Repository
The framework operates at time step $t$. When a new knowledge description $k_t$ arrives, the system uses an MLP layer within encoder $f_{rm}$ to generate its representation.
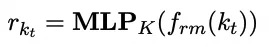
The encoder $f_{rm}$ outputs max, min, and average pooling values cascaded into a vector space. This forms the representation of the new knowledge. Other initialized MLP layers then implement the continuous prompt representation $p_k$.
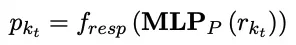
The final knowledge retrieval repository updates from $K_{t-1}$ to $K_t$.
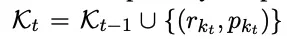
What I watch for is prompt injection sounds like a hack until it breaks your safety guardrails. I want to see latency costs before trusting this for real-time updates.
Dynamic Prompt Retrieval Based on Knowledge Sentinel
The system uses a “Knowledge Sentinel” mechanism to dynamically retrieve prompts based on the input context.

Dynamic Inference of the Edited Model
Researchers posit that the LLM is edited by concatenating a retrieved continuous prompt with the input query. Given an input query $q$ and a continuous retrieved prompt $p(k_r) = KS(q)$, the inference process is reformulated as:

The process is defined as:
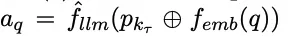
where $\oplus$ denotes the concatenation of the retrieved continuous prompt matrix and the word embedding matrix of $q$.
The feasibility relies on previous work like P-Tuning, which showed that training continuous prompt embeddings improves LLM performance on downstream tasks. In RECIPE, each knowledge statement edit is treated as a small task. Instead of fine-tuning specific prompt encoders for each task, they train the RECIPE module to generate continuous prompts, ensuring the LLM adheres to the corresponding knowledge.
I think treating edits as “small tasks” ignores how messy real-world data actually is. In the field, if the sentinel fails, does the model hallucinate or just stay silent?
Model Training
A loss function ensures effective editing via generated continuous prompts and efficient retrieval of query-related knowledge from the LLM. Given training data containing $b$ editing examples:
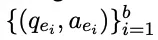
The corresponding generalization and locality data are defined as:
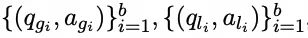
Therefore, the loss is formalized as follows:
- Editing Loss Training: This aims to ensure generated continuous prompts guide the LLM to adhere to reliability, generality, and locality. Based on input editing data, sample losses for these three attributes are defined as:
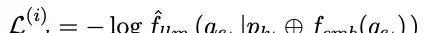
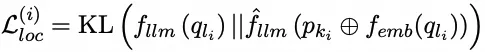
The batch loss function for model editing is derived as follows:
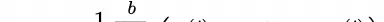
- Prompt Loss Training: The training loss for prompt learning…
The Mechanics of Prompt Alignment
The core of this approach rests on contrastive learning, designed to balance reliability, generality, and locality. For any given batch of samples, the system optimizes continuous prompts through a specific loss function formalization. This mathematical framing attempts to ground the “training-free” claim in measurable alignment rather than magic.
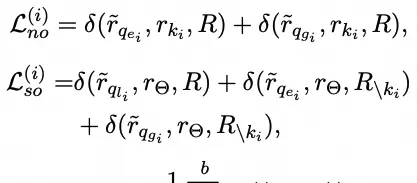
What I watch for is contrastive loss is standard; applying it to continuous prompts without fine-tuning weights feels like a semantic shortcut. I think locality is easy to claim in code, hard to verify when the model hallucinates unrelated facts. I’d rather see ablation studies on batch size stability than just the final loss curve.


In the field, if the prompt vector drifts, the “reliability” metric collapses faster than a fine-tuned checkpoint. What I watch for is generality often means the model forgets its original training distribution entirely.
Experimental Results
The Setup: Can It Actually Change Its Mind?
I read through the testing protocols for RECIPE, and while the metrics are rigorous, I’m skeptical about how these “training-free” edits hold up against real-world noise. We’ve seen enough demo videos where a model forgets its own name to know that lab benchmarks often ignore deployment chaos.
