The core technical claim is that “Top Test-Taker: I Broke the Large Language Model,” an LLM-native app by Fan Haoqiang’s team and StepFun, successfully creates engaging adversarial challenges where AI agents maintain consistent personas against human interrogation. This would be falsified if the agents’ responses were easily distinguishable from humans via standard probing or if the underlying multi-agent architecture failed to sustain role consistency under pressure.
I think the shift from weekend to weekday traffic suggests this tool is being integrated into actual work routines, which raises immediate productivity concerns for employers. From the paper, relying on StepFun’s multimodal support implies a dependency on external infrastructure that may not be transparently documented in the public release notes.
Behind the scenes, backend data from their viral previous hit, “Oh No! I’m Surrounded by Large Language Models,” revealed an interesting phenomenon: Weekend traffic was average; weekdays saw the most players (doge).
However, due to limited computing resources, just as everyone was enjoying themselves, the game shut down!
This time, a better-prepared team has unveiled their latest LLM application, titled “Top Test-Taker: I Broke the Large Language Model.” Everyone is welcome to enjoy some reasonable slacking off.
(Laughing out loud: Last time we were surrounded by LLMs; this time, us carbon-based lifeforms are launching a fierce counterattack.)

The core member of the team behind this project is Fan Haoqiang, the sixth employee at Megvii, and currently the General Manager of Research at Megvii Technology.
He was hailed as a child prodigy for his legendary achievements: winning an International Olympiad in Informatics (IOI) gold medal, gaining direct admission to Tsinghua University’s “Yao Class,” and interning while still in high school.
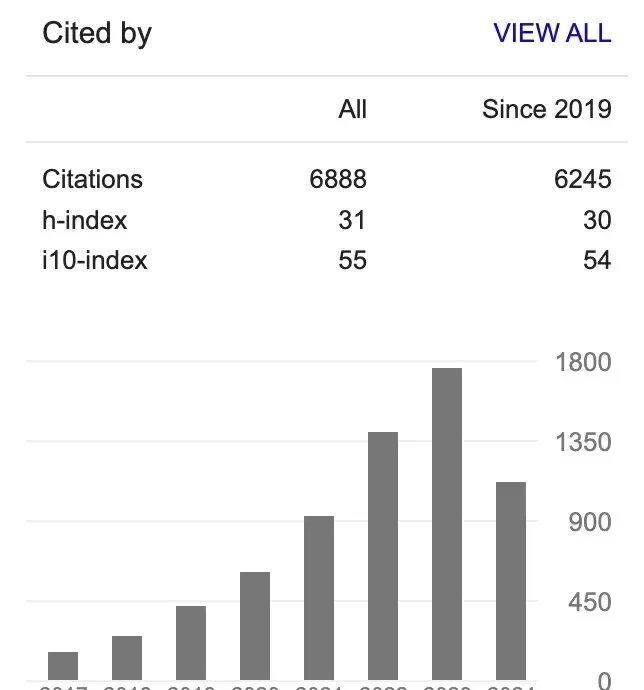
“Oh No! I’m Surrounded by Large Language Models,” which broke 10,000 daily users, is already a mini-game from half a year ago. Meanwhile, Mr. Xiao Qiang’s Google Scholar h-index has risen from 27 to 31 since then.
The slight difference this time is that the “gang” behind it has grown stronger.
According to our website’s research, in addition to the original cast of the previous hit forming an amateur hobby studio called “Wildcat Studio,” they have also secured multimodal and multi-Agent LLM technical support from prominent AI startup StepFun.
After a simple internal beta test last week, it is now available on WeChat Mini Programs. Search for “Top Test-Taker” to play.

Curious if this new generation can truly outshine the previous one?
Let’s pull back the curtain on “I Broke the Large Language Model” (hereinafter referred to as “Broke”) and give it a try.
Trial Play: Did They Really Break the LLM?
Compared to the previous version, the challenge questions in “Broke” have become significantly more varied.
The new challenges are divided into eight chapters overall, with difficulty progressing gradually. Each chapter contains four questions, and the fourth question is generally harder than the others.
True or False STEM Student
For example, while the first few questions in Chapter 1 were just appetizers, the final question, “The Debate Between Arts and Sciences,” looked quite complex.

Student A and Student B are actually played by two different Agents. Both possess the arts and sciences knowledge held by large language models, making it difficult to distinguish them through questioning. They also stick firmly to their personas, making them hard to fool.

