GPT-5.5 has just arrived, marking a shift in how Asia-Pacific enterprises will evaluate AI infrastructure costs against performance gains.
Its official positioning is described as “a new type of intelligence designed for practical work and agents.”
This time, Sam Altman did not personally step forward to say he was “shocked, dizzy, and collapsed upon first experience, feeling like he had witnessed an atomic bomb explosion.” Instead, he invited a group of proxies (early test users) to share their experiences.
One of them is an NVIDIA engineer who briefly lost access to GPT-5.5 after the early testing phase concluded, stating:

Losing access to GPT-5.5 is like having a limb amputated.
Jokes aside, the collaboration between OpenAI and NVIDIA this time is unprecedented.
First, GPT-5.5 was jointly designed with NVIDIA’s GB200 and GB300 NVL72 systems. From training to deployment, the model and hardware have been mutually optimized from their inception.
Second, OpenAI promoted Codex across NVIDIA’s entire company, with Altman sharing an email exchange with Jensen Huang.
Let’s look at the data to see the results of this collaboration.
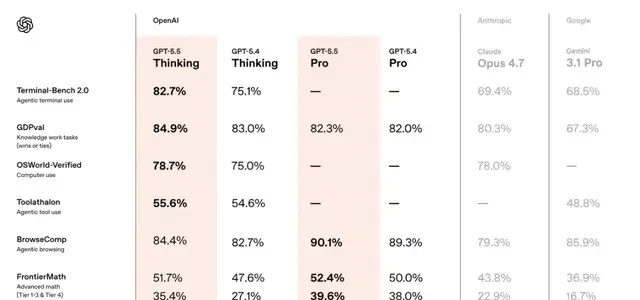
Compared to the previous version, GPT-5.4, the new model has pulled ahead in three key areas: coding, knowledge work, and scientific research.
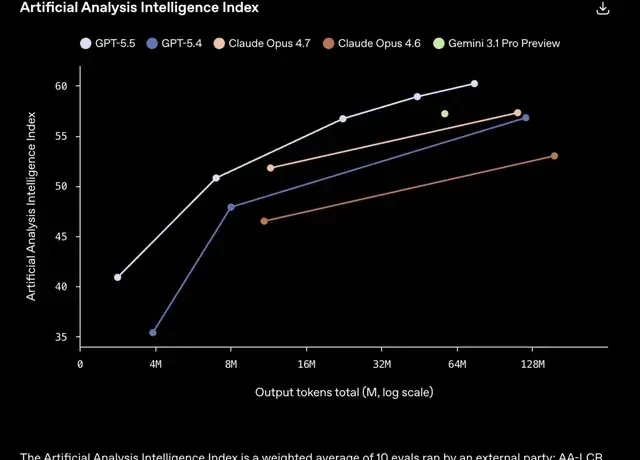
According to the Artificial Analysis Intelligence Index comprehensive test results, there are two ways to interpret the findings:
GPT-5.5 achieves the same scores as Claude Opus 4.7 and other models while consuming fewer tokens.
Alternatively, for the same token consumption, GPT-5.5 completes more tasks.
However, what surprised people most was not just the benchmark scores.
In every previous model upgrade, “stronger” and “slower” were almost always bundled together. This is the cost of Scaling Laws: larger models, more parameters, and longer thinking times. Users pay for intelligence but also for latency.
GPT-5.5 has broken this iron law.
In real-world production environments, its per-token latency is comparable to GPT-5.4, and it requires fewer tokens to complete the same tasks.
It is more efficient and more powerful.
(But the price has doubled.)

As of press time, the latest version of Codex already supports GPT-5.5.
The context window has also been upgraded to 400K.