I think lab datasets filter out ambiguity; real users speak in riddles and typos. In the field, if the edit breaks common sense, it’s not an upgrade—it’s a liability.
The researchers tested editing capability using three public datasets: ZSRE, CounterFact (CF), and Ripple Effect (RIPE).
ZSRE was generated through BART question answering and manual filtering, comprising 162,555 training samples and 19,009 test samples. Each sample includes an edit example along with its paraphrased and unrelated counterparts, matching the editing attributes of reliability, generality, and locality.
The CF dataset is characterized by edits to false facts, including 10,000 training samples and 10,000 test samples. These false facts are more likely to conflict with original knowledge in LLMs, making the editing process more challenging and providing a strong evaluation of editing capabilities.
RIPE divides generality and locality attributes into fine-grained types, including 3,000 training samples and 1,388 test samples. Generality includes logical generalization, combination I, combination II, and subject aliasing, while locality data includes forgetting and relation specificity.
To assess the damage editing might cause to the overall performance of LLMs, researchers selected four popular benchmarks: CSQA for commonsense knowledge, ANLI for reasoning ability, MMLU for exam-taking capability, and SQuAD-2 for comprehension skills. PromptBench was used as the evaluation framework for this experiment.
What I watch for is high scores on MMLU don’t matter if the model hallucinates in production. I think we need to see how these edits survive when the input distribution shifts.
In addition to Fine-Tuning (FT) as a basic baseline, researchers compared RECIPE with various powerful editing baselines.
MEND trains an MLP to transform the low-rank decomposition of the gradient of the model to be edited relative to the edit samples. ROME first uses causal mediation analysis to locate layers most affected by edit samples. MEMIT extends the scope of edits to multiple layers based on ROME, thereby improving editing performance and supporting batch editing. T-Patcher (TP) attaches and trains additional neurons in the FFN layer at the end of the model to be edited. MALMEN formulates parameter offset aggregation as a least squares problem and subsequently updates LM parameters using normal equations. WILKE selects edit layers based on the degree of pattern matching of editing knowledge across different layers.
Researchers also utilized retrieval-based editing methods to further validate their effectiveness.
