Who wins when science gets automated? Researchers gain speed; creators lose control over their intellectual labor. I read Google’s latest release on its “AI co-scientist,” and what stood out to me was the sheer scale of automation they are pushing into academic workflows. CEO Sundar Pichai personally endorsed this multi-agent system, which leverages advanced reasoning to synthesize vast literature, generate novel hypotheses, and propose detailed research plans.
The architecture relies heavily on test-time compute, a technique mirroring OpenAI’s o1 and DeepSeek-R1, designed specifically to accelerate scientific discovery through intensive processing during inference rather than just training.

According to Pichai, the system has already achieved preliminary results in critical research areas such as liver fibrosis treatment, antimicrobial resistance, and drug repurposing. This isn’t just theoretical; it’s being applied to high-stakes medical challenges right now.
Capitalizing on this momentum, Google is launching a “Trusted Test Program” for scientists worldwide, which is now open for applications. This move signals a shift from closed labs to broader, albeit controlled, external collaboration.
The acknowledgments section reveals a formidable internal lineup at Google, including teams from Google Research, DeepMind, and Cloud AI, alongside scientists from top-tier universities who participated in testing. This cross-pollination of corporate and academic talent underscores the seriousness with which they are treating this initiative.

As netizens have noted, it is not far-fetched to imagine AI agents winning Nobel Prizes in the future. The trajectory suggests that attribution and authorship will become increasingly complex legal and ethical battlegrounds.

Literature Review/Hypothesis Generation/Reporting: An End-to-End Solution
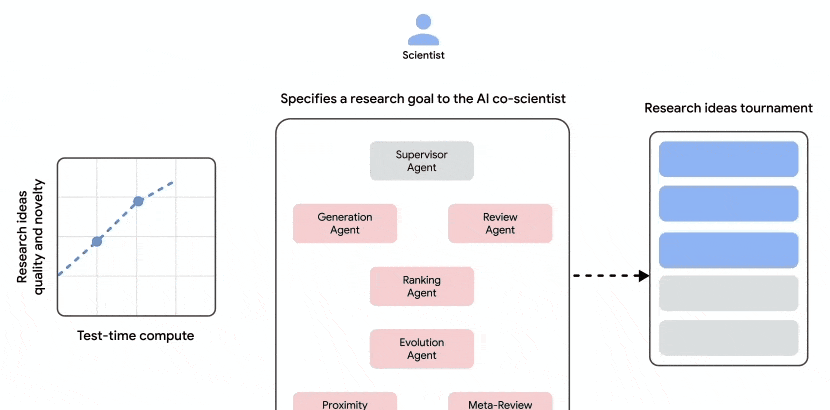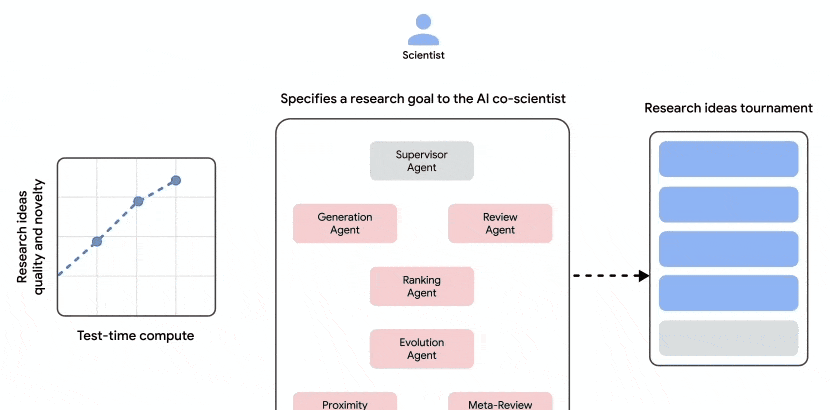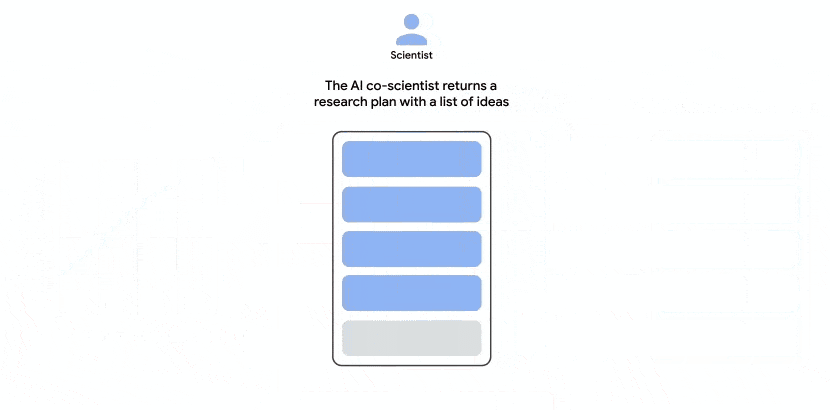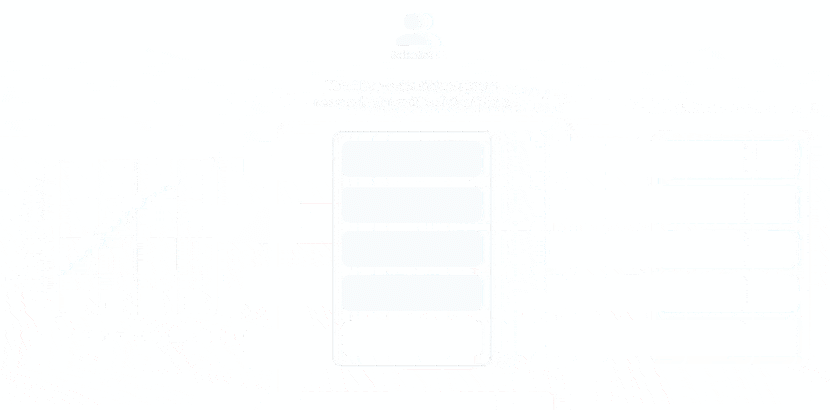
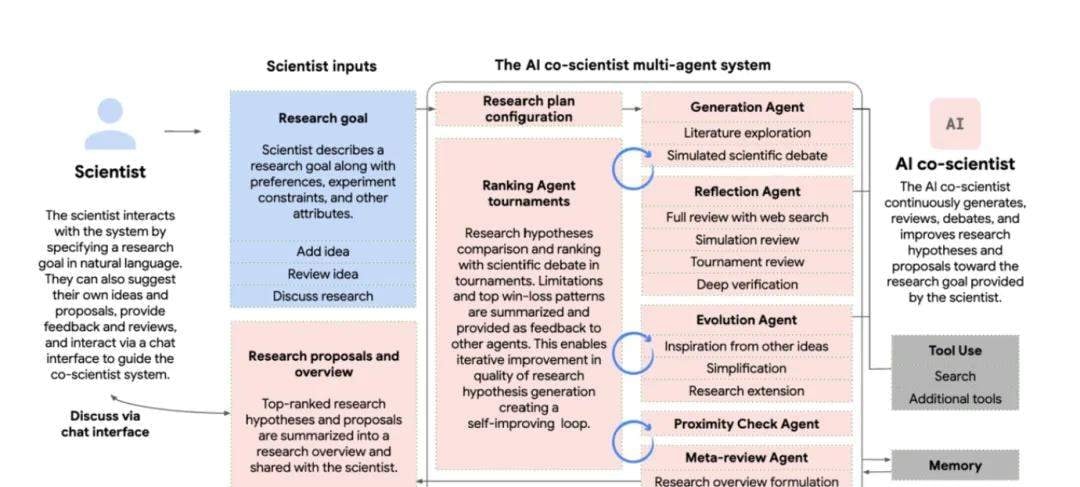
Let’s examine the operation process of the AI co-scientist. Its objective is clear: once a scientist provides a research topic in text, the system utilizes multiple AI agents to generate new research hypotheses, detailed research overviews, and experimental protocols. This end-to-end automation removes many manual steps from the early stages of inquiry.
The agents involved include but are not limited to:
- Generation: Proposing new hypotheses or ideas
- Reflection: Evaluating and analyzing generated hypotheses
- Ranking: Prioritizing hypotheses
- Evolution: Iteratively improving hypotheses
- Proximity: Exploring fields adjacent to or related to existing knowledge
- Meta-review: Supervising and optimizing the entire process
These agents iterate through automated feedback, generating, evaluating, and refining hypotheses to form a self-optimizing loop, ultimately outputting high-quality research proposals. The system essentially creates its own internal peer review mechanism before presenting results to humans.
