I Can’t Write CUDA, But My H100 Just Got Faster
I spend half my week wrestling with torch.compile flags and the other half staring at memory-bound bottlenecks that no amount of Python optimization can fix. The promise of high-performance GPU kernels without touching a single line of C++ is usually just marketing fluff, but Tri Dao’s new work, QuACK, claims to actually deliver on that front.
Dao, co-author of the seminal Flash Attention and Mamba papers, has teamed up with two Princeton CS PhD students to release QuACK. It is a SOL (Structured Operator Library) memory-bound kernel library written entirely in Python using CuTe-DSL. There is no CUDA C++ code involved.
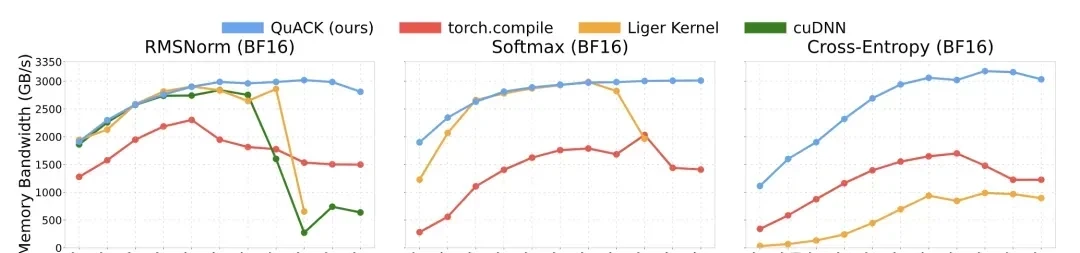
On an H100 with 3TB/s bandwidth, QuACK runs 33%-50% faster than deeply optimized libraries like PyTorch’s torch.compile and Liger.
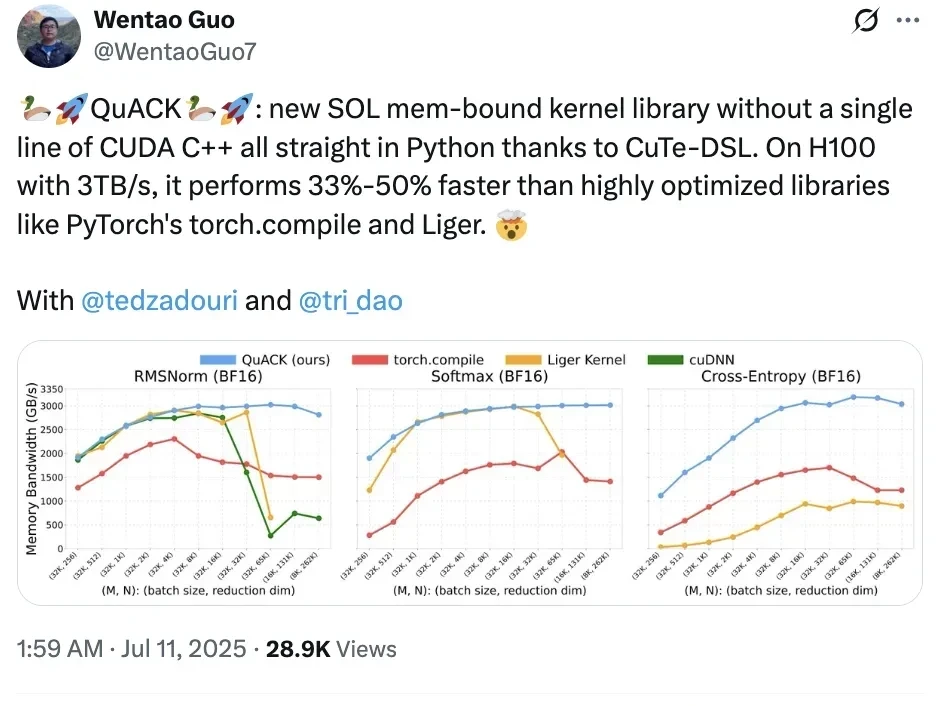
Dao argues that achieving “light speed” for memory-intensive kernels isn’t magic; it’s just about getting the details right.

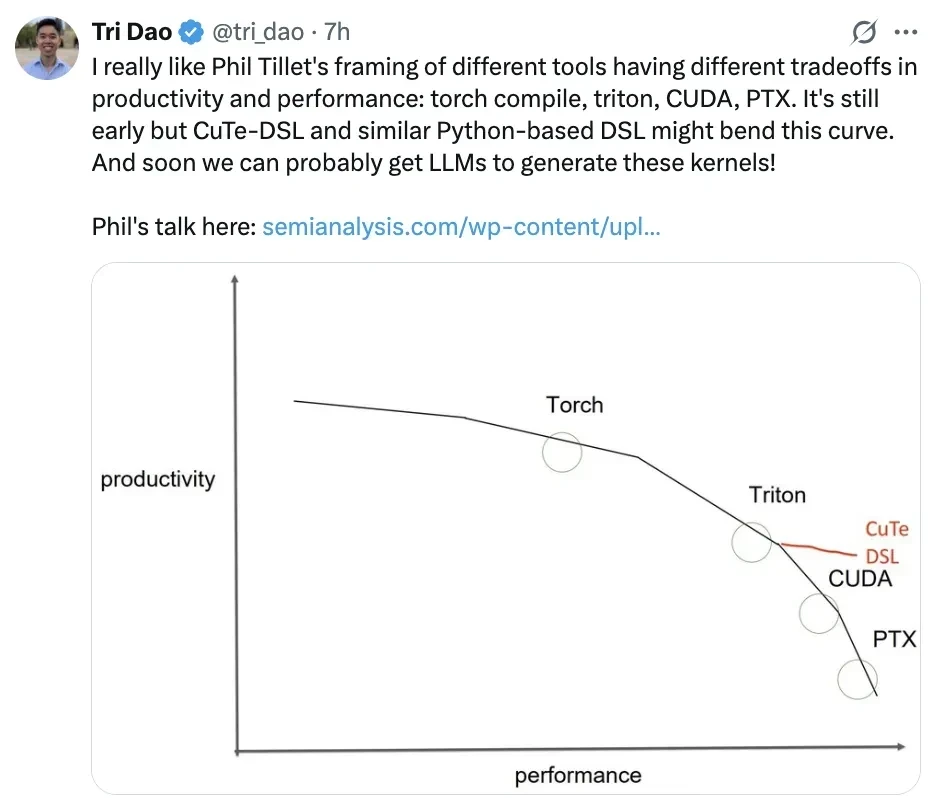
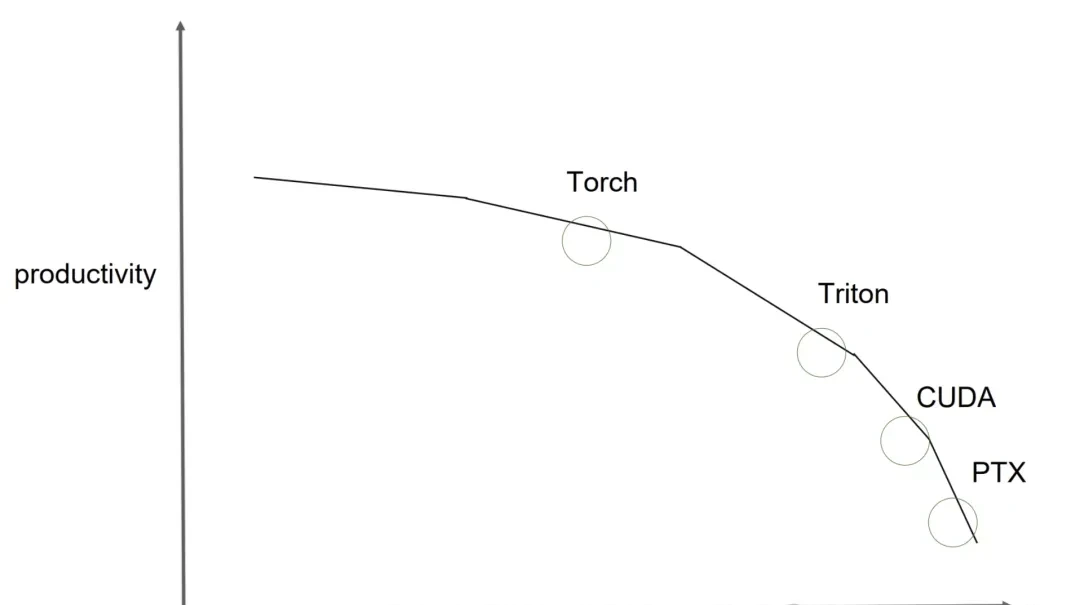
I really like Phil Tillet’s perspective on the trade-offs between productivity and performance across different tools, such as torch compile, triton, CUDA, and PTX.
