Skip Couplets in 2026: Let AI Write a New Year Song for You
AI is quietly surpassing me in yet another aspect—this time, it has better pitch than I do!
This isn’t just a novelty. It’s a signal that the barrier to entry for professional-grade music production has collapsed. For buyers and investors, this marks the end of the “human-in-the-loop” premium for basic composition. If you’re still paying for mid-tier songwriters in 2026, you’re overpaying.

Audio link: https://mp.weixin.qq.com/s/yDWVdeQuGxPgXzNLcxFLvg
The story goes like this:
A young man who has just finished his exams and graduated expresses his reluctance to part with his teachers and classmates. It captures the unique innocence and greenness of youth, while also harboring full anticipation for the future.
Impressive production, right? The dynamic rhythm, smooth melody, and emotional ups and downs all maintain a professional standard.
But would you believe it? From lyrics to arrangement, the entire song was generated with one click by AI.
Those “Little Dao Langs” simply expressed their thoughts in a single sentence, waited less than a minute, and produced a complete 2–6 minute track with stable structure, consistent pitch, and natural vocal timbre that doesn’t drift.
All of this comes from FreeQuantum, an AI company focused on self-developed music large models, which recently released its new model—YinChao V3.0.
Compared to the previous generation, YinChao V3.0 has achieved significant improvements in vocal quality, overall listenability and memorability, arrangement richness, and musical completeness.
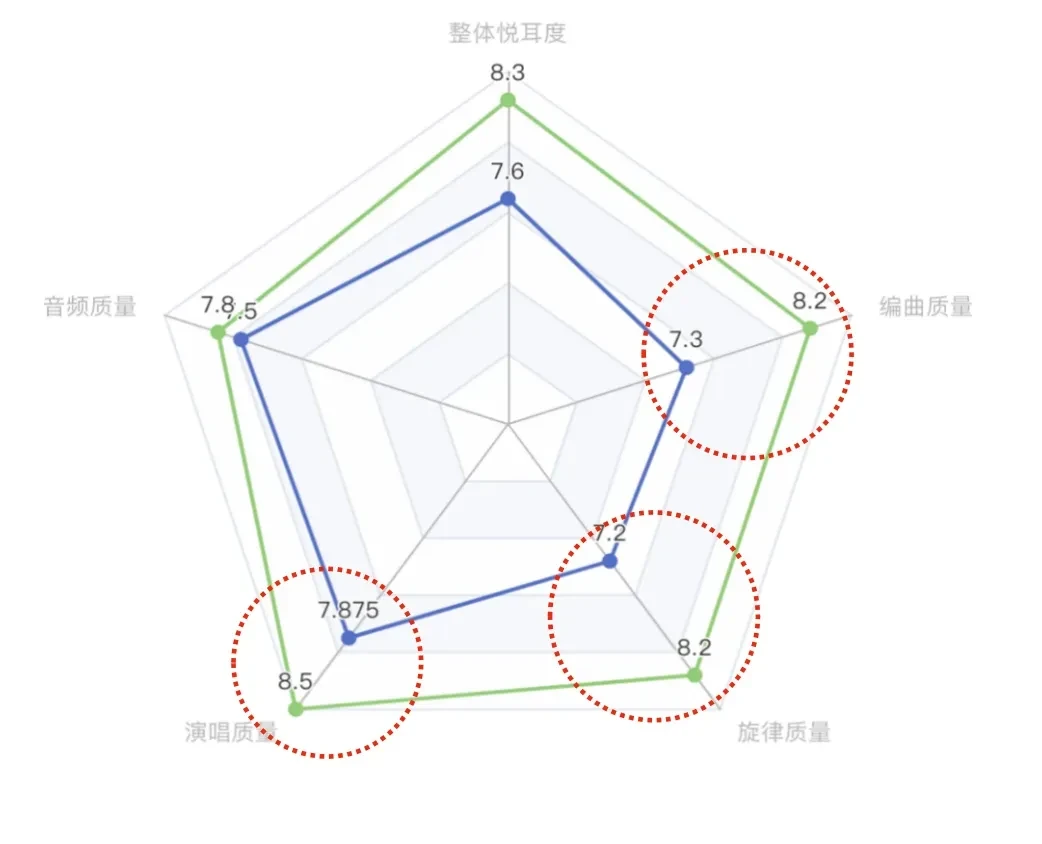
Currently, YinChao V3.0 is officially available on the web platform and official App, open for free trial to all users.