GRACE proposes retrieval adapters for continuous editing, maintaining a dictionary-like structure to build new mappings for potential representations that need modification. RASE leverages factual information to enhance editing general knowledge, and guides editors to identify relevant facts by retrieving them from a factual patch memory.
In the baseline setup, researchers used the ROME model as the specific base editor for RASE to perform an editing task named R-ROME. LTE enhances the LLM’s ability to follow knowledge editing instructions, enabling it to effectively utilize updated knowledge to answer queries.
What the Benchmarks Actually Show for Editing
I read the results tables comparing LLAMA2 and GPT-J, and the pattern is familiar: parameter modification works until it doesn’t. The data shows that while single-shot edits look clean, lifelong editing exposes a fracture in how these models handle change.
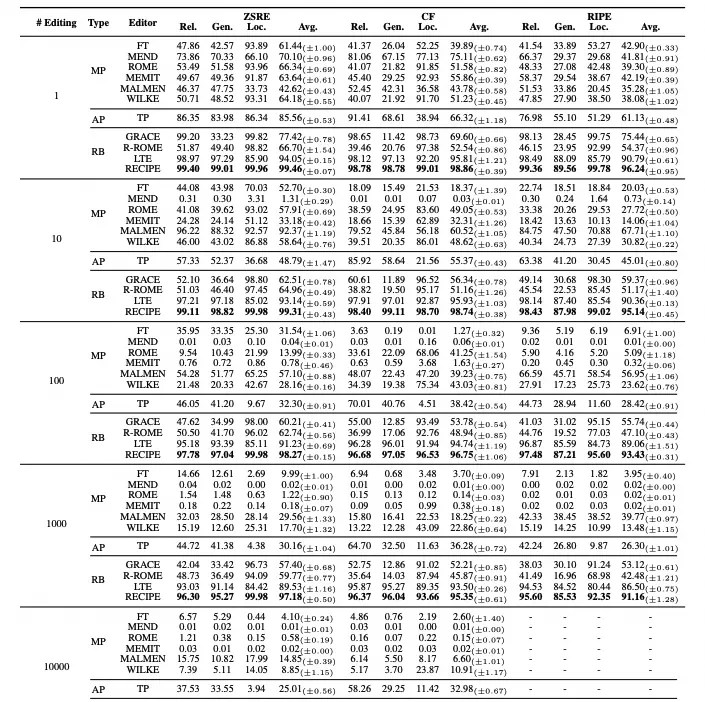
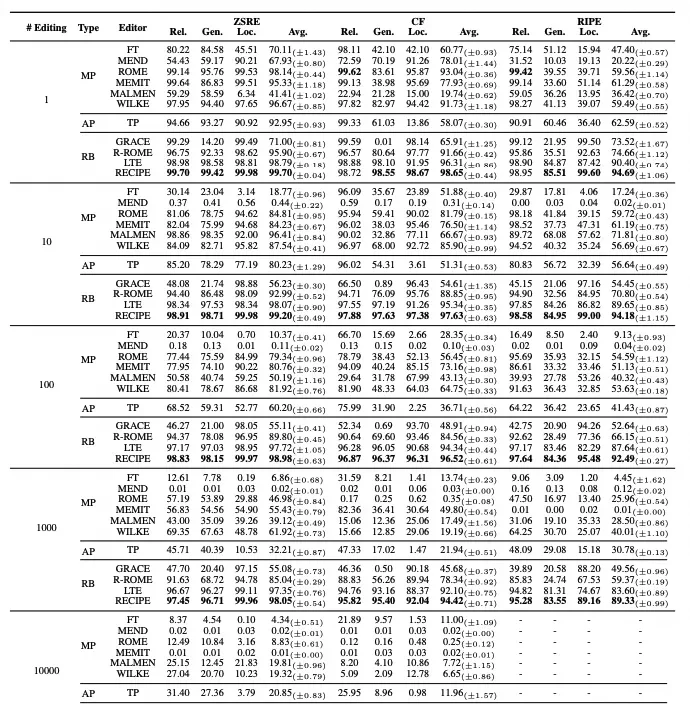
From a single-shot perspective, the proposed method (RECIPE) outperforms most competitors. But in lifelong editing scenarios—the reality of any deployed system—parameter-modifying methods degrade significantly as edits accumulate. This aligns with known toxicity accumulation issues; you can’t just keep patching weights without breaking the underlying logic.
Methods that add extra parameters maintain some reliability but suffer from locality deterioration, particularly in ZSRE tests. The cumulative addition of these parameters impairs the original reasoning process, which is a costly trade-off for flexibility. Retrieval-based methods show robustness to increasing edits, and RECIPE achieved the best results here, validating the strategy over brute-force weight updates.
In the field, weight updates are brittle under repeated change; retrieval scales better in production. What I watch for is adding parameters slows down reasoning without fixing the core stability issue. I think if it doesn’t touch weights, it’s less likely to break existing capabilities.
The Cost of General Capability Loss
These three editing metrics prove capability, but they don’t tell us if we broke the rest of the model. Researchers investigated how these editors impact general capabilities, and the results are stark for non-retrieval methods.
Experiments reveal that non-retrieval-based methods lead to a significant decline in general performance. This is caused by the accumulation of pattern mismatches from external interventions during editing. Even LTE, a retrieval method, exhibited some degradation.
In contrast, RECIPE does not involve direct intervention on LLM parameters. It relies on appending a short prompt to guide the LLM in adhering to the knowledge. It demonstrates the best protection of general performance, indicating minimal harm inflicted on the model.