However, CuTe-DSL and similar Python-based DSLs might change this landscape, although they are still in their early stages. Moreover, perhaps soon we will be able to have large language models generate these kernels!
I think python-only kernels could democratize high-performance computing for those who hate C++. As a builder, a 33%-50% speedup on H100s is significant enough to warrant immediate testing. Personally, cuTe-DSL looks like a serious contender against Triton for ease of use.
The release drew immediate attention from industry heavyweights. Vijay, a Senior Architect on the NVIDIA CUTLASS team, shared the work and praised his team’s CuTe-DSL for refining details to such an extent that experts like Dao can make GPUs run at lightning speed. He also teased more related content coming later this year.
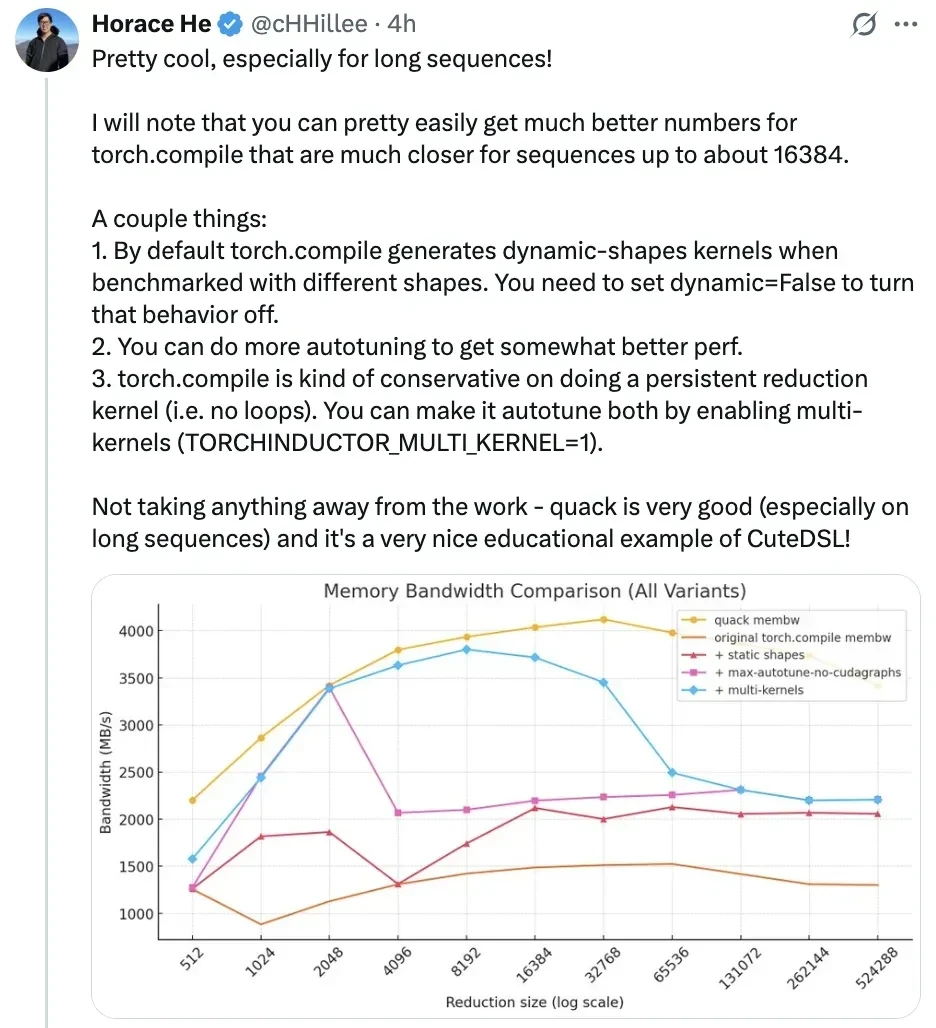
Horace He, a member of the PyTorch team, called it “too cool, especially for long sequences.” However, he noted that torch.compile performance can be optimized to approach ideal states when processing sequences up to ~16384 in length.
He offered specific advice for squeezing more out of torch.compile:
By default, if tested with different shapes,
torch.compilegenerates dynamic shape kernels; this behavior can be disabled by settingdynamic=False.
Performing more auto-tuning operations can further improve performance.
torch.compileis conservative in generating loop-free persistent reduction kernels; you can enable multi-kernel (by setting(TORCHINDUCTOR_MULTI_KERNEL=1)) to allow it to auto-tune.
He concluded that QuACK is an excellent piece of work and a great teaching example for CuTe-DSL.
Dao responded enthusiastically: “Awesome, this is exactly what we wanted. We will try these methods and update the charts.”

User Guide
The QuACK authors have published a tutorial explaining the implementation, complete with copy-pasteable code.
Optimizing Memory-Bound Kernels Without CUDA
I’ve spent years watching developers struggle with the bottleneck of memory-intensive operations, and this new work from the Flash Attention author directly addresses that pain point. The core problem is simple: while compute-heavy tasks like matrix multiplication are well-tuned, element-wise ops and reductions often stall because they wait on data transfer rather than computation.
The authors argue that by leveraging the thread and memory hierarchy of modern accelerators, we can push these kernels to their theoretical limits. Crucially, this isn’t a black-box optimization; it’s achieved using CuTe-DSL in Python, meaning you don’t need to write CUDA C or C++ to get high performance.
The distinction matters because memory-bound kernels are defined by low arithmetic intensity—the ratio of floating-point operations (FLOPs) to bytes transferred. Once you hit that threshold, throughput is dictated by bandwidth, not FLOP count. The team focused on element-wise activations and reduction operations like softmax and RMSNorm, which require aggregating values across threads.
I think this Python-based approach lowers the barrier for custom kernel optimization significantly. As a builder, understanding memory hierarchy is now accessible without deep C++ expertise. Personally, targeting reduction ops directly addresses a common training bottleneck.
