I’ve spent too many hours manually scrubbing through footage, hunting for those jarring white flashes and color shifts that ruin an otherwise good take. If you’re tired of fighting inconsistent lighting or camera hardware limitations in post-production, Meitu’s new approach to video restoration might just save your sanity.
Researchers from the Meitu Image Research Institute, the University of Chinese Academy of Sciences, and Sichuan University have introduced BlazeBVD, a novel algorithm designed to automatically eliminate video flickering. What stands out immediately is the performance claim: it reportedly runs 10 times faster than existing methods while requiring no prior knowledge of the specific flicker type or severity.

This “blind” capability means it can be applied broadly without needing to tune parameters for every unique lighting scenario. Whether you are dealing with sudden exposure changes or lagging camera sensors, the tool aims to stabilize the visual output seamlessly. The underlying research has been accepted by ECCV 2024, a premier conference in computer vision, signaling academic rigor behind the speed claims.
I think ten times faster is a massive leap for real-time editing pipelines. Blind deflickering removes the tedious manual masking step from my workflow. I need to see if it handles complex motion blur without artifacts. The ECCV acceptance suggests the math holds up under peer review.
How Does BlazeBVD Eliminate Video Flickering?
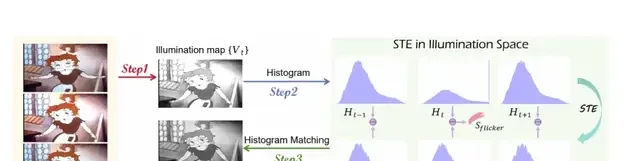
The core innovation draws inspiration from classic techniques like STE (Scale-Time Equalization for Deflickering), but introduces a histogram-assisted solution to boost efficiency. An image histogram represents the distribution of pixel values, acting as a statistical summary of brightness and contrast within a frame.

△ Image generated by Claude 3.5 Sonnet
To visualize this, think of a histogram as a chart showing how many pixels exist at each brightness level. By analyzing these distributions rather than raw pixel data, the algorithm can identify and correct sudden shifts that cause flickering more efficiently.
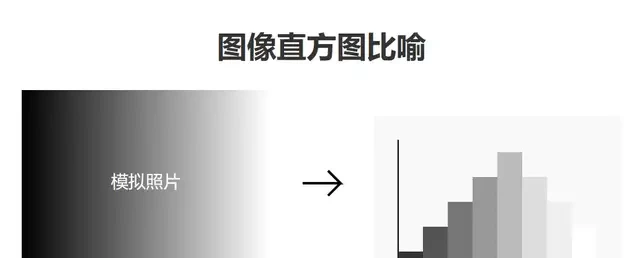
The process begins with STE, which analyzes the histogram of each frame and applies Gaussian filtering to smooth out these distributions. This initial step corrects frames with abrupt histogram shifts, stabilizing the scene and reducing visible flicker. While STE alone is limited to slight flickering, it validates two key principles:
- Histograms are more concise than raw pixel data, capturing brightness changes and flickering more effectively.
- Smoothing these histograms reduces video flickering, resulting in a more stable visual experience.
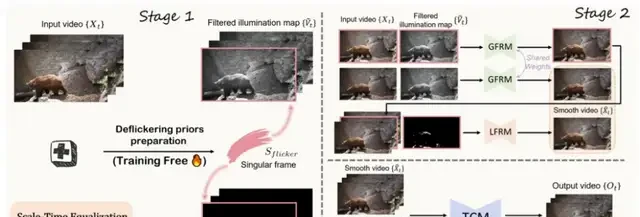
This validation led the team to leverage histogram cues to improve both quality and speed for blind video deflickering. Specifically, BlazeBVD operates through three distinct stages to achieve this result.
How BlazeBVD Actually Fixes Video Artifacts
I followed the release details on BlazeBVD, and the approach is essentially a three-step diagnostic process for video restoration. It doesn’t just guess; it treats each frame like a patient with specific symptoms.
First, the system uses STE to correct the histogram sequences of video frames within the illumination space. This sets the baseline for light distribution before any heavy lifting begins.
Next, it extracts critical metadata from these processed frames. It identifies which frames flicker most significantly (the set of singular frames), where lighting adjustments are needed (filtered illumination map), and exactly where overexposure or underexposure occurs (exposure map).
Then comes the restoration phase, split into two parallel efforts:
- Global Flicker Removal Module (GFRM): This uses the extracted illumination map to adjust the lighting of the entire video, ensuring brightness and color consistency across all frames.
- Local Flicker Removal Module (LFRM): For specific problem areas like blown-out highlights or crushed shadows, this module leverages optical flow information—tracking object movement—to restore fine details without introducing artifacts.
Finally, BlazeBVD applies a lightweight temporal network (TCM). Think of this as the video’s “beautifier,” smoothing out transitions between frames to prevent abrupt visual jumps. To enforce consistency, it uses an adaptive mask-weighted loss system that scores each frame, ensuring the entire sequence feels fluid and natural rather than disjointed.
The Numbers Behind the Speed Claim
I read through the experimental results, and the comparison against existing methods is stark. On the blind video deflickering task, BlazeBVD shows clear advantages in both visual quality and quantitative metrics.

In this visual comparison, “Deflicker” refers to existing baseline methods, while GT (Ground Truth) represents the ideal flicker-free video. The KL divergence metric indicates the difference between the processed output and that ideal state—a lower value means less distortion. Notably, BlazeBVD effectively restores illumination histograms without introducing color artifacts or distortions, such as the unnatural appearance of the man’s arm seen in other methods’ outputs (second column).
The quantitative data backs this up:

BlazeBVD achieves higher PSNR (Peak Signal-to-Noise Ratio, where higher is better for quality) and SSIM (Structural Similarity Index, closer to 1 is better). Crucially, it also scores lower in Ewarp, a metric where a lower value indicates greater video coherence and consistency.
In short, BlazeBVD outperforms existing baseline methods.
The visual difference is even more apparent when you look at the side-by-side comparison:

Ablation experiments further confirm that each module contributes to the final result:

In summary, across synthetic, real-world, and generated videos, BlazeBVD delivers superior qualitative and quantitative results. Most importantly for developers, its inference speed is 10 times faster than state-of-the-art models.

The related paper is currently available for those who want to dig into the architecture.
Paper:
https://arxiv.org/html/2403.06243v1
As a builder, ten times faster inference is a massive win for real-time editing pipelines. Personally, the dual-module approach handles global and local lighting issues simultaneously. I’d test this on heavily compressed footage to see if the temporal network holds up.
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google