Vivago 2.0 Promises Multimodal Production; Ops Must Watch the Latency Bill
I read the announcement for vivago 2.0 (Zhi Xiaoxiang AI) and followed the release details from HiDream.ai. The marketing claims an “all-encompassing” suite for image, video, and podcast generation, but as a platform engineer, I care less about the hype and more about whether this actually reduces our on-call pain or just adds another API call to monitor.

The tool supports image and video generation, which is standard now. The real question for us is whether the inference latency justifies the cost compared to specialized single-modal models we already have in our stack.

It claims mastery over fantasy scenes and diverse camera angles. If this integrates cleanly into our existing content pipelines without requiring custom adapters, it might ship this week; otherwise, it’s just another lab demo we’ll ignore until the API stabilizes.

The lip-sync feature is live, enabling podcast creation. This reduces the friction for audio content, but we need to verify if the sync accuracy holds up under production load or if it breaks silently in edge cases.

Video Link: https://mp.weixin.qq.com/s/bYNU6Mei2pq7KuFR8Ik2dQ
Key Highlights:
The platform offers hundreds of ready-to-use fun effect templates. While “effortless creation” sounds good for marketing, from an ops perspective, hard-coded effects limit our ability to customize outputs for specific brand guidelines or compliance needs.

Transformations like the one below require only a single image upload. This simplicity is nice for end-users, but it raises questions about input validation and resource consumption when handling high-resolution assets at scale.

Templates for people, animals, and buildings are available. The breadth of templates suggests a focus on consumer creativity rather than enterprise-grade consistency, which might not align with our strict quality assurance workflows.

The Image Agent allows generation via plain language and auto-optimizes prompts. This is a significant shift from manual prompt engineering, potentially reducing developer time spent on iterative refinement, though it introduces black-box variability in output quality.
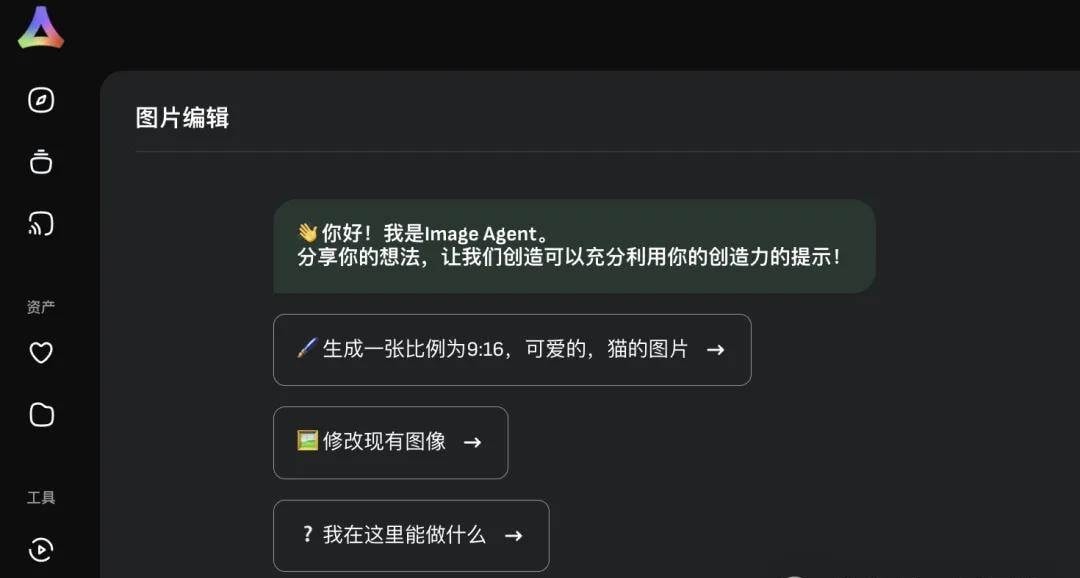
To cut to the chase, this is vivago 2.0. The team behind it, HiDream.ai, was founded by Mei Tao, an academician of the Canadian Academy of Engineering. Their R&D core comes from the University of Science and Technology of China (USTC).

