I’ve spent years watching AI coding assistants promise to save time, only to deliver half-baked snippets that require more debugging than they solve. The real friction isn’t just generating code; it’s the mental overhead of managing context, verifying logic, and stitching together disparate tools into a coherent workflow. Anthropic claims Claude 3.7 Sonnet solves this by introducing hybrid reasoning—a model that can toggle between instant responses and deep, step-by-step thinking on demand.
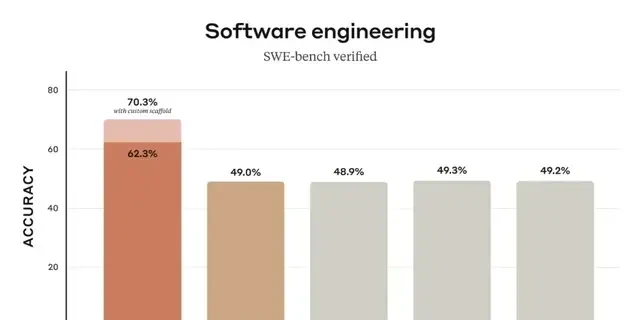
This release positions Sonnet as a comprehensive leader in coding and front-end web development, directly challenging competitors like OpenAI’s o3-mini. In side-by-side comparisons using identical prompts—specifically generating a p5.js script for 100 