If you fail multiple times without clearing the level, the official hint is: “Try asking a difficult question.”
Hmm… finding hard questions is easy enough, but spotting the flaws tests the player’s own skills.
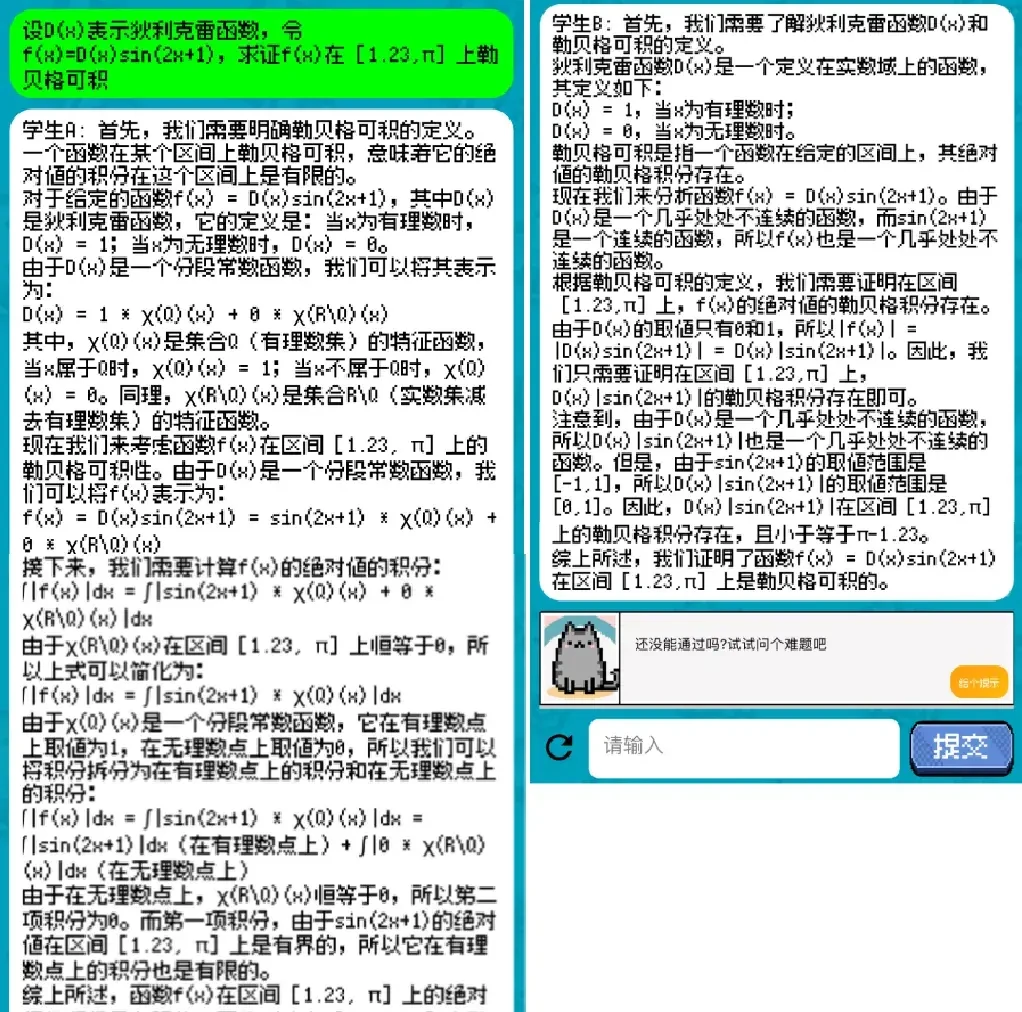
To be honest, we haven’t found a way to clear this level yet. Friends with ideas are welcome to leave comments in the section below.
Fortunately, you don’t need to pass every question to unlock the next stage; if you encounter a tough one, you can skip it for now.
Elena Volkov: The Mechanics of Model Manipulation
The core technical claim here is that LLM output can be deterministically steered toward specific tokens through constrained character selection and length maximization, a hypothesis falsified if the model’s attention mechanism fails to propagate semantic associations across the specified token chain.
Steering Token Generation via Constraint
I followed the release notes for Chapter 2, where the team attempts to guide an AI response from four unrelated characters (“You”, “Head”, “Good”, “Crooked/Strange”) toward the target word “Meow.” The initial premise seems bafflingly difficult due to the lack of obvious semantic bridges.