The team’s open-source model HiDream-I1 topped leaderboards within 24 hours of being open-sourced. This rapid adoption signals strong technical merit, but we must assess if the open-source weights translate to a stable, supported commercial API for our production environments.
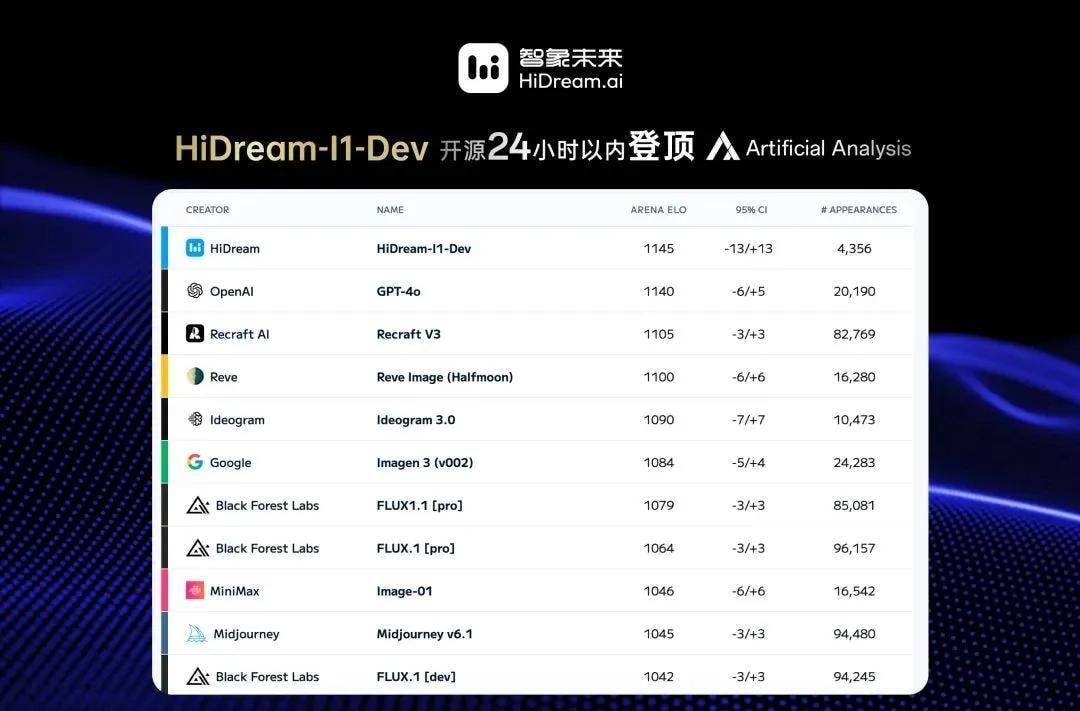
Recraft integrated it overnight, with global creators rushing to use it. This viral momentum is impressive, but we need to determine if the underlying infrastructure can handle sustained traffic spikes without degrading service level agreements (SLAs).

Interestingly, vivago 2.0 leverages the capabilities of HiDream-I1. This shared backbone suggests potential cost efficiencies if we can route traffic intelligently between the open-source model and the proprietary API layer.

Currently, vivago 2.0 has launched globally on web and app platforms. We got our hands on it for an immediate experience to see if the “dark horse” can actually compete with established players in a production setting.

VivaGo 2.0: One Tool for Images, Video, and Audio
I read the release notes for VivaGo 2.0, and the pitch is straightforward: consolidate your generative stack into a single interface. The platform claims to handle image generation, video conversion, audio podcasts, effects templates, community features, and trending topics all in one place. For ops teams watching tool sprawl, that’s either a dream or a maintenance nightmare waiting to happen.
In practice, consolidating modalities reduces API overhead but increases vendor lock-in risk. I think if the backend isn’t modular, debugging a video pipeline becomes harder, not easier.