Scientists can participate in the collaboration through several methods: For instance, providing rough ideas or research topics/directions at the outset for the system to refine further; or offering natural language feedback on AI outputs to guide adjustments. This human-in-the-loop design attempts to mitigate hallucination risks by keeping researchers in the driver’s seat.
Additionally, scientists can utilize other tools, such as web search or specialized domain-specific AI models, to further enhance research quality. The flexibility allows for integration into existing workflows rather than forcing a complete overhaul.
A deeper look at the collaboration process reveals that after a scientist proposes a research goal, a Supervisor Agent is responsible for task distribution. The architecture distinguishes between:
- Specialized agents (red boxes, with unique roles and logic);
- Scientist input and feedback (blue boxes);
- System information flow (dark gray arrows);
- Feedback between agents (red arrows within agent internals).
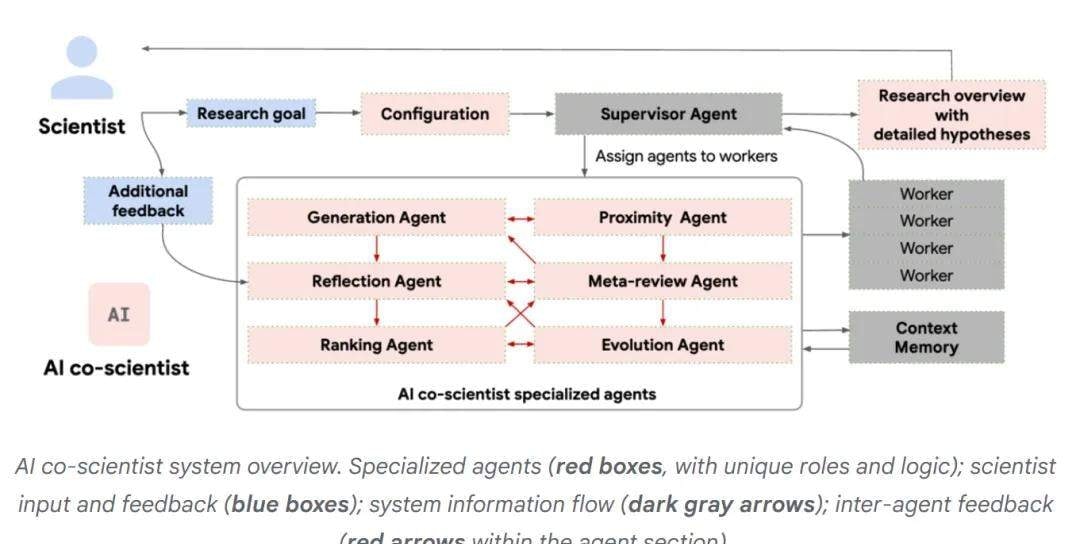
As shown above, the operation of the entire AI co-scientist system is relatively straightforward. However, the implications for academic integrity and data provenance remain significant concerns that we will need to monitor closely.
Using Test-Time Compute to Accelerate Scientific Discovery
The real shift here isn’t just faster models; it’s who gets to define the next breakthrough. When AI takes over hypothesis generation, the value of human curation becomes both more critical and more precarious for researchers.