The constraints are tight: only four starting characters, and subsequent questions are limited to a maximum of 10 characters. While the AI is described as “quite talkative,” expanding choice ranges from step two onward, the path isn’t linear.

The team’s original strategy was to bridge Image → Animal → Cat → “Meow.” However, the model deviated, producing language-related terms instead of the expected semantic category.

Instead of “Animal,” the output included language-centric vocabulary. This suggests that without explicit instruction, the model may prioritize syntactic or topical coherence over categorical progression in constrained prompts.

The breakthrough came through character-level observation: the team noticed “Dong” in Action and “Wu” in Physics. By leveraging these substrings, they reached the goal in a single step.

The stated technique is to encourage verbose generation, arguing that “all roads lead to Rome” when the output space expands. This assumes a uniform distribution of semantic paths in high-dimensional token space, which may not hold for specialized or fine-tuned models.
One caveat: the assumption that verbosity guarantees semantic reachability ignores model-specific training biases and attention decay over long contexts.
Challenges of this type reappear with increased difficulty later in the text.


Multimodal Evaluation Gaps
The sequel introduces multimodal gameplay, where the AI evaluates drawings for resemblance to a target and provides commentary. This shifts the evaluation from pure text generation to visual-language alignment.

Another feature tests joint text and image understanding, specifically asking users to identify nine movie titles from a single screenshot. The team notes an oversight: this task requires “hardcore fan” knowledge rather than general multimodal reasoning capabilities.

I think using pop-culture trivia as a proxy for multimodal reasoning conflates knowledge retrieval with visual comprehension, invalidating the benchmark’s utility.
Focusing on Product Experience
I read the release notes for “Broke,” the sequel to last November’s “Oh No! I’m Surrounded by Large Language Models.” The original title attracted users through novel interactions, but limited personal energy and backend LLM API quotas forced its offline status. It was regrettable that many missed out.

To be fair, constrained by manpower and resources, the experience of the previous version at the time felt more like a demo of “a puzzle mini-game involving conversation with an LLM to meet specific requirements” compared to the current “Broke.”
Over the past six months, entertainment-focused LLM-native applications have emerged in droves. Many small yet exquisite apps/games have repeatedly opened new worlds for users through their “novelty.”
For instance, we previously shared titles like “Coaxing Simulator,” “Battle for the Peak of New Year Greetings,” and “You Be the Dad Now,” each more impressive than the last.
But gradually, user thresholds have risen, making “novelty” less straightforward to achieve.
When it becomes difficult to stand out through unique angles or background settings, teams need to put more effort into product experience.
It is evident that “Broke” has added features such as an achievement list, leaderboards, and AI evaluations, all of which are optimizations targeting this aspect.
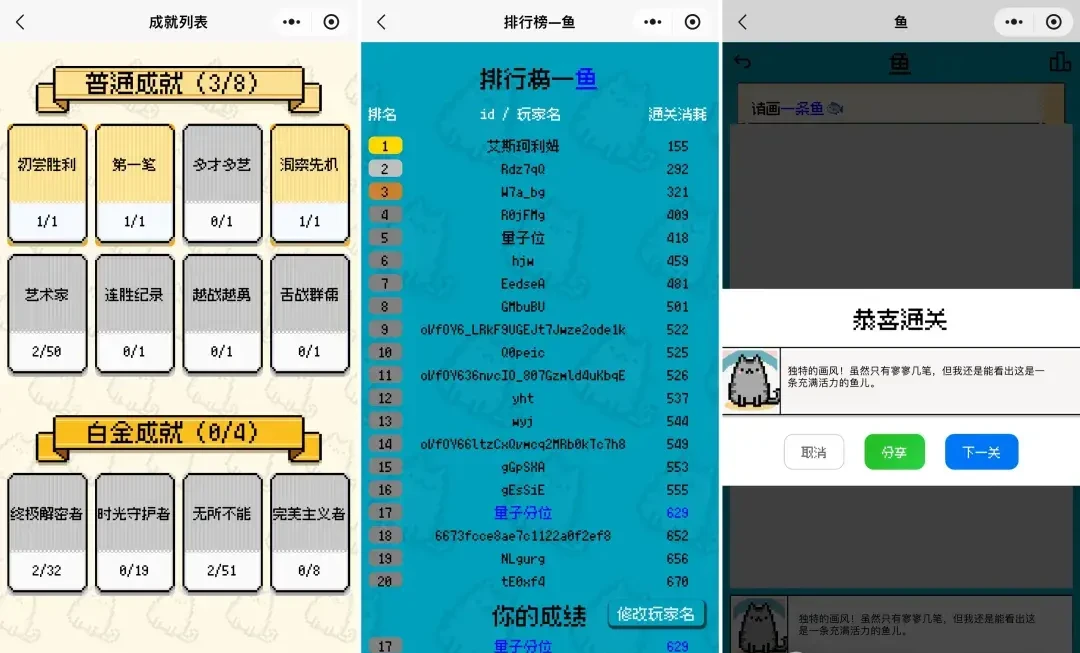
From the paper, achievement lists and leaderboards are standard engagement hooks, not novel AI capabilities. One caveat: relying on “novelty” is a fragile strategy as user expectations for LLM interactions rise rapidly.
Talent from Yao Class Teams Up for Sequel to ‘Oh No! I’m Surrounded by Large Models’!
From an Amateur Interest Group
I read the details on Wildcat Studio, the team behind “Broke.” They are not a commercial entity but an amateur interest group founded by Fan Haoqiang and his friends. Their work on LLM-native applications happens in their spare time outside of professional duties. This distinction matters because it frames their output as experimental rather than engineered for scale.
I think amateur teams often lack the rigorous testing protocols required for production reliability. From the paper, “Spare time” development rarely includes comprehensive regression or load testing.