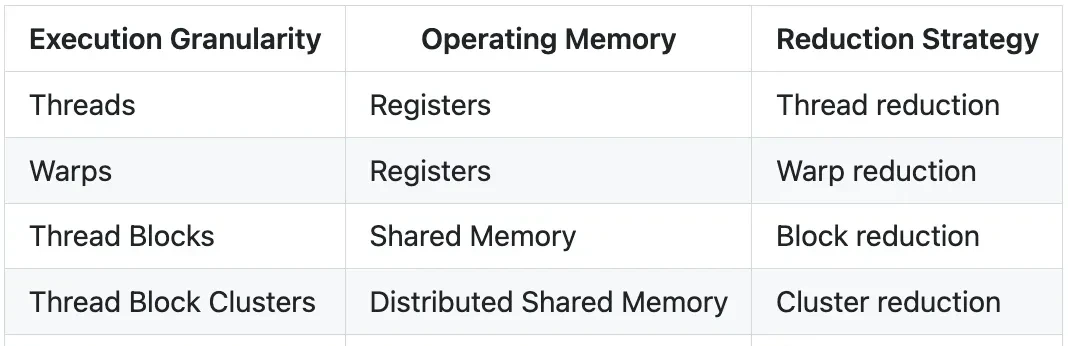
Hopper Architecture and Cluster Reductions
The implementation relies on specific hardware features, using the Hopper architecture (H100) as the baseline. CUDA execution here is structured into four levels: threads, thread blocks, thread block clusters, and the full grid. Threads run in groups of 32 called “warps” within a Streaming Multiprocessor (SM).
Each thread block accesses 192-256 KB of unified shared memory (SMEM). However, the game-changer is the H100’s thread clusters. These allow up to 16 thread blocks on adjacent SMs to share data via distributed shared memory (DSMEM) and perform atomic operations using low-latency cluster barriers. This avoids costly round-trips to global memory.

The authors implemented three key LLM kernels using CuTe DSL: RMSNorm, softmax, and cross-entropy loss. The goal is “GPU light-speed throughput,” achieved through coalesced global memory loading/storing and hardware-aware reduction strategies. They also detail cluster reductions for ultra-large-scale tasks, a feature introduced in Hopper.
I think cluster barriers on H100 make inter-SM communication viable for custom kernels. As a builder, cuTe DSL provides a practical path to exploit DSMEM without manual CUDA management.
Navigating the H100 Memory Ladder
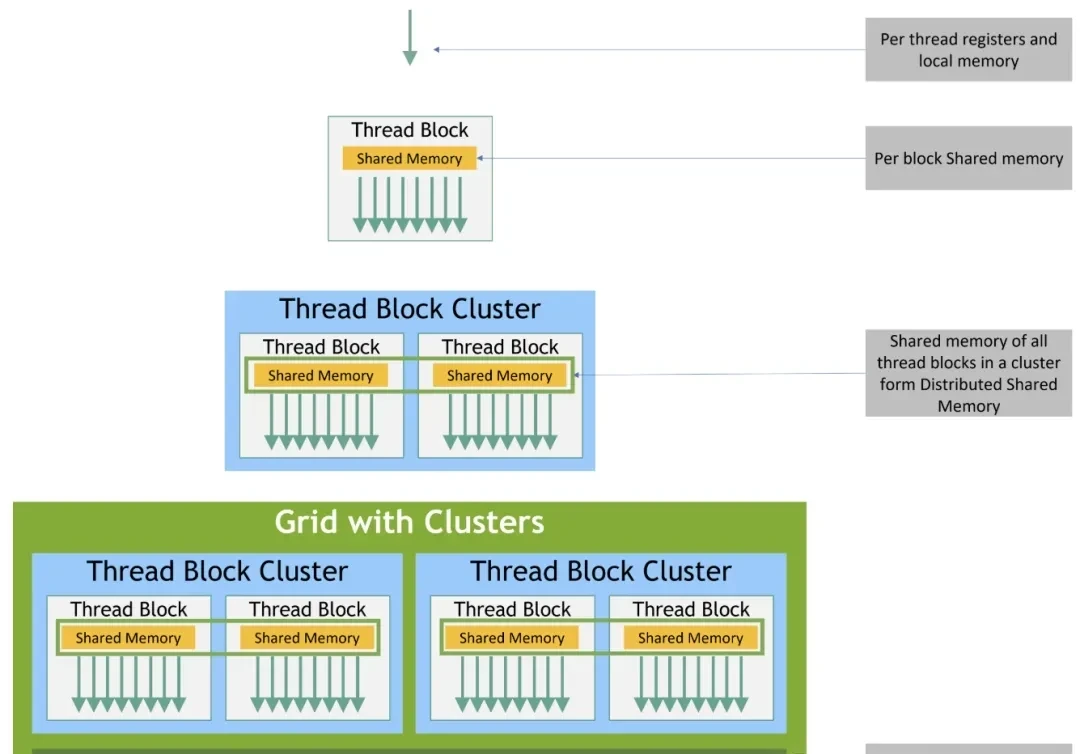
Correspondence between execution granularity and memory hierarchy in Hopper GPUs:
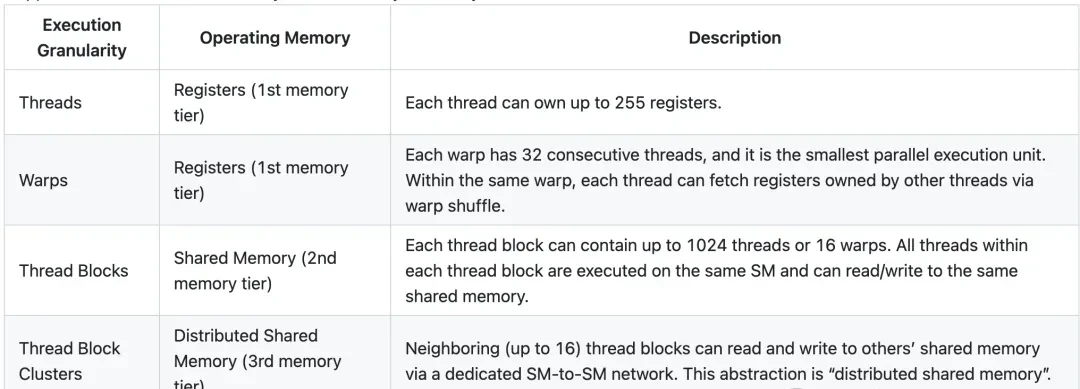
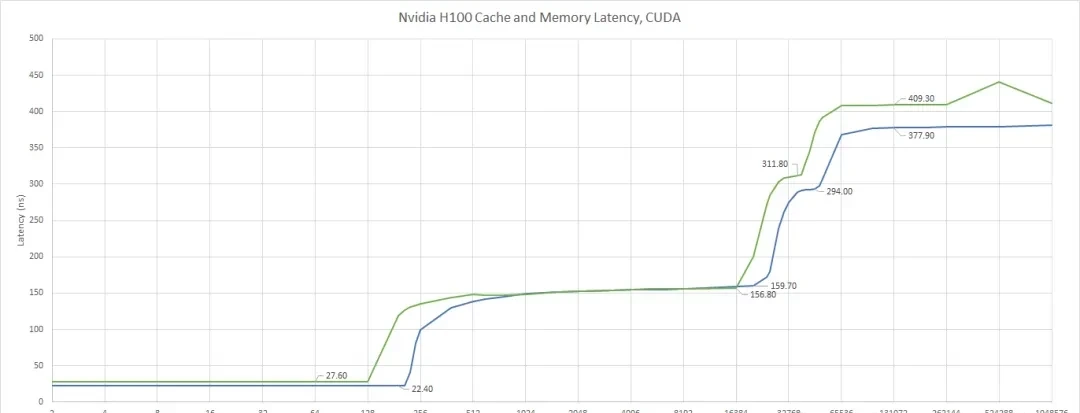
The core challenge here is that access latency and bandwidth vary drastically across each memory level. I read through the specifics: accessing a thread’s own registers takes only a few nanoseconds, while shared memory sits at about 10-20 nanoseconds. Moving up the stack, L2 cache latency spikes to 150-200 nanoseconds, and finally, hitting DRAM (main memory) takes approximately 400 nanoseconds.