In that case, it’s time for us at this website to put our skills to the test. Let’s dive in~
AI “Soul Singer” Writes Songs For You
The app interface presents four distinct creation modes: One-Sentence Songwriting, Photo-to-Song, Lyrics-to-Song, and Hit Song Remix.
Users can also create custom voices, using their own recordings to generate tracks. This feature allows anyone, regardless of vocal ability or songwriting skill, to produce a debut track instantly.

I tested the “One-Sentence Songwriting” mode. It is straightforward: you input a sentence describing the desired style or content.
For example, I entered a prompt wishing for good luck in the new year and driving away bad luck:
Go away! Bad luck, scatter! The exclusive battle anthem to banish misfortune.
If users struggle with phrasing, the system offers “One-Click AI Polish” and “Inspiration Prompts” features. These tools further lower the barrier to entry.
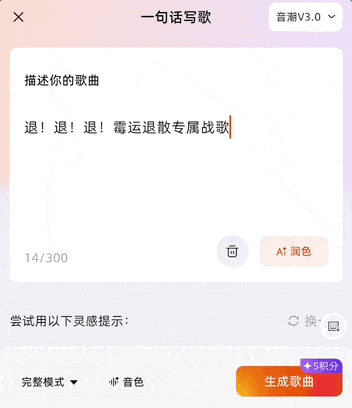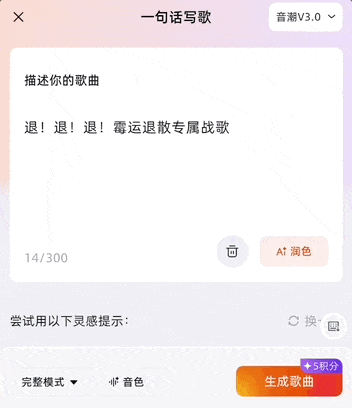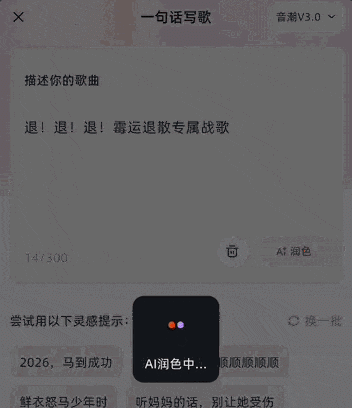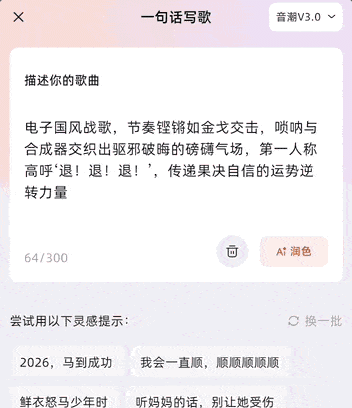
After entering your prompt, you can flexibly choose between two creation modes based on specific use cases.
- “Snippet Mode” is designed for short-form content scenarios like short videos and social media sharing, directly generating compact segments with prominent climaxes.
- “Full Version Mode” generates mature works lasting 2–6 minutes, covering complete structures including verses, choruses, and interludes, making it more suitable for personal projects or deep expression.
The system automatically matches recommended voices based on the song style. If you’ve previously created a personalized voice profile, you can select it here to give your work greater individuality.
Once all settings are ready, click the “Generate Song” button.
