The burden of proof has shifted overnight. As DeepSeek’s Janus-Pro-7B challenges Western incumbents and Alibaba’s Qwen2.5-VL enters the fray, enterprises must verify these open-source claims against their own compliance frameworks before adoption.
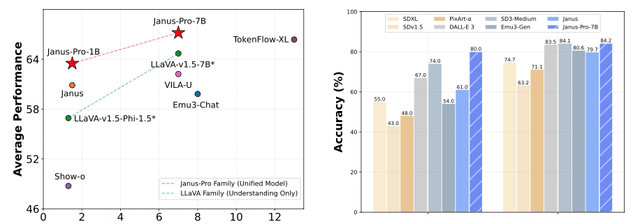
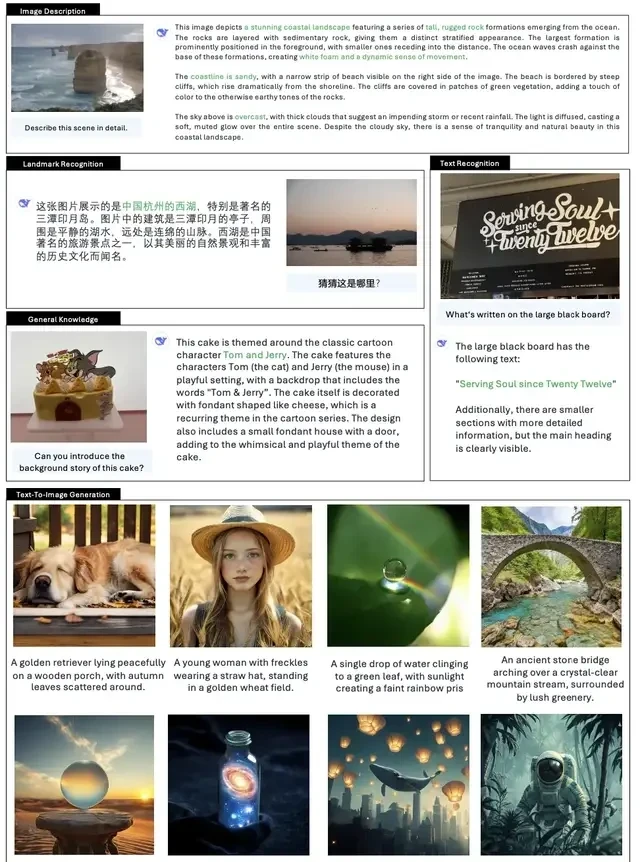
Janus-Pro-7B, a multimodal architecture that is open-source upon launch, has entered the arena with aggressive performance metrics. It outperformed DALL-E 3 and Stable Diffusion in GenEval and DPG-Bench benchmark tests.
You’ve likely been flooded with news about DeepSeek these past few days.
It has dominated the top spot on trending searches for an extended period, even causing a significant drop in Nvidia, the world’s first AI stock—plummeting nearly 17% and wiping out $589 billion (approximately RMB 4.24 trillion) in market value overnight, setting a record for the largest single-day decline in U.S. stocks.
The DeepSeek phenomenon continues to grow. During the Spring Festival holiday, users across China began experiencing its capabilities, causing DeepSeek’s servers to occasionally crash due to overwhelming traffic.



Notably, on the same night, Alibaba’s large language model family, Tongyi Qianwen (Qwen), also updated its open-source lineup:
The vision-language model Qwen2.5-VL, available in three sizes: 3B, 7B, and 72B.
Indeed, Hangzhou didn’t sleep last night as models raced to compete.
I think benchmark wins are marketing tools; enterprises must audit these models for data lineage before deployment. My sense is the Nvidia drop reflects market anxiety over compute cost parity, not just model capability. What concerns me is that open-source releases in China often bypass Western export controls, creating immediate supply chain risks.
DeepSeek’s Technical Pivot and Governance Implications
The release of Janus-Pro on Chinese New Year’s Eve marks a significant shift in the open-source multimodal landscape, driven by a team led by Chen Xiaokang, a Peking University Ph.D. graduate. This model is not merely an incremental update to Janus or JanusFlow; it represents a fundamental architectural decision to decouple visual encoding while maintaining a unified autoregressive transformer framework.