A Beginner’s Guide to the New Multimodal Tool
VivaGo 2.0 focuses on six core features: Image Generation, Image-to-Video Conversion, AI Podcasts, Special Effects Templates, Creative Community, and Trending Topics.
Let’s explore them one by one.
Consolidated Media Generation: Image, Video, and Podcasts
I read through the VivaGo 2.0 feature set, and the immediate production implication is consolidation. By bundling image, video, and podcast generation into a single interface, they are targeting workflow friction. For ops teams, this means fewer API integrations to manage, but potentially higher vendor lock-in risk if one component fails.
Operationally, consolidating tools reduces integration overhead but increases dependency on a single vendor’s uptime.
Image Generation: Prompt Assistance and Modes
The image generation module supports both text-to-image and text-plus-reference-image modes. VivaGo 2.0 addresses the common pain point of poor prompt engineering with a “Prompt Robot” button located in the bottom-right corner of the input field:
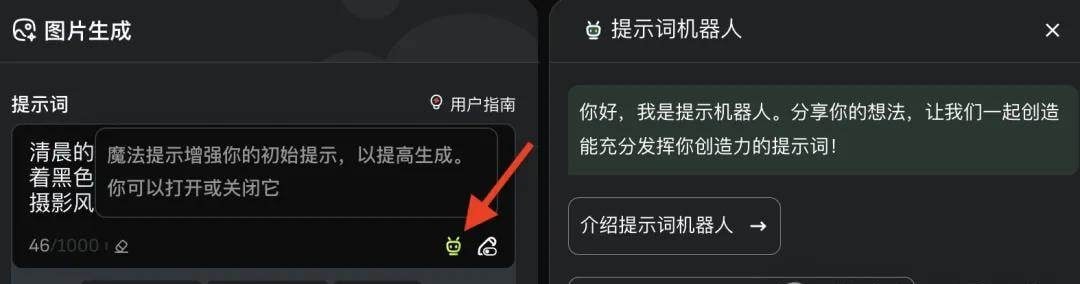
Clicking this allows users to input keywords, which the system then organizes into complete prompts. You can auto-import these via “Use Prompt” or refine them with “Cite”:
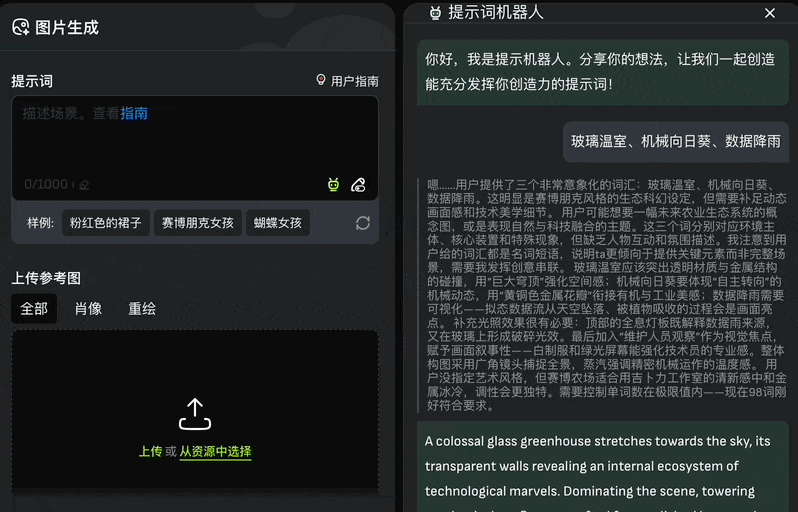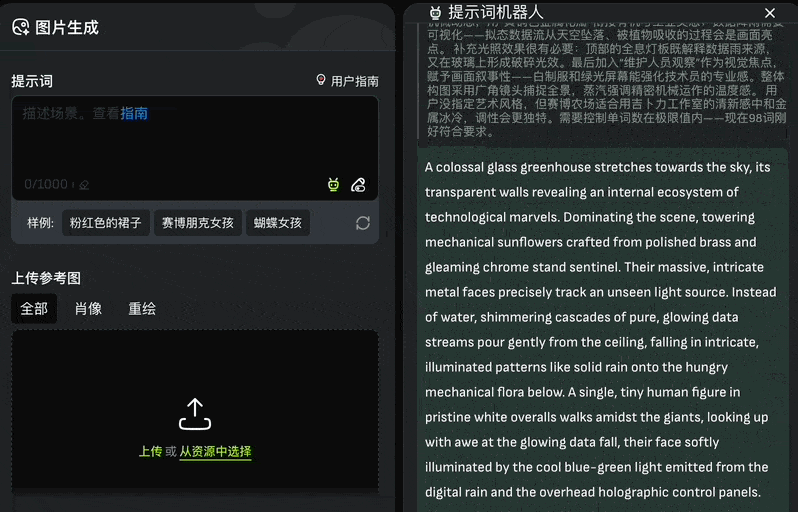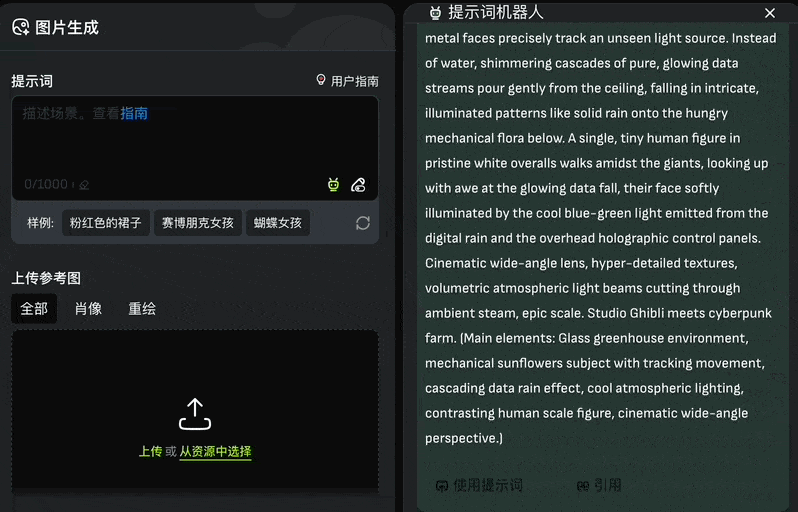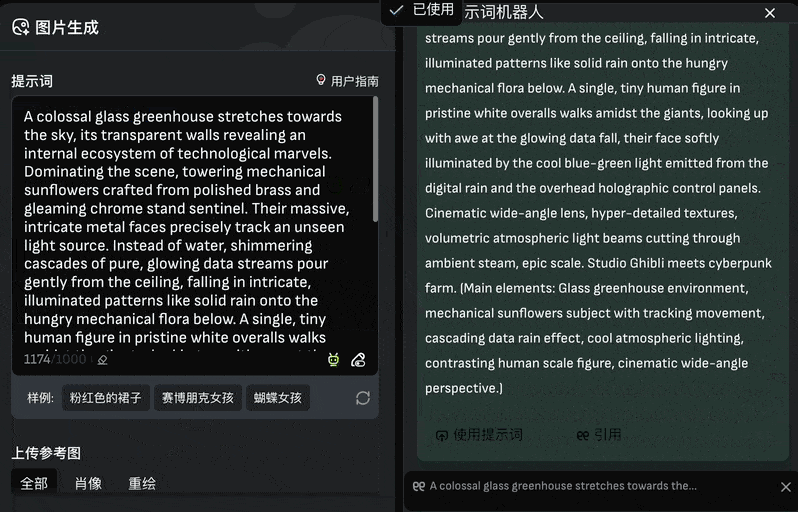
Standard parameters like image count, dimensions, and negative prompts are also configurable:

The results show impressive detail with minimal artifacts in test cases like a glass of lemon sparkling water. First-person perspective generation is also supported.