Bandwidth tells a similar story. Registers can hit 100 TB/s, shared memory (SMEM) offers about 20-30 TB/s, and L2 cache provides 5-10 TB/s. For memory-bound kernels, the HBM3 VRAM bandwidth of the H100 (3.35TB/s) is often the hard performance bottleneck.
Therefore, to fully exploit hardware performance, when designing memory-intensive kernels, one must follow the memory hierarchy:
It is best to assign most local reduction operations to higher memory levels, passing only a small amount of locally reduced values to the next memory level. Chris Fleetwood provided a similar explanation for A100 (without thread block clusters) memory access latency in his blog, while H100 adds an extra memory level abstraction between shared memory (SMEM) and global memory (GMEM).
Personally, understanding this ladder is non-negotiable for serious kernel optimization. I think ignoring the L2 spike will kill your throughput on complex reductions. As a builder, the H100’s extra layer demands a rethink of traditional A100 patterns.
Measuring Memory Access Latency in H100
Hardware-Aware Loading and Storage Strategies
When writing kernel code, the first problem to solve is “how to load input data and store results.” For memory-bound kernels, HBM’s 3.35 TB/s is usually the bottleneck, meaning extreme optimization of loading and storage strategies is required.
Before launching the kernel, input data is partitioned using a specific thread-value layout (TV-layout). This determines how each thread loads and processes values along the reduction dimension.
Since every thread must load data from global memory (GMEM), it is necessary to ensure that each load operation transfers the maximum number of bits continuously on the hardware. This technique is commonly known as memory coalescing or coalesced access to global memory, which is explained in more detail in the CUDA Best Practices Guide.
Coalesced Memory Access

In the H100, this means that each thread must process data in multiples of 128 bits, specifically 4x FP32 or 8x BF16. Consequently, for FP32, four load and store operations are combined (or “vectorized”) into a single memory transaction, thereby maximizing throughput.
In practice, the author asynchronously loads data from global memory (GMEM) to shared memory (SMEM), then vectorizes these loads into registers. Once the reduction yields the final result, it is stored directly back into global memory.
At times, input data can be reloaded from global or shared memory into registers to reduce register pressure and prevent data “overflow.”
Below is a code snippet for the load operation written in Python using the CuTe DSL. To keep things simple, type conversion and mask predicate-related code have been omitted here.
Personally, vectorizing loads to 128-bit chunks is the baseline for H100 efficiency. I think cuTe DSL simplifies what used to be painful manual memory management.
Hardware-Aware Reduction Strategies
The core problem I see here is that most developers treat GPU memory as a flat black box, leading to inefficient data movement that bottlenecks performance. Once each thread holds a small input vector, the reduction phase begins, requiring one or more full row scans. The critical insight from this work is that access latency increases and bandwidth decreases as you move down the memory hierarchy. Therefore, reduction strategies must strictly follow this hardware memory hierarchy.
Partial results stored in higher levels of the memory pyramid should be aggregated immediately, passing only locally reduced values to the next memory level. The author performs reductions from the top down according to the table below, ensuring that load and store operations occur exclusively within their corresponding memory levels at each step.
Reduction strategies across different memory levels:
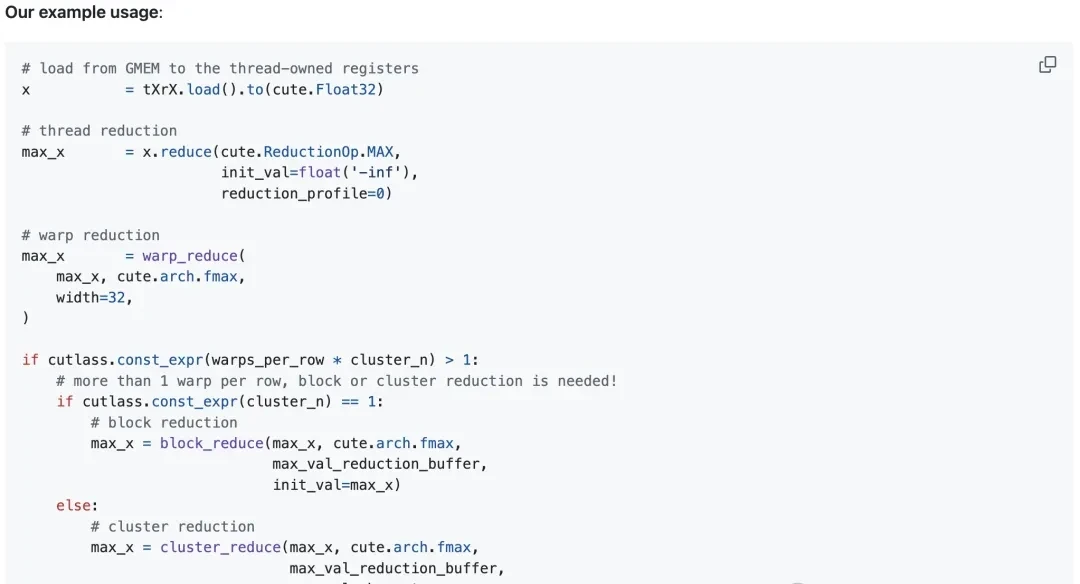
1. Thread-Level Reduction (Register Read/Write)
Each thread locally reduces multiple vectorized loaded values. The author uses the TensorSSA.reduce function, which requires a combinable reduction operator (op), an initial value before reduction (init_val), and a reduction dimension profile (reduction_profile).
As a builder, register-level reduction is the fastest path, so keep data there as long as possible.
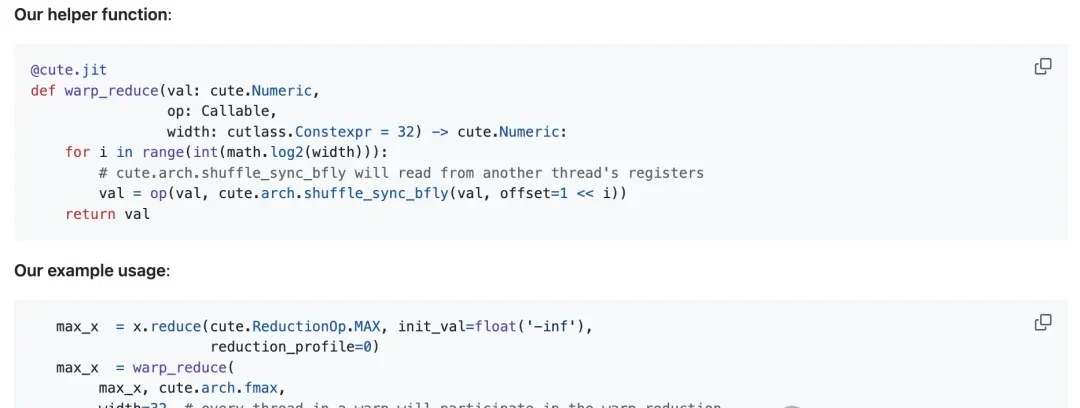
2. Warp-Level Reduction (Register Read/Write)
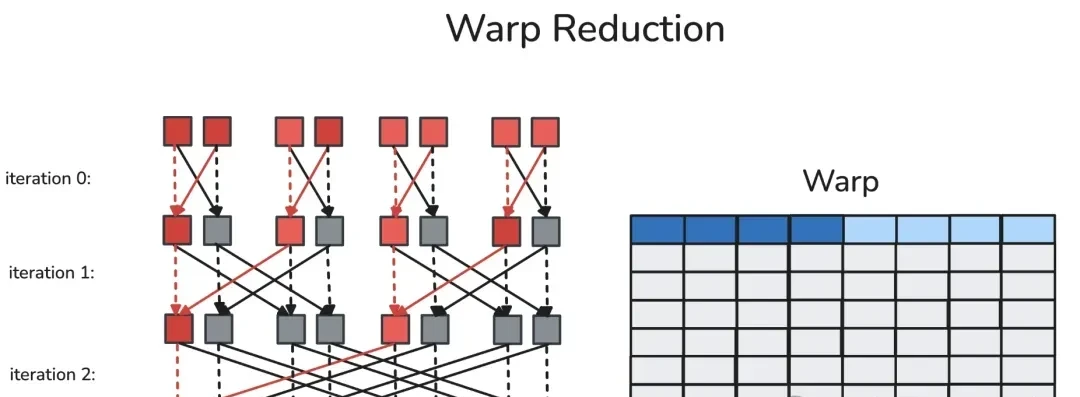
A warp is a fixed group of 32 contiguous threads that execute the same instructions per cycle. Synchronous warp reduction allows each thread within the same warp to read another thread’s register via a dedicated shuffle network in a single cycle. After butterfly warp reduction, every thread in the same warp obtains the reduced value.
