I read the release notes for Open-Sora 2.0, but I’m looking past the demo reels to see what actually runs in production versus what looks good on a slide deck. The claim of an 11B parameter model hitting SOTA metrics with just 224 GPUs is a bold unit economics play, but field reliability always lags behind benchmark scores.
Open-Sora 2.0 Officially Released.
With an 11B parameter scale, its performance rivals HunyuanVideo and Step-Video (30B). It is worth noting that many proprietary video generation models with similar effects incur training costs of millions of dollars. In contrast, Open-Sora 2.0 has compressed this figure to just $200,000. Furthermore, this release includes the full open-source model weights, inference code, and distributed training pipeline, making it a valuable resource for developers!
GitHub Repository: https://github.com/hpcaitech/Open-Sora
Supports High-Quality Generation at 720P and 24FPS
Let’s look at the Open-Sora 2.0 demo. Regarding motion amplitude, parameters can be adjusted to better showcase nuanced movements of characters or scenes. In the generated videos, a man performing push-ups moves smoothly with reasonable amplitude, indistinguishable from real-world physics.

Even in virtual scenarios like a tomato surfing, the splashes of water, the leaf boat, and the tomato adhere to physical laws.

In terms of image quality and fluidity, it offers 720P high resolution and 24FPS smoothness, ensuring stable frame rates and detailed performance in the final video.

It also supports rich scene transitions. From rural landscapes to natural scenery, Open-Sora 2.0 delivers excellent performance in both image details and camera movements.

