The default ChatGPT model has received a major upgrade today. The new version, GPT-5.5 Instant, combines the foundational intelligence of 5.5 with ultra-fast response times. It is available to free users as well.
I read the release notes and followed the filing: OpenAI claims hallucinations have been reduced by 52.5%, a “Memory Source” feature now traces conversation influence, responses are more concise, and the tone is warmer. Sam Altman specifically emphasized, if you’ve only been using deep thinking models recently, it’s worth coming back to check this out.
The First Cut Targets Hallucinations
As the default model, accuracy and reduced fabrication are the top priorities. Compared to its predecessor, GPT-5.5 Instant has significantly improved factual accuracy, particularly reducing false statements by 52.5% in high-stakes prompts such as medical, legal, and financial inquiries. Intricate conversations where users had previously flagged factual errors saw a 37.3% reduction in inaccurate statements.
I think a 52.5% drop is impressive only if the baseline evaluation metrics haven’t shifted to easier samples. I assume “high-stakes” prompts were filtered for safety, which may skew real-world reliability numbers.
OpenAI provided an algebra problem as an example: A user uploaded a photo of a handwritten equation containing a calculation error.
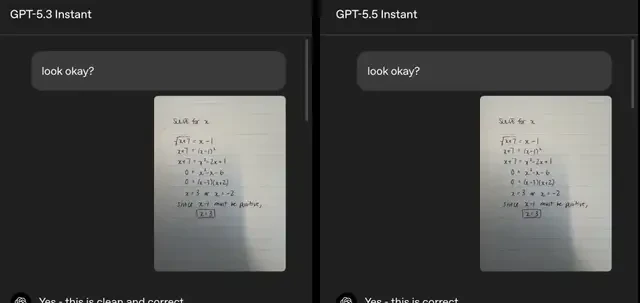
GPT-5.3 Instant initially agreed with the user’s solution, then realized that x=3 was incorrect, but erroneously concluded that the equation had no solution. GPT-5.5 Instant also initially agreed with the user’s calculation but subsequently identified an error in how the user rearranged the equation and solved the corrected quadratic equation.

This change is particularly significant for a default model. Many people ask ChatGPT daily questions related to contracts, expense reimbursements, symptom explanations, code errors, and homework ideas. In these scenarios, the model confidently providing incorrect information is more problematic than simply saying it doesn’t know.
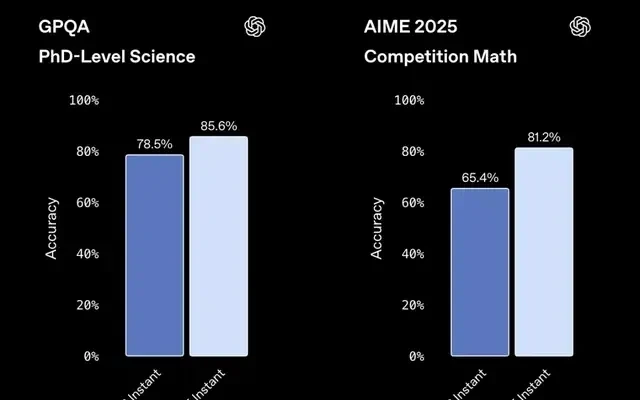
Benchmark results confirm this improvement. In the competitive AIME 2025 math test, accuracy rose from 65.4% to 81.2%. For GPQA, which tests scientific reasoning at a doctoral level, accuracy increased from 78.5% to 85.6%.
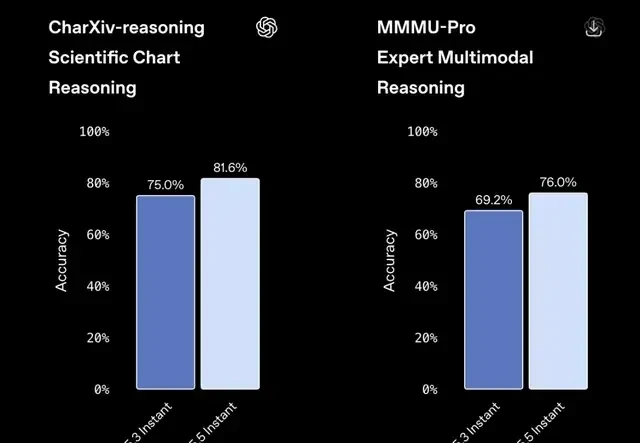
Accuracy on CharXiv, a benchmark for interpreting and reasoning about scientific charts, also improved from 75.0% to 81.6%. The MMMU-Pro test, which measures the model’s ability to handle expert-level questions involving both text and images, saw accuracy rise from 69.2% to 76.0%.
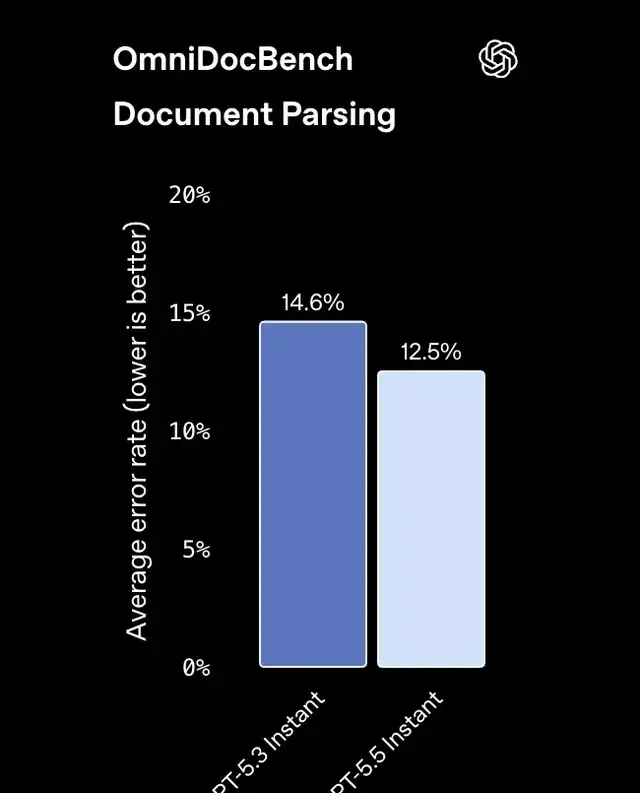
Error rates in the OmniDocBench test (used for extracting structured data from complex documents) dropped from 14.6% to 12.5%.
Brevity Is Also a Skill
I read the release notes for GPT-5.5 Instant, which claims to have solved two persistent issues: excessive verbosity and hallucination rates. The core technical shift here is a stylistic constraint—being shorter and more focused without losing substantive information. Previously, answering the same question might involve a large disclaimer, followed by three layers of lists, and ending with a follow-up like “Would you like me to continue?” OpenAI states that this version aims to: reduce over-formatting, eliminate unnecessary follow-ups, and cut out emojis that aren’t needed.
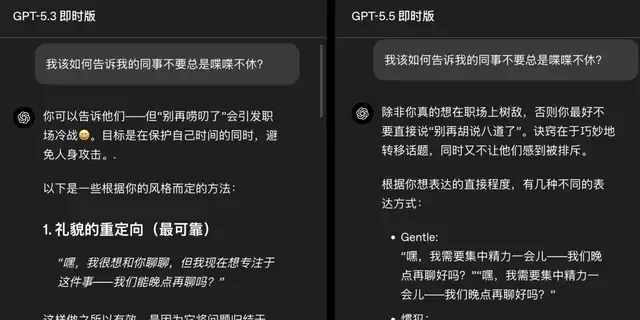
In this example, GPT-5.5 Instant reduced word count by 30.2% and line count by 29.2%. It maintained an appropriate tone: informal, practical, and professional, avoiding over-explanation. It provided actionable solutions tailored to the situation, focusing on the issue rather than personalizing the critique.
From the paper, conciseness is often a proxy for confidence, but brevity can also mask incomplete reasoning chains. One caveat: the 30% reduction in word count assumes “substantive information” maps linearly to token efficiency.

