The burden of proof now shifts to Guanglun Intelligence (Lunaria) to demonstrate that its synthetic data pipeline actually de-risks the deployment of physical AI for the enterprise clients on its roster.
Just now, a financing round by an AI company sparked intense discussion within our desk’s monitoring of the sector. The interest stems from the company’s tight coupling with embodied intelligence and the world models required for physical AI. More precisely, this entity is a critical supplier in the ecosystem bridging simulation and reality: a provider of simulation-based synthetic data.
I read that Guanglun Intelligence (Lunaria), a simulation synthetic data company, has just completed Series A and A+ financing rounds totaling hundreds of millions of yuan.
The disclosed investors include institutional players such as Orient Fortune Capital and Jiupai Capital, as well as industrial stakeholders like 37 Interactive Entertainment and Amber Capital. Existing shareholder Chentao Capital has also continued to increase its stake.
Equally noteworthy are its client roster, which includes Nvidia, Google, Alibaba, ByteDance, Figure AI, 1X Technology, Zhiyuan Robotics, Galbot, Toyota, Bosch, BYD, Geely, and more.
It single-handedly connects the entire AI ecosystem.
Rumors suggest that this company, the only global firm specializing in simulation synthetic data, has already broken through the 100 million yuan revenue mark.
As the world’s first company to integrate generative AI into simulation technology, Guanglun Intelligence was founded by Xie Chen, a prominent figure in the industry who previously served as the head of simulation at Nvidia, Cruise, and NIO.
Its recent breakout moment came from its inaugural interview with Madison Huang, daughter of Nvidia CEO Jensen Huang, discussing physical AI—the current hot topic.
Physical AI is the trend ignited by Jensen Huang earlier in 2025, but within just a year, inflection points for this trend are being continuously validated.
Guanglun Intelligence stands at this inflection point, which is the core reason it has attracted attention and optimism.
Hidden Champion in Embodied AI Secures Hundreds of Millions in Funding, Surpasses $100M Revenue
Why is it so promising? Because the trend inflection point has truly arrived.
The shift from information processing to physical interaction marks a critical governance and technical threshold. As AI moves into scenarios requiring object manipulation and environmental adaptation, existing systems reveal significant gaps. Fei-Fei Li’s essay From Words to Worlds highlights that human understanding extends beyond immediate visuals to spatial relationships and semantic meaning. This “spatial intelligence” is the core breakthrough for the next phase of AI development.
I think the burden of proof now lies on demonstrating safety in unstructured physical environments, not just digital accuracy.
Global research and industry sectors are focusing on world models and embodied intelligence as the pathways to bridge this gap. Both directions aim to enable model interaction with the physical world. Crucially, training these models no longer relies solely on image-text alignment or language-labeled data; it requires multimodal interaction process data. This data must possess scalability, structure, and strong controllability.
The industry-standard data pyramid categorizes training inputs into three types:
- Real-world teleoperation data
- Simulation synthetic data
- Human video data

Simulation synthetic data and human video data are considered “model-agnostic,” making them easier to standardize and generate at scale. Between these two, simulation synthetic data offers clearer structure, higher precision, stronger controllability, and a higher ROI (Return on Investment).
My sense is enterprises must verify the provenance of synthetic data to ensure it does not encode biases present in their generating algorithms.
In embodied intelligence, training both the “cerebellum” and “cerebrum” models for robots demands large amounts of simulation synthetic data. Cerebellum models, in particular, show an even higher dependence on high-fidelity simulation data. World models also exhibit a strong demand for this type of data. Fei-Fei Li emphasized in From Words to Worlds:
(For training world models), the role of high-quality synthetic data and additional modalities (such as depth, touch) cannot be underestimated; they play a supplementary role during key stages of the training process.
Moreover, compared to embodied VLA foundation models deployed on edge devices, cloud-applied world models require data at a much larger scale.

This demand stems from the pursuit of generalization and physical prediction, which requires larger-scale, more standardized data. Real-world data faces fundamental bottlenecks in scarcity, cost, and coverage. Physical-realistic simulation synthetic data can significantly enhance the physical understanding and predictive capabilities of world models, becoming a key demand direction for customers.
What concerns me is that the scale disparity between edge and cloud models creates distinct liability profiles that enterprises must audit separately.
A consensus emerges: Simulation synthetic data is currently the solution that best meets the data needs of embodied intelligence and world models.