bouncing balls with fading trails inside a rotating sphere—the visual output from Claude 3.7 Sonnet appears more robust than the baseline o3-mini result.
o3-mini:
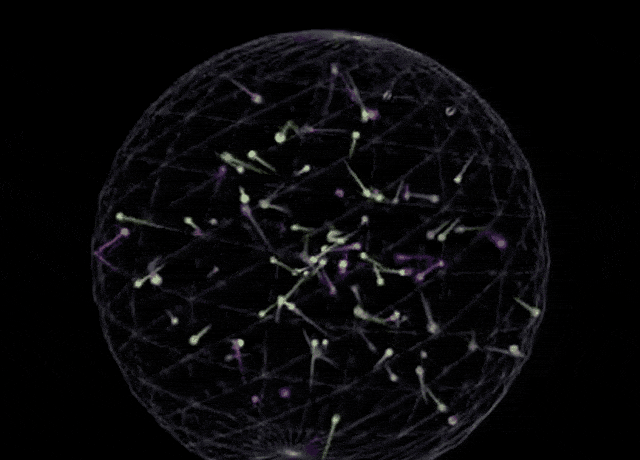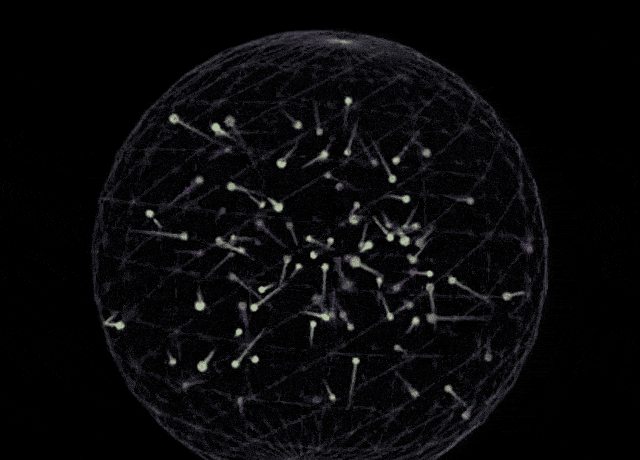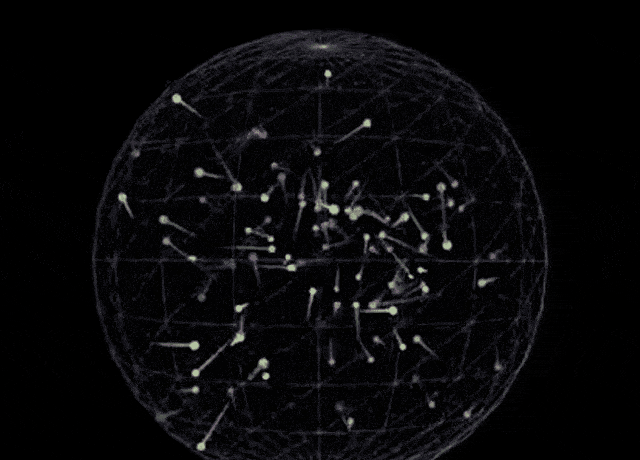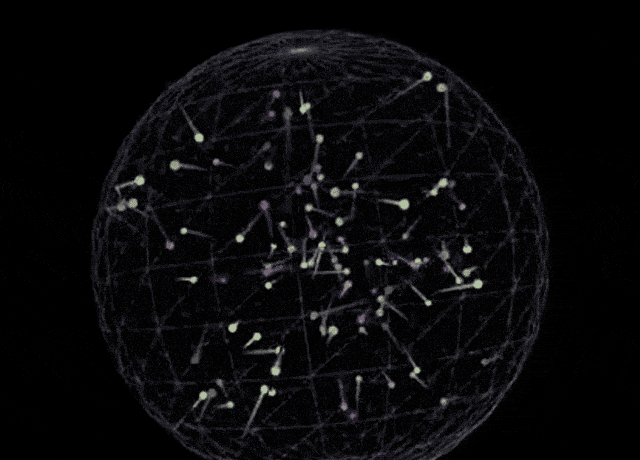
Claude 3.7 Sonnet:
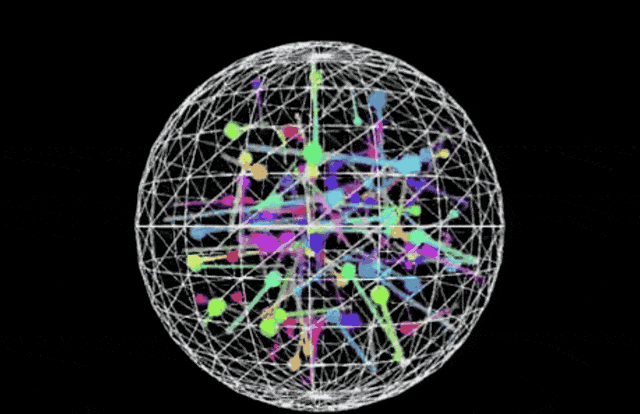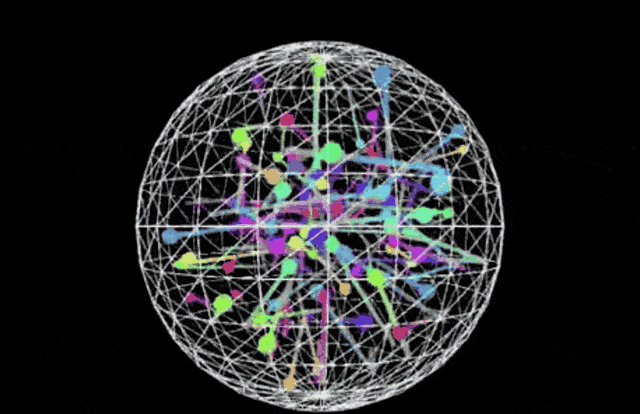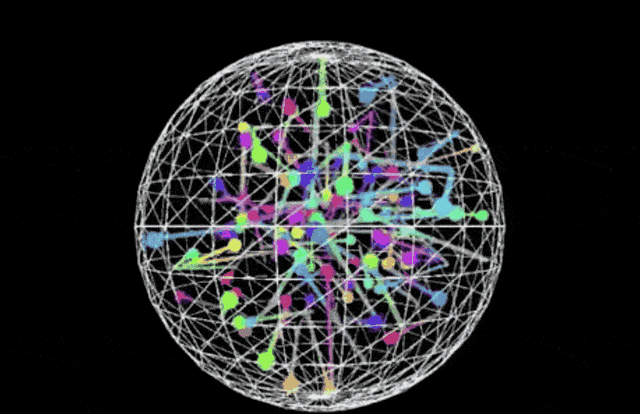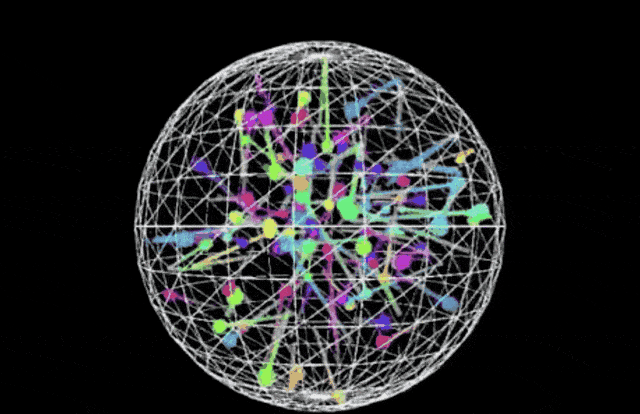
(Prompt: Write a p5.js script that simulates 100 colorful balls bouncing inside a sphere. Each ball should leave a fading trail showing its recent movement path. The container sphere should rotate slowly. Ensure proper collision detection is implemented so the balls remain within the sphere.)