In less than a minute, an entirely new song belonging to you is created. Let’s listen:

Audio link: https://mp.weixin.qq.com/s/yDWVdeQuGxPgXzNLcxFLvg
The prompt was understood well, the melody is clear, and the rhythm hits hard—it’s quite catchy (I’ve already started looping it).
The lyrics consistently revolve around the core theme of “bad luck goes away, good luck arrives,” with frequent golden lines:
“You shout once, I light a lamp; together our harmony overturns the night. We don’t wait for the wind to come; we generate our own.” “Pack up old worries and mail them to the Arctic Circle.” “Today, only accept deliveries, not bad news…”
This little AI is quite internet-savvy and knows how to write well.

English songs are also supported, with equally impressive results:

Audio link: https://mp.weixin.qq.com/s/yDWVdeQuGxPgXzNLcxFLvg
Of course, if you’re already skilled at writing lyrics or have existing ones, you can directly use the “Lyrics-to-Song” mode.
In this mode, you simply copy and paste your lyrics into the input box and make basic paragraph divisions. It supports various common structural sections such as verses, choruses, interludes, and bridges, and you can also use the built-in “Lyric Optimization” feature to polish them with one click.
Styles are set separately below the input box. The official platform provides multiple preset styles and also supports customization. Genres, emotions, instruments, languages (Chinese/English), and vocal gender can all be freely selected.
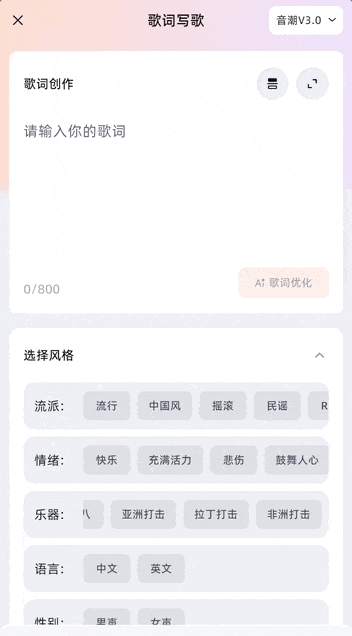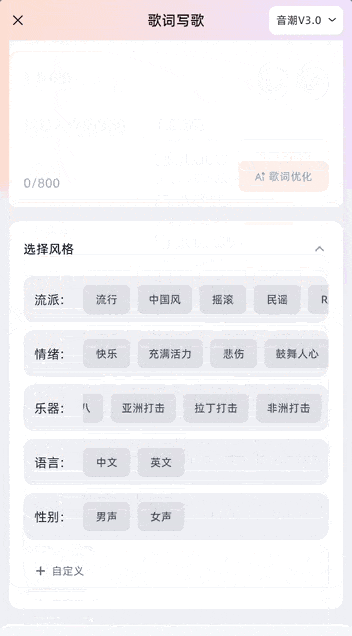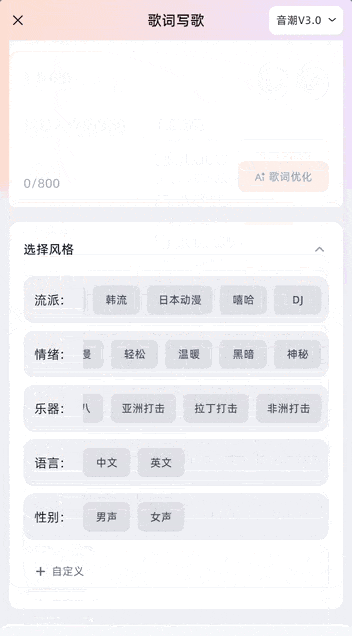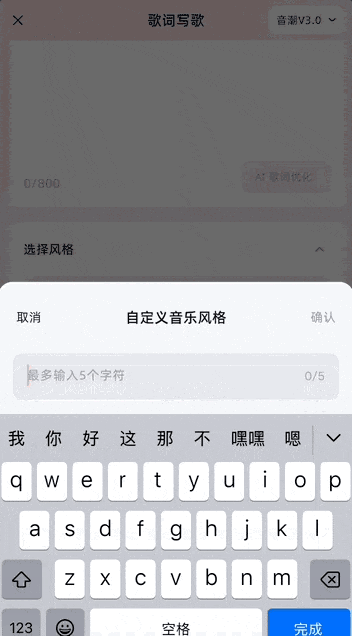
For example, simply input a short, romantic lyric snippet to have the AI optimize and polish it with one click, then compose music based on those lyrics. The final product is ready:
Video link: https://mp.weixin.qq.com/s/yDWVdeQuGxPgXzNLcxFLvg
As the vinyl spins softly, creating a lazy and i
Honestly, this is consumer-grade entertainment, not a professional production tool. I think custom voice cloning raises serious copyright questions for the industry.