Recent major advancements in embodied intelligence and world models are strongly correlated with simulation synthetic data. Fei-Fei Li’s team, collaborating with the Stanford AI Lab, developed a complete synthetic pipeline to generate “hundreds of millions” of high-quality vision-language-action data samples. This led to the BEHAVIOR Challenge, a benchmark for humanoid robot competitions aimed at promoting embodied intelligence in complex real-world home environments.
Looking at Nvidia’s released open-source humanoid robot foundation model GR00T N1.5, its pre-training and post-training data both contain large amounts of simulation synthetic data provided by Guanglun I
Hidden Champion in Embodied AI Secures Hundreds of Millions in Funding, Surpasses $100M Revenue
The burden of proof in embodied AI has shifted from pure algorithmic novelty to data determinism. As enterprises scale world models, they are no longer looking for supplementary resources but for fundamental elements that guarantee training stability. I read the recent developments closely: the industry is pivoting toward controllable, high-fidelity simulation synthetic data as the only scalable path forward.
The Shift from Supplementary to Fundamental
Intelligence systems are now using these methods to improve generalization capabilities for new objects and environments. These two achievements come from representative teams in academia and industry, respectively, yet they rely on consistent core data: controllable, high-fidelity simulation synthetic data.
The needs of technological progress have elevated simulation synthetic data from a “supplementary resource” to a “fundamental element.”
Almost simultaneously, Generalist AI threw a bombshell into the industry by releasing the GEN-0 embodied foundation model. This model was trained on 270,000 hours of human operation video data, marking the first validation of Scaling Laws in the data direction within the field of embodied intelligence.
This is an important signal of a paradigm shift in data for world models and embodied intelligence.
I think generalist AI’s move validates data scale as a primary driver, not just an afterthought. My sense is enterprises must verify if their internal data pipelines can handle this volume of video training. What concerns me is that the “first validation” claim sets a high bar for competitors lacking similar datasets.
Deterministic Training Fuel
These achievements collectively drove a shift in industry training paradigms and triggered a surge in data demand.
Simulation synthetic data, which possesses the greatest capacity for continuous expansion and engineering scalability, has become the most deterministic training fuel for embodied intelligence and world models.
On this track providing certainty, the hidden champion company is Guanglun Intelligence.
I think “Deterministic” is a strong word in AI; enterprises should audit these claims against their own risk frameworks.
Hidden Champion in Embodied AI Secures Hundreds of Millions in Funding, Surpasses $100M Revenue
Why is it so promising? It is a hidden champion in the data sector.
Guanglun Intelligence positioned itself early in this paradigm shift, completing technical validation before the broader market caught up. While the industry treated simulation synthetic data as merely a “research supplement,” Guanglun had already closed the loop on technical exploration, product definition, and engineering deployment.
Today, Guanglun Intelligence has essentially become part of the industry ecosystem—
It is deeply involved in the underlying co-construction of Nvidia’s simulation systems, serving as an early validator and development partner for the Newton physics engine. It also participated in the formulation of SimReady simulation data asset standards and the core construction of the Isaac Lab Arena strategy evaluation platform.
These projects conducted system-level collaboration based on technical capability as a prerequisite, rather than simple interface cooperation.
To put it simply, Guanglun’s simulation synthetic data capabilities have been embedded into the standard workflow for training world models, forming an irreplaceable role across three dimensions: underlying engines, data standards, and evaluation platforms.
This recognition is most convincingly demonstrated by Nvidia—the cornerstone company in the AI wave.
In mid-October, Madison Huang, daughter of Jensen Huang and Senior Director of Omniverse and Physical AI at Nvidia, made her first public appearance on a live interview program with Guanglun Intelligence CEO Xie Chen and Growth Lead Mustafa. They engaged in an in-depth discussion on “how to narrow the gap between robots in virtual and real worlds.”
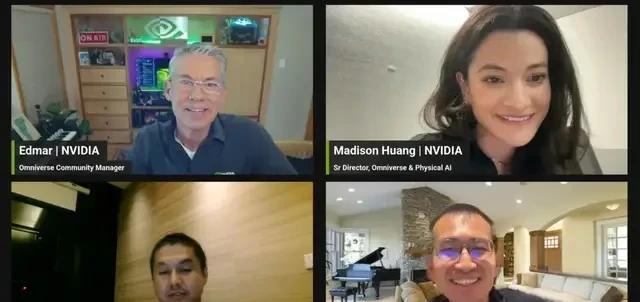
My sense is executive visibility with Nvidia signals strategic alignment, but enterprises must verify if this translates to contractual exclusivity or preferential pricing.
Earlier this month, during the keynote speech at Nvidia’s GTC DC conference, Jensen Huang showcased collaborative simulation results between Guanglun and Isaac Sim/Newton. The event featured a comparison of robotic arms completing fabric folding tasks across different simulation platforms. Despite using different underlying solvers, the simulated behaviors were highly consistent.
This demonstration not only highlighted Guanglun’s engineering capabilities in cross-platform high-fidelity simulation but also marked that its technical status in the global embodied intelligence training ecosystem is being confirmed by mainstream systems.