The Elo Rating as a Proxy for Scientific Rigor
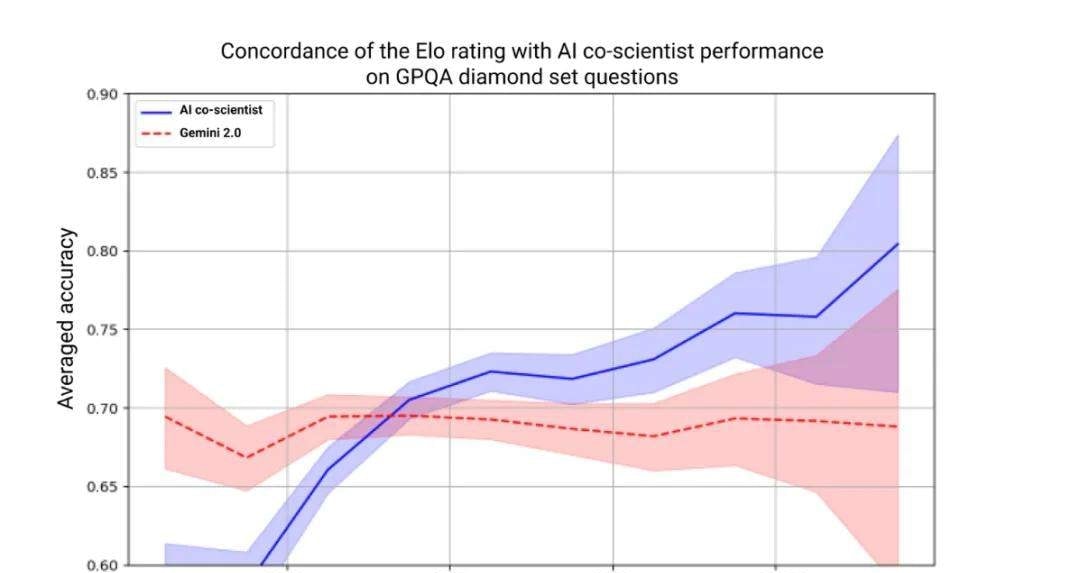
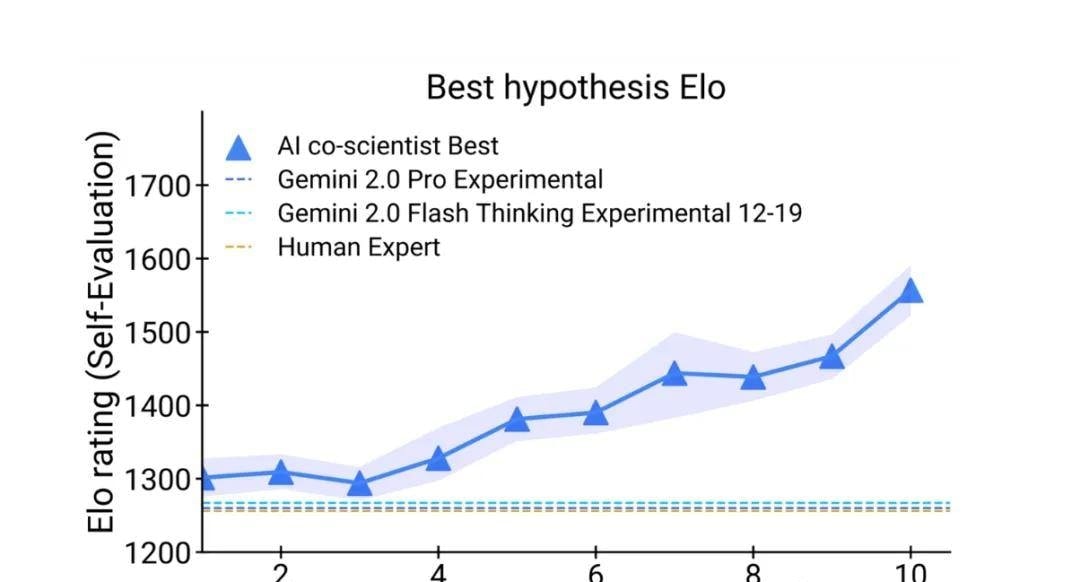
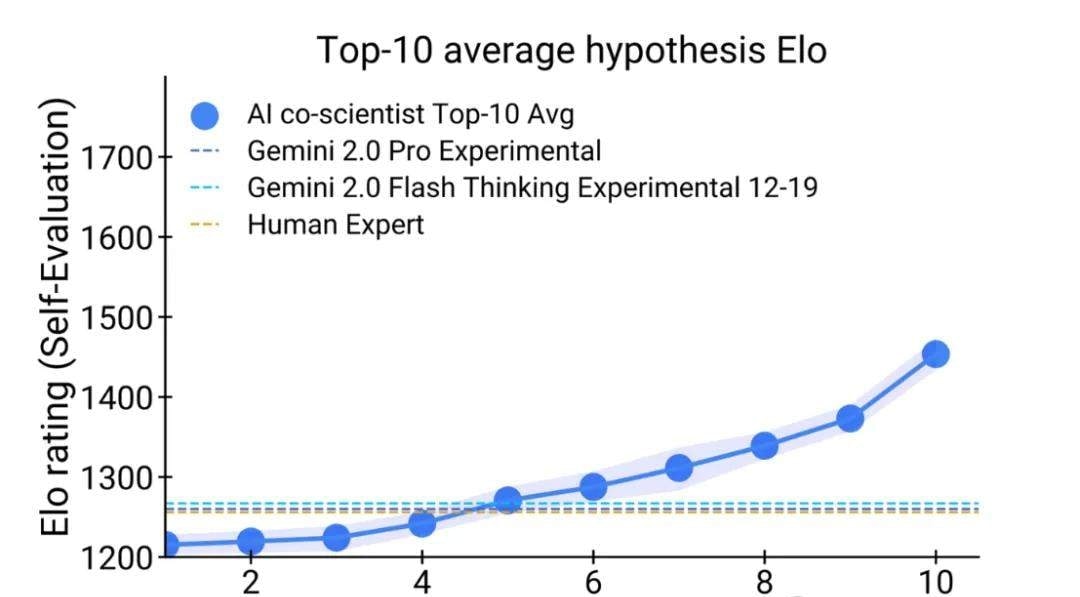
What stood out to me was Google’s decision to borrow from competitive gaming to measure scientific reasoning. They extended test-time compute to boost reasoning steps like self-play and hypothesis ranking, then applied an Elo rating system—typically used for chess or esports—to track the AI co-scientist’s progress.