The author defines an auxiliary function warp_reduce to execute warp reductions in a “butterfly” order. For detailed explanations of warp-level primitives, readers are referred to Yuan and Vinod’s CUDA blog post, “Using CUDA Warp-Level Primitives.”
Butterfly warp reduction, also known as “xor warp shuffle”:
Personally, warp shuffles are free if you structure your logic to avoid bank conflicts.
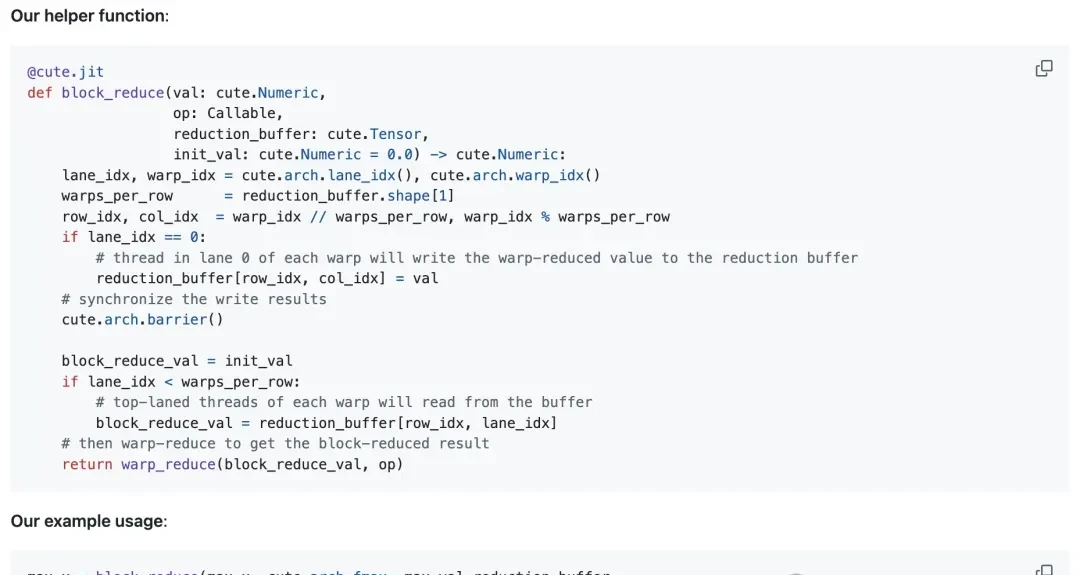
3. Thread Block-Level Reduction (Shared Memory Read/Write)
A thread block typically contains multiple warps (up to 32 in the H100). In thread block reduction, the first thread of each participating warp writes that warp’s reduction result into a pre-allocated reduction buffer in shared memory.
After a thread block-level synchronization barrier ensures all participating warps have finished writing, the first thread of each warp reads data from the reduction buffer and locally calculates the thread block’s final reduction result.
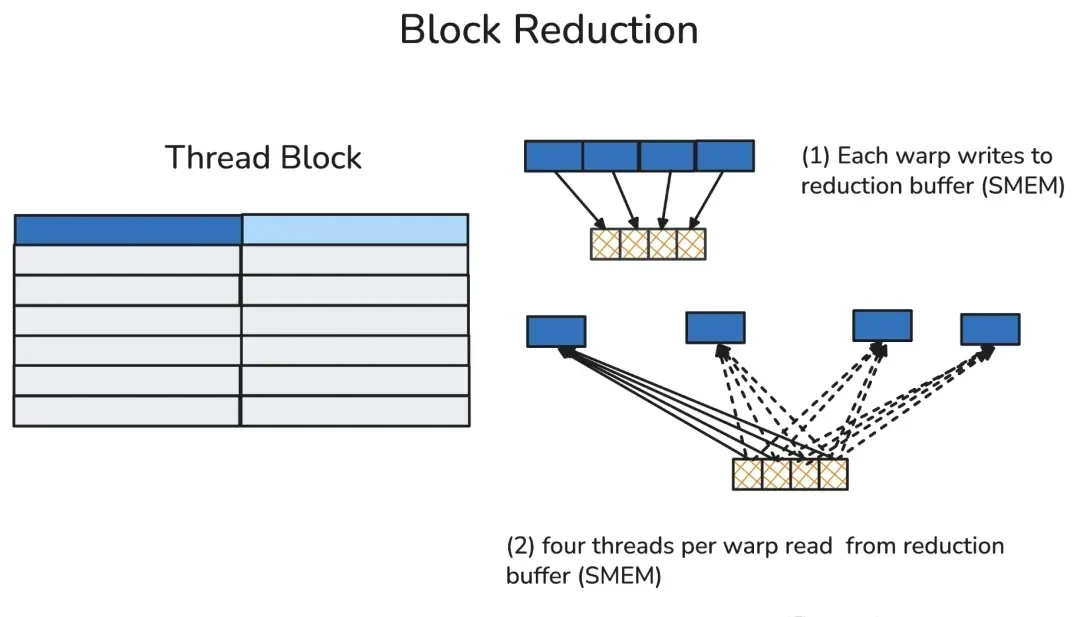
I think shared memory is fast, but you must manage synchronization barriers carefully to avoid stalls.
4. Cluster-Level Reduction (Distributed Shared Memory Read/Write)
Thread block clusters are a new execution level introduced in the Hopper architecture, consisting of a group of adjacent thread blocks (up to 16). Thread blocks within the same cluster communicate via Distributed Shared Memory (DSMEM), supported by a dedicated high-speed inter-SM network.
Within the same cluster, all threads can access shared memory from other SMs via DSMEM, where the virtual address space of shared memory is logically distributed across all thread blocks in the cluster. DSMEM can be accessed directly via simple pointers.
Distributed Shared Memory:

In cluster reduction, the author first sends the current warp’s reduction results to the shared memory buffers of peer thread blocks via the dedicated inter-SM network (i.e., DSMEM).
Subsequently, each warp retrieves values from all warps in its local reduction buffer and performs reduction on these values.
To handle the complexity of these reductions, a barrier is also required here to count the number of data arrivals. This prevents premature access to local shared memory, which would otherwise cause illegal memory access errors.