What concerns me is that high-fidelity consistency across solvers reduces integration risk, yet enterprises should audit the specific liability clauses for simulation errors in their contracts.
Secondly, Guanglun’s client base itself serves as a sample of industry trends.
With the rapid iterative development of embodied intelligence and world models, Guanglun’s customer group almost covers all typical institutions with high-intensity demands for simulation synthetic data.
We reviewed Guanglun’s official presentation materials and compiled its publicly disclosed client list, including but not limited to:
- Large Model Companies: Nvidia, Google, Genesis AI, Alibaba, ByteDance…
- Robot body/platform companies: Figure AI, 1X Technology, Zhiyuan Robotics, Galbot…
- Industry Companies: Toyota, Bosch, BYD, Geely…
It is said that due to various reasons, some partners have not been disclosed publicly, but they are undoubtedly Big Names in the industry.
Several senior figures close to the data industry revealed three pieces of information to us:
First, Guanglun’s clients basically cover all the strongest international embodied large models and world models. Second, more than 80% of the simulation assets and synthetic data for major international embodied teams come from Guanglun. Third, Guanglun has already served all top three global world model companies.
I think an 80% market share claim requires independent verification; enterprises must assess supply chain concentration risk before committing long-term resources.
The importance of simulation synthetic data to the industry, as well as Guanglun’s current strength, goes without saying.

As demand expands, Guanglun’s service positioning is no longer simply “supplying simulation synthetic data.” Aligning with market demand rhythms, its services have expanded to cover the entire lifecycle.
In the pre-training phase, it provides synthetic dat
Hidden Champion in Embodied AI Secures Hundreds of Millions in Funding, Surpasses $100M Revenue
The burden of proof for embodied AI viability now rests on data infrastructure providers who can close the loop between simulation and reality. Guanglun Intelligence is positioning itself as that critical node, moving beyond simple data supply to offer a full-lifecycle service model. This shift demands rigorous verification from enterprises regarding compliance, safety standards, and the actual generalization capabilities of synthetic training sets.
The Full-Process Service Model
Guanglun’s approach integrates human video data to build generalization capabilities during the initial phase. In post-training, it provides high-quality simulation synthetic data and supports model fine-tuning through reinforcement learning. Finally, in the testing phase, it offers simulation platform services and evaluation standards, assisting customers with test-time evaluations and launch validations.
This seamless full-process service of data, platforms, and evaluations has become a standard cooperation path used by many leading clients.
I read this as a move toward locking in enterprise contracts through dependency on their proprietary evaluation metrics.
My sense is enterprises should verify if these “standard paths” create vendor lock-in risks. What concerns me is that the closed-loop flywheel reduces friction but increases reliance on Guanglun’s specific stack. I think governance teams must audit the synthetic data sources for bias and safety compliance.
This is also the essential difference between Guanglun Intelligence and previous-generation data suppliers: providing not just data, but full-process, full-lifecycle services for data—a data flywheel with an end-to-end closed loop.
This full-process data capability has allowed AI industry ecosystem customers to recognize Guanglun Intelligence’s golden positioning through demand feedback and “voting with their feet.”