For reference-based generation, three modes are available: Full Reference, which uses the entire image as a guide; Portrait, which extracts facial features for style transfers; and Redraw, which re-renders images into artistic styles like photorealistic, illustration, Pixar-style, or 3D.
△ Left: Reference image; Right: Cyberpunk style conversion
Image Agent: Interactive Batch Processing
The standout feature is the Image Agent, an interactive chat interface that interprets intent from context. It supports batch editing and generation. For instance, after generating a puppy chasing a frisbee, users can request a pixel art style shift. Vivago 2.0 processes four images simultaneously while maintaining consistency with original elements.
The agent also includes “rewrite” and “help me write” functions to simplify prompt creation using plain language.
Video Generation: Keyframes and Quality Enhancement
Video generation operates in image-to-video and text-to-video modes. The image-to-video mode allows for smooth transformations by setting start and end frames via two key images.
The interface streamlines this process; users can initiate video creation directly from generated images on the canvas. This transforms static assets, like a bicycle-riding image or even memes, into dynamic videos with a single click. Notably, Vivago 2.0 automatically enhances image quality during this process, handling realistic scenes and imaginative fantasies alike.
AI Podcast: Lip-Sync and Voice Synthesis
The final component is the AI Podcast feature, which focuses on lip-syncing capabilities. Users can provide their own voice recording or use text-to-speech generation. The system can also generate content based on existing images or videos, syncing lip movements to inputted text such as “Life is like a box of chocolates. You never know what you’re gonna get”.
In practice, automated quality enhancement reduces post-processing time but may introduce unpredictable latency during peak loads.
I read the release notes for VivaGo 2.0, and what stood out to me is the shift from isolated media generation to a unified multimodal pipeline. The team claims this single product handles image, video, and podcast creation with hundreds of effects, aiming to reduce the friction of stitching together disparate tools.
The technical demonstration highlights precise synchronization between audio inputs and visual outputs. Specifically, they selected an image showing a profile view of a person to test lip-syncing accuracy. The result remains smooth and natural, even as the character’s body language changes in sync with the speech. This level of temporal coherence is often where lab demos fail under production load.
I think lip-sync latency will dictate your user experience, not just generation speed. Operationally, unified pipelines reduce integration debt but increase single-point-of-failure risk. In practice, profile-view testing is a good start, but edge cases like occlusion need real-world validation.
VivaGo 2.0 expands beyond these core capabilities to offer even more social and open-ended features, signaling an intent to capture broader creator workflows rather than just technical benchmarks.
https://mp.weixin.qq.com/s/bYNU6Mei2pq7KuFR8Ik2dQ
Feature Expansion: Hundreds of Effects at Your Fingertips
The VivaGo 2.0 release leans heavily on accessibility through effect templates. The platform now ships with over 300 stylish options that users can apply via a single click, effectively lowering the barrier to entry for non-technical creators. I read the documentation and noted this is positioned as a way to let beginners “instantly become effect masters.”
I think template libraries reduce user friction but increase storage overhead for edge caching. Operationally, single-click application sounds great until you hit rate limits on the inference endpoint.
To demonstrate the pipeline, we uploaded an AI-generated image of a little girl into the system. The result was a smooth outfit change with minimal latency visible in the preview. This highlights the underlying model’s ability to handle semantic swaps without requiring complex prompt engineering from the end-user.
In practice, if the swap logic isn’t cached, you’re burning GPU cycles on repetitive requests. I think smooth transitions are nice; consistent identity preservation is what keeps users coming back.
The Creative Community module introduces a social layer where creators can share millions of imaginative ideas. Users can “borrow” these concepts and directly use the same prompts, creating a feedback loop for content generation. I followed the release notes, which highlight this as a key differentiator for user retention.
Here are more excellent examples from the community:
Looking ahead, the team is preparing to launch a Topics feature. This will allow users to participate in trending topics to increase the exposure of their works. Currently, beta access for this feature is limited, suggesting they are still stress-testing the recommendation algorithm.