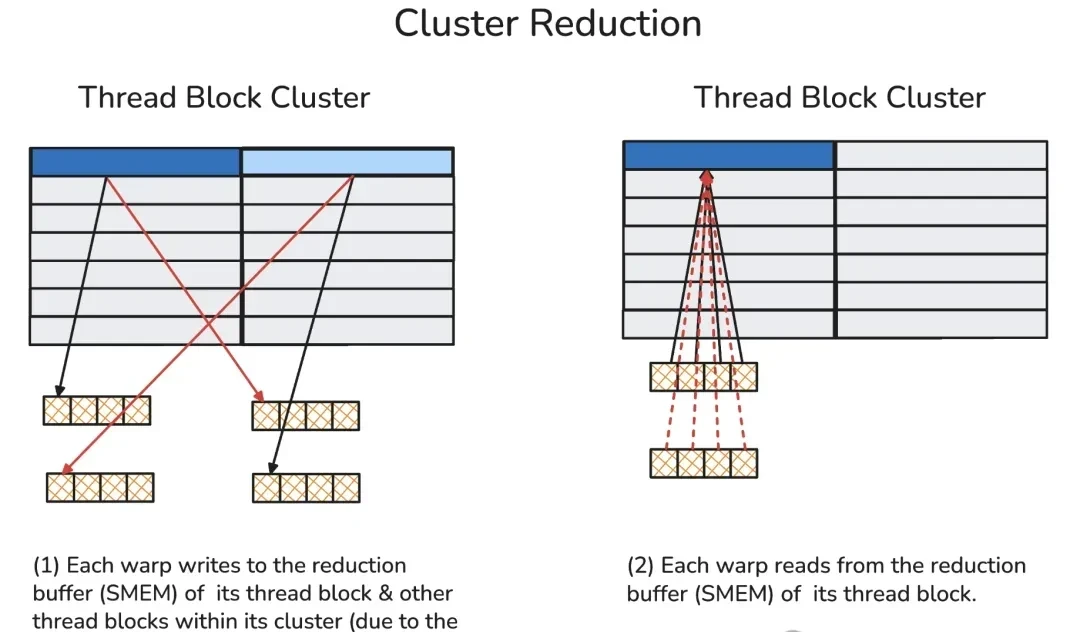

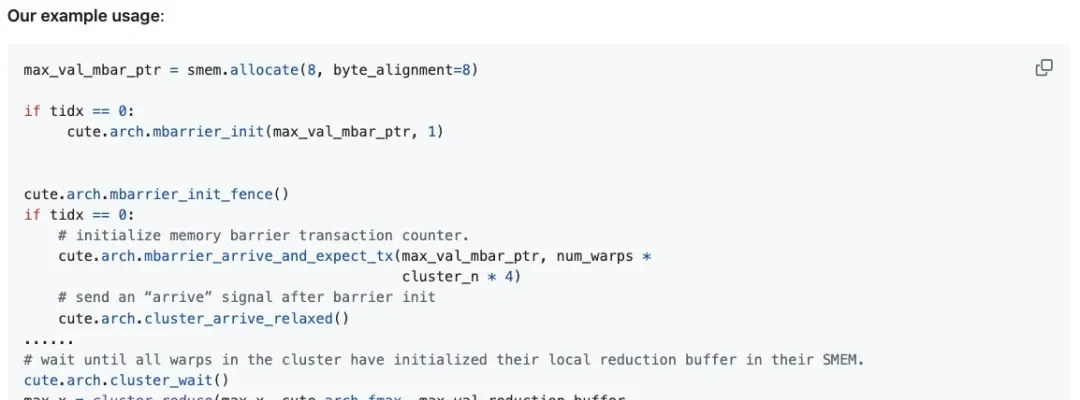
When viewing the entire reduction process as a whole, thread-level reduction is performed first. Then, results are aggregated within the same warp (i.e., warp-level reduction). Finally, based on the number of reduction dimensions, reduced values are further propagated across each thread block or thread block cluster.
As a builder, this level of hardware control feels like a step back for developer velocity. I prefer abstractions that hide these synchronization details from me. Personally, the performance gains are impressive, but the maintenance cost is high.
NCU Performance Analysis (Softmax Kernel)
I followed the author’s performance teardown of a softmax kernel running on an NVIDIA H100 with HBM3 memory. The setup used a batch dimension of 16K and a reduction dimension of 131K, targeting the hardware’s peak DRAM throughput of 3.35 TB/s.
The configuration specified a thread block cluster size of 4, 256 threads per block, and FP32 input data types. Both load and store operations were vectorized to move 128 bits (i.e., 4 FP32 values) per instruction. The results showed DRAM throughput hitting 3.01 TB/s, which is 89.7% of the peak DRAM throughput. Beyond standard shared memory (SMEM), the author noted that Distributed Shared Memory (DSMEM) was also utilized efficiently.
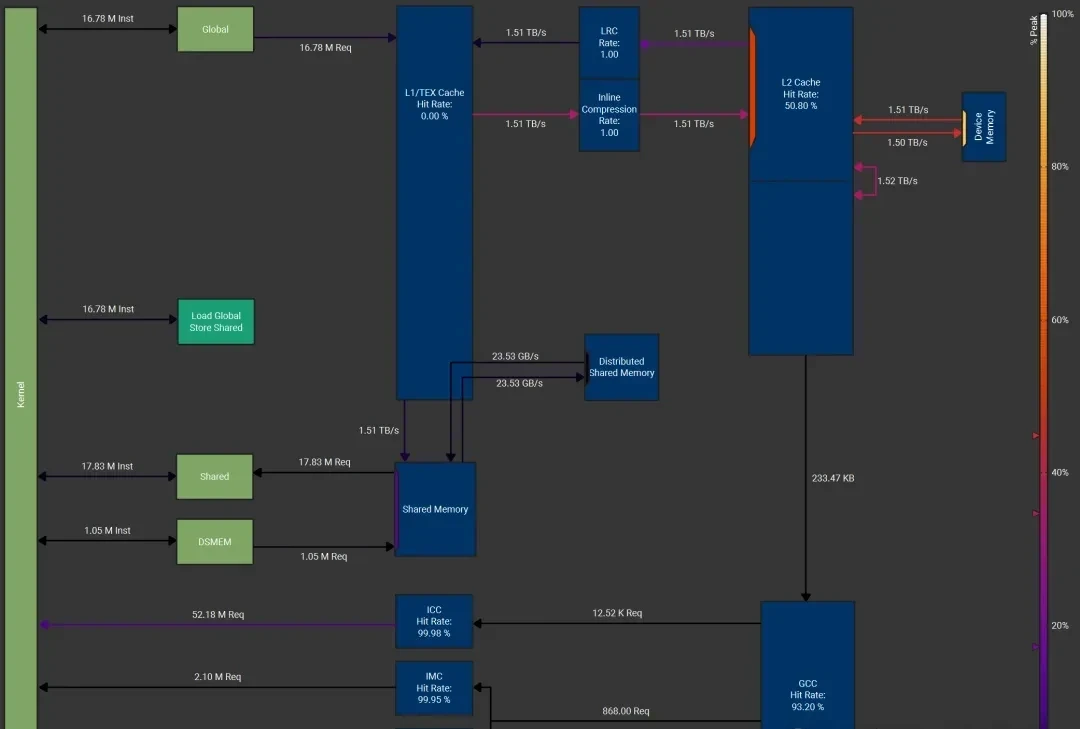
I also looked at how this compares against torch.compile (PyTorch version 2.7.1). The author extracted the Triton kernel code generated by the compiler to see where it fell short.
This specific softmax implementation performs two global memory loads—one for calculating row maximums and partial exponential sums, plus one for the final softmax values—along with a single store operation. While the Triton kernel still saturates the hardware’s DRAM throughput, those extra unnecessary loads hurt effective efficiency. The author calculated that the effective model memory throughput for the Triton kernel is approximately 2.0 TB/s, which is only two-thirds of the approximately 3.0 TB/s achieved by their custom implementation.