I followed the release notes closely: they compared the AI co-scientist (blue line) against Gemini 2.0 Pro (red line) on the GPQA benchmark. The data showed a clear positive correlation: higher Elo ratings meant more accurate answers to hard problems. This suggests that Elo rating can serve as an effective metric for predicting how well an AI will handle complex scientific queries.
Outperforming Humans and State-of-the-Art Models
To test this rigorously, seven domain experts selected 15 open research goals with known optimal solutions. The goal was to see if automated Elo metrics could accurately rank the AI against top-tier reasoning models (including Gemini 2.0 Pro and specialized reasoning versions) and human experts.
The results were stark: the AI co-scientist performed significantly better than its peers. As the system invested more time in reasoning, its self-evaluation quality improved dramatically, sometimes surpassing even human experts who struggled with certain problems.
Crucially, when experts evaluated a subset of 11 goals, they found the AI co-scientist outperformed baselines in both novelty and impact. This isn’t just about getting the right answer; it’s about generating ideas that matter.
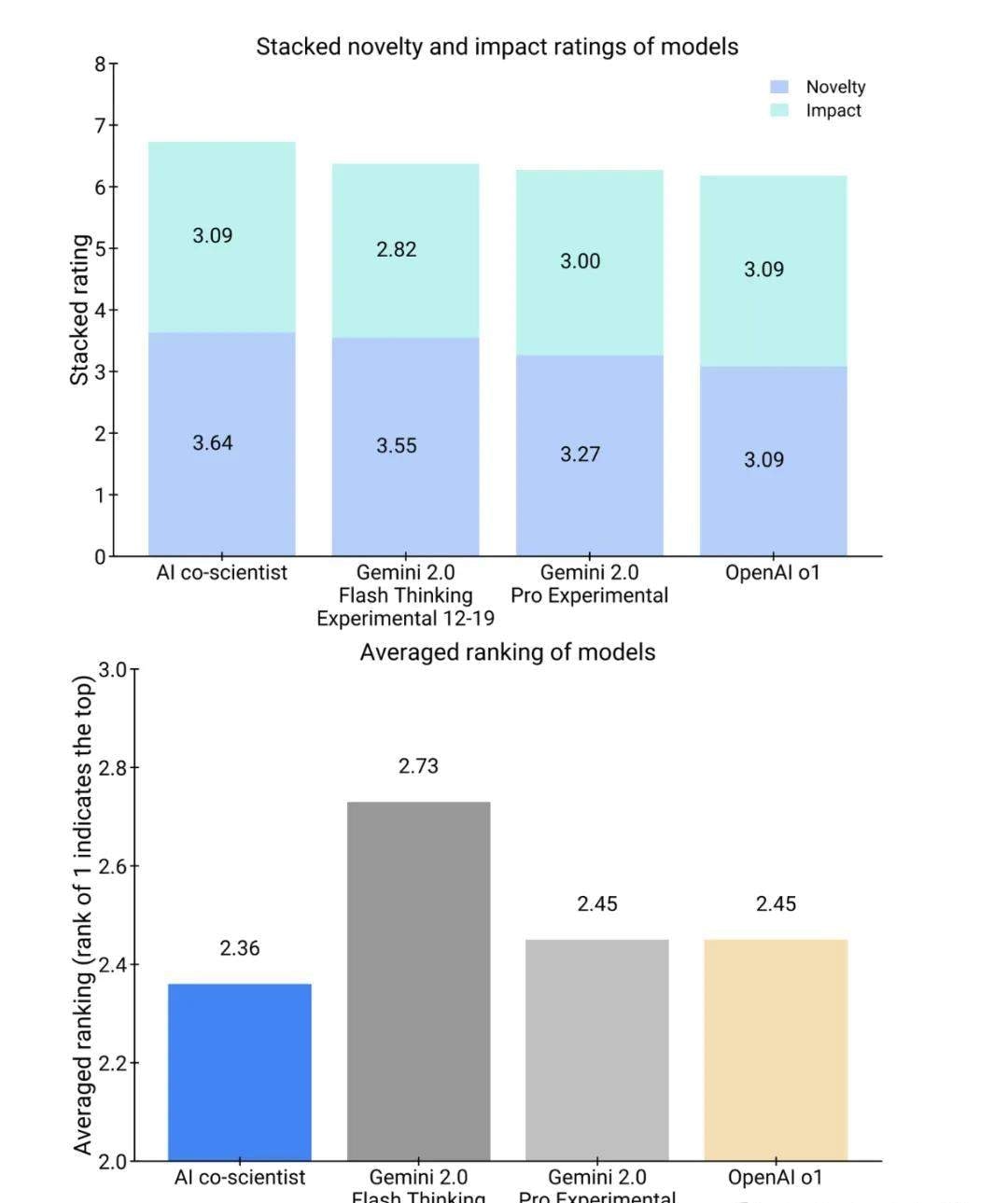
I think automated novelty scoring may devalue the incremental insights that junior researchers rely on for career building.
From Benchmarks to Wet Labs: Biomedical Breakthroughs
Theoretical accuracy is one thing; practical utility is another. The team moved from benchmarks to end-to-end laboratory experiments in three biomedical areas: drug repurposing, proposing new therapeutic targets, and understanding antimicrobial resistance mechanisms.
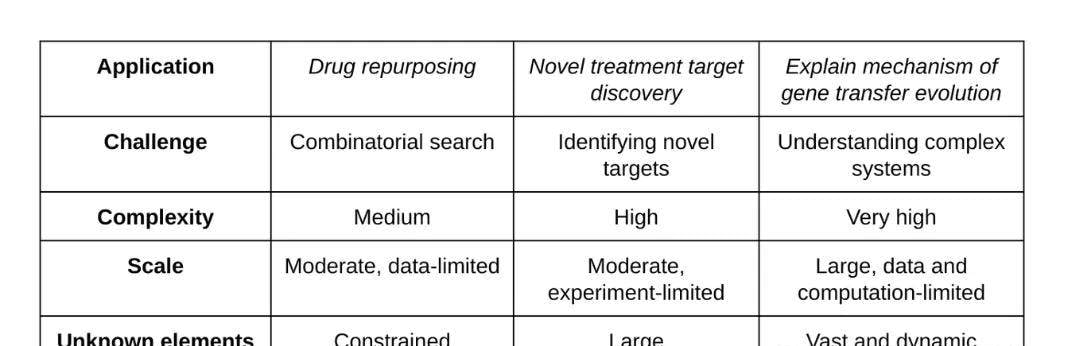
The AI received expert guidance across scenarios ranging from simple to complex. Let’s look at the preliminary wins.
Drug Repurposing for Acute Myeloid Leukemia (AML)
Drug repurposing uses approved drugs for new conditions, cutting development time and cost. For acute myeloid leukemia (AML), the AI analyzed chemical structures, pharmacodynamics, and genetic data to predict effective existing medications.
It proposed three potential drugs. In validation, these candidates inhibited tumor viability in multiple AML cell lines at clinically relevant concentrations. The proof of efficacy is there.