Skip Couplets in 2026: Let AI Write a New Year Song for You
The barrier to entry for music generation just collapsed again. If you’re an investor watching the generative audio space, look at the velocity of feature integration here. We are moving from text-to-audio to image-to-song in months, not years. This isn’t just about novelty; it’s about capturing user attention through effortless creation.
The latest capability is Photo-to-Song. It strips away the friction of prompt engineering. You upload an image, and the model infers the mood. It generates matching lyrics and melody automatically. No style settings required.
I tested the snippet mode with a random reference image. The output was immediate.
Video link: https://mp.weixin.qq.com/s/yDWVdeQuGxPgXzNLcxFLvg
The model handles diverse genres without apparent struggle. I tried a photo taken from inside a car during a road trip. It generated background music suitable for social media travel posts.
Video link: https://mp.weixin.qq.com/s/yDWVdeQuGxPgXzNLcxFLvg
There is also a Hit Song Remix feature. It creates adaptations based on existing works. I didn’t test this deeply, but the capability exists for users who want to tweak established tracks.
Crucially, all Yinchao-generated songs are downloadable as audio or video files. The videos include AI-generated cover art by default. You can edit song titles before sharing. This reduces the friction of distribution significantly.

My assessment after thorough testing is straightforward. Yinchao simplifies music creation far beyond initial expectations. Users without music theory or instrumental skills can now produce complete songs based on simple emotional prompts. Daily fragments of thought become shareable audio assets.
The quality withstands repeated listening. Melodic progressions feel natural. Choruses contain memorable hooks. The arrangement structure is coherent, avoiding the patchwork feel common in early AI music. Vocal details are restrained, lacking stiffness or overt mechanical artifacts. These are polished works, not just trials.
The way I see it, the downloadability and auto-cover art features solve real distribution friction for casual creators. Honestly, quality has crossed from novelty to shareable content; the “uncanny valley” of AI music is narrowing.
So, how does Yinchao achieve this level of polish?
Yinchao V3.0: The Aesthetic Ceiling Breaks
The End of the “Algorithmic Ceiling”
I’ve watched AI music models hit a wall for years. Pure algorithmic iteration fails because it cannot translate abstract music theory into concrete optimization goals. There is a natural cognitive gap between code and art. Yinchao claims to have broken this barrier with its V3.0 release.
The secret isn’t just better silicon; it’s personnel. The team integrates musicians directly into technical discussions. They translate intuitive musical feelings into rational algorithmic language. This “Music + Technology” dual-helix drive injects professional knowledge into the codebase. It shifts generation from unidirectional reasoning to creative acts based on theoretical cognition.
I think human-in-the-loop design beats pure scale when solving subjective aesthetic problems. The way I see it, cross-disciplinary teams are the only viable moat against generic AI mediocrity.
Vocal Separation and Emotional Nuance
The most immediate upgrade is vocal quality. Yinchao V3.0 uses a self-developed dual-track modeling mechanism[1]. It separates vocals from accompaniment, learning features in different semantic spaces before fusing them structurally. This prevents information interference while matching rhythmic synergy.