The VivaGo 2.0 AI toolbox also includes diverse functional modules such as 3D generation, AI virtual try-on, and video background removal:
Interested users are encouraged to explore these features firsthand. However, the launch has not been without growing pains. Vivago 2.0 has been quite popular since its launch, sometimes even causing server congestion due to high traffic. This indicates a need for better auto-scaling policies or queue management in the near future.
The Next Evolution of Open-Source SOTA
I read the technical breakdown for Vivago 2.0’s new Image Agent, HiDream-A1. It doesn’t just generate; it edits and converses. But before we celebrate the “all-around” claim, let’s look at the engine under the hood. The filing shows HiDream-A1 integrates advanced closed-source models—HiDream-I1.1 and HiDream-E1.1—which are built upon the open-source foundations of HiDream-I1 and HiDream-E1.
Operationally, closed-source integrations mean vendor lock-in risks for your inference pipeline. Check if these “advanced” layers expose stable APIs or just proprietary endpoints.
The HiDream-I1 Foundation Model
At the core is HiDream-I1, a 17-billion-parameter image generation foundation model. The team released it in three distinct flavors, each targeting a different latency budget:
- HiDream-I1-Full: The complete version requiring over 50 diffusion steps. It’s for high-precision work like commercial poster design where quality trumps speed.
- HiDream-I1-Dev: A guided distilled version cutting steps to 28. This is the “golden balance” between fidelity and throughput.
- HiDream-I1-Fast: An ultra-fast variant generating high-quality images in just 14 steps, designed for real-time applications.
The performance claims are aggressive. Less than 24 hours after release, HiDream-I1-Dev topped the Artificial Analysis Image Generation Arena leaderboard. It also hit State-of-the-Art (SOTA) results on three key benchmarks:
- HPS: Evaluates semantic relevance, image quality, and aesthetics.
- GenEval & DPG-Bench: Measure semantic alignment between generated images and input text.
In practice, leaderboard spikes often reflect specific prompt distributions rather than general robustness. Verify if the SOTA holds on your actual production dataset before committing resources.
HiDream-E1: Interactive Editing via Voice
Then there’s HiDream-E1, an open-source large model for interactive image editing. It features a recently viral capability: editing images via voice commands, similar to GPT-4o. The filing explicitly states that the combination of HiDream-I1 and HiDream-E1 can be considered the open-source equivalent of GPT-4o’s multimodal capabilities.
Architecture: Sparse MoE in DiT
The real engineering intrigue lies in how HiDream-I1 achieves this efficiency. It integrates Sparse Mixture-of-Experts (MoE) technology into the Diffusion Transformer architecture. They designed a dual-stream to single-stream hybrid sparse DiT structure.
Here’s how it works:
- Dual-Stream Phase: The model processes image and text tokens separately, like two hands performing distinct tasks. Each modality has its own dedicated channel for thorough characteristic extraction.
- Single-Stream Phase: The architecture switches to allow deep fusion of both modalities.
The “ingenious” part is the dynamic Mixture-of-Experts (MoE) router in both phases. It dynamically assigns each input token to the expert module best suited to handle it, optimizing compute usage per token rather than running dense layers for everything.
I think moE routers add inference complexity and potential cold-start latency. Ensure your serving infrastructure can handle dynamic routing overhead without spiking p99 response times.
Text Encoding and Training Strategy
For text understanding, HiDream-I1 uses a “four-pronged” hybrid strategy:
- Long-context CLIP: Provides visual-semantic alignment.
- T5 Encoder: Handles complex text structures.
- Llama 3.1: Contributes deep semantic understanding.
Notably, features are extracted from multiple intermediate layers of the LLM to prevent loss of detailed information in the final layer output. This comprehensive approach significantly enhances prompt adherence.
Training employed progressive resolution scaling: starting at 256×256, moving to 512×512, and finally reaching 1024×1024.