The model also demonstrates capability in generating interactive elements like video games, suggesting a broader utility beyond static scripts.
As a hybrid reasoning model, it offers two distinct modes: near-real-time responses for quick tasks, and “Extended Thinking” for complex logic. In Extended Thinking mode, Anthropic reports improvements in mathematics, physics, instruction following, and coding accuracy. Crucially, API users can now precisely control the model’s thinking time, allowing for a balance between latency and depth. This feature is available across all platforms, including Amazon Bedrock and Google Cloud, though Extended Thinking is excluded from free tiers.

I think controllable thinking time is a practical feature for managing API costs on complex tasks. As a builder, hybrid reasoning reduces the need to switch between different model tiers for simple vs hard problems. Personally, excluding extended thinking from free tiers limits early exploration for casual developers.
Pricing remains unchanged from previous generations: $3 per million input tokens and $15 per million output tokens, with thinking tokens included in that rate. Beyond the model itself, Anthropic launched Claude Code, their first dedicated coding tool. The company claims it can complete tasks that previously required over 45 minutes of manual work in a single execution, aiming to reduce context-switching fatigue for developers.
The developer community’s reaction has been immediate and eager, with many expressing readiness to integrate these tools into their daily stacks.
The version number also raises questions; the jump to 3.7 suggests a significant architectural shift rather than an incremental update, prompting speculation about why the numbering skipped traditional expectations.

Claude 3.7 Sonnet: The First Hybrid Reasoning Model
I’ve been watching the industry fracture into “fast” and “deep think” camps, but Anthropic is trying to merge them with Claude 3.7 Sonnet. Their philosophy mirrors how our brains work: we don’t switch between two different people; we just decide whether to answer quickly or dig deeper. They argue reasoning shouldn’t be a separate model entirely, but a comprehensive capability built into frontier LLMs.
This hybrid approach means one model handles both standard prompts and extended reflection. In Standard mode, it’s an upgrade over Claude 3.5 Sonnet for everyday tasks. Switch to Extended Thinking, and the model engages in self-reflection before responding, boosting performance in math, physics, coding, and instruction following.
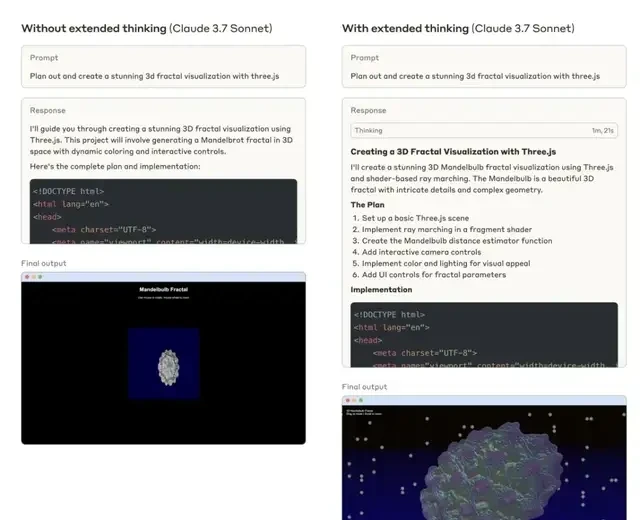
The prompting syntax remains consistent across both modes, which lowers the friction for adoption.
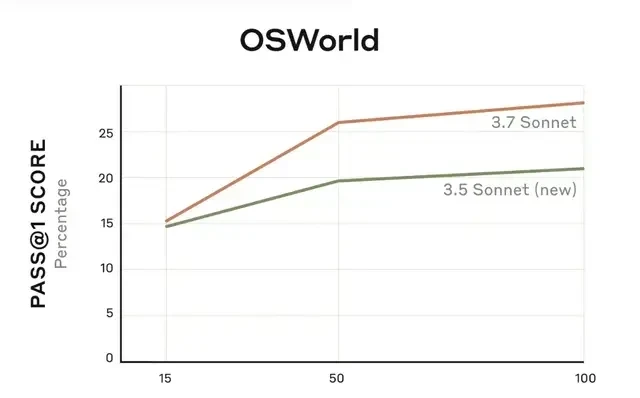
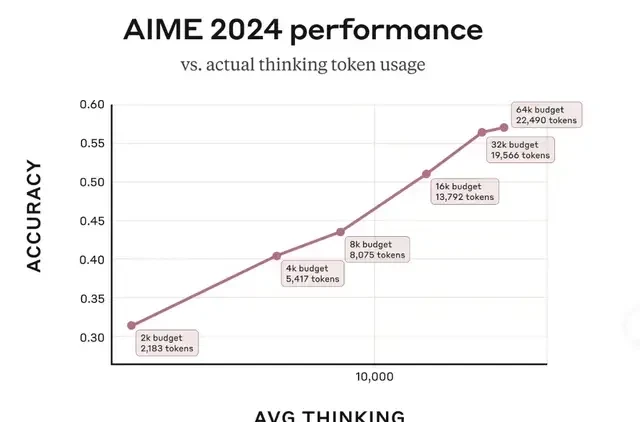
Second, you get control over the thinking budget. API users can cap the model’s internal thought process at N tokens. While N is flexible, the total output cannot exceed 128K tokens. This lets you trade speed and cost for quality. Performance scales with the token allowance; the AIME 2024 results chart below illustrates this direct correlation.