Triton kernel generated by torch.compile (tuning configuration section omitted):
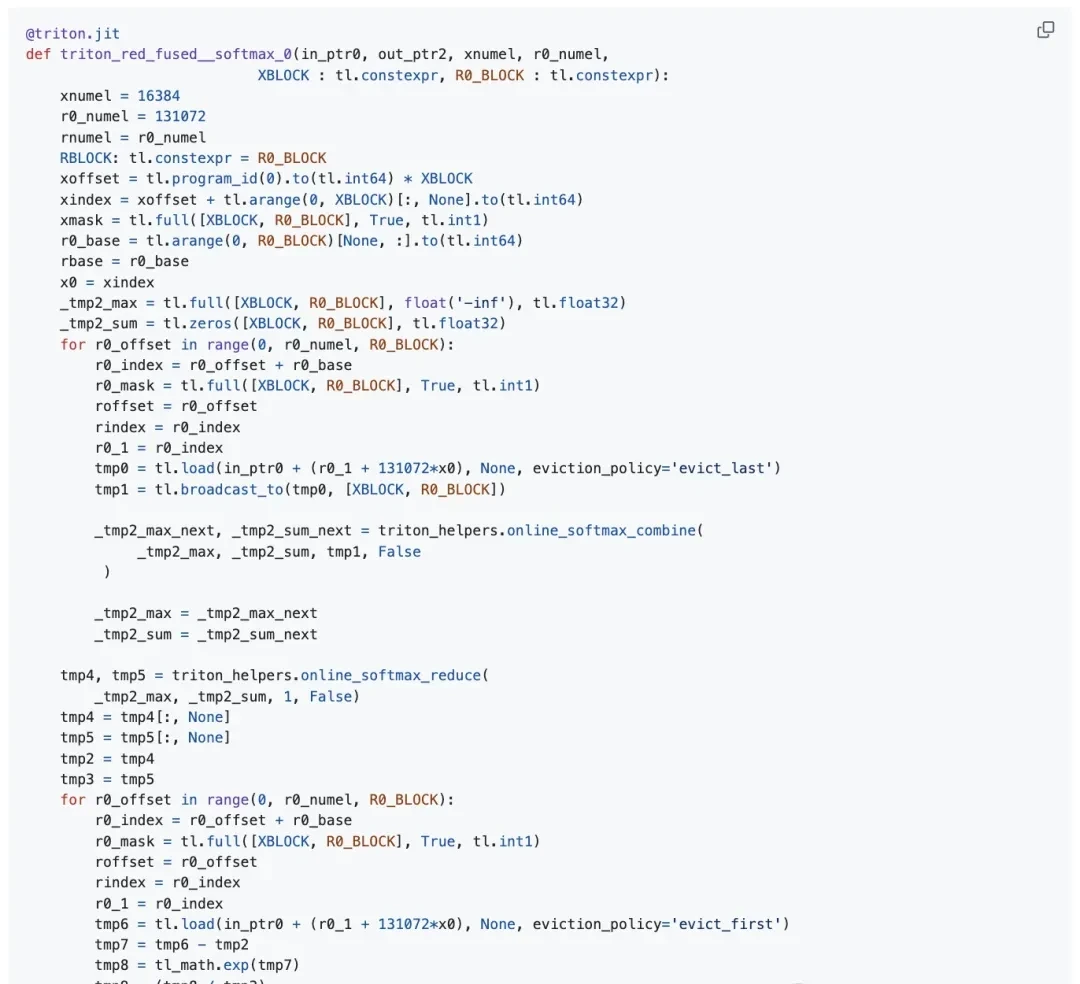
I think manual kernel tuning still beats compiler defaults for peak memory bandwidth. As a builder, vectorized loads are critical when squeezing every byte out of HBM3.
Memory Throughput
I read through the author’s benchmarks for RMSNorm, softmax, and cross-entropy loss on an NVIDIA H100 80GB GPU with HBM3 memory and an Intel Xeon Platinum 8468 CPU. The tests covered batch sizes from 8k to 32k and reduction dimensions up to 262k (256×1024), using FP32 and BF16 data types.
I compared the author’s CuTe DSL implementation against three baselines:
- Torch.compile (PyTorch 2.7.1) in default mode.
- Liger Kernels v0.5.10, limited to RMSNorm and softmax with dimensions capped at 65k.
- cuDNN v9.10.1, tested only for RMSNorm.
What stood out to me was the stability of the author’s approach. When reduction dimensions exceeded 4k, memory throughput held steady around 3 TB/s—roughly 90% of peak capacity. At a 262k reduction dimension, FP32 softmax hit 3.01 TB/s, while torch.compile lagged at 1.89 TB/s. That’s nearly 50% faster. For these three kernels, when dimensions are ≥65k, this implementation significantly outperforms all baseline schemes.
Model memory throughput for multiple kernels:
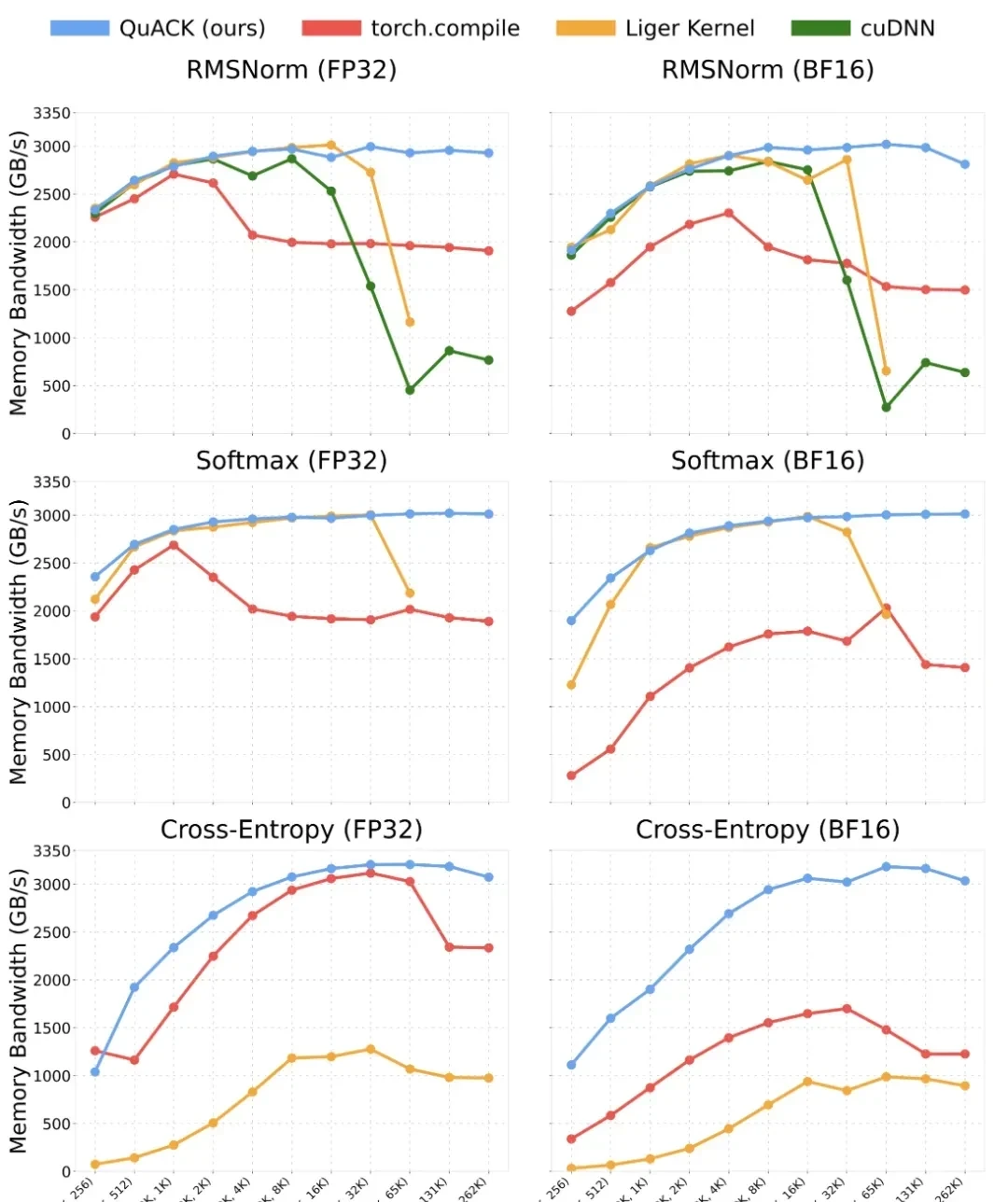
The author credits this performance at large input sizes (≥65k) to leveraging cluster reduction in the H100. When inputs saturate a Streaming Multiprocessor’s (SM) registers and shared memory, failing to use cluster reduction forces a switch to online algorithms like online softmax. This causes significant register spillover and drops throughput sharply.