The team also introduced layered enhancement strategies from its HEAR framework[2]. This ensures accurate replication of melisma and glissando. More importantly, it strengthens emotional perception through hierarchical learning. The model no longer just sings in tune; it adjusts tone based on context. Sadness becomes restrained emotion. Passion becomes driven tension. Vocals now possess narrative capability.

Honestly, semantic-aware vocal control is the new standard for usable AI music. I think emotional nuance requires architectural changes, not just more data.
Melodic Hooks and Arrangement Coherence
Current AI music suffers from a lack of memorable hooks. Yinchao V3.0 addresses this by enhancing motif design capabilities. The distribution of tension between notes shows greater structural awareness. Climaxes and build-ups are clearer, making choruses recognizable. It can now “write choruses” rather than just generating linear flows.
Once melody and vocals align, arrangement coherence improves significantly. Style modeling automatically matches instrumentation to genre. Instruments divide labor around the main melody instead of stacking randomly. Transitions between sections are natural; bridge connections are smooth. Rhythmic layers are distinct.
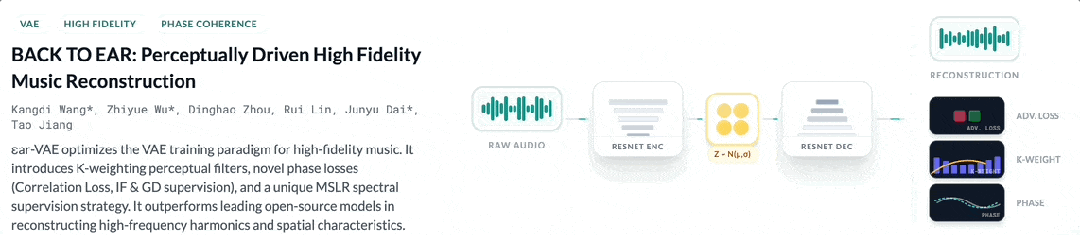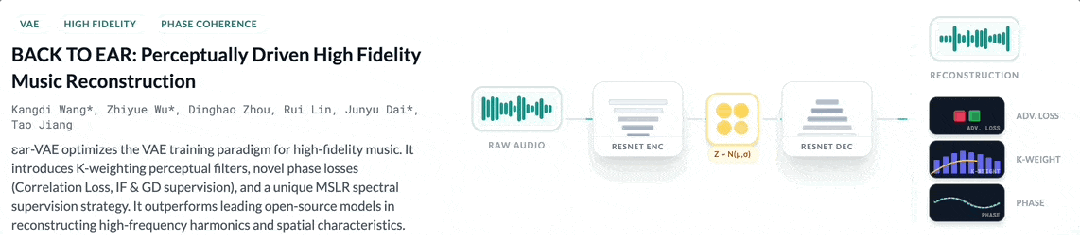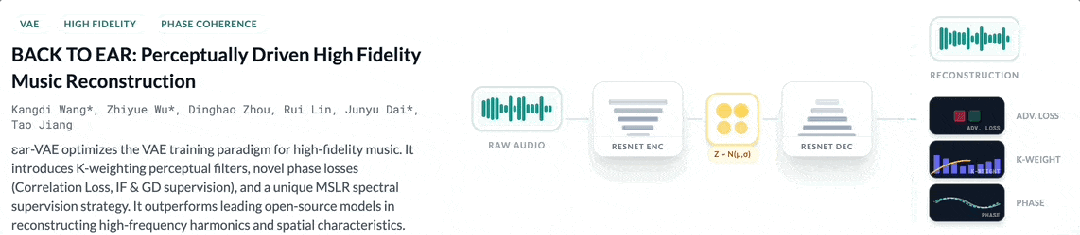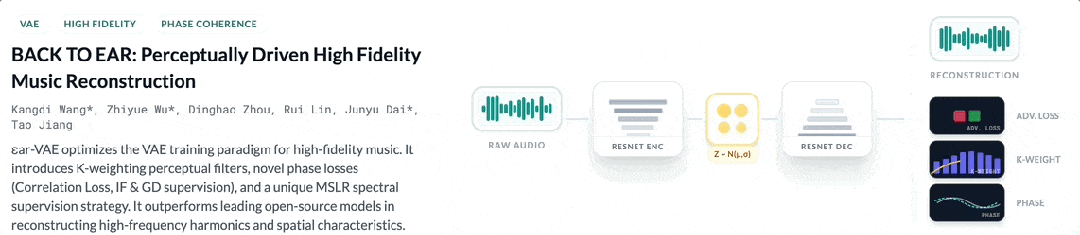
Spatial Fidelity via ϵar-VAE
The “physical texture” of sound has been re-polished. Yinchao V3.0 employs its team-developed ϵar-VAE[3] core technology. This independently models spatial information throughout the entire generation pipeline. It introduces representation and supervision methods for spatial data. The result is high-fidelity reconstruction of temporal-spatial shifts, such as Tom fills in drum sections or automated panning effects.