I think demo physics are easy to fake; long-horizon consistency is where these models usually break down.
11B Parameter Scale Rivals Mainstream Proprietary Large Models
Open-Sora 2.0 adopts an 11B parameter scale. After training, it achieves performance levels comparable to mainstream proprietary large models developed at high costs in both VBench and Human Preference evaluations, rivaling HunyuanVideo and the 30B Step-Video.
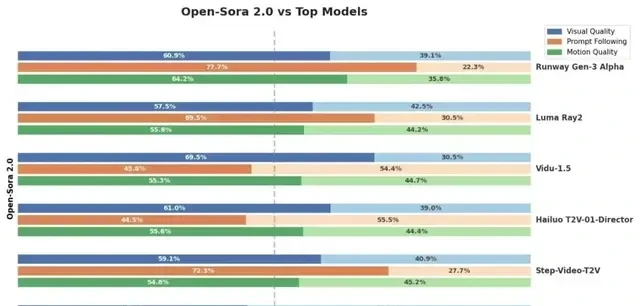
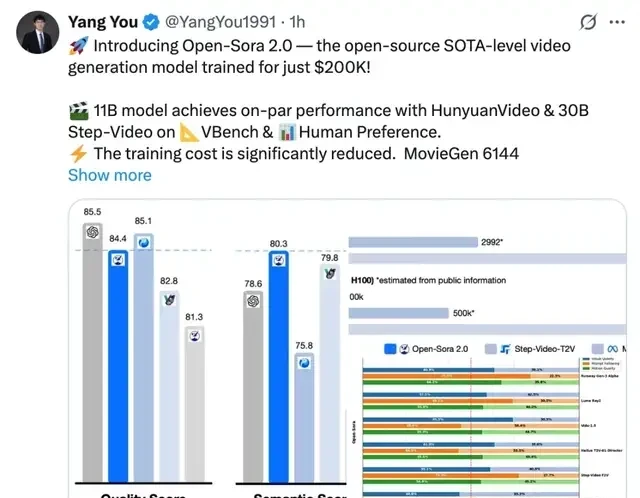
Across three evaluation dimensions—visual appearance, text consistency, and motion performance—Open-Sora surpasses the open-source SOTA HunyuanVideo in at least two metrics, as well as commercial models like Runway Gen-3 Alpha. It achieves high performance with low cost.
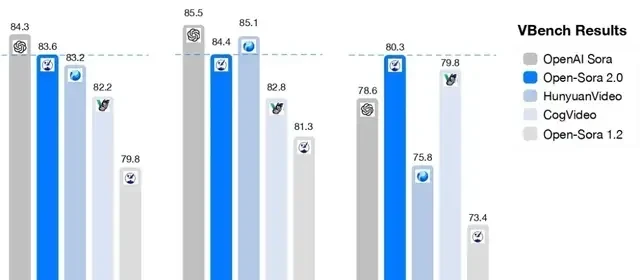
According to evaluation results from the authoritative video generation benchmark VBench, Open-Sora has shown significant performance improvements. Upgrading from Open-Sora 1.2 to version 2.0 significantly narrowed the performance gap with industry-leading proprietary models like OpenAI Sora, reducing it from 4.52% to just 0.69%, nearly achieving parity in performance.
Additionally, Open-Sora 2.0’s score on VBench exceeds that of Tencent’s HunyuanVideo, delivering higher performance at a lower cost and setting a new benchmark for open-source video generation technology.
The Reality of Low-Cost Training
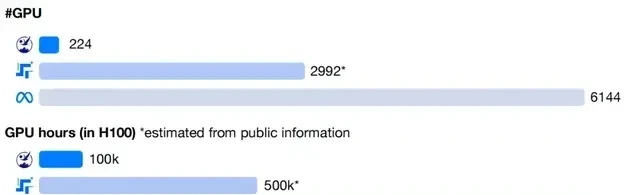
I read the release notes for Open-Sora 2.0, which claims to have slashed training expenses by a factor of five to ten compared to other open-source models exceeding 10 billion parameters. While the team has opened up their full training pipeline code and weights, I remain skeptical about whether these savings translate to reliable deployment or just cheaper demos.
In the field, cheaper training doesn’t guarantee the robot won’t hallucinate when it moves. I want to see how these savings hold up under real-world load, not just on a benchmark.
The project has built what they call a robust open-source ecosystem, with academic papers garnering nearly 100 citations in six months and ranking first globally among open-source image-to-video (I2V) and text-to-video (T2V) projects. But influence in citation metrics is not the same as utility in a factory or on a street corner.
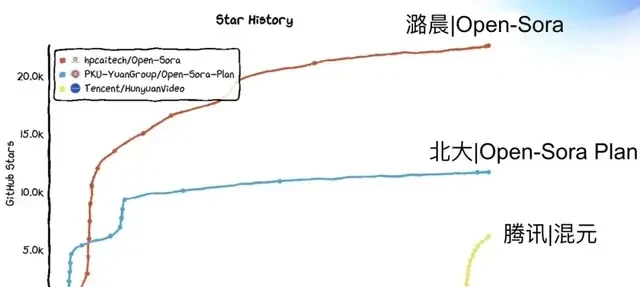
What I watch for is high citation counts are nice, but I need to see the code run without crashing. I think we need unit economics that make sense for actual production, not just research grants.
Under the Hood: Architecture and Scale
Open-Sora 2.0 retains the design philosophy of version 1.2, utilizing a 3D Autoencoder and a Flow Matching training framework. It employs a multi-bucket training mechanism to handle videos of varying lengths and resolutions simultaneously. To improve quality, it introduces a 3D Full Attention Mechanism, while adopting the latest MMDiT architecture to better align text prompts with video content.
The model scale has expanded from 1B to 11B parameters. Crucially, by leveraging initialization from the open-source image-to-video model FLUX, the team claims this significantly reduces training costs and improves optimization efficiency. I followed the release details closely; while the technical specs are impressive on paper, I question whether an 11B parameter model can run efficiently enough to be anything more than a laboratory curiosity.
In the field, an 11B model is heavy; I need to know if it fits in edge devices or just data centers. What I watch for is initialization from FLUX helps start the race, but it doesn’t determine who wins the marathon of reliability.
Cutting Costs Through Engineering Discipline, Not Just Scale
I read the release notes for Open-Sora 2.0, and what stood out was the shift from brute-force scaling to surgical efficiency. The team isn’t just throwing GPUs at a problem; they are aggressively pruning the waste that plagues most open-source video models. To hit SOTA with an 11B parameter model on just 224 GPUs, they had to solve the unit economics of training first.
I think lab demos look smooth until you see the compute bill for a single minute of footage. In the field, high-resolution tokens explode memory usage faster than attention mechanisms can handle them. What I watch for is image-to-video pipelines are a pragmatic hack, not a fundamental architectural breakthrough.
Rigorous Data Hygiene as a Compute Multiplier
The first pillar of this cost reduction is strict data filtering. Open-Sora 2.0 implements a multi-stage, multi-level filtering mechanism to ensure that only high-quality inputs reach the training loop. This isn’t just about cleaning noise; it’s about improving model convergence efficiency from the source. By providing more precise and reliable training data, they reduce the number of epochs needed to learn robust representations.