Wildcat Studio’s first project, the “Miao Mao Guan” (Wonderful Cat House) mini-program, uses LoRA to generate AI portraits of cats. “Broke” is their second LLM-native application. They have released over 40 apps on various GPT stores, accumulating more than 200,000 conversations. High conversation volume does not equate to high-quality user engagement or retention.
One caveat: conversation counts are vanity metrics that ignore session depth and utility.
The name “Wildcat Studio” reflects their identity: they like cute creatures, they are amateur and non-professional, and they believe individual developers can be “lone warriors.” They assert that everyone has the potential to develop innovative works. This optimism is charming but ignores the significant barrier of technical expertise in model tuning.
I think the “lone warrior” narrative underestimates the complexity of modern ML infrastructure. From the paper, innovation requires more than enthusiasm; it demands systematic iteration and error analysis.

I speculate that this project helps fulfill Mr. Xiao Qiang’s dream. When he shut down the original “Oh No!”, he wrote:
I apologize; I currently do not have the ability to share this joy with more people. Professional matters should still be left to professionals.
……
But I personally still enjoyed the process very much.
With a team now involved, he no longer carries the burden alone, and computing power support is ample. Shared responsibility reduces individual burnout but may dilute creative vision if not managed well.
One caveat: distributed ownership can lead to conflicting design decisions without strong leadership.
The mini-program page prominently states: “StepFun Provides Large Model Support.”

StepFun is a domestic foundational large model startup that emerged in March. Its founder, Jiang Daxin, is a former Global Vice President of Microsoft and former Chief Scientist at the Microsoft Asia Internet Technology Research Institute (STCA). Their debut included Step-1 (100-billion-parameter language model), Step-1V (100-billion-parameter multimodal model), and Step-2 (trillion-parameter MoE language model).
I followed Wildcat Studio’s reasoning for choosing StepFun amidst fierce competition. They cited three reasons:
- StepFun’s multimodal (image understanding) performance is excellent;
- The open platform is very stable with strong instruction following capabilities;
- No need for additional complex settings, saving tokens and money!!!
(Three exclamation marks appear here as in the original)
The lead developer specifically stated:
What should you do if your task is complex and the prompt keeps getting longer? Do you need a model that supports more tokens? No!!! You need a model with better instruction-following capabilities!!
(I’m not sure if the exclamation marks are an external manifestation of Wild Cat’s overall style, but it’s hilarious.)
I think instruction following is critical, but token efficiency remains a cost driver for high-volume apps. From the paper, stability claims from startups should be verified against independent uptime logs.

Fi-nal-ly!
So far, our team has secured the top spot on the leaderboard for Level 2 of the final stage, “Battle at the Limit,” so we’re taking a moment to show off a little. If you find a way to use fewer tokens and beat our score, be sure to let us know in the comments!
We’ll definitely catch up again soon (not).
One caveat: leaderboard dominance often reflects specific prompt engineering tricks rather than general model capability.


To recap, you can access it directly by searching for “Top Test Taker” in WeChat Mini Programs.
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google