The way I see it, spatial modeling is essential for distinguishing pro-grade audio from demos. Honestly, ϵar-VAE targets the final 10% of quality that separates pros from amateurs.
The Moat Is Data, Not Just Code
The audio industry has spent years chasing “high fidelity” as a marketing buzzword. FreeScale’s latest release proves that true quality isn’t just about frequency response—it’s about spatial layering and instrument grain. I read their technical breakdowns, and the shift is palpable: AI is no longer generating noise; it’s reconstructing complex arrangements with human-like intuition.
This isn’t a incremental update. It’s an architectural overhaul of how we evaluate machine-generated music. The listening experience has moved beyond simple specs to restore the emotional weight of production design.
I think fidelity is now a baseline, not a differentiator. Buyers must look at spatial reconstruction capabilities.
Solving the Subjectivity Problem
Music evaluation remains a subjective mess. There are no absolute objective metrics for “good” sound. FreeScale recognized this bottleneck early and built a solution that most competitors ignored: a professional human review team paired with fine-grained systems.
They didn’t just ask machines to score audio. They mapped human aesthetics into the model’s parameter space. The dimensions they track are granular—melodic motifs, vocal tone handling specific to Chinese language nuances, arrangement richness, and stylistic unity. This is how you achieve “human-machine aesthetic alignment.”
Dr. Jiang Tao, CTO and Executive CEO of FreeScale, framed this as their core challenge: “How to converge the tastes of annotators from different backgrounds into a universal, credible consensus on aesthetics, and use data to help models truly understand this beauty?”
They iterated through countless versions to answer that question. The goal is simple: make AI creative judgment indistinguishable from senior industry intuition.
The way I see it, subjectivity can be quantified if you invest in the right human-in-the-loop infrastructure.
Validating Against Global Peers
Theory means nothing without benchmarks. At ICASSP 2026, an international top conference in acoustics and audio, FreeScale’s AI music evaluation system (BAL-RAE) faced fierce global competition.
The results were announced during the inaugural “Automatic Song Aesthetics Evaluation Challenge.” FreeScale secured second place globally in Task 1 (Comprehensive Song Aesthetic Scoring). This validates their approach against other major research teams worldwide.
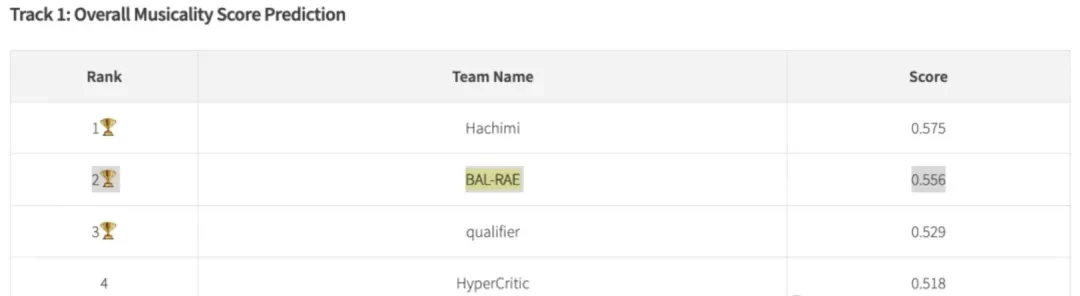
From pioneering days with zero models to leading industry standards in “human-like feel” and musicality, the trajectory is clear. FreeScale’s moat comes from long-term, steadfast investment in full-chain architecture, data curation, and aesthetic alignment. They didn’t get lucky; they engineered this lead.