Third, the optimization focus has shifted toward real-world tasks. Anthropic is de-emphasizing pure math and CS competition problems in favor of what actually reflects user needs.

△ Solving practical probability problems
The community has been particularly impressed by its “vibe coding” capabilities—AI-assisted coding for non-developers. One user tested it with a complex request: > Can you write the most complex fabric simulation using p5js?
While Grok 3 and o1 pro yielded no usable results, Claude 3.7 Sonnet delivered working code.

It also achieved State-of-the-Art (SOTA) performance in agent tool usage.
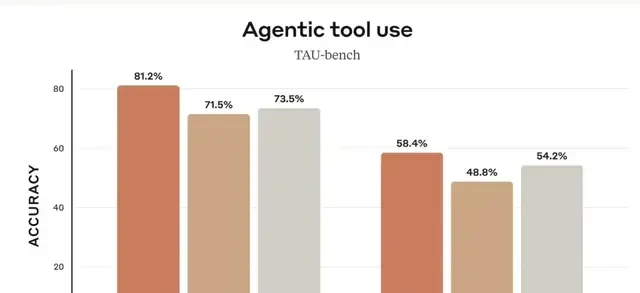
Claude 3.7 Sonnet excels in instruction following, general reasoning, multimodal capabilities, and agent coding. Extended Thinking provides significant boosts specifically in mathematics and science.
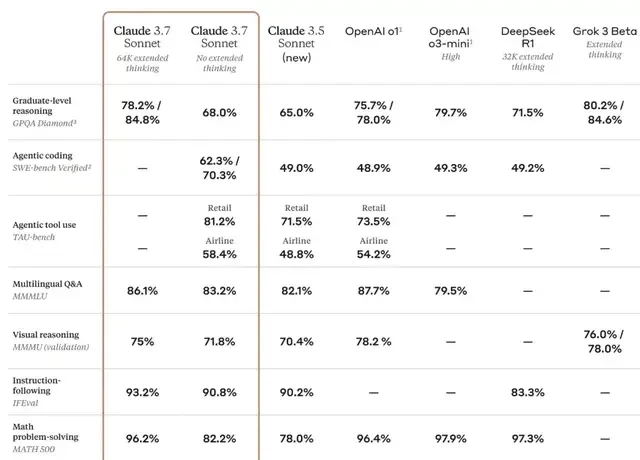
Beyond traditional benchmarks, it even surpassed all previous models in a Pokémon game test. The team equipped Claude with basic memory, screen pixel input, and function calls for key presses and navigation. This allowed it to exceed typical context limits, play continuously, and interact tens of thousands of times.
Final experiments showed it was the best-performing Sonnet model to date; it successfully battled three Pokémon Gym Leaders (game bosses) and won their badges. In contrast, Claude 3.0 Sonnet couldn’t even leave the house in Pallet Town where the story begins.
The x-axis represents the number of interactions completed by Claude while playing; the y-axis indicates significant milestones in the game, such as collecting certain items, navigating to specific areas, and defeating bosses.
For this release, researche
I think hybrid reasoning cuts context switching for developers who need both speed and depth. As a builder, controllable thinking budgets help manage API costs on complex tasks. Personally, vibe coding results suggest strong utility for non-developer teams.
Hybrid Reasoning and Fine-Tuned Safety
What stood out to me in this release is Anthropic’s pivot toward parallel test-time computation as a primary lever for performance. Rather than just scaling parameters, they are using compute dynamically during inference to boost accuracy on hard problems.