Coding Autonomy Shifts the Workflow
I watched OpenAI’s latest release ripple through developer communities this week, signaling a shift that extends far beyond Silicon Valley labs into the APAC tech hubs where I monitor supply chain efficiencies daily. Programming is now the arena where GPT-5.5 demonstrates its most significant leap forward.
Previously, users had to meticulously break down tasks, watch models step by step, and remain ready to correct deviations at any moment. GPT-5.5 operates differently. You feed it a requirement, and it breaks it down, executes the code, and checks itself. I found that you only need to review the final results now.
OpenAI demonstrated this capability with a 3D action game generated by GPT-5.5 under Codex, running directly in the browser. The model implemented combat systems, enemy encounters, HUD feedback, and environment textures using TypeScript/Three.js.
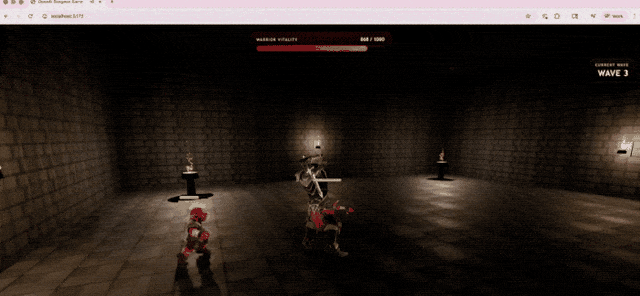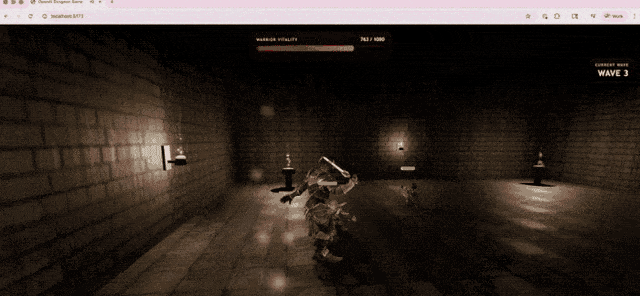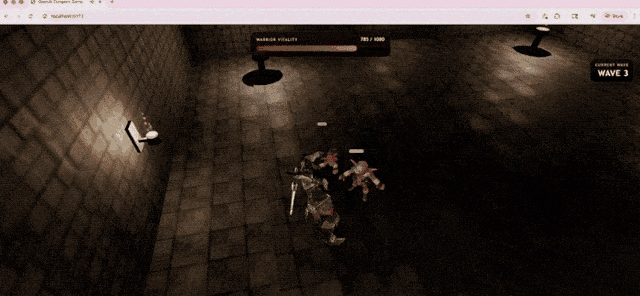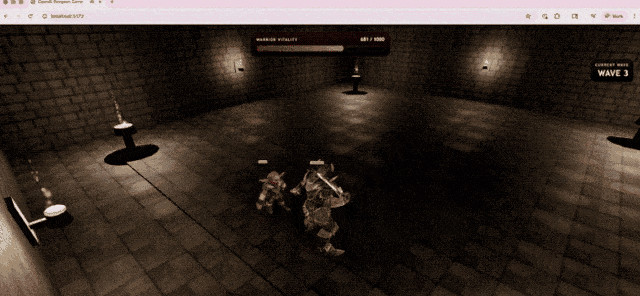
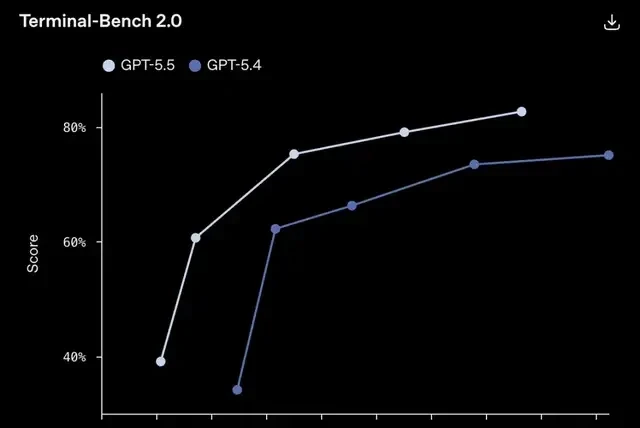
In Terminal-Bench 2.0, a rigorous test measuring complex command-line workflows, GPT-5.5 scored 82.7%. The previous version, GPT-5.4, scored 75.1%, while the current strongest competitor, Claude Opus 4.7, scored 69.4%.
To put it simply: where previous-generation models would get stuck on nearly a third of such difficult problems, this new model reduces that failure rate to less than one-quarter. I followed these benchmarks closely because they indicate how quickly enterprise workflows in Asia might adapt to higher autonomy.
I think this efficiency gain allows APAC firms to reduce headcount dependency for routine debugging tasks. From an APAC angle, lower error rates mean faster deployment cycles for regional fintech and logistics platforms.
Next up are the voices of early testers, whose experiences I have been tracking across regional tech forums:
Dan Shipper, an early tester and CEO of a startup who is also an active AI product developer, conducted an experiment. After his app launched with a bug, he hired a top-tier engineer to refactor it. The engineer worked hard and eventually provided a solution.
Then, Shipper rewound the clock: he fed the buggy code into the model to see if it could independently arrive at the same decision as the engineer.
GPT-5.4 couldn’t do it. GPT-5.5 did.
Shipper said this was the first time he felt true “conceptual clarity” from a coding model. It wasn’t just responding; it understood the problem and figured out how to solve it on its own. I noted that this level of understanding is rare in models trained primarily on pattern matching rather than logical reasoning.