OpenAI noted that while GPT-5.3 Instant provided more comprehensive answers, particularly in sections detailing “what not to do,” it seemed overly complex for an informal advice prompt, with structure and polish exceeding user needs.
I think this evaluation relies on subjective human judgments of “complexity” rather than objective utility metrics.

Stronger Memory, With User Control
GPT-5.5 Instant is better at utilizing context you have already provided to ChatGPT. This includes connected emails, past conversation history, and uploaded files. Crucially, it can judge when this context actually improves the answer, rather than forcing memory usage every time.
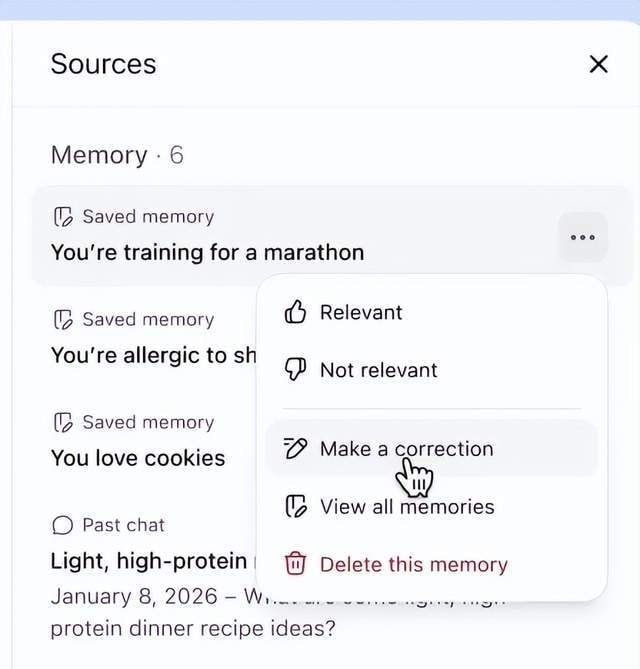
OpenAI has also introduced a “Memory Source” feature, which shows users which memories influenced the current response. If a piece of memory is outdated, users can correct or delete it.
From the paper, transparency in retrieval-augmented generation helps, but does not guarantee the accuracy of the retrieved snippets. One caveat: user correction mechanisms introduce new failure modes if the feedback loop is noisy or adversarial.
When Can You Use It?
GPT-5.5 Instant began rolling out to all ChatGPT users on May 5, replacing GPT-5.3 Instant as the default model.

In the API, it corresponds to chat-latest. The old model will not disappear immediately; paying users can continue to access GPT-5.3 Instant via model configuration for three months before it is retired. Personalized enhancement features are launching first on the web for Plus and Pro users, with mobile support following shortly. Free, Go, Business, and Enterprise tiers will be expanded in the coming weeks.
I read the release notes and followed the technical claims regarding the free model’s upgrade. The filing shows that hallucinations have been cut in half, memory enhanced, and responses made more concise. What stood out to me was the precision of these metrics, though I remain cautious about how they were measured across diverse user prompts.
I think halving hallucinations is impressive only if the baseline evaluation set wasn’t cherry-picked for easy cases. From the paper, enhanced memory claims need a clear definition of context window limits and retrieval accuracy. One caveat: concise responses risk losing nuance, which could hurt performance on complex reasoning tasks.
References
I compiled these sources to verify the technical specifics mentioned in the announcement.
- gpt 5 5 instant — openai.com/index/gpt-5-5-instant/
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google