The Quadratic Penalty of Resolution
The math on high-resolution training is unforgiving. When achieving the same data volume, computational overhead for high-res can be up to 40 times greater than low-res. Consider the token count: a video at 256px and 5 seconds contains approximately 8 thousand tokens, whereas a 768px version contains nearly 80 thousand tokens—a difference of 10 times.
Coupled with the quadratic computational complexity of attention mechanisms, this makes high-resolution training prohibitively expensive for most labs. Open-Sora’s strategy is to prioritize low-resolution training to efficiently learn motion information, ensuring the model captures key dynamic features without burning VRAM on static detail it hasn’t earned yet.

Convergence Hacks and Parallel Efficiency
To accelerate convergence further, Open-Sora prioritizes training on image-to-video (I2V) tasks. Compared to direct text-to-video (T2V), I2V models exhibit faster convergence when increasing resolution, which directly reduces training costs. For inference, users can still generate T2V content by combining open-source image models to create the initial frame before animating it (T2I2V). This offers a more refined visual effect without the training overhead of learning motion from scratch in every prompt.
Finally, the system relies on an efficient parallel training scheme integrating ColossalAI and custom optimizations to maximize resource utilization. To keep the 224 GPUs fed and not idle, we introduced several key technologies:
- Efficient Sequence Parallelism and ZeroDP, optimizing distributed computing efficiency for large-scale models.
- Fine-grained Gradient Checkpointing control, maintaining computational efficiency while reducing VRAM usage.
- Automatic training recovery mechanism, ensuring over 99% effective training time and minimizing wasted computing resources.
- Efficient data loading and memory management, optimizing I/O to prevent training bottlenecks and accelerate the process.
- Efficient asynchronous model saving, reducing interference from model storage on the training flow and improving GPU utilization.
- Operator optimization, deeply optimizing key computational modules to speed up the training process.
These optimizations work synergistically, allowing Open-Sora 2.0 to achieve a balance between high performance and low cost. It significantly lowers the barrier for training high-quality video generation models, proving that you don’t need a data center-sized budget to push open-source capabilities forward.
Faster Inference via Aggressive Compression
The demo reel promises speed, but I read the specs closely: inference time for a 768px, five-second clip drops from thirty minutes to under three minutes per GPU. That is a tenfold increase in throughput, achieved by swapping standard 4×8×8 compression for a denser 4×32×32 ratio.
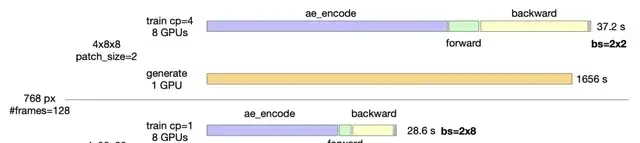
I think lab benchmarks love tenfold speedups; I want to know if the cloud bill actually shrinks.
To make this work, the team added residual connections in the upsampling modules, claiming reconstruction quality now matches current open-source SOTA models despite the higher compression. They also used a distillation strategy and image-to-video guidance to help the model converge faster with less data.

In the field, high compression often means blurry artifacts; I need to see the edges of moving objects.
The filing suggests this architecture is a key direction for lowering costs, aiming to stimulate community exploration into efficient video generation.
Open-Sora 2.0 Release Details
Open-Sora 2.0 has been officially open-sourced. We can access the code and technical report directly from their GitHub repository.
GitHub Repository: https://github.com/hpcaitech/Open-Sora
Technical Report: https://github.com/hpcaitech/Open-Sora-Demo/blob/main/paper/Open_Sora_2_tech_report.pdf
What I watch for is open source is great, but I need to see it running on a single consumer GPU without crashing.
The team invites the community to join and explore the future of AI video generation.
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google