More senior engineers are reporting the same thing: GPT-5.5 is significantly stronger in reasoning and autonomy than both GPT-5.4 and Claude Opus 4.7.
It can identify issues in advance and predict testing and review requirements without explicit prompts.

Coding is just the beginning. The same leap in capability is spreading to knowledge work and scientific research, a trend I expect will accelerate regulatory discussions across our desk’s coverage area.
Globally, regulatory bodies must update IP frameworks as models generate more original architectural logic. I think this autonomy reduces the barrier for smaller APAC startups to compete with larger incumbents.
Beyond Coding: From Syntax to Scientific Partner
What GPT-5.5 does in Codex goes far beyond writing code; it generates documents, organizes spreadsheets, and creates presentations. I see this shift as a critical evolution for the Asia-Pacific tech sector, where efficiency gains in knowledge work are now becoming measurable. From an APAC angle, this capability leap forces regional enterprises to rethink their internal AI integration strategies immediately.
OpenAI has emphasized multiple times that it understands what you want better than the previous generation. More importantly, it uses tools on its own and verifies whether its output is correct. You provide a vague idea, and it helps complete the rest. I followed the release notes closely, and this autonomous verification loop stands out as the key differentiator for enterprise adoption.
Here is an interesting data point: over 85% of OpenAI’s own employees use Codex for work every week. (What about the other 15%?) I wonder if that minority represents a resistance to change or simply a lack of need for such heavy automation in their specific roles.
Let’s look at the evaluation results first. On the knowledge work benchmark GDPval, GPT-5.5 scored 84.9%, outperforming Claude Opus 4.7 by 4.6 percentage points.
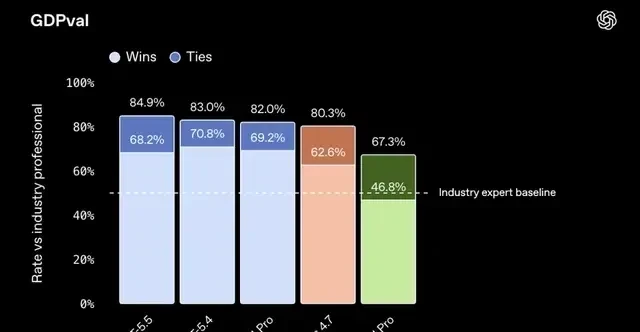
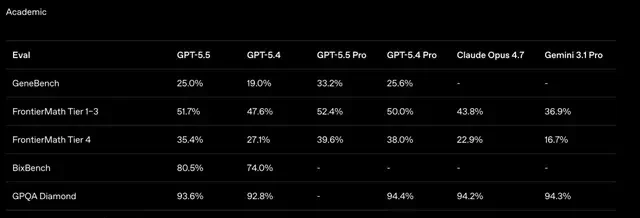
In FrontierMath Tier 4, one of the most difficult math benchmarks currently available, featuring problems from unpublished papers and open questions from top researchers, GPT-5.5 Pro achieved a score of 39.6%. Claude Opus 4.7 scored 22.9%, a gap close to double. I read these figures with caution; while the margin is significant, real-world performance often varies based on prompt engineering and context window management.
What is truly interesting is how scientists are using it. Bartosz Naskręcki, an Assistant Professor of Mathematics at Adam Mickiewicz University in Poland, typed a single sentence into Codex. Eleven minutes later, an algebraic geometry visualization application was running. The application could plot the intersection lines of two quadratic surfaces (marked in red) and transform these intersections into the standard form of Weierstrass curves using the Riemann-Roch theorem. He later expanded it to include more stable singularity visualization features. One sentence, 11 minutes. In the past, setting up the project framework alone would have taken half a day.