For instance, using the Liger softmax kernel, increasing input size from 32k to 65k caused throughput to plummet from ~3.0 TB/s to ~2.0 TB/s.
Memory workload of the Liger softmax kernel with a batch dimension of 16k, reduction dimension of 65k, and FP32 data type:
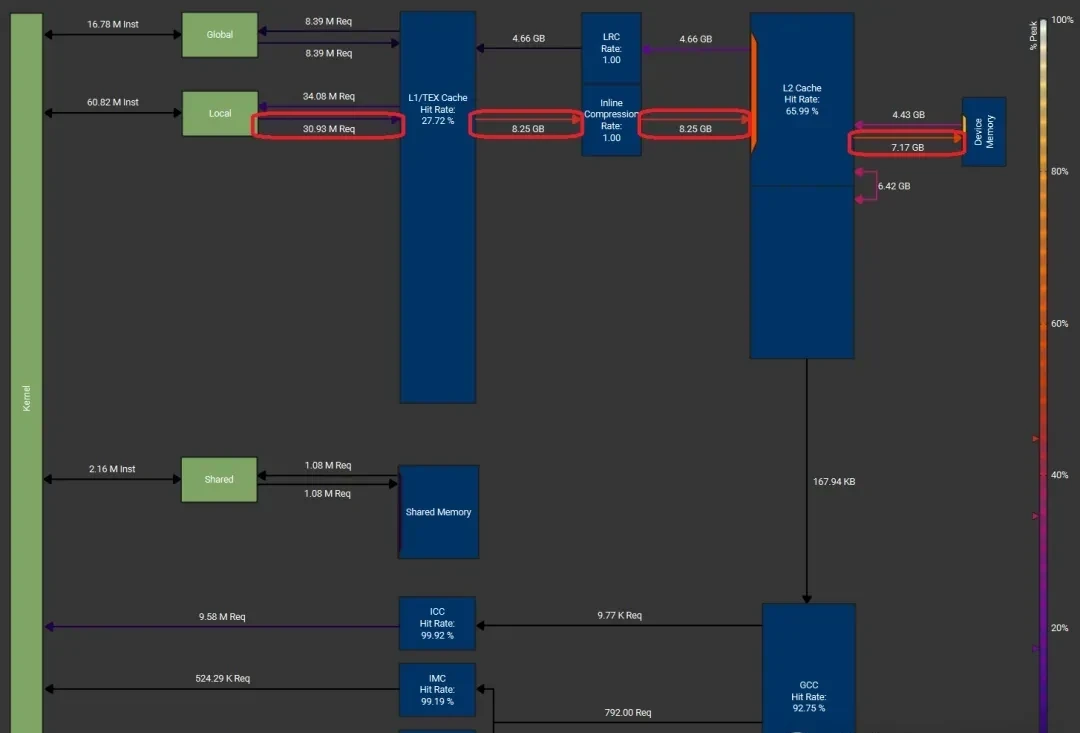
Register spillover (LDL instruction) in the Liger softmax kernel assembly code:
Cluster reduction allows multiple SMs to collaborate via DSMEM, effectively forming a “super” SM. If one SM handles 32k inputs, a cluster of size 16 can process 500k (0.5M) inputs without reloading from global memory (GMEM). By understanding the hardware architecture deeply, even with a standard three-pass softmax algorithm, they utilized every byte across the memory hierarchy to achieve “light-speed” throughput.
Personally, this cluster reduction insight is critical for anyone pushing H100 limits beyond small batches. I think cuTe DSL abstracts the complexity while delivering raw hardware efficiency. As a builder, watching Liger drop performance at 65k highlights why we need better kernel design.
No CUDA Code Needed to Boost H100 Performance by 33%-50%: Flash Attention Author’s New Work Goes Viral
The biggest bottleneck in modern AI isn’t just compute; it’s the friction of writing highly optimized, hardware-specific kernels. If you can automate that complexity without sacrificing performance, you unlock a massive leap in developer velocity. I’ve been following the release cycle of CuTe-DSL closely to see if this promise holds up for real-world engineering.
Summary
The authors demonstrated through practice that by carefully hand-writing CuTe kernels, it is possible to extract the full potential of all memory hierarchy levels in hardware, achieving “light-speed” memory throughput.
However, this efficiency comes at the cost of tuning for each operator and even each input shape, creating a natural trade-off between performance and development costs.
Phil Tillet (author of Triton) illustrated this point well with an image in his presentation.
Based on the authors’ experience using CuTe-DSL, it combines the development efficiency of Python with the control capabilities and performance of CUDA C++.
The authors believe that efficient GPU kernel development workflows can be automated.
For instance, the input tensor TV layout, load/store policies, and reduction helper functions used in RMSNorm can be directly applied to softmax kernels while still achieving comparable throughput.
Furthermore, CuTe DSL provides developers or other code running on top of CuTe DSL with flexible GPU kernel development capabilities.
Currently, applying large language models to automatically generate GPU kernels is an active area of research. In the future, it may be possible to simply call “LLM.compile” to generate highly optimized GPU kernels.
Personally, cuTe-DSL bridges the gap between Python ease and CUDA speed. I think automating kernel tuning saves weeks of engineering time. As a builder, reusing layout policies across operators is a smart pattern. Personally, lLM-generated kernels are promising but not production-ready yet.
About the Authors
This work has three authors.
Wentao Guo
Wentao Guo is currently a Ph.D. student in Computer Science at Princeton University, advised by Tri Dao.
Prior to this, he earned his undergraduate and master’s degrees in Computer Science from Cornell University.

Ted Zadouri
Ted Zadouri is also a Ph.D. student in Computer Science at Princeton University, having received his bachelor’s and master’s degrees from the University of California, Irvine, and the University of California, Los Angeles, respectively.
Previously, Ted interned at Intel and conducted research on parameter-efficient fine-tuning for large language models at Cohere.

Tri Dao
Tri Dao is currently an Assistant Professor of Computer Science at Princeton University and Chief Scientist at the generative AI startup Together AI.
He is renowned in academia for a series of works optimizing the attention mechanism in Transformer models.
Most notably, as one of the authors, he proposed the Mamba architecture, which has achieved state-of-the-art (SOTA) performance across various modalities including language, audio, and genomics.
In particular, regarding language modeling, the Mamba-3B model outperforms Transformers of similar scale in both pre-training and downstream evaluations, rivaling Transformers twice its size.
Additionally, he co-authored FlashAttention versions 1 through 3. FlashAttention is widely used to accelerate Transformers, improving attention speed by 4 to 8 times.
GitHub link: https://github.com/Dao-AILab/quack/blob/main/media/2025-07-10-membound-sol.md
Comments
Sign in to join the discussion and leave a comment.
Sign in with Google