Their method involves sampling multiple independent reasoning paths and then selecting the best answer without knowing the ground truth upfront. One strategy relies on majority voting—picking the most common response across samples. Another approach deploys a secondary model (like another instance of Claude) to review its own work or apply a learned scoring function, ultimately choosing what it deems the strongest output.
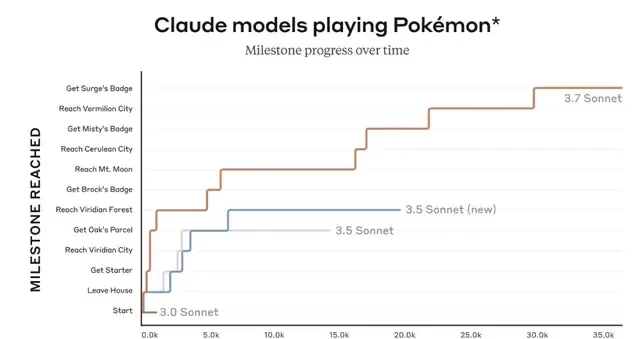
This technique delivered striking results on GPQA, a benchmark featuring difficult questions in biology, chemistry, and physics. Under conditions equivalent to 256 independent samples, using a learned scoring model, and capped at a maximum thinking cost of 64 tokens, Claude 3.7 Sonnet achieved an 84.8% GPQA score. Notably, it hit 96.5% on the physics subset alone.
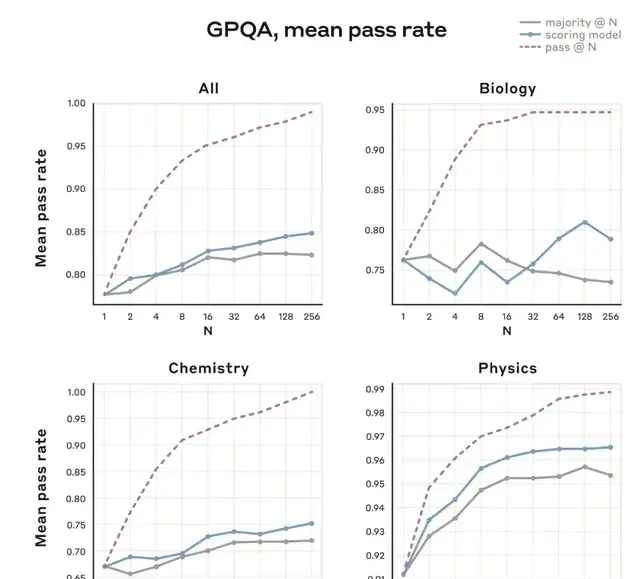
Beyond raw accuracy, the model shows improved nuance in safety handling. Claude 3.7 Sonnet makes finer distinctions between harmful and benign requests, which reduces unnecessary refusals by 45% compared to its predecessor. This suggests a shift toward fewer false positives in content moderation without compromising security.
I think parallel reasoning adds latency but pays off on complex logic tasks. As a builder, fewer false refusals means less friction for legitimate code generation. Personally, gPQA scores are impressive, but real-world debugging remains the true test.
The First Real Coding Agent Arrives
I’ve been waiting for an agent that doesn’t just chat but actually touches my files. Claude Code is here, and it’s not playing around with half-measures. Based on the official reveal, this isn’t a simple autocomplete plugin; it’s a full-stack worker bee. It can search your codebase, read files, edit them, write tests, run those tests, commit the changes, and push directly to GitHub. It even hooks into command-line tools.

Right now, it’s in early preview, but the interface is terminal-native. This matters because most of us live in the CLI when we’re deep in refactoring or debugging.
The efficiency gains are staggering in the early demos. Anthropic claims Claude Code can complete tasks that usually take over 45 minutes of manual human operation in a single pass. That’s not just speed; it’s a fundamental shift in how we handle repetitive coding overhead.
I think this saves hours on mundane refactoring tasks I hate doing manually. As a builder, terminal-native access means zero context switching for my daily workflow. Personally, one-shot completion of 45-minute tasks is the killer feature here.
Over the next few weeks, Anthropic plans to iterate rapidly based on real usage data. They’re focusing on tool call reliability, support for long-running commands, better in-app rendering, and expanding Claude’s understanding of its own capabilities. It’s a living system, not a static release.
They’ve also tightened up the experience on Claude.ai. GitHub integration is now available across all plans on the platform. This allows developers to directly connect their code repositories to Claude without needing separate enterprise setups or complex API configurations.
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google