Chen Xiaokang, a Ph.D. graduate from Peking University, leads the team.
Specifically, it is built upon DeepSeek-LLM-1.5b-base/DeepSeek-LLM-7b-base and serves as a unified multimodal large model for both understanding and generation. The entire model adopts an autoregressive framework.
It addresses the limitations of previous methods by decoupling visual encoding into separate pathways while still utilizing a single, unified transformer architecture for processing.
This decoupling not only alleviates role conflicts between the visual encoder in understanding versus generation tasks but also enhances the flexibility of the framework.
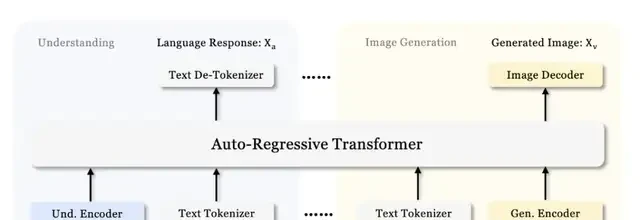
For multimodal understanding, it employs SigLIP-L as the visual encoder, supporting 384 x 384 image inputs. For image generation, Janus-Pro uses the VQ tokenizer from LIamaGen to convert images into discrete IDs with a downsampling rate of 16.
After flattening the ID sequence into one dimension, they use a generative adapter to map the codebook embeddings corresponding to each ID into the LLM’s input space. These feature sequences are then concatenated to form a multimodal feature sequence, which is subsequently fed into the LLM for processing.
In addition to the prediction heads built into the LLM, randomly initialized prediction heads are used for image prediction in visual generation tasks.
Compared to the previous version of Janus, which involved three training stages, the team found this strategy suboptimal and significantly reduced computational efficiency.
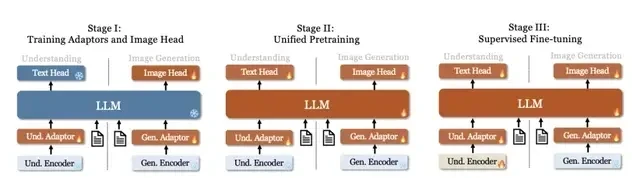
To address this, they made two major modifications.
- Stage I: Extended Training Duration: The number of training steps in the first stage was increased to allow for thorough training on the ImageNet dataset. Research indicates that even with fixed LLM parameters, the model can effectively simulate pixel dependencies and generate reasonable images based on category names.
- Stage II: Focused Training: In the second stage, the team abandoned the ImageNet dataset and directly utilized standard text-to-image data to train the model for generating images based on dense descriptions.
Additionally, during the supervised fine-tuning in Stage III, the proportion of different types of datasets was adjusted. The ratio of multimodal data, pure text data, and text-image data was changed from 7:3:10 to 5:1:4.
By slightly reducing the proportion of text-to-image data, this adjustment allows the model to maintain strong visual generation capabilities while improving multimodal understanding performance.
The final results show that it achieves parity with existing state-of-the-art (SOTA) vision understanding and generation models.
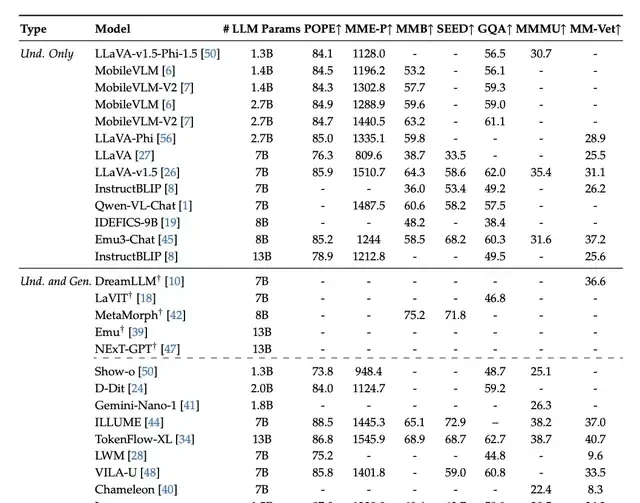
Compared to the previous Janus version, it provides more stable outputs for short prompts, offers better visual quality and richer details, and possesses the ability to generate simple text.

Qualitative results demonstrating further improvements in multimodal understanding and visual generation capabilities.
I think decoupling vision from text reduces hallucination risks in hybrid tasks. My sense is enterprises must audit the new dataset ratios for compliance bias. What concerns me is that open-source parity forces proprietary vendors to justify their premiums.
DeepSeek’s Disruption: Governance, Cost, and the Nvidia Shock
By Priya Sharma | Enterprise AI & Governance Editor
The recent release of DeepSeek’s open-source models has triggered a seismic shift in enterprise risk assessments. The burden of proof now lies with organizations to verify whether their legacy infrastructure investments remain viable against low-cost, high-efficiency alternatives. This is not merely a technical update; it is a governance challenge regarding capital allocation and vendor lock-in.
DeepSeek Conquers Global Users
I have followed the rapid escalation of interest in DeepSeek over the past few days. The conversation has moved beyond tech circles into broader societal discourse, including endorsements from high-profile figures like Game Science’s CEO, who described the achievement as having “Top-tier technological achievement, six major breakthroughs.”
Even Guo Fan, director of The Wandering Earth, took notice. While the speculation about a cameo role is lighthearted, it underscores the cultural penetration of this technology.
The catalyst was the open-sourcing of its reasoning model, R1. Trained for just $5.6 million—a fraction of Meta’s GenAI executive salaries—R1 matches or surpasses OpenAI’s o1 in many benchmarks. Crucially, DeepSeek is genuinely free. While ChatGPT offers a free tier, full capabilities require a $200 subscription. This pricing disparity drove users to DeepSeek, propelling it to the number one spot on the U.S. Apple App Store’s Free Apps chart, surpassing ChatGPT and Meta’s Threads.