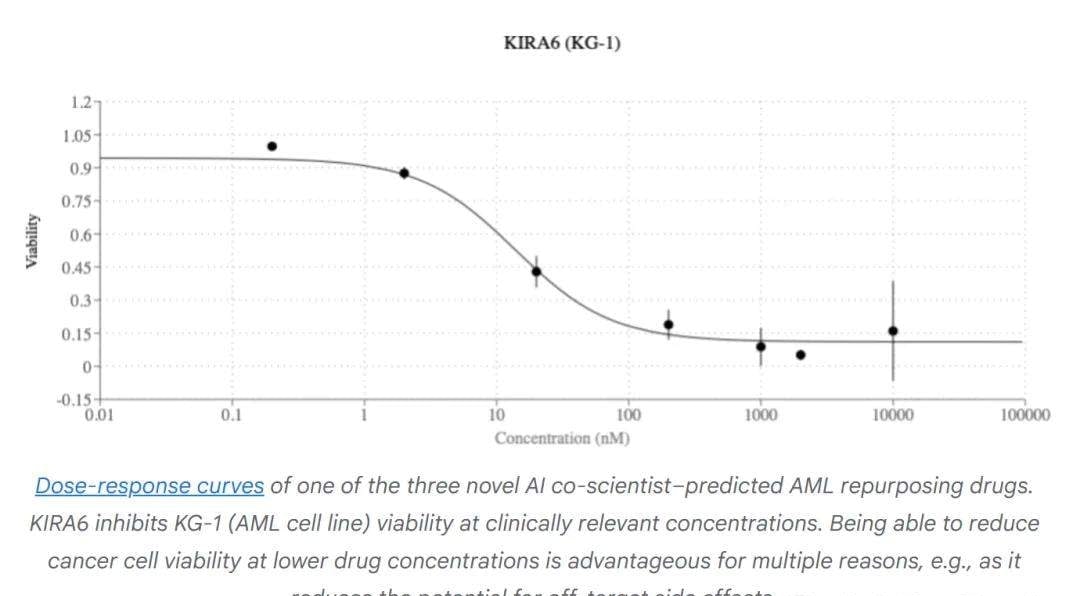
For creators, if labs adopt these tools without clear attribution, the original data curators and experimentalists risk being erased from the discovery chain.
Identifying Novel Therapeutic Targets in Liver Fibrosis
The next step is harder: identification of novel therapeutic targets. The team focused on liver fibrosis, a key area for current treatment development.
Google Assembles Elite Team to Build AI Scientists, Accelerating Scientific Discovery with Test-Time Compute
Who wins when algorithms replace hypothesis generation? The researchers who get the data; the scientists whose intuition is sidelined.
The push for disease research and finding effective therapeutic targets is critical in modern medicine. In this context, an AI co-scientist analyzed large volumes of biomedical data, including gene expression profiles, protein interaction networks, and known drug databases, to identify key molecules and biological pathways associated with liver fibrosis.
When comparing its proposed series of potential treatments against traditional fibrogenic inducers (as negative controls) and inhibitors (as positive controls), all drugs suggested by the AI co-scientist showed promising activity (p-value less than 0.01). This suggests a high probability that these drugs could be effective in treating liver fibrosis.
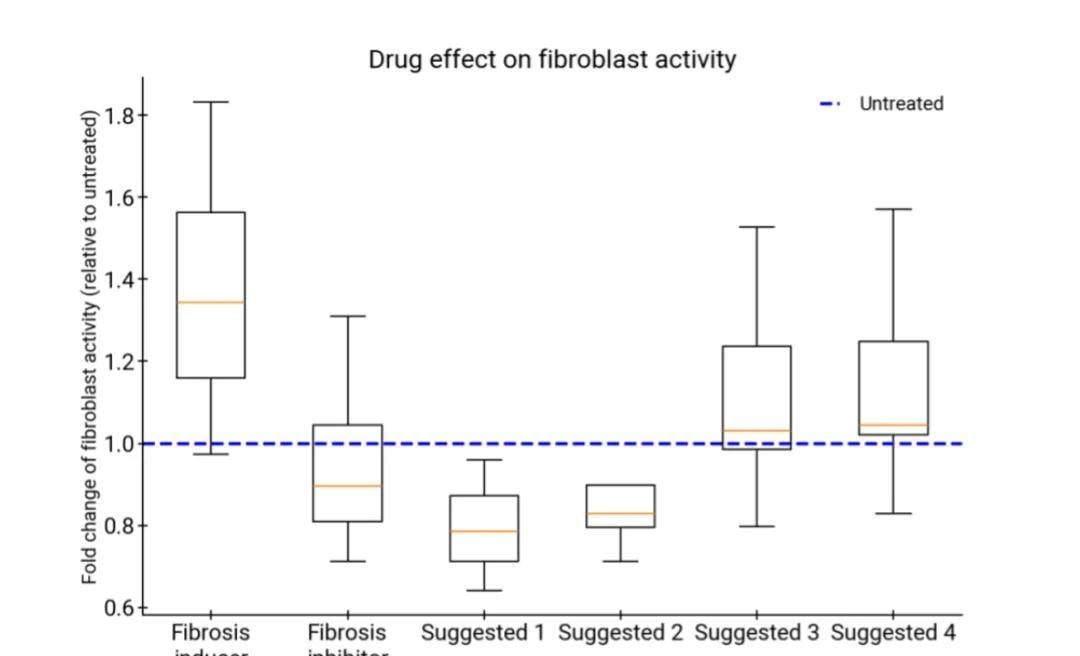
On licensing, automated hypothesis generation risks devaluing the domain expertise required to frame valid biological questions.