HiDream-A1: The All-Around Agent
The ZhiXiang Future team didn’t stop at text-to-image. They extended HiDream-I1 into an instruction-based editing model, HiDream-E1, using a “context learning” approach. Users provide the original image and instructions, and the model executes the modification.
Finally, they integrated both to launch HiDream-A1. This agent acts as an “all-around image assistant,” capable of:
- Generating images from descriptions.
- Editing images via instructions.
- Engaging in multi-turn conversational creation.
Users can complete complex tasks through natural language, much like chatting with ChatGPT.
Operationally, multi-turn conversational agents increase context window costs and latency. Monitor token usage closely; a “chat” interface can quickly become an expensive debugging nightmare if not rate-limited.
The Pragmatic Path of ZhiXiang Future’s Multimodal Engine
In practice, controllable scale beats GPU arms races for startups that need to ship revenue, not just benchmarks.
I’ve been tracking the funding and technical trajectory of ZhiXiang Future, a company founded in March 2023 by Tao Mei. While the corporate entity is new, Mei is an established heavyweight: an Foreign Academician of the Canadian Academy of Engineering and a Fellow of IEEE, IAPR, and CAAI. His pedigree signals serious expertise in AI, computer vision, and multimedia, but for platform engineers, the real story lies in their go-to-market strategy.
The core team hails from technical divisions at global Fortune 500s including Microsoft, Baidu, Tencent, Huawei, JD.com, and ByteDance. Over 90% hold doctoral or master’s degrees, with many alumni of the University of Science and Technology of China (USTC). Crucially, most possess deep backgrounds in AI video technology. As far back as 2017, they published “To Create What You Tell: Generating Videos from Captions” at the ACM Multimedia conference.
I think legacy GAN research proves long-term commitment to visual generation, reducing the risk of chasing fleeting trends.
That paper was among the first academic explorations of text-to-video generation—then termed Caption-to-Video. While their early GAN-based outputs were imperfect by today’s standards, the forward-looking nature of that work laid the groundwork for their current breakthroughs. Leveraging this accumulation, ZhiXiang Future became the first globally launched open-source image and video generation model based on the Diffusion Transformer (DiT) architecture.
Unlike hyperscalers burning tens of thousands of GPUs, ZhiXiang Future adopted a pragmatic path: focusing technically on visual multimodal foundation models while offering commercially viable, controllable solutions. This approach has resonated with investors who prioritize technical viability over raw compute dominance.
Their financing journey reflects this confidence. After seed funding from Alpha Community and Zhonghe Da Seed No. 1 Fund in April 2023, they completed a Pre-A round led by Dunhong Capital in the first half of 2024. By late 2024, an A-round led by state-owned funds—primarily Hefei Industrial Investment—closed with the A-round funding scale reaching hundreds of millions of RMB. Co-investors included the Anhui Province AI Mother Fund and Hubei Changjiang Film Group Co., Ltd.
Operationally, state-backed capital reduces runway anxiety, allowing engineering teams to focus on product stability over survival.
Tao Mei articulates this strategy clearly: “Large language models require massive computing power and funding. In 2023, thousands of GPUs were needed; in 2024, tens of thousands are required. This is a winner-takes-all field. For Chinese startups, raising such large amounts of capital is difficult, as is keeping up with the competition from tech giants. The video industry track does not require such massive investment, has controllable scale, and is closest to commercialization.”
Market data supports this pivot. In 2023, approximately $20 billion in global AIGC revenue came from video and images, representing 50%-60% of the total. Midjourney alone generated $200 million in this segment, proving strong product-market fit (PMF).
Since March 2023, ZhiXiang Future has released several key artifacts:
- ZhiXiang Multimodal Large Model: A parameter scale exceeding tens of billions, enabling joint modeling of text, images, video, and 3D content. It has successfully passed both model and algorithm filing requirements.
- “ZhiXiang AI” Product Series: Offers image generation/editing, 4K high-definition output, global/local controllability, and script-driven multi-shot video generation. These features provide distinct commercial advantages in AIGC technology and digital creativity.