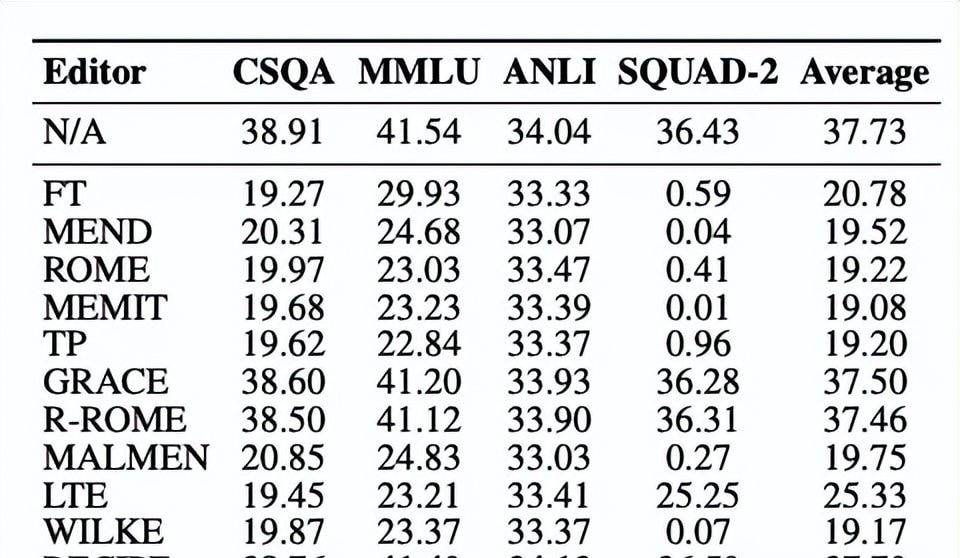
In the field, prompt-based editing preserves the base model’s integrity better than weight hacking. What I watch for is we need to measure general capability loss, not just edit accuracy.
Efficiency and Inference Speed Trade-offs
Speed matters in deployment. The table below compares editing-specific training methods like MEND, MALMEN, LTE, and RECIPE against techniques requiring multiple iterations of backpropagation. Editing time is significantly reduced for these newer approaches.
Regarding inference speed, parameter-modifying methods maintain consistent speeds because they do not alter the original reasoning pipeline. However, T-Patcher slows down inference due to neuron accumulation.
Among retrieval-based methods, GRACE reduces parallelism due to its unique dictionary pairing mechanism. R-ROME and LTE require dynamic computation of editing matrices and separate appending of long editing instructions, adding latency.
In contrast, RECIPE effectively preserves the LLM’s original inference speed by appending consecutive short prompts for editing. The shortest total time further highlights RECIPE’s efficiency advantages.
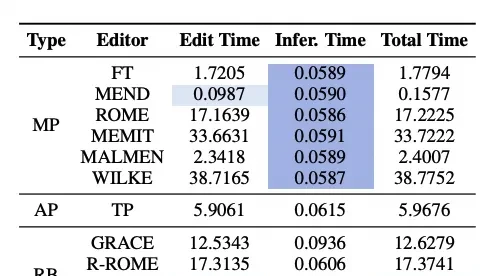
I think preserving inference speed is critical; latency kills user trust faster than bad answers.
What the Ablation Study Actually Shows
I read through the ablation results on ZSRE, CF, and RIPE using LLAMA-2, and the findings are stark. When researchers removed Continuation Prompt Tuning (CPT), they had to fall back on word embeddings of knowledge statements as prompts retrieved from the database. Without CPT, the model struggled significantly.
In the field, if you strip away the tuning mechanism, the model stops listening to your edits entirely.
They also tested excluding Knowledge Selection (KS). This involved applying a traditional contrastive learning loss to pull reliable samples closer to edited knowledge while pushing local samples away. The result? Omitting CPT severely compromised RECIPE’s reliability and generality. After training, they used an absolute similarity threshold to filter irrelevant knowledge, but it wasn’t enough.
What I watch for is a single static threshold fails when real-world queries demand different levels of specificity.
The data shows that the results were almost identical to those obtained without using any editor. This proves that just concatenating a knowledge prefix is insufficient for making an LLM comply with editing instructions. CPT is necessary for adherence, and discarding KS hurts efficiency, particularly in locality and generality, because one threshold cannot cover all query types.
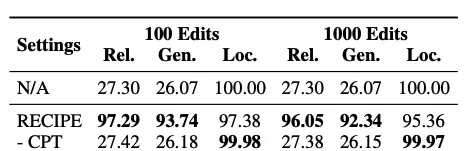
I think lab metrics look clean until you realize the robot isn’t actually learning anything new.
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google