The surge was so intense that DeepSeek’s servers crashed multiple times, requiring emergency maintenance. For enterprises, the key takeaway is how to achieve parity with OpenAI while managing limited resource costs. Unlike capital-intensive models abroad that require hundreds of thousands of GPUs and billions in investment, DeepSeek focuses on overhead reduction.
Technical Efficiency vs. Capital Intensity
I read the technical details closely, noting two primary drivers: distillation and pure reinforcement learning. R1 open-sourced six distilled smaller models trained on R1 data; notably, the distilled Qwen-1.5B model outperformed GPT-4o in certain tasks.
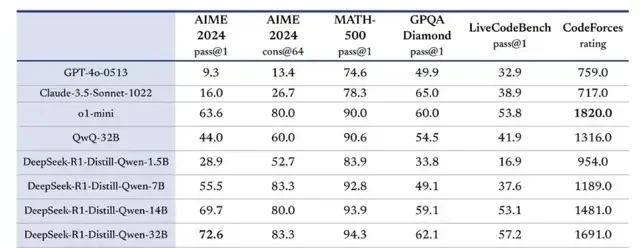
Furthermore, by abandoning Supervised Fine-Tuning (SFT) and using thousands of iterations of reinforcement learning, DeepSeek achieved AIME 2024 scores comparable to OpenAI’s o1-0912.
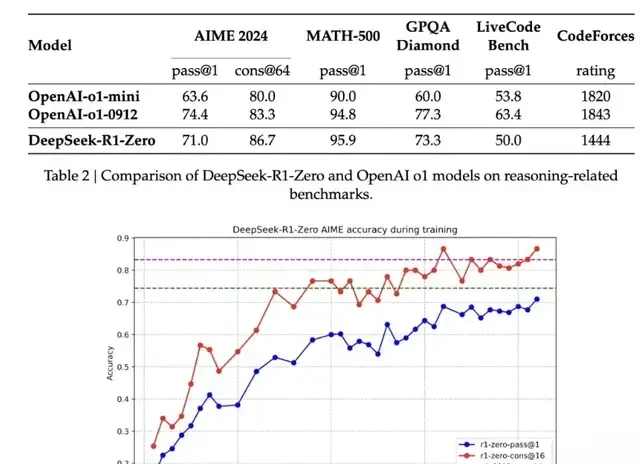
This efficiency has sparked intense debate about the necessity of massive AI infrastructure spending. Questions such as “Is it necessary to spend $500 billion building data centers?” and “Are massive investments in AI computing power justified?” have resonated deeply in capital markets.
The financial impact was immediate. Nvidia’s shares plummeted 17%, wiping out nearly $600 billion in market value—the largest decline since March 2020. Jensen Huang’s personal wealth shrank by over $13 billion overnight, with Broadcom and AMD also seeing significant declines.
In response, Nvidia stated that DeepSeek represents an exceptional AI advancement and a prime example of test-time scaling. They emphasized that DeepSeek leverages widely available models and computing power fully compliant with export controls, noting that inference still requires substantial Nvidia GPUs and high-performance networking. Nvidia outlined three scaling laws: pre-training, post-training, and the new test-time scaling law.
Meta and OpenAI were similarly shaken by these developments. Internally, Meta established a dedicated team to respond.
I think enterprises must audit their AI spend against open-source alternatives immediately. My sense is the $500 billion data center narrative faces serious credibility challenges now. What concerns me is that compliance teams should verify if “export-compliant” hardware meets internal security standards.
DeepSeek’s Overnight Surge Wipes $4 Trillion Off Nvidia’s Market Cap as It Releases New Open-Source Multimodal Model on Chinese New Year’s Eve
The market shockwaves from DeepSeek’s latest release have forced a rapid recalibration of expectations across the AI sector. As an editor focused on governance and enterprise risk, I am tracking not just the valuation shifts, but the strategic maneuvers that follow such volatility. The burden now falls on enterprises to verify whether these open-source advancements translate into reliable, compliant production environments or merely speculative hype.
Competitors React with Aggressive Budgets and Free Access
The competitive landscape has shifted dramatically in a matter of hours. Reports indicate that a dedicated research group is actively dissecting DeepSeek’s technical details to improve its own Llama series models. This immediate reverse-engineering effort highlights the intense pressure on incumbent players to maintain their technological edge.
In response, OpenAI’s Sam Altman announced that the new o3-mini model would be launched for free on ChatGPT. This move is an attempt to regain some market momentum by lowering the barrier to entry for users who might otherwise migrate to cheaper or more efficient alternatives. Meanwhile, broader industry plans are scaling up significantly; one entity outlined a New Year plan including an AI budget starting at $40 billion, aiming for 1.3 million GPU cards by year-end.
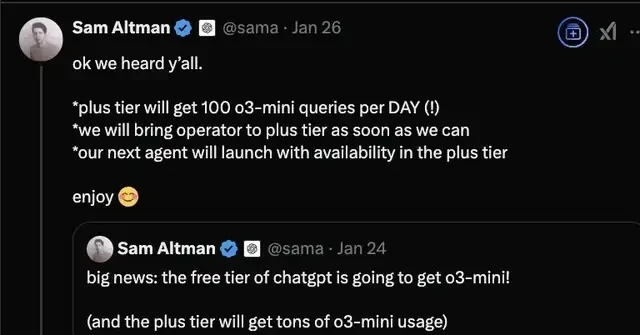
I think free model access is a customer acquisition tactic, not a long-term revenue strategy. My sense is the $40 billion GPU commitment signals an arms race that will strain supply chains. What concerns me is that enterprises should audit Llama improvements for data provenance before integration.
Market Volatility and Future Speculation
With the release of this new model, discussions about DeepSeek continue to dominate industry discourse. The overnight surge in interest has had tangible financial consequences, notably wiping approximately $4 trillion off Nvidia’s market cap as investors reassess the cost-efficiency of large language models. This volatility underscores the risk associated with heavy reliance on a few key hardware suppliers.
Rumors suggest a new version from DeepSeek may be released soon, potentially on February 25, 2025. While this date remains unconfirmed, it sets a clear expectation for the next wave of technical disclosures. Investors and CTOs alike are watching closely to see if subsequent releases can sustain the current level of innovation or if the initial surge was an outlier event.