In 2024, the company accelerated strategic collaborations, signing a partnership with Ciwen Media and launching an “AI+” cooperation plan jointly with Shanghai Film Group. They also released the first national-level AIGC video ringtones application,
Multimodal AI Dark Horse Unveils New Tool: One Product for Image, Video, and Podcast Generation with Hundreds of Effects by Expert Team
I read the filing from ZhiXiang Future’s launch event in Beijing on December 28, 2024. The production implication here is a pivot from experimental MaaS to shipped SaaS tools, signaling that they are ready for enterprise integration rather than just lab demos. They debuted ZhiXiang Multimodal Generation Large Model 3.0 and ZhiXiang Multimodal Understanding Large Model 1.0 at the Anhui Artificial Intelligence Industry Pilot Zone ceremony.
The Tech Specs: What Actually Ships
The ZhiXiang Multimodal Generation Large Model 3.0 claims comprehensive upgrades in image and video generation. This includes improvements in visual quality, relevance, and enhanced controllability of camera and scene movements. I followed the release notes for optimizations driven by multi-scenario applications, which suggests they are targeting specific workflow bottlenecks rather than generic creativity.
In practice, controllability is the only metric that matters when you’re trying to replace manual editing in a production pipeline.
Simultaneously, ZhiXiang Multimodal Understanding Large Model 1.0 aims for more precise understanding of image and video content. It uses object-level visual modeling and event-level spatiotemporal modeling to achieve this accuracy. This isn’t just about generating pixels; it’s about structuring data so downstream automation can actually parse the output.
I think if the model can’t reliably segment objects, your automated post-production scripts will break on edge cases every time.
The Business Model: From MaaS to RaaS
Entrepreneurship in AIGC is brutal, but Mei Tao’s goals extend beyond commercial success to a broader mission. “I am not starting this business as an individual; I represent Chinese tech experts embarking on a new era to carve out a path,” Mei stated. He added that if their technology and commercialization strategies succeed, the story should be replicable for others.
Operationally, founders talking about “replicable paths” usually means they’ve standardized their API contracts enough for us to integrate without custom glue code.
ZhiXiang Future’s business model has evolved significantly between 2023 and 2025. In 2023, they provided foundational capabilities via Model-as-a-Service (MaaS). By 2024, they shifted to Software-as-a-Service (SaaS), launching tool-based products that validated application value in professional scenarios.
In practice, moving from MaaS to SaaS reduces our infrastructure overhead because we no longer need to manage the underlying inference cluster ourselves.
By 2025, they launched a strategy focusing on “IP secondary creation + consumer market penetration.” This aims to build a scaled commercial ecosystem and integrate upstream and downstream resources. They are moving toward RaaS (Results-as-a-Service), delivering growth directly rather than just selling tools.
Strategic Partnerships and Market Position
The company has secured key partnerships, including AI One-Word Video with China Mobile Migu and a strategic cooperation agreement with Cambricon in Beijing. These alliances suggest they are betting on hardware-software co-optimization to keep latency low and costs manageable at scale.
I think partnering with chip makers like Cambricon is a smart move if you want to avoid vendor lock-in from the major cloud providers during inference scaling.
ZhiXiang Future will focus primarily on the application and commercialization of multimodal large models going forward. This trajectory aligns with the common AIGC development path: meeting high demands of professional users first, then lowering barriers for mass-market adoption.
The Verdict: 2025 as a Breakout Year
Undoubtedly, with the emergence of multimodal AI capabilities, 2025 is destined to be a breakout year for this technology. AIGC video generation is being viewed as a new-generation super platform akin to TikTok. Yet, beneath clear trends and market opportunities, only teams with genuine technical strength, product intuition, and clear commercialization rhythms can soar to success.
Operationally, hype cycles kill projects; the teams that survive are those who treat latency and cost per token as hard constraints from day one.
ZhiXiang Future is currently demonstrating these very traits and potential. I’m watching their SaaS rollout closely to see if they can maintain quality while scaling to consumer volumes without blowing up their inference costs.
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google