Derya Unutmaz, an Professor of Immunology at the Jackson Laboratory for Genomic Medicine, used GPT-5.5 Pro to analyze a gene expression dataset: 62 samples and nearly 28,000 genes. The result was a complete research report. He stated that this would have taken his team several months to accomplish. I noted how quickly biomedical data processing is accelerating; this speed could reshape grant timelines for researchers across Asia-Pacific institutions as well. Globally, such rapid analysis capabilities may accelerate drug discovery pipelines globally, impacting international health security frameworks.
OpenAI summarized its positioning of GPT-5.5 in scientific research accurately: it is no longer like a one-off answer engine but more like a “research partner.” Early testers are not just using it for information retrieval. They use it for multi-round paper revisions, pointing out logical flaws item by item, and proposing new analytical approaches. It remembers the entire context of your research, with each conversation building upon the previous one.
GPT-5.5 achieved something significant in the field of mathematics. Ramsey numbers, one of the core problems in combinatorics. In layman’s terms, it studies how large a network must be to guarantee that a certain order inevitably emerges. For example, among six people, there are always three who know each other or three who do not know each other; this is the simplest Ramsey theorem. It has been a hard nut for mathematicians to crack for decades, particularly the asymptotic properties of off-diagonal Ramsey numbers, which have long remained unresolved.
GPT-5.5 found a new proof path. It did not reproduce known methods but discovered a novel route. Subsequently, this proof was confirmed as correct by Lean, one of the most rigorous formal verification tools in mathematics. I view this as a pivotal moment for AI-assisted pure science; it moves beyond pattern matching into genuine logical discovery.

An AI has made an original contribution verified by formal tools in a core field of pure mathematics. A year ago, this was unimaginable. I think this milestone challenges the traditional view of human creativity as the sole domain of intellectual breakthroughs.
The Secret Behind “Stronger but Not Slower”
How can a model be both more capable and faster?
I see this not as incremental tweaking, but as a fundamental overhaul of the reasoning architecture. OpenAI has effectively torn down and rebuilt the core system to achieve this duality.
As I noted earlier, GPT-5.5 was co-engineered with NVIDIA’s GB200 and GB300 NVL72 systems. This partnership delivers a substantial jump in intelligence while maintaining equivalent latency standards.

There is a deeper narrative here, one that I find particularly revealing about the industry’s trajectory.
The Codex system, powered by GPT-5.5, analyzed weeks of production traffic data to write its own partitioning heuristic algorithm for load balancing. Previously, requests were split into fixed-size chunks distributed to accelerators. However, I observed that this static strategy often failed under varying traffic patterns—sometimes the chunks were too coarse, other times too fine, causing resource utilization to fluctuate wildly.
Codex analyzed weeks of real traffic data and wrote its own adaptive partitioning algorithm, dynamically adjusting the chunking strategy based on actual traffic shapes.
Token generation speed increased by over 20%.
The model optimized the infrastructure running itself; AI is making itself run faster.
This outcome stems from the overall reconstruction of the reasoning system combined with the model’s participation in its own optimization.

OpenAI stated that this is “a step toward a new way of getting computers to do work.” But when models begin to optimize the infrastructure they run on, I question how far this autonomy has truly extended.
From an APAC angle, self-optimizing code reduces human engineering overhead but raises safety verification challenges. Globally, this shift moves AI from passive tool to active infrastructure manager across data centers. I think efficiency gains here may pressure competitors to adopt similar closed-loop optimization strategies.
One More Thing
With GPT-5.5, OpenAI expects the pace of future model releases to accelerate.
We see quite significant progress in the short term and extremely significant progress in the medium term.
I think progress over the past few years was unexpectedly slow.
These words came from Chief Scientist Jakub Pachocki during a press conference call.
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google