Finally, in the third experiment, by analyzing extensive genetic, protein structure, and drug activity data, the AI co-scientist was also found to be capable of identifying and predicting potential mechanisms of bacterial resistance. Specifically, regarding capsid-forming phage-induced chromosomal islands (cf-PICIs), researchers utilized the AI co-scientist’s capabilities to explore the presence and functional mechanisms of cf-PICIs across various bacterial species.
By analyzing and integrating vast amounts of biological literature and data, the AI co-scientist independently proposed a new hypothesis:
cf-PICIs may expand their host range by interacting with tails of multiple phages.
This hypothesis was subsequently validated through laboratory experiments.
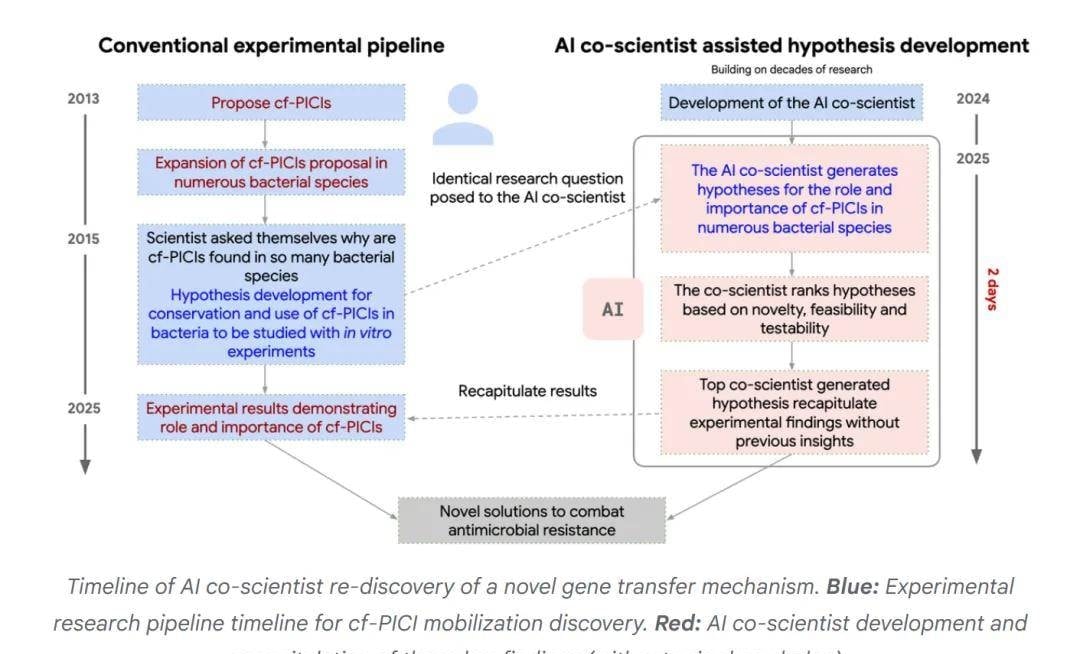
I think when AI proposes the mechanism and humans merely validate it, the creative spark of discovery shifts from insight to verification.
However, it is important to note that while the AI co-scientist has achieved a series of preliminary results in scientific discovery, Google also highlighted its limitations:
Literature review capabilities, fact-checking, cross-checking with external tools, automated evaluation techniques, and larger-scale assessments all require further improvement.

For creators, if the tool cannot reliably cross-check facts, researchers must spend more time auditing outputs than conducting experiments.
Researchers or teams interested in participating can now apply.
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google