Honestly, second place at ICASSP 2026 confirms their evaluation engine is tier-one globally.
The Open-Source Gambit
The music tech sector is notoriously closed-source. Commercial solutions are usually hidden behind walls. FreeScale could have kept their self-developed system proprietary to advance quietly. Instead, they chose to open-source some of their research results and modules externally.
This is a strategic anomaly. On the product side, they enable everyone to write songs. On the technical side, they pave the way for other teams. For a company with viable commercial solutions to contribute technical details to the open-source community is rare. It signals confidence in their underlying architecture rather than fear of leakage.
More open-source achievements are available on FreeScale’s technical team ear-lab homepage: https://eps-acoustic-revolution-lab.github.io/ear-lab

Technology at this level is rarely accidental. The team behind it deserves scrutiny, not just because of the output, but because of the transparency they’ve forced into a closed industry.
I think open-sourcing core modules is a power move that accelerates ecosystem dependency on their standards.
The Human Element in the Machine Loop
I read the release notes from FreeScale, and what stood out to me is their refusal to treat music AI as a pure engineering problem. Founded in 2023, they are betting on a core team where every member is a musician. CTO Jiang Tao claims his algorithm team could form a full band—wind, strings, percussion, vocals included. I saw the photos; guitars and Populeles sit casually on desks next to servers.
This isn’t just marketing fluff. The head of their evaluation team writes lyrics for top-tier artists while speaking fluent code. He bridges the gap between emotional tension in music and metric logic in algorithms. It creates a necessary tug-of-war. Sometimes an AI track feels infectious but fails spectrogram checks. Other times, technical “fuzziness” sounds more realistic to human ears than clean data suggests.
The way I see it, a musician-led dev team is a moat against generic, soulless synthetic audio. Honestly, freeScale’s hybrid approach balances cold metrics with warm emotional resonance.

Commercial Traction and Copyright Clarity
I followed their deployment strategy, and it is aggressively practical. YinChao, their model, is already in the supply chain for music generation APIs. They cover MV generation and image-to-video conversion. Offline KTV collaborations are underway. Users may soon sing AI-original songs in private booths. The 2025 World Artificial Intelligence Conference (WAIC) theme song, AI For Good, was fully supported by YinChao—from lyrics to vocals.
The legal framework is equally direct. YinChao’s user agreement explicitly assigns copyright of AI-generated music to users. They even assist with certification. This removes the biggest friction point for professional adoption. Music consumption is layered and scenario-specific. FreeScale targets the sweet spot closest to everyone, from film scores to social media background tracks.
I think assigning copyright to users solves the enterprise adoption bottleneck immediately. The way I see it, kTV integration turns a creative tool into a recurring revenue stream.
Democratizing the “Jay Chou” Effect
Jiang Tao’s philosophy is blunt: ride-hailing drivers and delivery riders have stories but lack tools. He believes they could be the next generation of pop stars. This isn’t just idealism; it’s a market expansion strategy. By lowering the barrier to entry, FreeScale taps into a massive, untapped user base that traditional music tech ignores.
The team emphasizes enabling everyone to create music. At a mechanistic level, this means robust tools for non-musicians. At a philosophical level, it validates the emotional output of AI as legitimate art. The collision between technical control and emotional surprise is where the value lies. I see this as a shift from music as a product to music as a utility.
Honestly, targeting non-musicians expands the TAM far beyond professional producers. I think emotional authenticity, not just technical perfection, will drive consumer adoption.
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google