I think february 25 is a key date to monitor for further market correction.
The Hangzhou Night Shift and the Qwen Update
While DeepSeek’s release dominated headlines, a quieter but equally significant shift occurred in Hangzhou. Shortly after the market turmoil settled, Alibaba’s Qwen team updated its open-source family with Qwen2.5-VL. This isn’t just another model drop; it signals how rapidly the competitive landscape is consolidating around multimodal capabilities that enterprises must now evaluate for compliance and integration readiness.

The release arrives with a narrative weight that feels almost cinematic, echoing the high-stakes drama of Three-Body. But beneath the literary comparison lies a concrete technical offering. Qwen2.5-VL launches in three distinct sizes: 3B, 7B, and 72B. For enterprise governance teams, this tiered approach allows for granular risk assessment based on computational footprint and data sensitivity.
My read: Smaller models like the 3B variant may reduce inference costs but require stricter output validation. My read: The 72B size demands significant infrastructure, forcing CTOs to audit their GPU availability immediately. My read: Enterprises should verify if Qwen’s agent capabilities meet internal security protocols before deployment.
The model supports visual understanding of objects, Agent capabilities, long-video comprehension with event capture, structured output, and more. These features expand the attack surface for potential hallucinations or data leakage, particularly in video processing where context windows are vast.
(For details, please refer to the next tweet.)
P.S. Finally, following Hangzhou’s “Six Little Dragons,” Guangdong’s “Three AI Heroes” have emerged. This geographic clustering of talent suggests a regional supply chain risk that global enterprises must monitor.
(Hangzhou’s Six Little Dragons are Game Science, DeepSeek, Unitree Robotics, Cloudwalk Technology, BrainCo, and Qunhe Technology.)
They are Liang Wenfeng from Zhanjiang (founder of DeepSeek), Yang Zhilin from Shantou (founder of Moonshot AI/Kimi), and AI academic heavyweight He Kaiming from Guangzhou. The rise of these specific founders highlights the concentration of innovation in southern China, creating a distinct ecosystem that operates somewhat independently of Western governance norms.

My read: The geographic concentration of AI talent creates a single point of failure for global supply chains. My read: Enterprises must assess the export control implications of using models from these specific regional hubs.
Hugging Face Link:
https://huggingface.co/deepseek-ai/Janus-Pro-7B
GitHub Link:
https://github.com/deepseek-ai/Janus
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google