Revenue Validation and Market Confidence
This golden positioning is also reflected more intuitively in tangible cash-generating capabilities. This website has learned that although still in its early startup stage, Guanglun Intelligence’s annual revenue has already broken through 100 million yuan.
This level of income represents not only growth speed but also the reliability of delivery capabilities and business models.
Founder Xie Chen mentioned in a public interview that securing the first client after the company’s establishment in 2023 was not easy.
But once word-of-mouth began to spread, it is said that Guanglun’s customer numbers started expanding continuously and at an accelerated pace. The latest report states:
Revenue exceeds last year by more than ten times, surpassing 100 million yuan.
I followed the release noting that rapid revenue scaling in B2B AI infrastructure often signals strong product-market fit but requires scrutiny of contract durations and renewal rates.
My sense is tenfold growth warrants due diligence on customer concentration risk. What concerns me is that revenue exceeding 100 million yuan validates the synthetic data market demand.
This change in supply and demand is a direct market feedback on the value of simulation synthetic data.
Additionally, as the saying goes, “Ducks know first when the river warms.” This website also learned that this golden positioning has provided Guanglun Intelligence with a unique perspective: large models, embodied intelligence, world models… every aspect of the AI industry
Before a windfall sector takes off, its potential is often foreshadowed by the business needs of companies like Guanglun Intelligence.
This is also the key reason why the use of funds from Guanglun’s latest funding round has drawn extra attention.
Hidden Champion in Embodied AI Secures Hundreds of Millions in Funding, Surpasses $100M Revenue
Behind the Hundreds of Millions in Funding Lies the Trajectory of an Entire Industry
The burden of proof now shifts to enterprises: can they secure the supply chain for high-fidelity data before competitors lock it down? As I followed this development, it became clear that Guanglun Intelligence’s latest funding round is less about immediate cash and more about securing the infrastructure layer for physical AI. An investor told us that the primary purpose of Guanglun Intelligence’s current funding round is to expand supply and strengthen its capacity for scaled delivery.
Synthetic data, which already leads the head market, is driving a pivotal transformation in embodied AI.

From an investment perspective, there is reason to believe that this funding round reveals not only a valuation judgment of Guanglun itself but also shifts in the rhythm of the entire sector.
World models and embodied AI cannot rely on existing internet data. The training bottleneck lies neither in algorithms nor in computing power, but in the ability to continuously supply high-quality structured data. The industry is entering a phase where “data determines performance.”
It is important to note that technological iteration is rapid, and industry progress leaves players with no patience for waiting for data to catch up slowly. There is an urgent need to quickly find service providers capable of synchronously delivering controllable, high-fidelity, and scalable data, ensuring long-term, guaranteed support.
Can it cover pre-training, post-training, and testing phases or the entire workflow? Can it meet multi-model interface adaptation requirements? Can it continuously improve effectiveness within a closed loop of training-generation-retraining?
Competition is intensifying, and every data company will face these questions countless times.
Guanglun’s advantage lies in the fact that these capabilities are already complete. Thus, it has once again taken the lead by extending its goals to a longer-term positioning:
Building the data infrastructure for physical AI.
For Guanglun, this goal is the natural evolution of its business—
The training of embodied AI and world models is long-term and dynamic; demands increase as projects progress. It is impossible for every team to build its own simulation systems or video collection pipelines. The industry naturally requires a “shared data foundation.”
Guanglun started early, possesses a complete technology stack, and has a massive customer base. If it does not act now, other players will inevitably step in soon.
Leveraging first-mover advantages for long-term planning is both grounded in reality and in line with the trend.

Furthermore, behind the new developments in Guanglun’s financing lies a shift in industry perspectives on data:
Data is transforming from “procured resources” into “serviceable platforms.” Embodied AI and world models, which cannot directly consume internet data, require massive ingestion of custom-generated structured scenario data.
Whoever can continuously supply high-quality simulation and human behavior data holds the underlying resources for next-generation intelligent systems. The value of data companies is embedded in this transition.
The wave of change in AI 2.0 has entered a period where infrastructure reform centered on data is paramount.
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google